
> 이 글은 스탠퍼드대학교 Andrew Ng 교수님의 강의를 수강한 것을 토대로 작성한 글입니다
📌 Multivariate Linear Regression
다변량 선형 회귀
-
앞에서는 하나의 X로 Y를 예측함
But, 실제 현실에서는 여러 개의 X로 Y를 예측하는 경우의 문제가 대부분
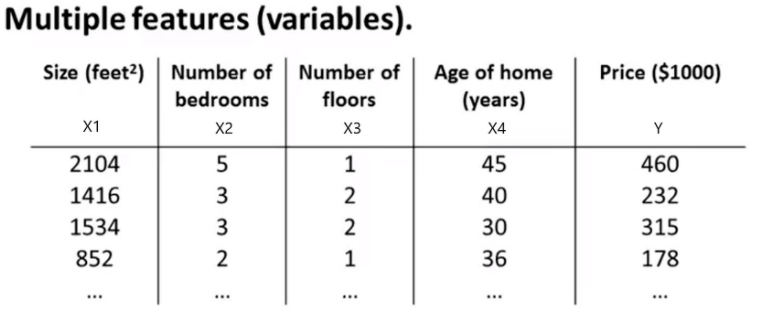

-
한 개의 X로 이루어진 선형회귀의 가설함수
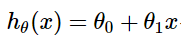
-
여러 개의 X로 이루어진 선형회귀의 가설함수
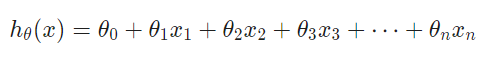
-
두 행렬의 곱으로 나타냄 가설함수

-
💡 위의 식들을 보면 X가 여러개일 때와 X가 하나일 때의 식이 같은 것을 알 수 있으며 이는 두 문제 모두 같은 접근방식을 사용 할 수 있음을 의미함
-
📌 Gradient Descent for Multiple Variables
다변량 경사하강법
-
다변량 선형 회귀와 결과가 같음


- 💡 위의 식들을 보면 θ가 여러개일 때와 θ가 하나일 때의 식이 같은 것을 알 수 있으며 이는 두 문제 모두 같은 접근방식을 사용 할 수 있음을 의미함
📌 Feature Scaling
데이터 전처리
- Feature들의 크기와 범위를 정규화시켜주는 것
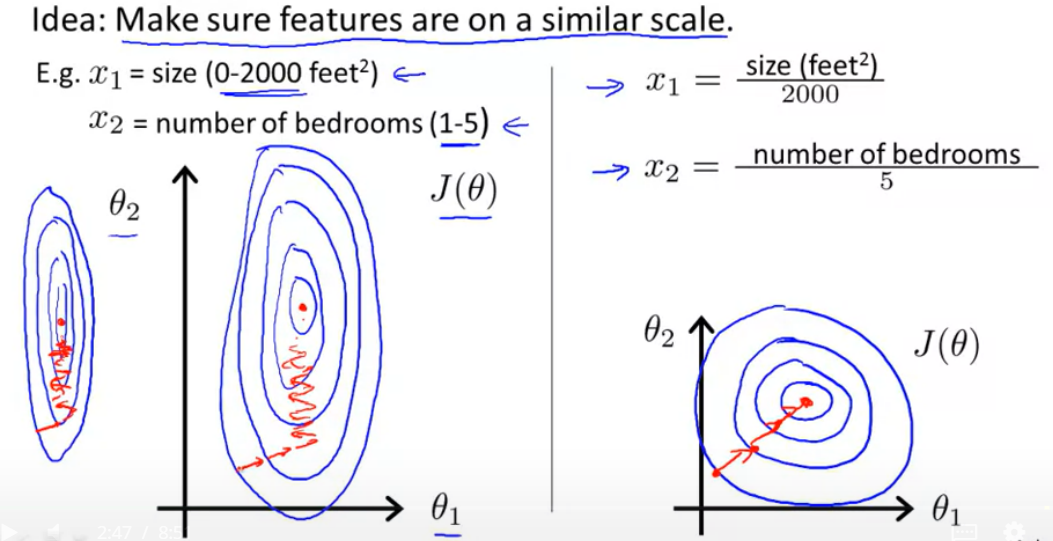
- 서로 Scale이 다른 데이터들을 그대로 쓰게되면 비용함수 J에 대한 등고선이 왼쪽처럼 얇거나 두꺼운 형태를 띄게 됨
그러면 gradient는 오랜 시간 동안 앞 뒤로 진동하며, 엄청난 시간이 지나고 나서야 최소값에 도달함 - 하지만 feature들을 feature들이 가진 최대값으로 나눈다면 feature들의 범위가 0과 1 사이의 값이 되기 때문에 오른쪽처럼 균형있는 형태로 바뀜
그러면 gradient는 좀 더 빠르게 최소값에 도달할 수 있음
- 서로 Scale이 다른 데이터들을 그대로 쓰게되면 비용함수 J에 대한 등고선이 왼쪽처럼 얇거나 두꺼운 형태를 띄게 됨
- how to mean normalization
- [ x - 평균(Avg) / x Max - x Min ] 이 식을 이용하여 근사화를 진행하면,
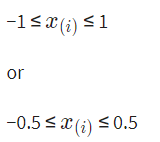 모든 feature들이 위와같 값을 띄게 됨
모든 feature들이 위와같 값을 띄게 됨
- [ x - 평균(Avg) / x Max - x Min ] 이 식을 이용하여 근사화를 진행하면,
📌 Learning Rate
α (알파)
-
α 값이 커지면 커질수록 overshooting이 일어나 최소점을 찾지 못함
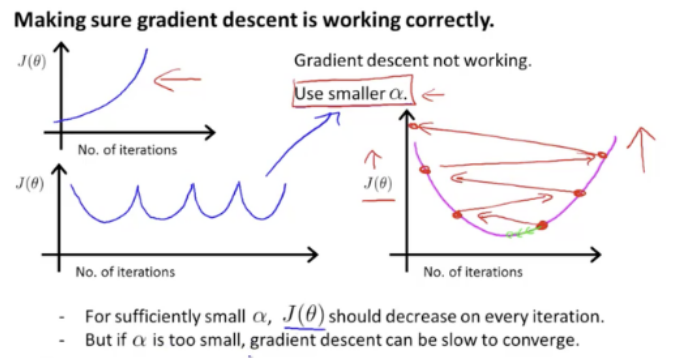
-
α 값을 잘못 선택할 경우 위와 같은 결과를 얻게됨
- 왼쪽 위의 그래프처럼 너무 큰 α 값을 선택하면 최소점에 도달하지 못하고 계속 증가함
- 왼쪽 아래의 그래프처럼 충분히 작지 않은 α값을 선택하면 최소점을 찾지 못함
- 오른쪽 그래프처럼 충분히 작지 않은 α 값을 선택하면 overshooting이 일어남
따라서 최소점을 찾기 위해서는 적절한 α (Learning Rate)값을 선택해야함
-
-
하지만 적절한 Learning Rate를 찾는 공식은 없음

- 그렇기 때문에 "0.001 −> 0.003 −> 0.01 −> 0.03 −> 0.1 −> 0.3 −> 1" 이렇게 Learning Rate를 작은 수부터 키워나가며 비용그래프를 보며 적절한 값을 직접 찾는 노가다를 해야함
📌 Features
- Features를 줄이자
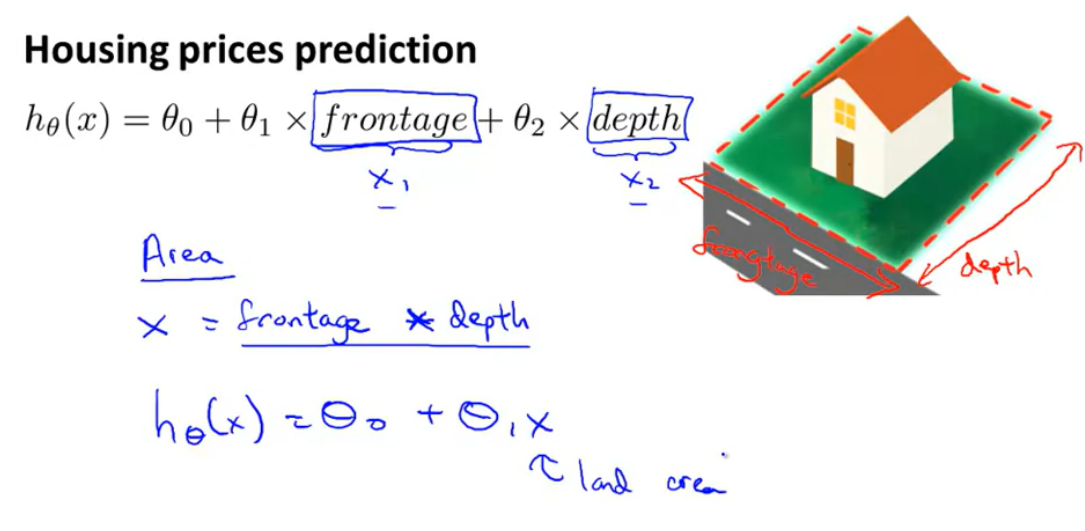
- 집의 가격을 구하는 선형회귀 문제에서 집의 Feature가 집의 가로길이, 집의 세로길이 두가지가 있다고 가정하면, 함수 h는 위와 같이 변수가 두 개로 표현이 됨
하지만 두개의 Features가 의미하는 정보를 생각해보면, 이는 넓이라는 것을 알 수 있음, 이를 이용하면 함수 h의 변수를 하나로 변환할 수 있음
- 집의 가격을 구하는 선형회귀 문제에서 집의 Feature가 집의 가로길이, 집의 세로길이 두가지가 있다고 가정하면, 함수 h는 위와 같이 변수가 두 개로 표현이 됨
📌 Polynomial Regression
다항회귀
- Features Scaling을 잘하자
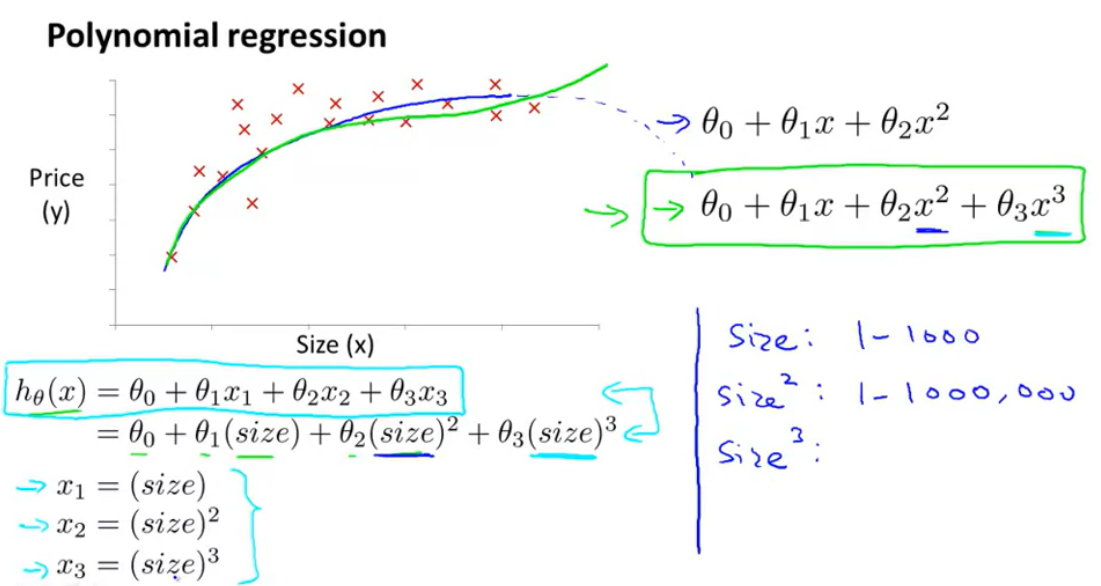
-
- 1차 식은 집 값 data set인 x표시들을 표현하기 어려움
- 파란색 선 처럼 2차식으로 표현하는 것은 집의 크기는 커지는 반면 가격은 점점 떨어질 것이기 때문에 옳지 않음
- 연두색 선 처럼 3차식으로 표현하면 올바르게 표현이 가능함
Features의 개수가 증가하였으므로 Features Scaling를 잘 해야함
-
- EX
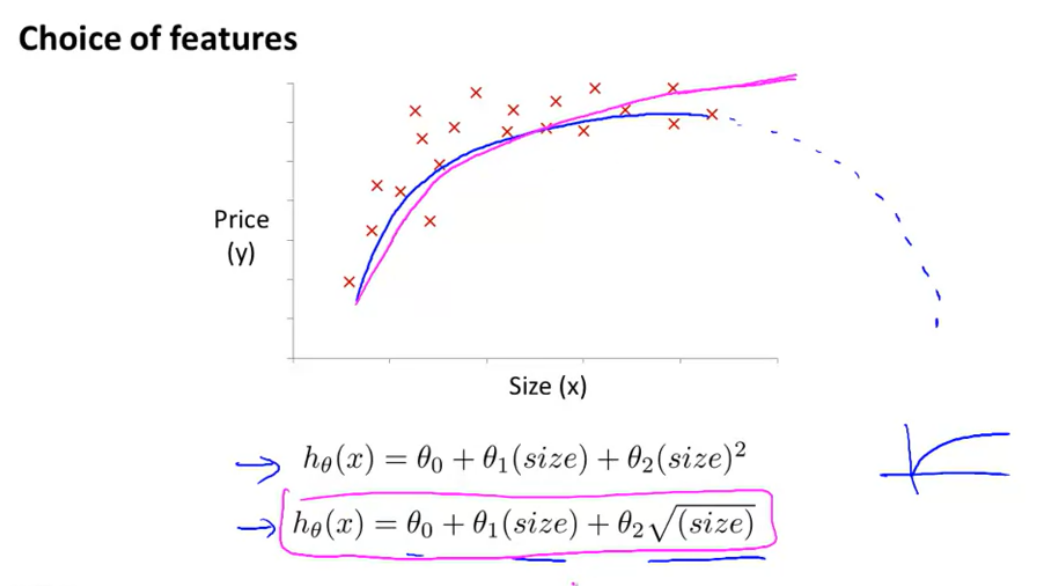
- 위와 같이 Features를 잘 선택하면 성능을 향상시켜 보다 편리하게 문제를 해결 할 수 있음
📌 Normal Equation
정규방정식
- 최적의 θ값을 찾기 수월한 방법
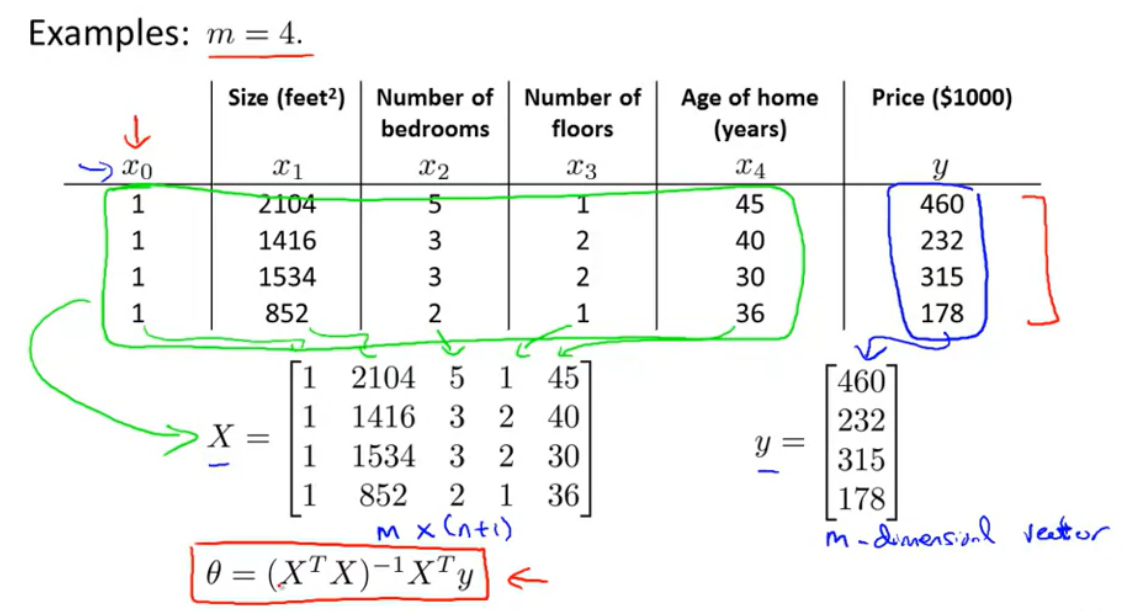
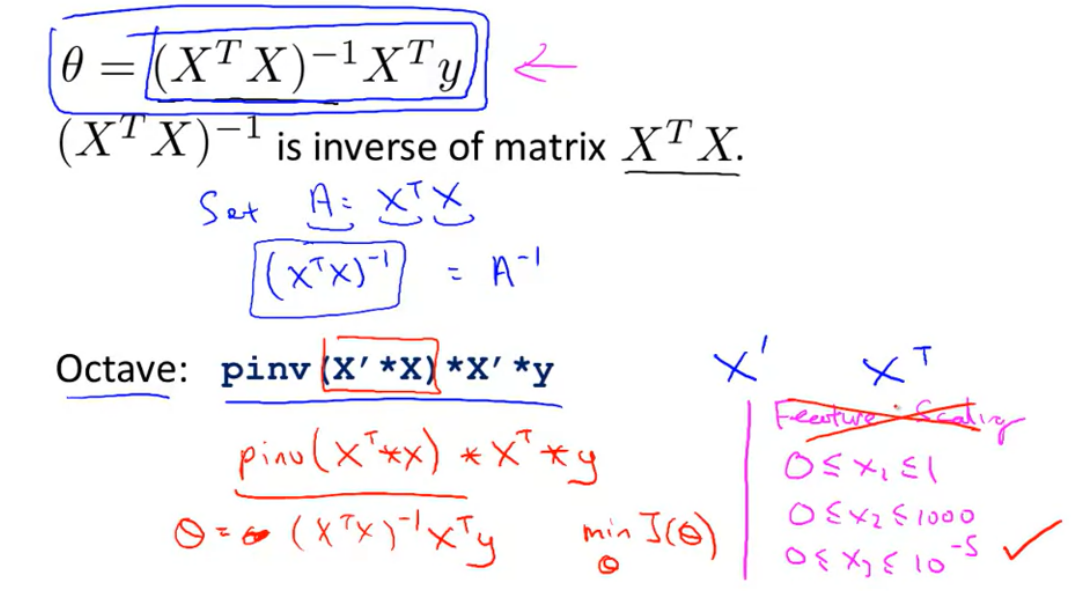
- 반복적으로 계산하는 Gradient Descent 알고리즘과 달리 θ를 분석적으로 계산하기 때문에 최소점을 단 한번의 계산으로 얻을 수 있음
- Normal Equation

+ 역행렬이 없는 경우는 대체로 두가지 경우임
1) 불필요한 Features를 가지고 있는 때
2) 너무 많은 Features를 가지고 있는 때 (예:m≤n).
따라서 역행렬이 없는 경우 불필요한 Features를 지우거나 개수를 줄이면 됨

레벨업중...