
> 이 글은 스탠퍼드대학교 Andrew Ng 교수님의 강의를 수강한 것을 토대로 작성한 글입니다
📌 Classification
다중 분류
- 주어진 feature에 따라 데이터를 discrete한 class에 분류하는 방법
- Ex)

- Ex)
- 예측변수 y는 0과 1의 값을 가짐
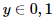
- 일반적으로 0은 "negative class" / 1은 "positive class" 로 나눠 부르지만, 두 개를 바꿔 사용해도 상관 없음
📌 Hypothesis Representation
가설 설명
- 회귀 분석에서 사용한 가설함수는 아래와 같다고 하자,
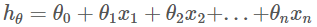
- 가설함수를 백터곱으로 나타내면 아래와 같다
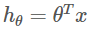
- 이 가설함수를 0 ~ 1 사이의 값만 갖도록 시그모이드 함수를 사용하면 다음과 같다
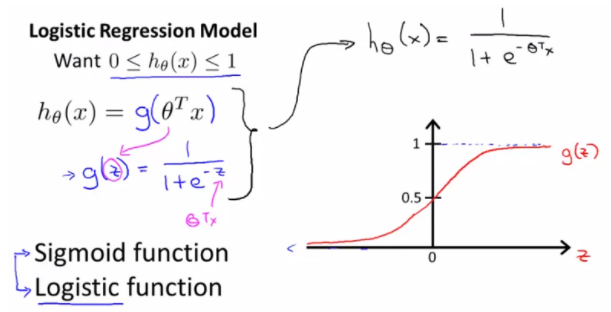
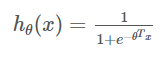
- Ex) 악성 종양을 판단할 때, 1이면 악성, 0이면 양성이라고 하면
-> 여기서 함수값이 0.7이 나왔을 경우 악성일 확률이 70%라고 봄
📌 Decision Boundary
결정 경계
- y = 0과 y = 1을 가르는 경계선
📌 Cost Function
비용 함수
-
선형회귀분석의 비용함수
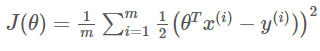
-
개별적인 비용 ( 아래로 볼록한 함수 = convex )
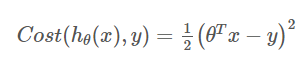
-
로지스틱 회귀분석 적용
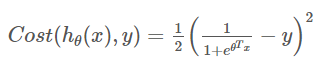
위 함수는 convex가 아니기 때문에 최솟값을 구하기 어려움 -
이를 해결하기 위해 아래와 같은 새로운 형태의 함수 도입
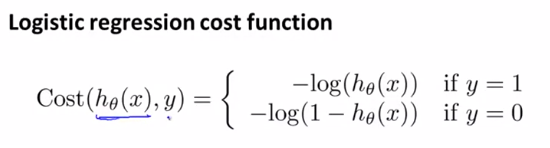
그러면 y = 0일 때와 y = 1일 때 서로 다른 함수를 따르게 됨
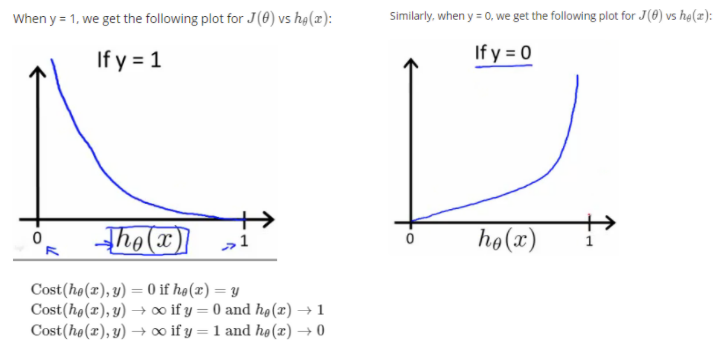
📌 Simplified Cost Function and Gradient Descent
단순화된 비용함수와 경사하강법
- 합치기 전의 개별비용함수
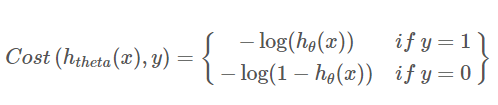
- 합친 후의 개별비용함수
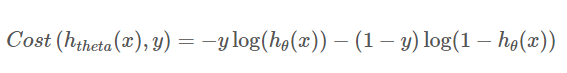
- 비용함수
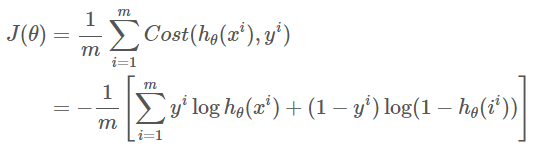
- 경사하강법 적용


📌 Multiclass Classification
One-vs-All (One-vs-Rest)
다변량 다중 분류
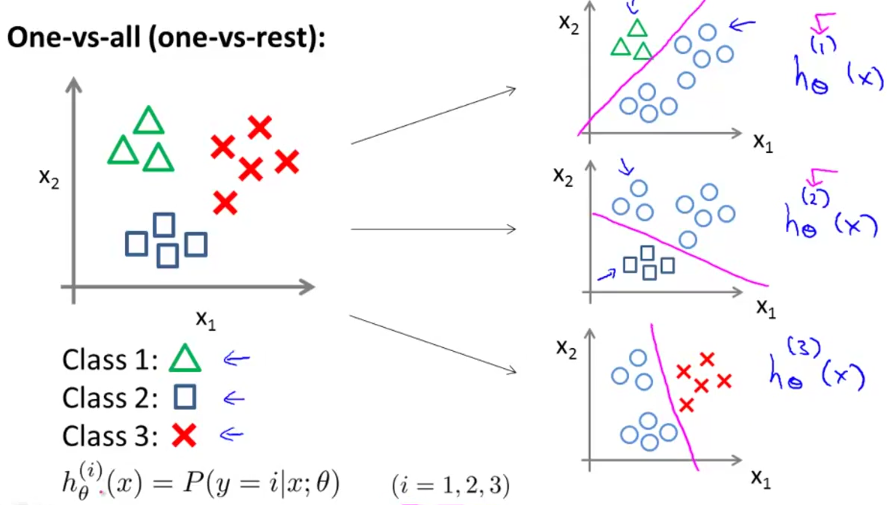
class의 모든 h함수에 대해 예측값을 구한 다음 가장 값이 큰 class가 해당 x가 속하게 되는 최종 결과가 됨
📌 overfitting
과적합
- 과소적합, 적합, 과대적합
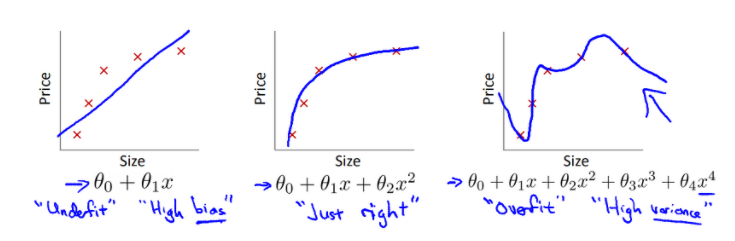
- 해결 방법
-
feature의 개수를 줄이기
-
제거할 feature와 유지시킬 feature를 직접 선택
-
Model selection algorithm을 사용하여 자동으로 feature를 선택
-
-
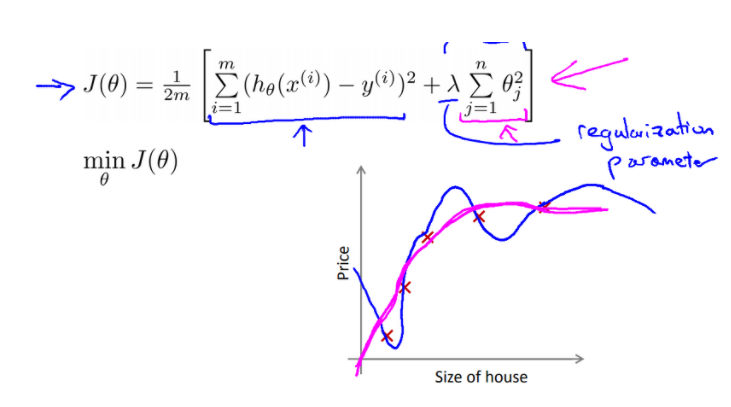
Regularization (정규화)
-
모든 feature를 유지하고, parameter theta 값만 줄임
-
유용한 feature들이 많으면 성능이 좋아짐
-
비용함수

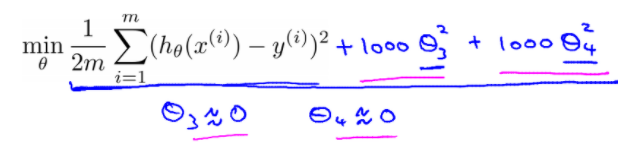

레벨업중...