
Convolutional Neural Network (CNN)
: 인간의 시신경을 모방하여 만든 딥러닝 구조
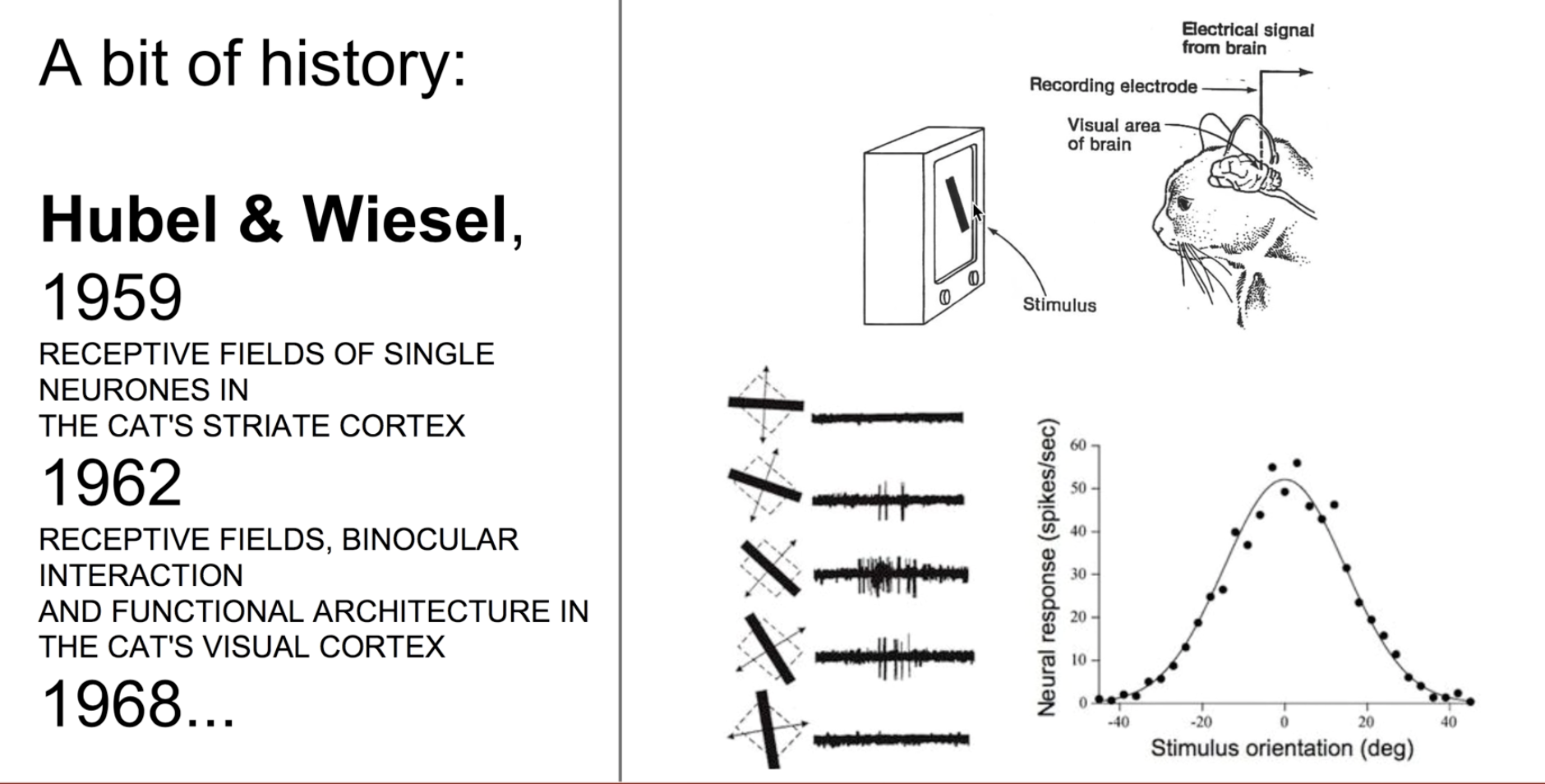 -> 고양이가 사물을 인식하는 방법에서 착안
-> 고양이가 사물을 인식하는 방법에서 착안
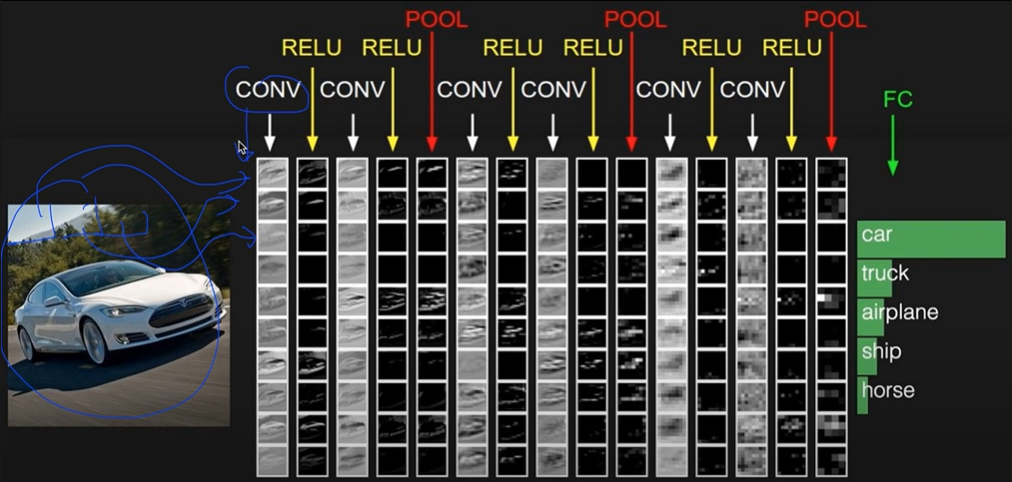 -> 이미지가 입력으로 주어지면 이미지를 부분으로 나누어 Conv, Relu, Poor 등의 층을 반복하여 통과하여 학습한 후 Fully Connected Neural Network를 구성하여 레이블링 진행
-> 이미지가 입력으로 주어지면 이미지를 부분으로 나누어 Conv, Relu, Poor 등의 층을 반복하여 통과하여 학습한 후 Fully Connected Neural Network를 구성하여 레이블링 진행
이미지 처리 방법 용어
Filter : 이미지를 한번에 처리할 크기, filter을 통해 값을 하나로 합함.
Stride : filter를 움직이는 크기, stride가 1이면 1칸씩 움직이고 stride가 2면 2칸씩 움직임
Padding: 네트워크에 모서리가 어디인지 알려주는 것, 크기가 급격히 감소하는 것을 막아줘 입력의 이미지와 출력의 이미지가 같게 만들어줌
이미지 처리 방법 1
-
ex) 32x32 크기 & rgb색상 값을 가지는 이미지
-> 32x32x3

-
이미지의 일부를 잘라내기 위해 5x5x3 필터를 사용한다고 가정

여기서 필터는 원본 이미지를 필터의 크기만큼 나누고 나누어진 이미지에서 Wx+b라는 수식을 사용하여 하나의 숫자를 추출함
(W = 필터의 값)

-
이 과정을 전체 이미지 크기만큼 반복
이미지 처리 방법 2
-
7x7 이미지에 3x3 필터를 사용하면 5x5의 결과를 얻음
여기서 Stride는 1로 설정
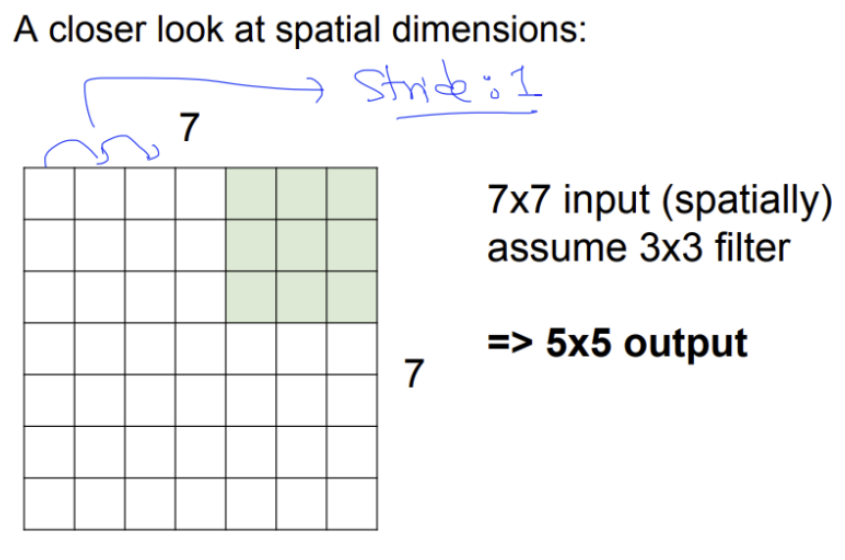
-
stride값에 따라 결과를 계산할 수 있음
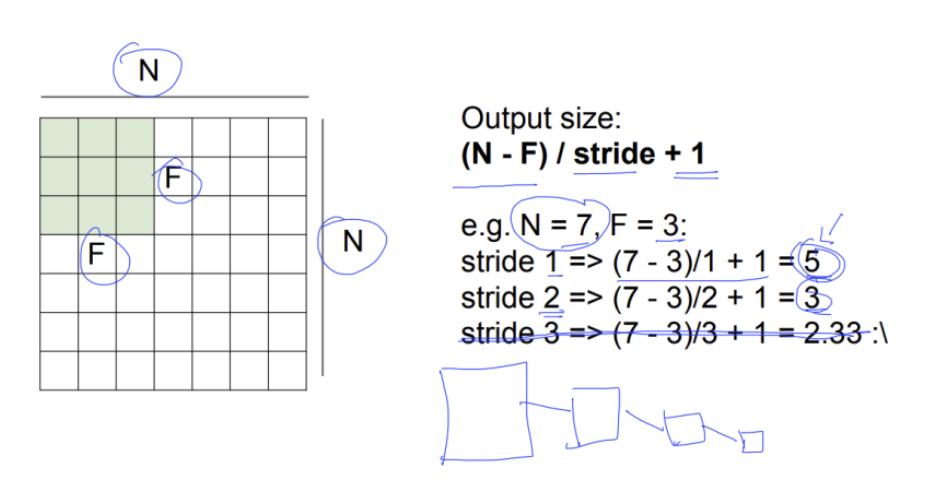
-
Padding
 Convolutional Layer를 거치면 이미지가 크기가 점점 감소하므로 원본이미지에 0을 padding하여 이를 예방
Convolutional Layer를 거치면 이미지가 크기가 점점 감소하므로 원본이미지에 0을 padding하여 이를 예방
(여기서, convolution layer란, CNN에서 핵심이 되는 부분으로 이미지를 classification하는데 필요한 feature 정보들을 추출함) -
이미지 출력
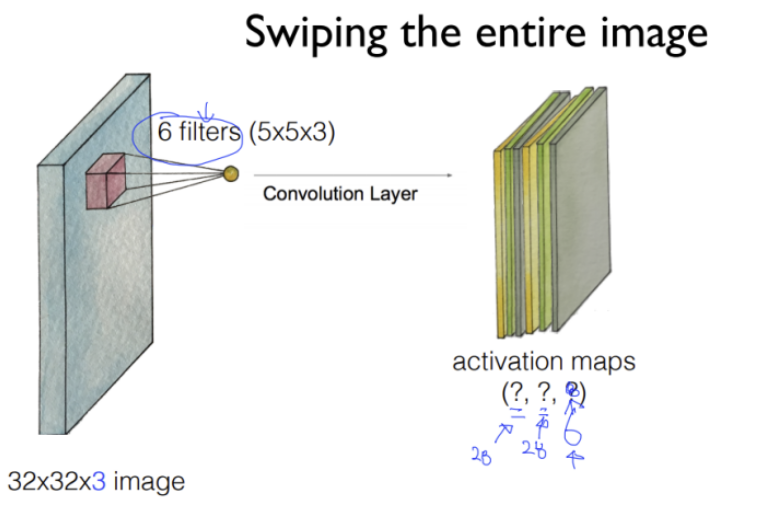 6개의 필터를 사용하여 이미지 출력 -> 이 이미지를 Activation Map이라 함
6개의 필터를 사용하여 이미지 출력 -> 이 이미지를 Activation Map이라 함 -
계속해서 Convolution layer 통과
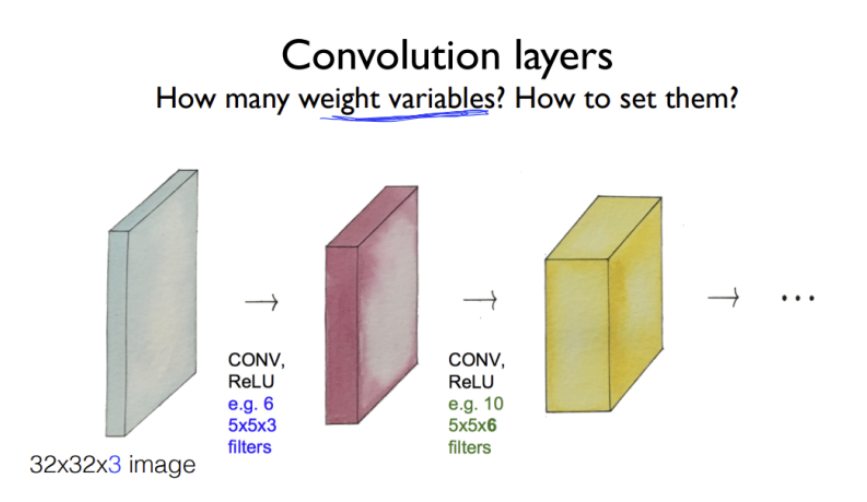 일반적으로 Convolution layer를 통과할 때마다 이미지의 크기는 작아지고 두께는 두꺼워짐
일반적으로 Convolution layer를 통과할 때마다 이미지의 크기는 작아지고 두께는 두꺼워짐
