

결정 트리
01. 결정 트리란?
-
결정 트리(Decision Tree)
예 / 아니오로 답할 수 있는 어떤 질문들이 있고, 그 질문들의 답을 따라가면서 데이터를 분류하는 알고리즘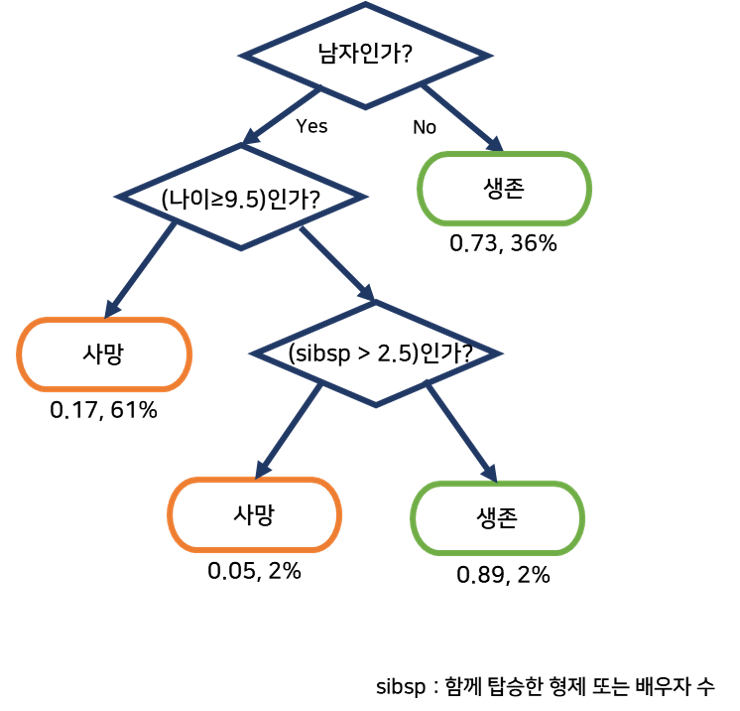 위의 예시처럼 예측하려는 데이터에 대한 질문들의 답에 따라 왼쪽 또는 오른쪽으로 가서 데이터를 분류해준다.
위의 예시처럼 예측하려는 데이터에 대한 질문들의 답에 따라 왼쪽 또는 오른쪽으로 가서 데이터를 분류해준다.
이때 중요한 것은 한 속성을 딱 한 번만 사용해야 되는 것은 아니라는 점이다. 나이가 9.5 이상인지 한 번 질문하고 나중에 나이가 6 이상인지 아닌지 질문하는 등 하나의 속성으로 여러 개의 질문을 만들 수도 있다.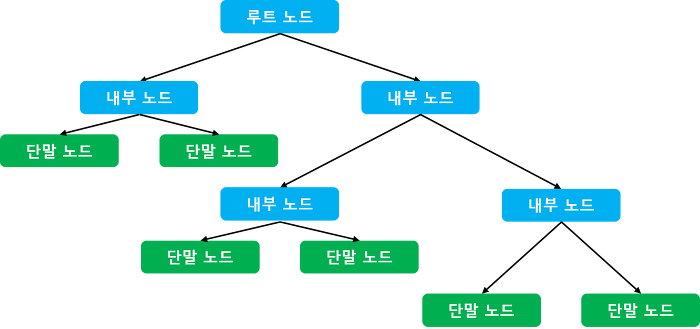 이 알고리즘은 하나의 시작 지점에서 퍼져나가는 모습이 마치 나무와 비슷하고, 한 단계 내려갈 때마다 왼쪽으로 갈지 오른쪽으로 갈지 선택하는 알고리즘이기 때문에 "결정 트리"라고 한다.
이 알고리즘은 하나의 시작 지점에서 퍼져나가는 모습이 마치 나무와 비슷하고, 한 단계 내려갈 때마다 왼쪽으로 갈지 오른쪽으로 갈지 선택하는 알고리즘이기 때문에 "결정 트리"라고 한다.하나하나에 있는 박스를 노드라고 하고, 구체적으로 가장 위에 있는 질문 노드를 root 노드, 트리의 가장 끝에 있는 노드들을 leaf 노드라고 한다.
leaf 노드는 항상 사망/생존과 같이 특정한 예측값을 갖고 있고 나머지 노드들은 예/아니오로 답할 수 있는 질문을 갖는다.
02. 지니 불순도
Review) 선형 회귀 알고리즘의 목적 : 학습 데이터를 가장 잘 나타낼 수 있는 일차식 찾기
결정 트리 알고리즘의 목적은 학습 데이터를 직접 분류해보면서, 데이터들을 가장 잘 분류할 수 있는 노드들은 찾아내는 것이다. 머신 러닝 프로그램이 이미 정해진 내용대로 만드는 게 아니라 경험을 통해 직접 정해나가야 하기 때문에 데이터를 분류해보면서, 각 위치에서 어떤 노드가 가장 좋을지 골라야 한다.
- 지니 불순도(gini impurity)
손실 함수 같은 개념으로, 어떻게 분류하거나 질문을 하는 게 좋고, 안 좋은지에 대한 기준이 된다.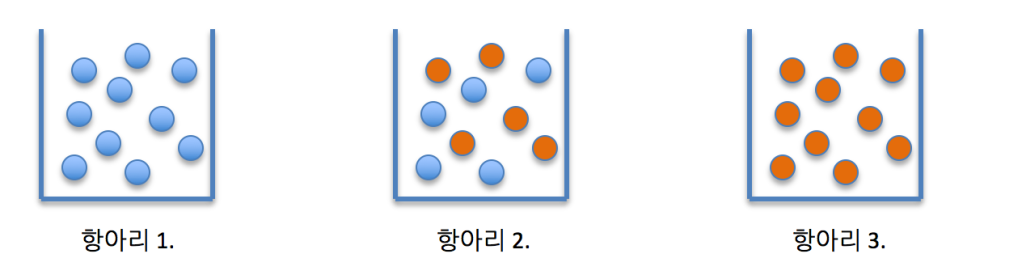 위의 예시에서, 지니 불순도는 데이터 중 빨강 / 파랑 데이터가 얼마나 섞여 있는지를 나타낸다. 항아리 1 또는 3과 같이 데이터가 하나의 분류라면, 100% "순수한" 데이터 셋이라 하고, 항아리 2와 같이 반반씩 분류가 갈려 있으면 100% "불순한" 데이터 셋이라고 한다.
위의 예시에서, 지니 불순도는 데이터 중 빨강 / 파랑 데이터가 얼마나 섞여 있는지를 나타낸다. 항아리 1 또는 3과 같이 데이터가 하나의 분류라면, 100% "순수한" 데이터 셋이라 하고, 항아리 2와 같이 반반씩 분류가 갈려 있으면 100% "불순한" 데이터 셋이라고 한다.
- 지니 불순도 공식
지니 불순도는 데이터 셋이 정확히 얼마나 불순한지를 숫자로 표현해준다.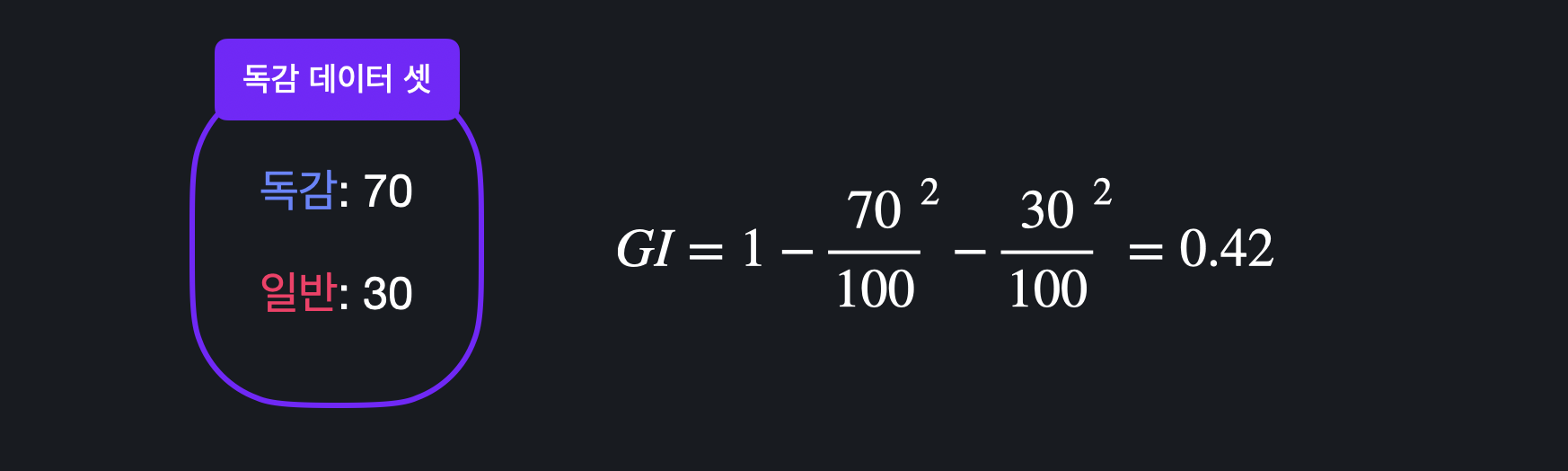 독감 데이터 예시에서는 로 구할 수 있다.
독감 데이터 예시에서는 로 구할 수 있다. 지니 불순도가 높을수록 데이터가 불순하다, 즉 데이터 셋에 다양한 분류가 섞여있다.
지니 불순도가 높을수록 데이터가 불순하다, 즉 데이터 셋에 다양한 분류가 섞여있다. 지니 불순도가 낮을수록 데이터가 순수하다, 즉 데이터 셋 안의 데이터들이 모두 하나의 분류에 집중되어 있다. 이때 가장 순수한 데이터는 지니 불순도가 0이다.
지니 불순도가 낮을수록 데이터가 순수하다, 즉 데이터 셋 안의 데이터들이 모두 하나의 분류에 집중되어 있다. 이때 가장 순수한 데이터는 지니 불순도가 0이다.
03. 노드 평가하기
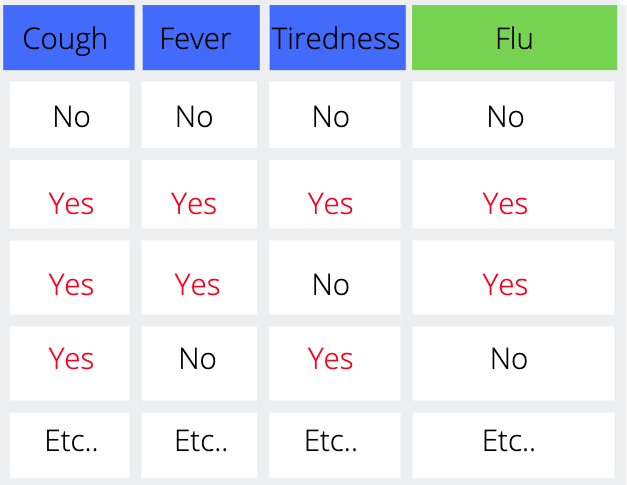
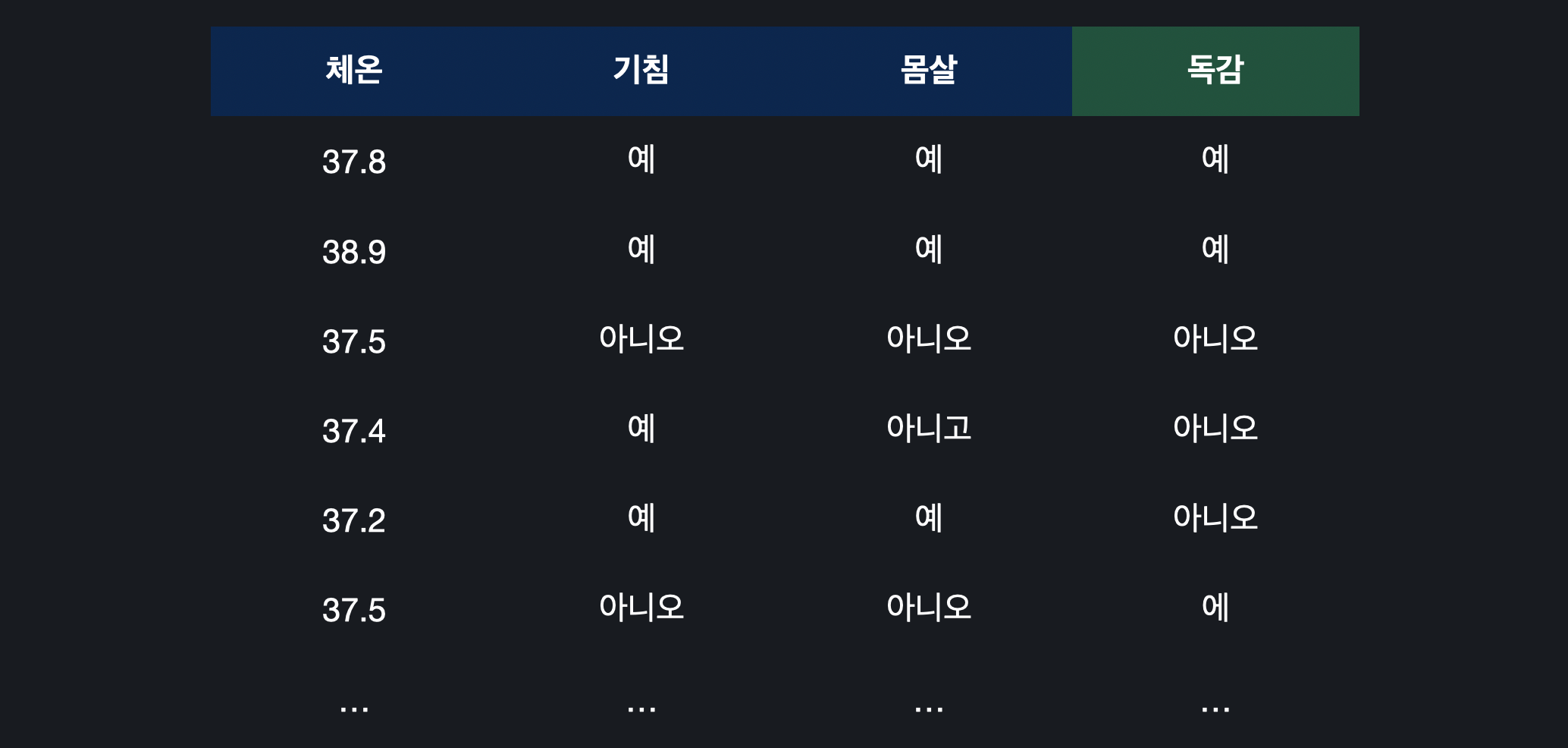
위의 데이터 셋은 고열, 기침, 몸살 여부를 속성으로 갖고 환자가 독감인지 아닌지를 목표 변수로 갖는다. 따라서
질문 노드 : 고열이 있나요? / 기침이 있나요? / 몸살이 있나요?
분류 노드 : 독감 / 일반 감기
와 같이 구분할 수 있다.
결정 트리를 만들기 위해서는 가장 먼저 root 노드를 만들어야 하는데 방법은 다음과 같은 단계로 이루어진다.
1. 질문 노드를 만들지 않고 바로 분류 노드를 만든다. ex) 모든 데이터가 독감이다
2. 질문 노드 중 하나를 root 노드로 만든다.
1) 분류 노드 평가하기
예시) 학습 데이터가 90개 있고 그 중 독감인 사람이 50명, 아닌 사람이 40명 있는 경우 지금 같은 경우 독감 데이터가 더 많기 때문에 데이터 셋이 독감 노드로 분류된다.
지금 같은 경우 독감 데이터가 더 많기 때문에 데이터 셋이 독감 노드로 분류된다.
좋은 분류 노드는 최대한 많은 학습 데이터의 예측을 맞춰야 하고, 이것은 데이터 셋이 순수할수록(지니 불순도가 낮을수록) 좋은 분류 노드임을 의미한다.
위 예시의 불순도를 계산해보면, 로 불순도가 꽤 높게 계산된다. 이렇게 데이터가 불순할 때는 분류 노드로 만들면 성능이 안좋아지게 된다.
이렇게 분류 노드를 만들려고 할 때는 분류하려고 하는 데이터 셋의 불순도를 계산하면, 이 노드가 어느 정도의 데이터를 맞출 수 있는지 한 번에 알 수 있다.
2) 질문 노드 평가하기
좋은 질문 노드는 섞여 있는 데이터를 잘 나눠서 점점 더 분류하기 쉽게 만들어 준다. 나뉜 데이터 셋들이 순수할수록(지니 불순도가 낮을수록) 좋은 질문이다.
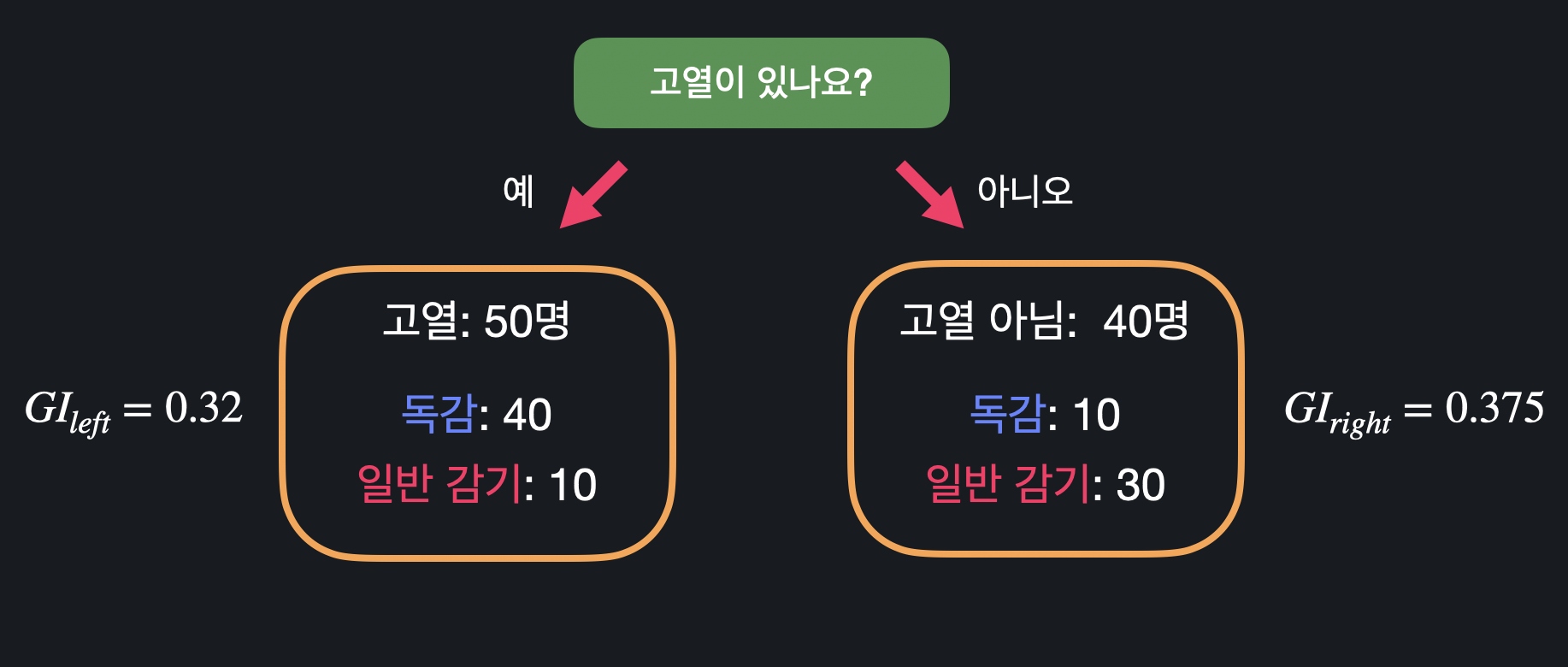 질문 노드의 성능은 나뉜 두 데이터 셋의 지니 불순도를 통해 평가한다. 분류된 두 데이터 셋의 지니 불순도는 다음과 같이 구할 수 있다.
질문 노드의 성능은 나뉜 두 데이터 셋의 지니 불순도를 통해 평가한다. 분류된 두 데이터 셋의 지니 불순도는 다음과 같이 구할 수 있다.
"고열이 있나요?"라는 질문 노드의 성능을 평가하기 위해서는 위의 두 불순도를 평균 내주면 되는데, 그냥 더하는 것이 아니라 각 데이터에 크기만큼 무게를 줘서 합쳐줘야 한다.
따라서 가 "고열이 있나요?"라는 질문 노드에 대한 지니 불순도이고, 이 값이 작을수록 질문 노드의 성능이 좋다고 할 수 있다.
04. 노드 고르기
<03. 노드 평가하기>에서 구한 질문 노드와 분류 노드의 지니 불순도를 비교해 가장 불순도가 낮은 노드를 선택하면 된다.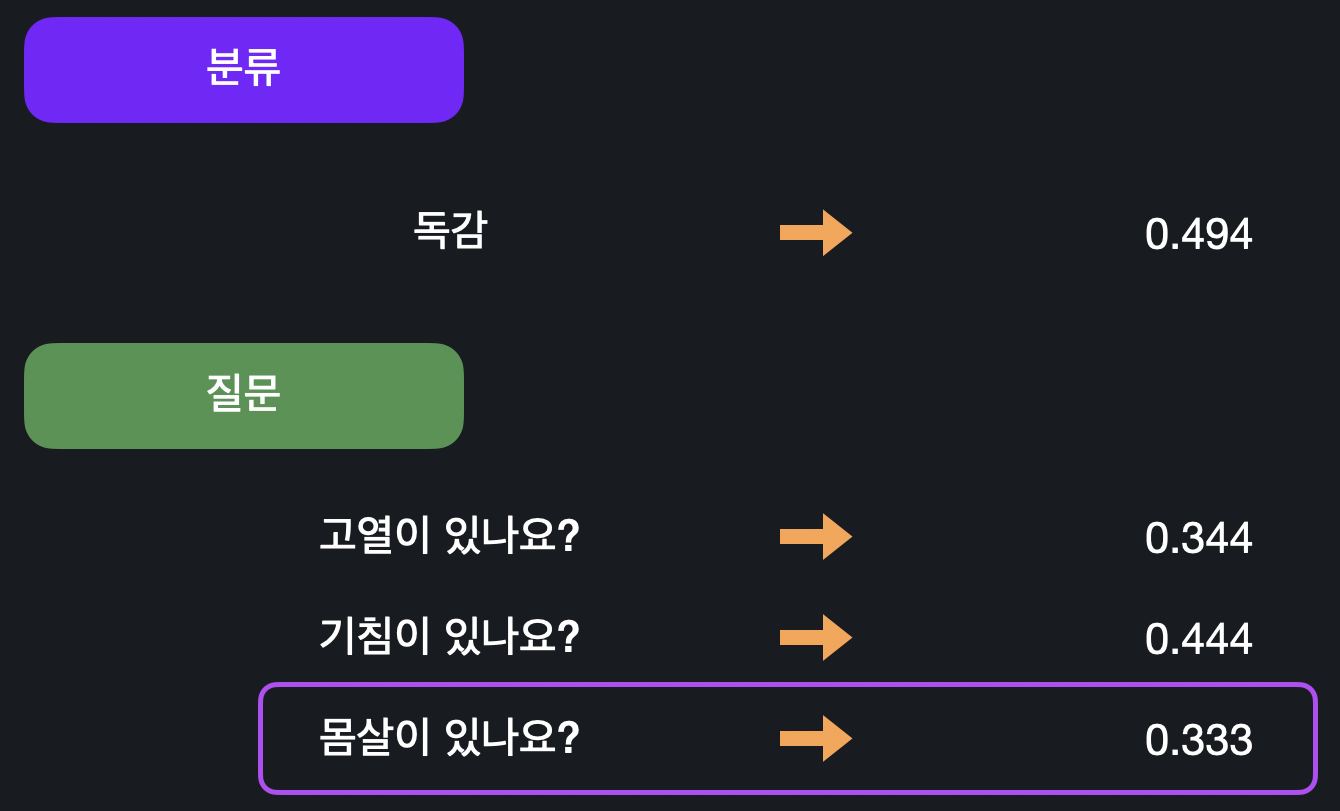 예시에서 만들 수 있는 모든 노드들 중 "몸살이 있나요?"가 가장 불순도가 낮으므로 이걸 root 노드의 질문으로 고르면 된다.
예시에서 만들 수 있는 모든 노드들 중 "몸살이 있나요?"가 가장 불순도가 낮으므로 이걸 root 노드의 질문으로 고르면 된다.
05. 모든 노드 만들기
<03. 노드 평가하기>와 <04. 노드 고르기> 과정을 반복하면서 root 노드 다음으로 똑같이 나머지 노드들을 고르면 된다. root 노드는 이미 선택했기 때문에, root 노드를 통해 분류된 학습 데이터를 가지고 다시 가장 좋은 노드를 찾아주면 된다.
- 트리의 깊이
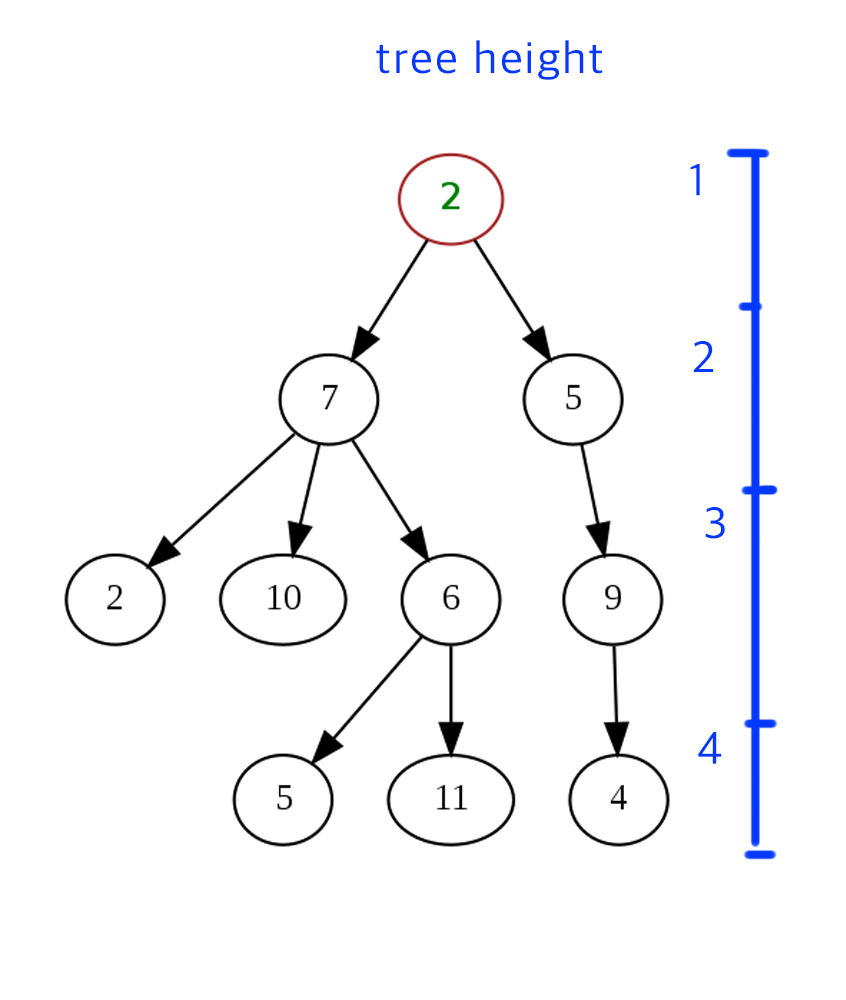 트리가 몇 층까지 내려가는지를 뜻하며, 모델을 만들 때 깊이를 지정해줄 수도 있다. 그렇게 되면 특정 깊이까지 내려오면 더 이상 불순도를 비교하지 않고 분류 노드를 만들게 된다.
트리가 몇 층까지 내려가는지를 뜻하며, 모델을 만들 때 깊이를 지정해줄 수도 있다. 그렇게 되면 특정 깊이까지 내려오면 더 이상 불순도를 비교하지 않고 분류 노드를 만들게 된다. - 속성이 숫자형일 때 질문 노드 만들기
 체온처럼 숫자형 데이터인 경우, 무수히 많은 질문들을 만들 수 있다.
체온처럼 숫자형 데이터인 경우, 무수히 많은 질문들을 만들 수 있다.
그럴 때는 먼저 데이터를 오름차순으로 정렬한 후 , 연속된 데이터에 대한 평균을 계산하고 그 값으로 만든 질문 노드의 지니 불순도를 구한다.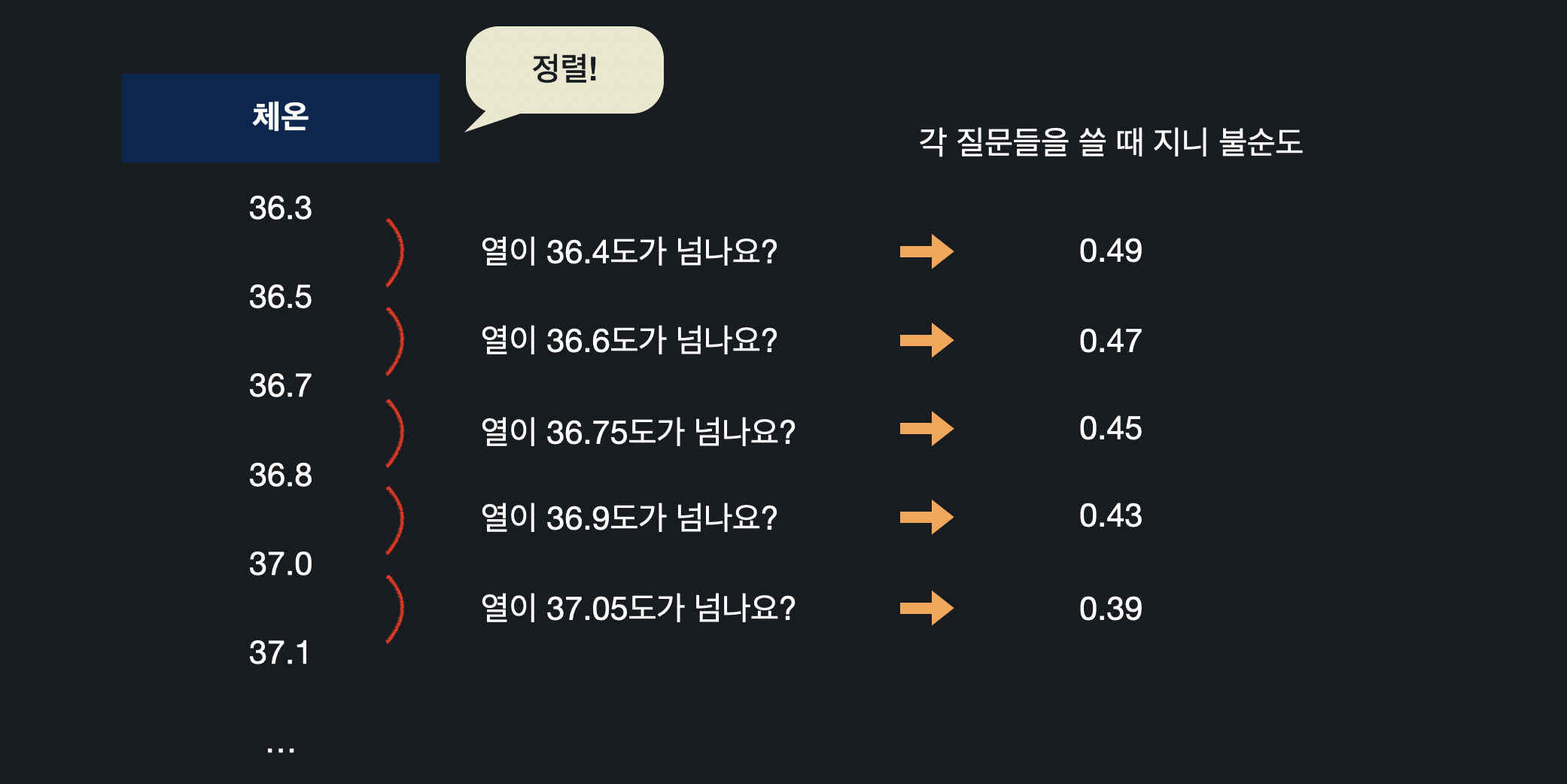 지니 불순도를 비교했을 때, 가장 낮은 값을 갖는 온도가 체온 속성에 대한 대표 질문("체온이 37.5가 넘나요?")이 되고,
지니 불순도를 비교했을 때, 가장 낮은 값을 갖는 온도가 체온 속성에 대한 대표 질문("체온이 37.5가 넘나요?")이 되고,
이렇게 뽑은 대표 질문으로 <04. 노드 고르기>에서 한 대로 노드들의 성능을 비교해주면 된다. 이런 방식으로 데이터가 불린형이든 숫자형이든 상관 없이 결정 트리 노드들을 만들 수 있다.
06. 속성 중요도
-
노드 중요도(Node Importance)
노드 중요도는 한 노드에서 데이터를 두 개로 나눴을 때, 데이터 수에 비례해서 불순도가 얼마나 줄어들었는지를 계산하는 것이다.- : 노드 중요도
- : 중요도를 계산하려는 노드까지 오는 학습 데이터의 수
- : 전체 학습 데이터의 수
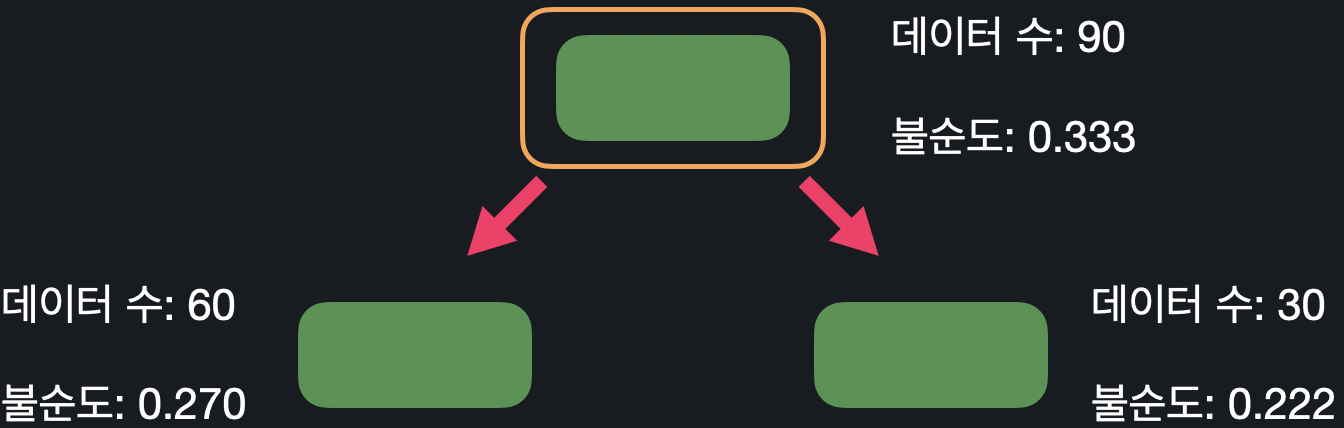 예시) root 노드의 중요도
예시) root 노드의 중요도
특정 노드가 얼마나 중요한 노드인지 판단할 때, 이 노드 전후로, 불순도가 얼마나 낮아졌는지를 노드 중요도를 통해 파악할 수 있다. 이렇게 나눠지는 데이터 셋들에 대해 "점점 더 많은 정보를 얻는다"라고 해서 이 수치를 정보 증가량(information gain)이라고도 부른다.
-
속성 중요도(Feature Importtance)
속성 중요도는 특정 속성이 얼마나 중요한지를 계산한다.먼저 위 방법대로 모든 질문 노드에 대해 중요도를 구한 다음, 트리 안 모든 노드의 중요도의 합으로 나눠주면 된다.
 모든 노드가 데이터를 양 갈래로 나누면서 나누는 데이터 셋들의 지니 불순도를 낮추게 되는데, 이렇게 전체적으로 낮춰진 불순도에서 특정 속성 하나가 낮춘 불순도가 얼마나 되는지를 계산하는 것이다.
모든 노드가 데이터를 양 갈래로 나누면서 나누는 데이터 셋들의 지니 불순도를 낮추게 되는데, 이렇게 전체적으로 낮춰진 불순도에서 특정 속성 하나가 낮춘 불순도가 얼마나 되는지를 계산하는 것이다.
특정 속성을 질문으로 갖는 노드들의 중요도의 평균을 구한 것과 비슷해서 속성의 평균 지니 감소(Mean Gini decrese)라고 부르기도 한다.
