
랜덤 포레스트
01. 결정 트리와 앙상블
결정 트리는 개념 자체가 비교적 직관적이고 해석하기도 굉장히 쉽지만, 이상적인 머신 러닝 모델이 되기 힘든 한 가지 특징을 갖는다. 바로 "부정확성"인데, 쉽게 얘기하면 다른 모델들에 비해 성능이 안좋다는 뜻이다.
그럼에도 결정 트리를 응용하면 성능이 좋은 다른 모델들을 만들 수 있다. 결정 트리를 응용하는 가장 대표적인 기법으로는 앙상블이 있다.
- 앙상블(ensemble)
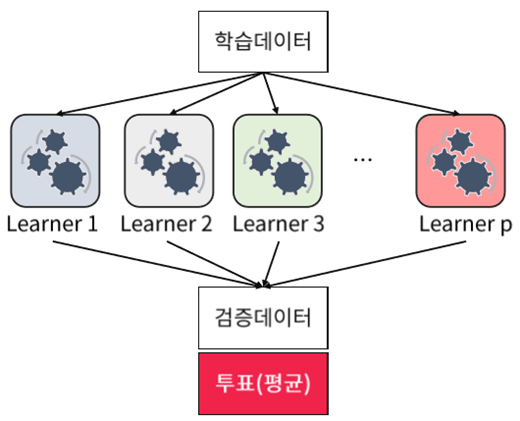
하나의 모델을 쓰는 대신, 수많은 모델들을 만들고 이 모델들의 예측을 합쳐서 종합적인 예측을 하는 기법이다.
결정트리와 앙상블을 합치면, 결정 트리 하나를 사용하는 것보다 성능이 훨씬 좋은 모델들을 만들 수 있다.
02. Bagging
-
랜덤 포레스트(Random Forest)
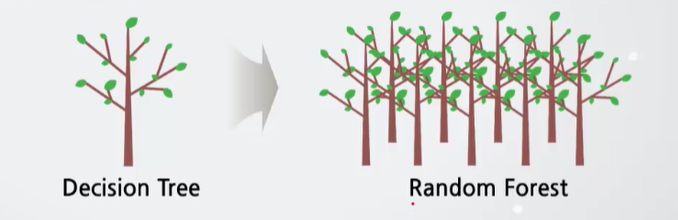 트리 앙상블 알고리즘 중 하나로, 수많은 트리들을 임의로 만들고 이 모델들의 결과를 다수결 투표로 종합해서 예측하는 모델이다. 트리를 엄청 많이, 임의로 만들기 때문에 '랜덤 포레스트'라는 이름을 갖는다.
트리 앙상블 알고리즘 중 하나로, 수많은 트리들을 임의로 만들고 이 모델들의 결과를 다수결 투표로 종합해서 예측하는 모델이다. 트리를 엄청 많이, 임의로 만들기 때문에 '랜덤 포레스트'라는 이름을 갖는다.랜덤 포레스트에서 임의성을 더하는 요소는 두 가지가 있다.
1 ) Bootstrapping
2 ) 모든 속성 중 임의로 몇 개를 고른 후, 그 속성들을 이용하는 질문들 중 더 좋은 것을 선택하여 결정 트리 만들기 -
Bootstraping
원래의 데이터 셋을 이용해 임의로 새로운 데이터 셋을 만들어 내는 방법이다.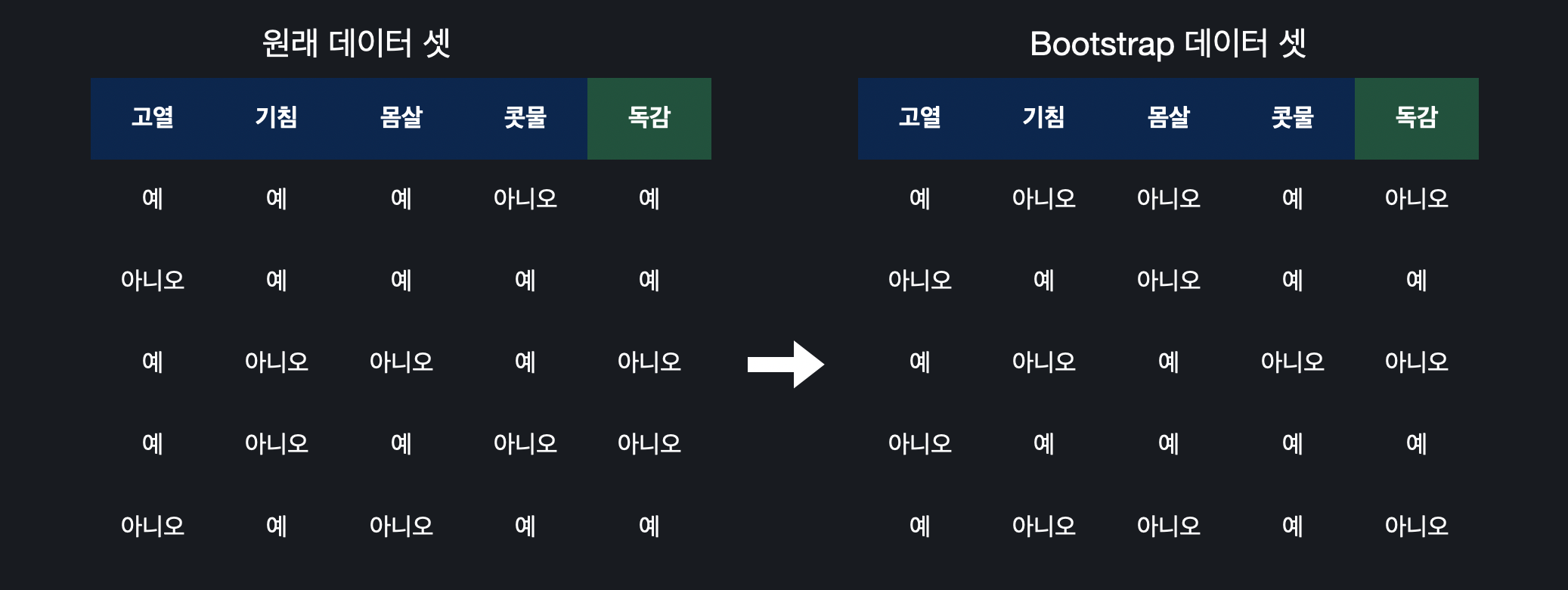 다음과 같은 독감 환자 데이터 셋을 사용한다 가정하면, bootstrapping으로 이 데이터를 이용해서 조금 다른 데이터 셋을 만들어 주면 된다.
다음과 같은 독감 환자 데이터 셋을 사용한다 가정하면, bootstrapping으로 이 데이터를 이용해서 조금 다른 데이터 셋을 만들어 주면 된다.앙상블에서는 수많은 모델들을 만들어 예측하는데, 이때 모델들이 다 정확히 똑같은 데이터 셋으로 학습되면 다양하게 결과가 나오지 않고 모든 모델들이 비슷한 결과를 낼 수도 있다.
이것을 방지하기 위한 방법 중 하나로, 한 모델을 만들 때마다 다 똑같은 데이터 셋을 사용하는게 아니라 임의로 만든 bootstrap 데이터 셋을 사용해주는 것이다. -
Bagging(Bootstrap aggregating)
bootstrap 데이터 셋을 만들어 내고, 모델들의 결정을 종합(aggregate)해서 예측하는 앙상블 기법을 나타낸다. 랜덤 포레스트는 bagging을 사용하는 여러 알고리즘 중 하나이다.
03. 임의로 결정 트리 만들기
bootstrap 데이터 셋으로 결정 트리를 만든다고 할 때,
결정 트리를 그냥 만들 때는 각 속성들을 사용한 질문들의 지니 불순도를 구해 가장 불순도가 낮은 질문 노드를 사용했다.
반면, 랜덤 포레스트는 여러 속성 중 임의로 두 개(속성이 더 많으면 세 개나 네 개도 고를 수 있음)를 골라 불순도를 계산해 더 좋은 것을 root 노드의 질문으로 정한다.
이렇게 매 노드를 만들 때 임의로 만들기 때문에 수많은 서로 다른 결정 트리들이 나올 수 있게 된다.
정리하자면, bootstrapping으로 임의의 데이터 셋을 만들고, 임의로 질문 노드들을 만들어 결정 트리를 만든다. 이 과정을 엄청 많이 반복하면서 수많은 결정 트리를 만드는 것이 "랜덤 포레스트"이다. 최종적으로 예측을 할 때는 이렇게 만든 수많은 결정 트리들의 예측값을 다수결 투표로 종합해서 결정한다.
