
모델 평가
01. k겹 교차 검증
-
k-겹 교차 검증(k-fold cross validation)
지금까지 머신 러닝 모델을 만들 때, 주어진 데이터를 training set과 test set으로 나눠 training set으로는 모델을 학습시켰고 test set으로는 모델의 성능을 파악하였다.
하지만 이 방식은 운좋게 test set에 대해서만 성능이 좋다거나, 반대로 딱 test set에 대해서만 성능이 안 좋게 나올 수도 있다는 문제가 있다.k겹 교차 검증은 이런 문제를 해결해 머신 러닝 모델의 성능을 조금 더 정확하게 평가할 수 있는 방법이다.
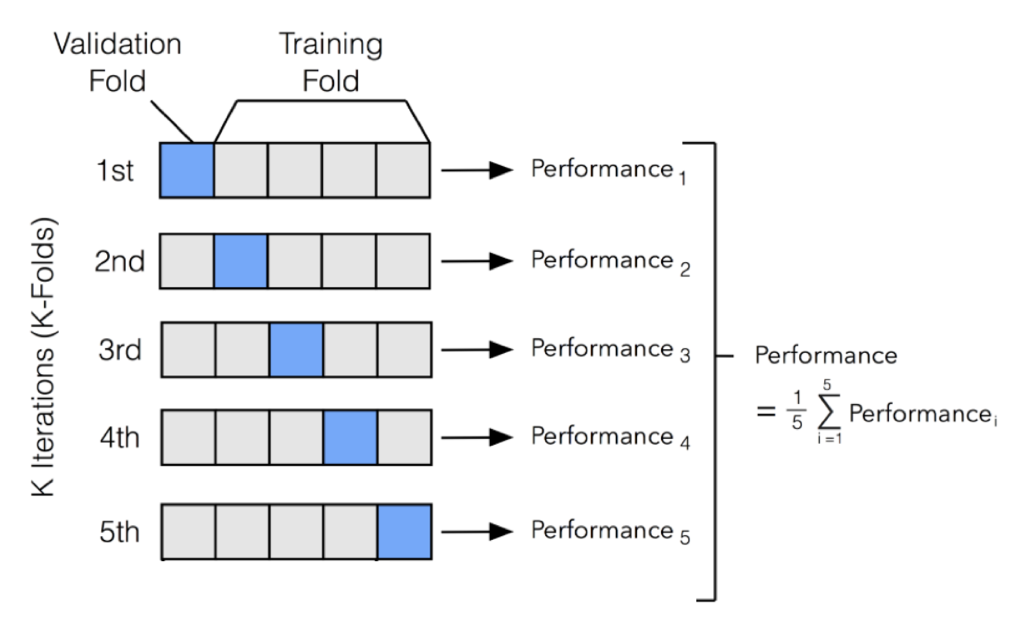 step 1) 전체 데이처를 k개의 같은 사이즈로 나눠준다.
step 1) 전체 데이처를 k개의 같은 사이즈로 나눠준다.
step 2) step 1의 데이터 셋들을 이용해 모델의 성능을 여러 번 검증한다.
step 3) step 2에서 얻은 각 테스트 셋에 대한 성능의 평균을 전체 모델의 성능으로 취급한다.이렇게 모델의 성능을 여러 번 다른 데이터로 검증하기 때문에 평가에 대한 신뢰가 올라간다.
이 때, k는 데이터의 갯수에 따라 달라지지만 일반적으로 5로 지정한다. 또한 데이터가 많을수록 우연히 test set에서만 성능이 다르게 나올 확률이 적기 때문에 작은 k를 사용해도 된다.+) 데이터가 너무 적거나 잘못 되었을때, 알고리즘이 완벽해도 성능이 안좋을 수 있다. 일반적으로 완벽하게 학습을 하려면, 데이터를 traing/test/validation으로 나눠 사용하는데 데이터가 적은 경우는 저렇게 나누는 것이 불가능하다. k겹 교차 검증에서는 모든 데이터가 학습 데이터이자 테스트 데이터로 쓰이기 때문에 데이터를 더 효과적으로 사용할 수 있다.
하이퍼파라미터 고르기
01. 하이퍼 파라미터
- 하이퍼 파라미터(Hyperparameter)
: 머신 러닝 모델을 학습시키기 전에 사람이 미리 정해줘야 하는 변수들
ex) Lasso 모델에서의 alpha와 max_iter
하이퍼 파라미터에 어떤 값을 넣느냐에 따라 모델의 성능에 큰 차이가 있을 수 있기 때문에 모델의 성능을 최대한 높여주는 파라미터를 고르는 것이 굉장히 중요하다.
02. 그리드 서치
-
그리드 서치(Grid Search)
좋은 하이퍼 파라미터를 고르는 방법 중 하나로 매우 직관적이다.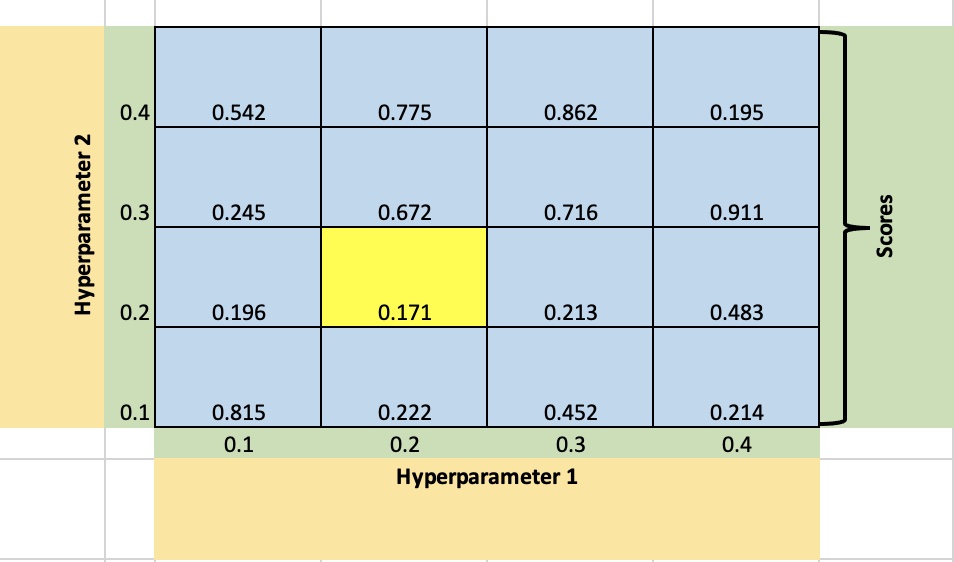
step 1) 정해줘야 하는 각 하이퍼 파라미터에 넣어보고 싶은 후보 값을 몇 개씩 정한다.
step 2) 모든 후보 값의 조합을 모델에 학습시켰을 때의 성능을 k겹 교차 검증을 통해 구한다.
step 3) step 2의 값들 중 성능이 가장 좋았던 하이퍼 파리미터 조합을 고른다.이렇게 표로 grid(격자 모양)를 만들고, 여기서 성능이 가장 좋은 하이퍼 파라미터를 찾는 방법이기 때문에 grid search라 부르고, 하이퍼 파라미터가 2개 이상일 때도 똑같은 방식으로 하이퍼 파라미터 조합을 고르면 된다.
