
📍 강의 자료 출처 : LG Aimers
Ensemble Learning
: 머신러닝에서 알고리즘의 종류에 상관없이 서로 다르거나, 같은 매커니즘으로 동작하는 다양한 머신러닝 모델을 묶어 함께 사용하는 방식
이미 사용하고 있거나 개발한 알고리즘의 간단한 확장으로,
Supervised learning task에서 성능을 올릴 수 있는 방법이다.
다양한 모델들의 각 장점을 살려서 예측 성능을 향상시킬 수 있다. 먼저 학습 데이터 셋을 random하게 부터 까지 나누어서 학습을 진행한다.
먼저 학습 데이터 셋을 random하게 부터 까지 나누어서 학습을 진행한다.
cf> 모두 다른 model로 학습하기도 하지만 같은 model들을 사용하는 경우도 있기 때문에 학습 데이터 셋이 겹치는 것을 지양해야 한다.
이후 각각의 학습 model의 결과에 따라 다수결로 최종 예측을 결정하게 된다.
장점
- 예측 성능을 안정적으로 향상 가능하다
∵ 다양한 여러 개의 model의 결정으로 최종 예측 결과를 제공
→ noise 등으로부터 보다 안정적 - 쉽게 구현이 가능하다
- model parameter의 튜닝이 많이 필요없다
∵ 각 모델들이 독립적으로 동작
단점
- model 자체로는 compact한 표현이 되기 어렵다
Ensemble을 구성하는 가장 기본적인 요소 기술은 bagging과 boosting이 있다.
Bagging (Bootstrapping + Aggregating)
: 학습 과정에서 training sample을 랜덤하게 나누어 선택해 학습하는 방식 original 학습 데이터 를 n개로 나눠 ~ sub sample들을 구성하고 각 sub sample로 각각의 model을 학습시킨다.
original 학습 데이터 를 n개로 나눠 ~ sub sample들을 구성하고 각 sub sample로 각각의 model을 학습시킨다.
→ model을 정량적으로 학습시킬 수 있다.
(∵ 각 sample set이 다른 model에 영향을 미치지 않음)
lower variance의 안정적인 성능을 제공하는데 유용하다.
train sample의 숫자가 적거나 / model이 복잡한 경우에 발생하는 과적합 문제에 대해 sample을 random하게 선택하는 과정에서 data augmentation 효과를 가질 수 있고 간단한 model을 집합으로 사용할 수 있기 때문에 보다 안정적인 성능을 제공할 수 있다.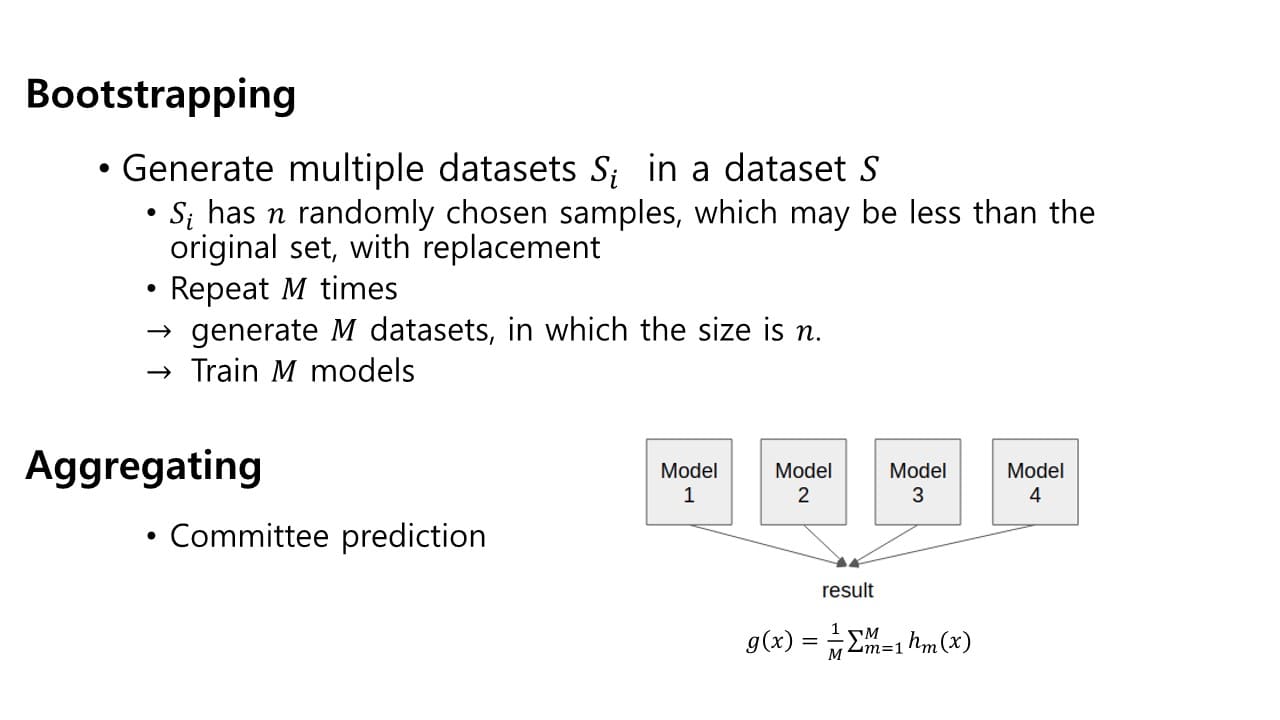
- Bootstrapping
: 다수의 sample data set을 생성해서 학습하는 방식
Boosting
: sequencial한 성질을 이용해 모델의 성능을 높이는 방식
Bagging과 달리 sequencial하게 동작한다.
연속적으로 classifier를 적용하게 되면 이전에 동작한 classifier들의 결과를 현재 classifier의 결과를 향상하는 데 사용할 수 있다.
+) Weak Classifier의 Cascading
- Weak Classifier : Bias가 높은 Classifier로,
모델 자체가 단순해서 strong classifier에 비해 성능이 낮아 혼자서는 무언가를 수행하기 어려운 model
→ weak classifier를 연속적으로 적용한다면 복잡한 sample도 효과적으로 구분할 수 있다.
Adaboost
: basic classifier에 의해 오분류된 sample에 대해 보다 높은 가중치를 두어 다음 학습에 사용할 수 있게 하는 방식
→ 이전 classifier들의 실패를 고려한다. 장점
장점
- 간단하게 구현 가능하다
- 특정한 학습 알고리즘에 구애받지 않는다
Random Forest
: Bagging과 Boosting을 활용하는 대표적인 알고리즘
= Decision tree의 집합
decision tree는 매 노드에 의해 예측이 이루어지기 때문에 sequencial한 성질을 갖고(Boosting) 이러한 decision tree들을 모아 최종 예측을 한다(Bagging).
Evaluation; Model 성능 평가하기
Supervised learning에서 Model의 성능은 어떻게 평가할까?
-
Accuracy(Model의 정확도) 측정
 이때 각 경우에 대해 오차가 얼마 있었는지 표현하는 방법으로 Confusion matrix를 사용한다.
이때 각 경우에 대해 오차가 얼마 있었는지 표현하는 방법으로 Confusion matrix를 사용한다.
cf> false positive error : 실제로는 negative인데 positive라 예측한 경우 unbalanced data set의 경우, accuracy 외에도 precision과 recall 값을 동시에 보아야 모델의 성능을 제대로 측정할 수 있다.
unbalanced data set의 경우, accuracy 외에도 precision과 recall 값을 동시에 보아야 모델의 성능을 제대로 측정할 수 있다. -
ROC Curve
: 서로 다른 classifier의 성능을 측정하는데 사용하는 지표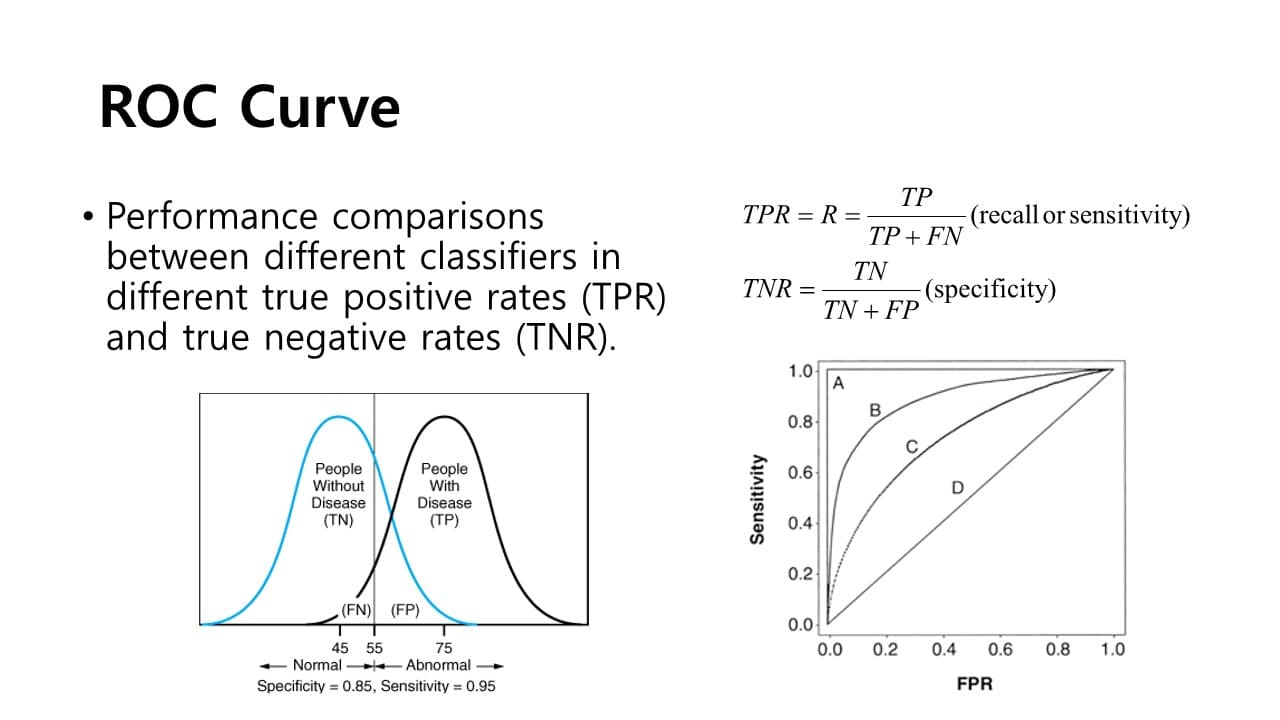
- 가로축 = FPR = (1 - TPR)
- 세로축 = sensitivity = recall
서로 다른 classifier에 대해 여러 개의 ROC Curve를 그렸을 때 왼쪽 상단으로 갈수록 좋은 성능을 의미한다.
