
📍 강의 자료 출처 : LG Aimers
1. 인과성에 대한 소개와 인과적 추론을 하기 위한 기본 개념
인과성 (Causality)
: 하나의 어떤 무엇인가가 다른 무엇을 생성함에 있어 영향을 미치는 것
인과성이 인공지능, 기계학습, 데이터사이언스와 어떤 연결고리가 있을까?
인공지능에 대한 일반적 정의를 보면, '에이전트(소프트웨어, 로봇 등)가 목표를 성취하기 위해 합리적인 액션을 취하는 것'이라 할 수 있다.
→ 환경에 변화를 줘서 원하는 상태로 변화시키는 인과관계로 해석 가능하다.
기계학습은 보통 '데이터의 상관성'을 학습한다.
데이터사이언스는 풀고자 하는 질문에 따라 다르겠지만 결과적으로 상관성과 인과성을 모두 복합적으로 고려한다.
+) Pearl 교수의 인과 계층
- level 1. Associational or Observational
: 가장 기본적인 "관측" 계층으로, 시스템을 구성하고 있는 변수들의 상관성을 알 수 있다. - level 2. Interventional or Experimental
: "실험" 계층으로, 시스템을 중재(인터벤션)함으로써 나오는 결과를 파악하고자 한다. - level 3. Counterfactual
: 관측 값과 실험에 의한 값을 동시에 고려하는 반사실적 계층
데이터를 분석하고자 할 때 2가지 사항을 고려해야 한다.
- 주어진 데이터가 상관성을 지니고 있는지 아니면 인과성을 지니고 있는지
- 알고자 하는 질문이 단순히 조건부 확률과 갘은 상관성이 관한 것인지, 인과성에 관한 것인지
Structural Causal Model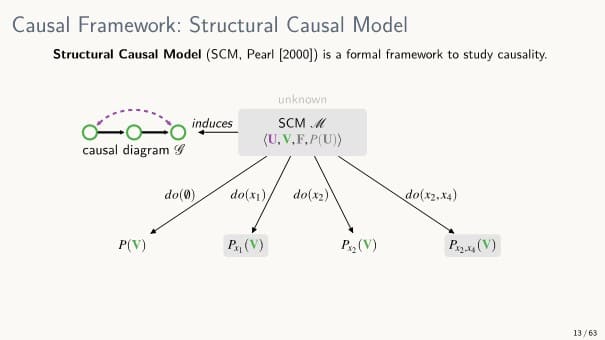
실제 시스템을 수학적으로 추상화한 모델로,
관측 가능한 모든 변수 를 생성하는 인과적 매커니즘을 정리하고 있다.
이 모델을 기반으로
- 어떠한 중재도 하지 않았을 경우 관측 가능한 모든 변수들에 대한 관측 분포를 볼 수 있다.
- 임의의 변수를 중재하는 경우(= 어떤 실험을 한다면) 실험에 대한 결과 분포가 나올 것이다.
중재
변수 를 중재한다 = 해당 변수의 함수값을 임의의 상수로 고정한다
→ 대신 임의의 상수 로 고정한 submodel을 정의한다.
⇒ 인과: 임의의 변수 집합 가 있고 이 집합 가 고정되었을 때 우리가 관심을 가지는 변수들 가 특정 값을 가질 확률은 어떻게 될 것인가
→ 또는
d-seperation
: 그래프에서 조건부 독립성을 읽어낼 수 있는 알고리즘



