
📍Attention Is All You Need (원문)
❗️개념을 정리하기 위해 작성한 글로, 내용상 잘못된 부분이 있을 수 있다는 점 참고 바랍니다.
논문에서는 순서가 아래와 같이 구성되어있다.
- Introduction
- Background
- Model Architecture
- Encoder and Decoder Stacks
- Attention
- Scaled Dot-Product Attention
- Multi-Head Attention
- Application of Attention in our Model
- Position-wise Feed Forward Networks
- Embeddings and Softmax
- Positional Encoding
- Why Self-Attention
- Training
- Training Data and Batching
- Hardware and Schedule
- Optimizer
- Regularization
- Results
- Machine Translation
- Model Variations
- Conclusion
이 글은 논문 순서를 그대로 따라가기보다는 내가 공부할 때 이해하기 편했던 흐름대로 작성하려고 한다.
기존 Sequence-to-Sequence 모델
+) sequence modeling : 입력 sequence가 들어오면 또다른 sequence를 가지는 데이터를 생성하는 task
RNN, LSTM, GRU와 같은 seq2seq 모델은
- 모든 데이터를 한 번에 입력 받아 처리 (X)
- sequence position 에 따라 순차적으로 입력 받아 처리 (O)
따라서 시점의 hidden state 가 시점의 hidden state를 계산할 때 사용된다. 이는 매 단어마다 생성되는 hidden state가 그 전 시점의 sequence 정보를 함축하고 있다는 장점이 된다.
하지만 입력을 순차적으로 받아 처리하기 때문에 아래와 같은 한계가 존재한다.
- sequence 길이가 길어지면 memory와 computation 부담 증가
- 각 단어에 대해 앞으로만 전파 → 모든 단어들 간의 관계성 파악 어려움
특히 sequence 길이가 길어질 때 발생하는 long-term dependency problem가 seq2seq 모델의 가장 큰 한계이다.
Transformer
Transformer는 기존 seq2seq 모델의 이러한 한계를 개선하고자 고안되었다. Attention 매커니즘만으로 구성된 모델로, input과 output 데이터에서 sequence distance와 무관하게 서로간의 dependencies만을 사용하여 모델링한다.
+) Attention은 transformer에서 처음 제안된 개념이 아니다. Transformer 이전에 RNN과 Attention을 결합하여 사용하기도 했다. 하지만 Transformer가 주목 받은 이유는 recurrent layer 없이 attention 매커니즘만으로 구성되었기 때문이다.
Attention
: 문맥에 따라 집중할 단어를 결정하는 방식
Encoder-Decoder 구조에서 context vector를 사용할 때 정보가 소실되는 문제를 개선하고자 Attention을 도입했다.
📍 3. Attention [초등학생도 이해하는 자연어처리]
 📚 블로그 참조 (Reference에 출처 표시하였습니다)
📚 블로그 참조 (Reference에 출처 표시하였습니다)
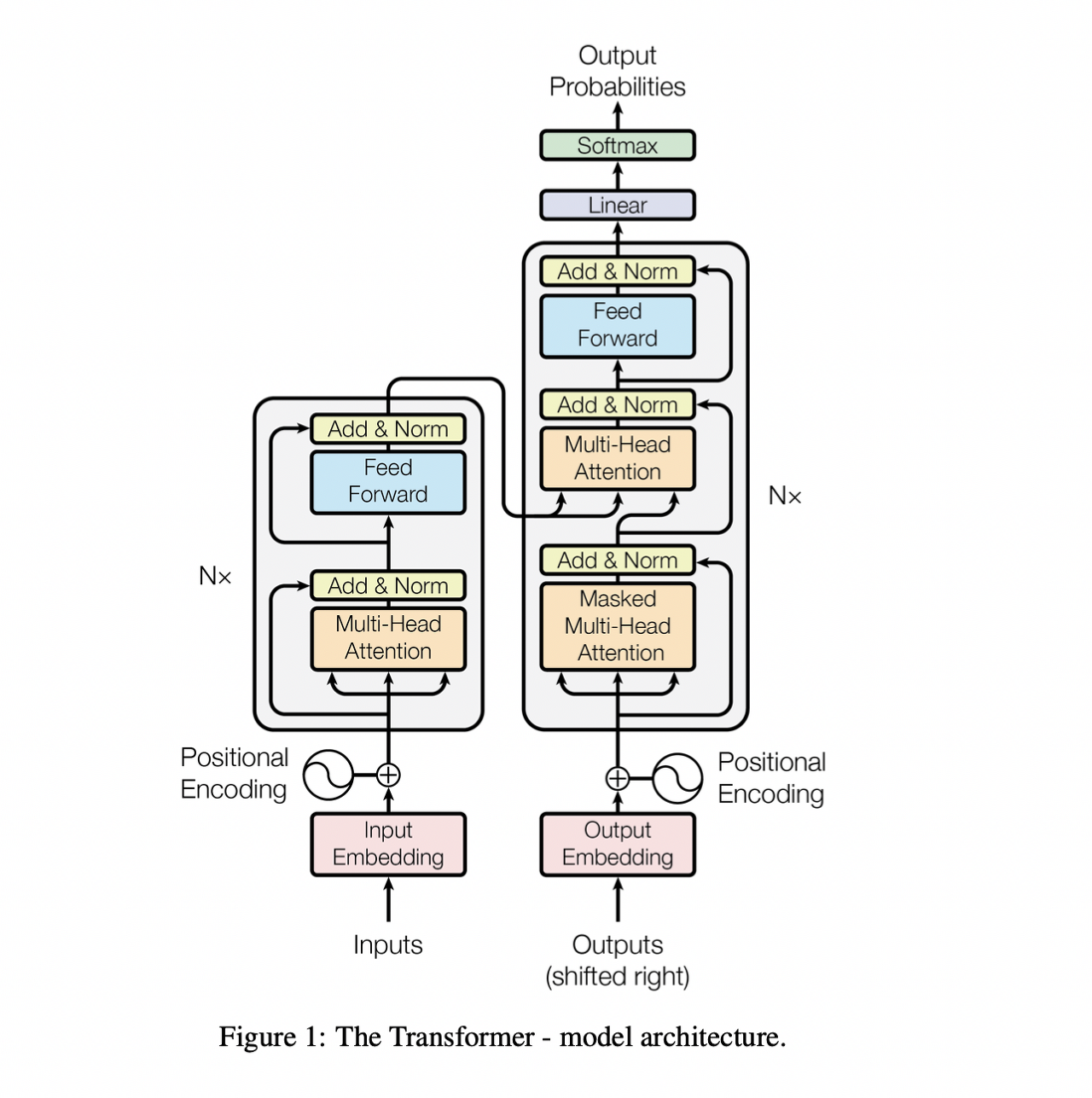
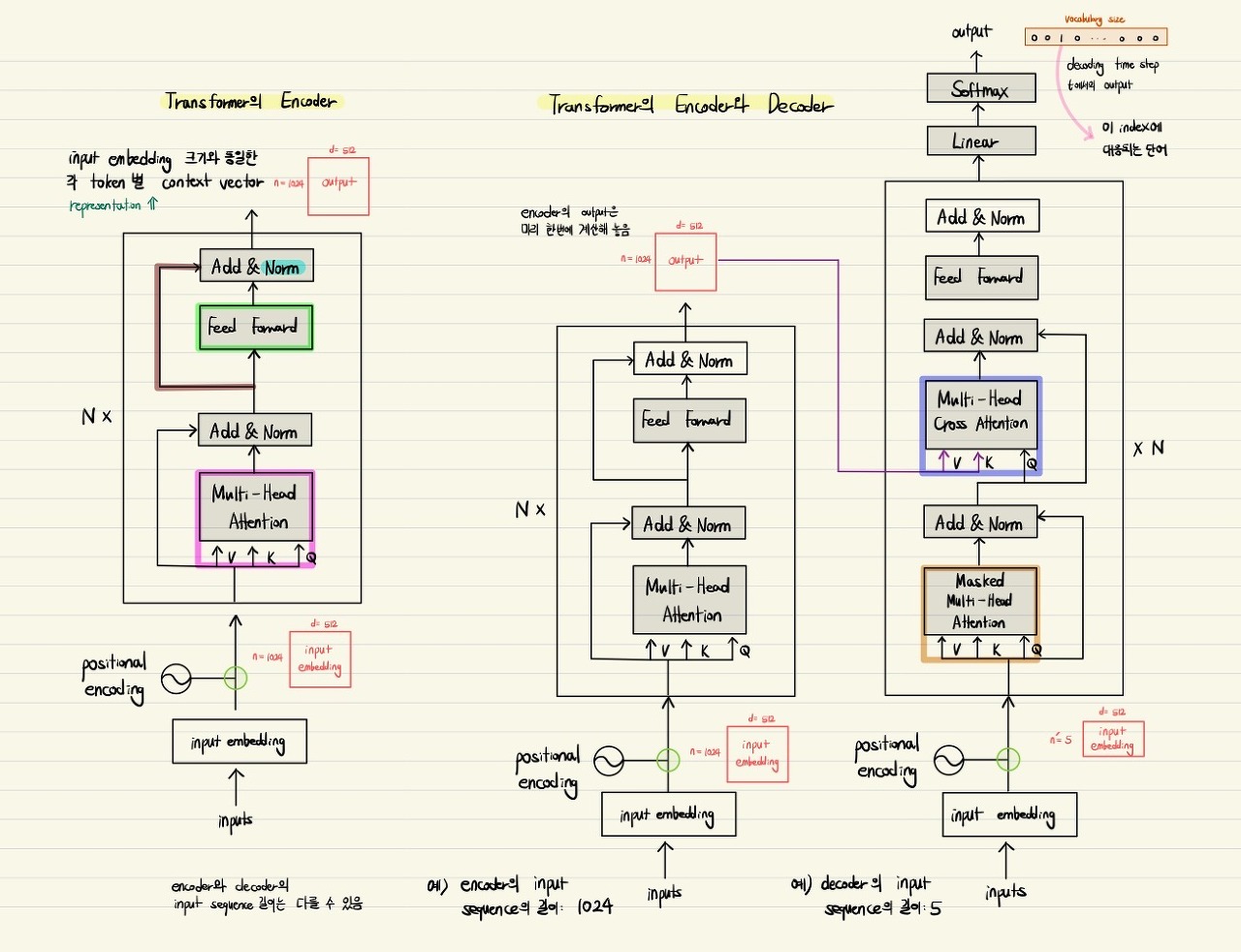
Transformer는 seq2seq모델과 마찬가지로, Encoder + Decoder 구조로 이루어져 있다. 이때 Encoder와 Decoder의 내부는 recurrenct layer나 convolution layer 없이 self-attention layer와 fully connected layer로만 구성되어 있다.
Encoder
Input Embedding
단어를 숫자값을 갖는 벡터 형태로 변환하는 과정이다. 단어들 간의 dependencies를 계산하기 위해서는 이 과정을 거쳐 숫자로 이루어진 벡터를 만들어야 한다.
Positional Embedding
Transformer는 입력 sequence를 한 번에 받아 처리하기 때문에 순서 정보를 고려하지 않는다. 하지만 번역, 요약, 단어 분류 등의 task를 수행할 때 입력되는 단어의 순서에 따라 결과가 크게 바꾸는 경우가 빈번하기 때문에 순서 정보는 반드시 고려해야 할 사항이다.
따라서 전체 입력 sequence에서 단어별 위치 정보를 각 단어의 임베딩 벡터에 추가하고자 positional encoding을 수행한다.
논문에서 사용한 positional encoding 방식은 아래와 같다.
- 짝수번째 원소 =
- 홀수번째 원소 =
주기함수를 사용하는 이유
📍 Transformer와 Nerf에서의 Positional Encoding의 의미와 사용 목적
- positional encoding한 결과 값의 범위를 [-1, 1]로 제한하여 단어가 가지는 기존의 의미에서 많이 벗어나지 않도록 하기 위해
- 주기함수의 frequency를 다양하게 줌으로써 임의의 두 위치에 대해 positional encoding 결과가 겹칠 확률을 줄이기 위해
ex)My favorite fruit is an Applevs.Apples grown from seed tend to be very different from those of their parents, and the resultant fruit frequently lacks desired characteristics.
→ 두 문장에서 Apple에 대해 positional encoding을 할 때, 같은 단어이지만 위치 정보가 매우 다르다. 따라서 이를 고려하기 위해 주기함수를 사용한다.
Multi-Head Attention
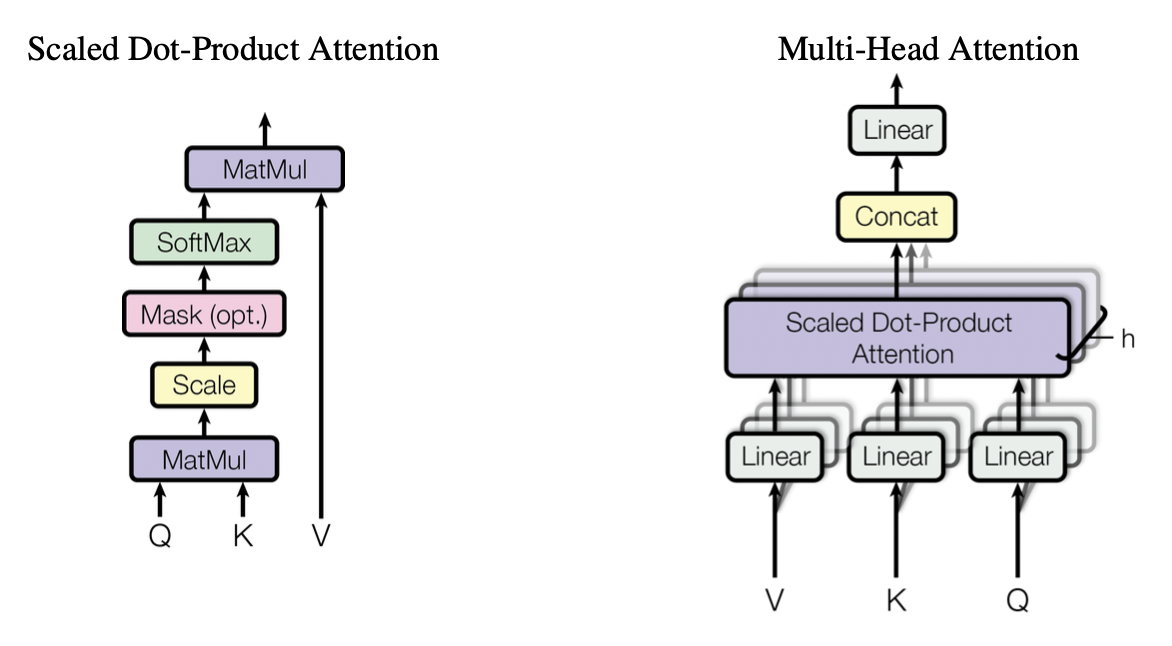
1. Scaled Dot-Product Attention
Scaled Dot-Product Attention이 수행되는 과정은 아래와 같다.
step 1) (어떤 단어 벡터 : Q) · (문장의 모든 단어 벡터를 모아둔 행렬 : K)
→ relation vector가 생성된다.
step 2) 를 로 나눠 scaling
→ 이후 softmax 시 벡터 내의 값들이 0 근처로 모이면서 gradient가 커지도록 만들어준다.
(softmax 시 값이 1 근처이면 gradient가 작아져 학습이 제대로 수행되지 않을 수 있음)
step 3)
→ 단어(Q)가 모든 단어들과 어느 정도 correlation이 있는지 확률분포의 형태로 변환해준다.
step 4) 에 행렬 를 곱한다.
⇒ 결과적으로 기존 벡터에 Q와 K 간의 correlation 정보를 더한 vector가 생성되고, 이것이 단어의 encoding vector이다.
"Self" Attention
📍 4-1. Transformer(Self Attention) [초등학생도 이해하는 자연어처리]
- Q, K, V의 값이 동일하다 (X)
- Q, K, V의 시작 값이 동일하다 (O)
⇒ 동일한 입력을 받지만 학습 가중치 W, W, W에 따라 최종적으로 생성되는 Q, K, V의 값은 각각 다르다.
2. Multi-Head Attention
동일한 입력을 가지고 여러 개의 head로 나누어 동시에 병렬적으로 Self-Attention을 수행한다.
따라서 Q, K, V의 시작 값은 동일하지만, 이 입력을 선형변환하는 파라미터 W, W, W가 각 head별로 달라 구해지는 encoding vector가 head별로 다르다.
이때 파라미터의 수를 줄이기 위해 Q, K, V 행렬의 크기를 줄이는데, 그 식은 아래와 같다.
따라서 MHA란,
- input 자체를 여러 개의 작은 차원으로 slice (X)
- input으로부터 Q, K, V를 만드는 변환행렬인 W, W, W의 output 차원을 줄여 그 Q, K, V에 관해 self-attention을 수행 (O)
⇒ 어떤 한 단어에 대해 서로 다른 기준으로 여러 관점에서의 정보를 추출할 수 있고 이 과정을 병렬적으로으로 수행할 수 있다.
Residual Connection & Layer Normalization
Residual Connection (= Skip Connection)
sub layer 결과에 원본 input을 더해주어 층이 깊어질수록 원본 input에 대한 정보가 손실되는 것을 방지한다. 이 결과, 역전파 시 gradient vanishing 문제를 줄일 수 있다.
Layer Normalization
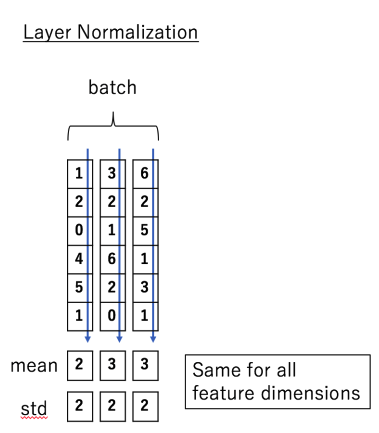
 각 instance별로 feature의 평균과 분산을 구해서 그 feature 자체를 정규화한다. 이 결과, 다수의 sample에 대해 평균 = 0, 분산 = 1인 분포로 변환할 수 있다.
각 instance별로 feature의 평균과 분산을 구해서 그 feature 자체를 정규화한다. 이 결과, 다수의 sample에 대해 평균 = 0, 분산 = 1인 분포로 변환할 수 있다.
Feed Forward
앞선 layer들에서는 '선형변환'만 수행되기 때문에 활성화함수 ReLU를 포함하여 비선형성을 추가해준다.
Decoder
Masked Multi-Head Attention
Decoder에서 self-attention을 수행할 때 QK에 masking을 적용한다. 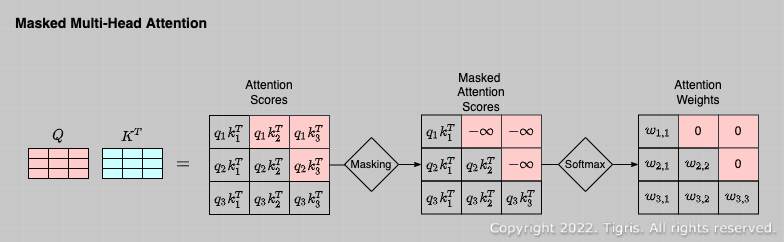 masking : 미래 시점 단어 부분인 행렬 상단에 로 설정하여 QK에 곱해준다.
masking : 미래 시점 단어 부분인 행렬 상단에 로 설정하여 QK에 곱해준다.
⇒ Decoder에 입력되는 문장의 각 단어에 대해 Q, K, V를 만들어서 단어별 encoding vector를 만들 때 앞 단어의 encoding vector가 미래 시점의 정보는 반영하지 못하도록 한다.
Multi-Head Attention
Encoder의 Q, K, V는 모두 동일한 입력으로부터 생성되는 반면, Decoder의 Q, K, V는 입력이 서로 다르다. 이 경우를 Encoder-Decoder attention이라 한다.
Q : Decoder의 이전 layer에서 얻은 decoder embedding
K, V : Encoder에서 얻은 embedding
⇒ ground truth의 각 단어들이 encoder의 입력으로 주어지는 입력 문장에서 어떠한 단어에 더 주목할 지 구하고, ground truth 문장의 각 단어를 encoding할 때 입력 문장에서 어떤 단어의 encoding vector를 더 많이 반영할지 가중평균을 구하는 과정이다.
Training
Optimizer
Adam optimizer를 사용하였고, 학습률 스케쥴러(lr scheduler)를 사용하여 동적으로 학습률을 변화시켰다.
- 학습 초반 : 작게 → 극소에 도달했을때 너무 쉽게 벗어나지 않도록
- 학습 중 iteration이 늘어날수록 : 도 비례하여 증가 → 학습 속도를 빠르게 할 수 있도록
- 특정 iteration 임계점에 도달 : 을 서서히 줄임 → global minima에 근접했음에도 이 너무 커서 쉽게 빠져나오는 현상을 막도록
Regularization
가 너무 큰 값을 가지지 않도록 (= 모델 복잡도를 낮추도록) 하여 overfitting을 방지하는 방법이다. 이 논문에서는 총 3가지 규제 기법을 사용하였다.
Residual Dropout
- 각 sub layer(self-attention layer, FFN layer)의 output에 dropout 적용하기
- embedding 벡터와 positional encoding 벡터의 합(summation)에 dropout 적용하기
Label Smoothing
- 학습 과정 중 label smoothing 적용하기
label smoothing
📍 라벨 스무딩(Label smoothing), When Does Label Smoothing Help?
: hard label (0 또는 1로 binary encoding된 label) → soft label (0 ~ 1 사이의 값을 갖는 label)로 변환하는 방식
Why Self-Attention
-
the total computational complexity per layer (layer 당 전체 계산 복잡도)
sequence length < representation dimensionality 이면 self-attention이 RNN보다 complexity가 낮다. 이때, 대부분의 경우가 < 에 해당한다. -
the amount of computation that can be parallelized (sequential 병렬 처리가 가능한 계산량)
- RNN : input을 순차적으로 받아 번의 RNN cell을 거침 →
- Self-Attention : input의 모든 position 값들을 한 번에 처리 →
-
the path length between long-range dependencies in the network
- Self-Attention : 각 token이 모든 token들과 참조하여 그 correlation 정보를 구해서 더함
→ max path length =
상수 시간으로 매우 작기 때문에 long-range dependencies를 쉽게 학습할 수 있다.
- Self-Attention : 각 token이 모든 token들과 참조하여 그 correlation 정보를 구해서 더함
References
📍 Attention is all you need paper 뽀개기
📍 [논문 리뷰] Transformer 논문 리뷰 (Attention Is All You Need)
📍 [Paper review] Attention 설명 + Attention Is All You Need 리뷰
📍 [Paper] Attention is All You Need 논문 리뷰
📍 [논문정리] Attention is all you need
📍 Attention Is All You Need 논문 리뷰
📍 Self-Attention is not typical Attention model
📍 [논문 스터디 Week 4-5] Attention is All You Need
