[Review] BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding
Review

📍 BERT: Pre-training of Deep Bidirectional Transformers for
Language Understanding (원문)
❗️개념을 정리하기 위해 작성한 글로, 내용상 잘못된 부분이 있을 수 있다는 점 참고 바랍니다.
논문에서는 순서가 아래와 같이 구성되어있다.
- Introduction
- Related Work
- Unsupervised Feature-based Approaches
- Unsupervised Fine-tuning Approaches
- Transfer Learning from Supervised Data
- BERT
- Model Architecture
- Input/Output Representation
- Pre-training BERT
- Fine-tuning BERT
- Experiments
- GLUE
- SQuAD v1.1
- SQuAD v2.0
- SWAG
- Ablation Studies
- Effect of Pre-training Tasks
- Effect of Model size
- Feature-based Approach with BERT
- Conclusion
이 글은 논문 순서를 그대로 따라가기보다는 내가 공부할 때 이해하기 편했던 흐름대로 작성하려고 한다.
Introduction
BERT는 unlabeled data를 MLM(Mask Language Model)과 NSP(Next Sentence Prediction)을 거쳐 pre-train시킨 후
얻은 pre-trained parameter를 task에 맞는 labeled data로 fine-tuning하며 업데이트하는 방식이다.
사전 학습은 token-level task와 sentence-level task 같은 NLP 분야에서 좋은 성능을 보여주었다.
이러한 사전 학습은 두 가지 방식으로 적용될 수 있는데, 그 방식은 아래와 같다.
1. Feature-based Approaches
: 사전 학습 단계에서부터 특정 task에 맞게 모델을 학습시키는 경우로, 해당 task에 특화된 모델 구조를 갖는다.
2. Fine-tuning Approaches ✓
: 특정 task에 특화된 파라미터 수는 최소화하고, general하게 사전 학습된 파라미터를 원하는 task에 맞게 fine-tuning해 전체 파라미터들을 업데이트한다.
이 논문에서는 ELMo를 feature-based approach로, GPT와 BERT를 fine-tuning approach로 분류하였다.
feature-based vs. fine-tuning
둘의 차이가 잘 이해가 되지 않았는데 대략적으로 정리하자면, 처음부터 task에 맞게 학습을 시키느냐 / 한 번 학습한 이후 원하는 task에 맞춰 다시 한 번 학습을 시키느냐의 차이인 것 같다. 후에 Transfer Learning도 등장하는데 이 셋의 유의미한 차이를 정리해볼 예정이다.
사전 학습을 할 때는 두 방식 모두 동일한 목적 함수를 사용하는데
전반적인 언어 표현을 학습하기 위해 unidirectional language models을 사용한다.
이때 unidirectional하게 학습한 경우, " 성능 저하 " (especially fine-tuning approach)의 한계가 발생한다.
ex) GPT : left-to-right 방식으로, 현재 토큰이 앞서 나타난 토큰에 대해서만 attention 계산 가능
하지만 Question-Answering 같은 문장 수준 tasks는 양쪽 문맥을 모두 파악해야 함
BERT
: Bidirectional Encoder Representations from Transformers
BERT는 Transformer에서 Encoder 부분이 여러 층 쌓여있는 구조로 이루어져 있다.
왜 Encoder 부분만 사용하였을까?
이에 대해서는 BERT의 목적을 생각하면 알 수 있다.
BERT는 문장을 생성하기 위한 GPT, 기계 번역을 위한 Transformer처럼
특정 task를 위한 모델이라기보다 전반적인 언어의 문맥에 대해 파악하는 데 초점을 맞추었다.
따라서 BERT 자체는 단어의 embedding 정보를 잘 파악하는 용도이다. 그렇기 때문에 Encoder 부분만 사용해 입력에 대한 정보를 함축하는 과정만 거친다.
BERT는 다음과 같은 구조를 가진다.
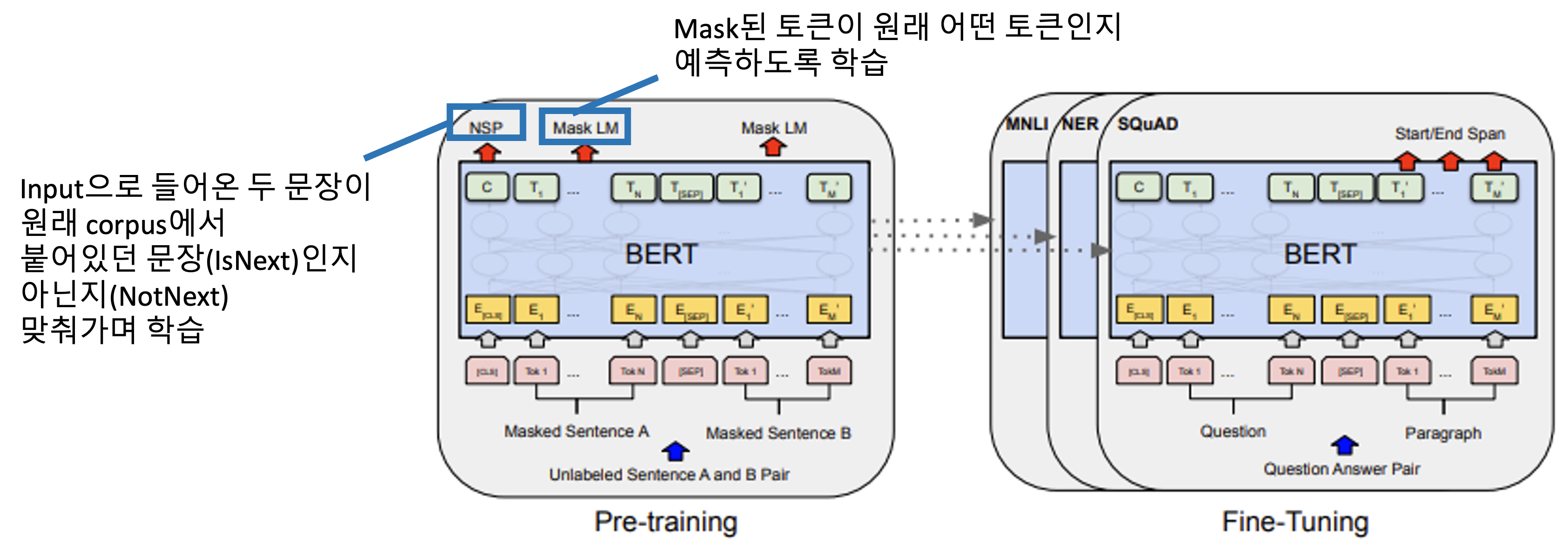
BERT의 framework는 두 단계로 구성되는데
왼쪽 부분의 pre-training step과 오른쪽 부분의 fine-tuning step을 거친다.
따라서 동일한 pre-trained 파라미터로 초기화된 모델에서 시작하여 task에 따라 파라미터가 업데이트되어 결과적으로 서로 다른 fine-tuned 모델을 갖게 된다.
Input / Output Representation
BERT의 입력은 총 3개의 임베딩 벡터가 합쳐진 형태이다.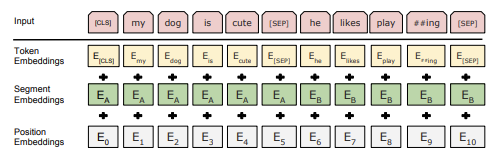
Sequence : 단일 문장 또는 쌍으로 이루어진 문장 (<Question, Answer>)
- 단일 문장 : 분류 task에 주로 사용 ex) 스팸 여부
- 쌍으로 이루어진 문장 : sentence-level task에 주로 사용 ex) Question-Answering
문장이 들어오면
step 1) WordPiece tokenizer로 토큰 임베딩 벡터 생성
step 2) [CLS] 토큰을 각 시퀀스의 첫(시작) 토큰으로 사용
step 3) text-pair가 들어오는 경우 하나의 시퀀스로 표현하기 위해 [SEP] 토큰으로 분리
⇒ 각 문장의 단어 token embedding vector + A/B 중 어떤 문장에 속하는지를 나타내는 segmentation embedding vector + 문장 내에서의 위치 정보를 나타내는 position embedding vector
[CLS]

Positional Encoding vs. Positional Embedding
- Positional Encoding - Transformer의 Encoder에서 사용한 방식
: 각 단어의 위치마다 고유한 값(벡터)을 만들어 내는 적절한 함수를 통해 각 단어의 위치를 설명하는 위치 임베딩 벡터를 만든 뒤, 단어 임베딩 벡터에 더해줌
- Positional Embedding - BERT에서 사용한 방식
: 위치 정보를 표현하기 위해 학습 가능한 추가적인Embedding layer를 사용함
→ 모델이 학습되면서 위치 정보를 어떻게 표현(embedding)하는게 제일 좋은지 스스로 학습함
Pre-training BERT
BERT는 두 가지 Unsupervised tasks를 통해 bidirectional하게 모델을 학습하고자 한다.
1. Masked Language Model
기존 left-to-right / right-to-left 같은 기존의 방식으로 학습을 하게 되면 입력 문장이 들어왔을 때, 간접적으로 예측하려는 단어를 참조하게 되고 multi-layer 구조에서 이전 layer의 output이 전체 문장의 토큰에 대한 정보를 담고 있기 때문에 해당 단어를 예측할 수 있는 간접 참조의 문제가 발생한다.
⇒ 문장에서 일정 토큰을 masking하고 해당 토큰이 구성하는 문장에서 앞뒤 문맥을 파악하여 masking된 토큰의 원래 값을 예측하는 방식
논문에서는 전체 토큰의 15%를 masking 하였는데, 실제 fine-tuning task에서는 [MASK] 토큰이 없기 때문에 pre-training과 fine-tuning 사이의 불일치성이 생기는 문제가 나타났다.
이를 해결하기 위해 15% 중
- 80% : [MASK] 토큰으로
- 10% : 랜덤한 토큰으로
- 10% : 원래 토큰으로
치환하는 방식을 사용하였다. 이렇게 masking된 토큰을 바탕으로 최종적으로는 cross-entropy loss를 사용해 기존의 토큰을 예측하도록 학습을 진행하였다.
2. Next Sentence Prediction
MLM만 거친 경우, 토큰 간 관계를 학습할 수 있지만 문장과 문장 사이의 관계는 학습할 수 없다. 따라서 NSP를 통해 masked language model에 text-pair representation을 학습시킨다.
문장 A와 문장 B를 모델에 넣는데
- 50% : A 다음으로 정답 문장인 B 그대로 제공 (→ IsNext)
- 50% : A 다음으로 랜덤한 문장이 제공 (→ NotNext)
와 같이 입력이 제공된다. 이렇게 주어진 데이터를 바탕으로 두 문장이 서로 연결됐는지 / 아닌지를 학습할 수 있다.
Fine-tuning BERT
앞에서 사전 학습을 마친 BERT는 토큰 간 관계, 문장 간 관계와 같이 전반적인 언어 표현에 대한 정보를 가지고 있다. 이를 원하는 task에 맞는 labeled data로 학습시켜 기존의 pre-trained 파라미터를 업데이트하면 된다.
이 단계는 pre-traing에 비해 상대적으로 적은 시간으로 수행 가능하다.
Conclusion
BERT는 대용량 unlabeled data로 bidirectional하게 모델을 학습시켜 파라미터 값을 얻는다. 이 값은 더 나은 학습의 시작점 역할을 한다. 이후 원하는 task에 맞는 labeled data로 앞서 얻은 파라미터 값을 업데이트한다.
이러한 pre-training → fine-tuning 방식으로 BERT는 11가지 NLP task에서 매우 우수한 성능을 보였다.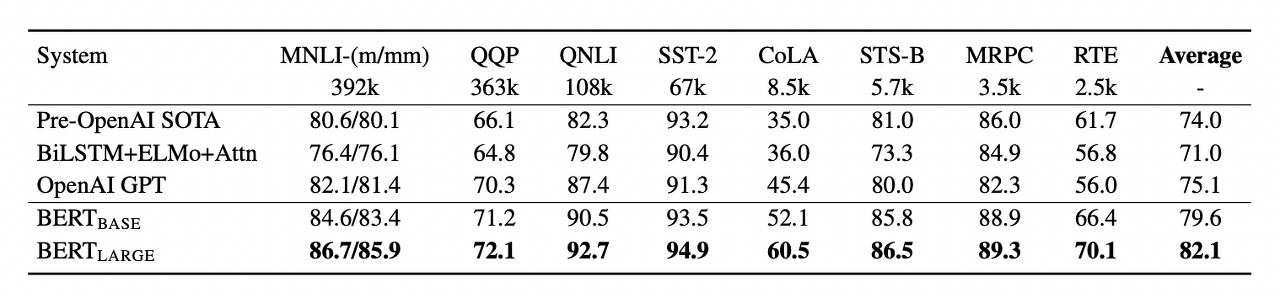 +) 모델의 크기가 클수록 큰 규모의 task에서 지속적인 성능 향상을 보임
+) 모델의 크기가 클수록 큰 규모의 task에서 지속적인 성능 향상을 보임
BERT vs. GPT
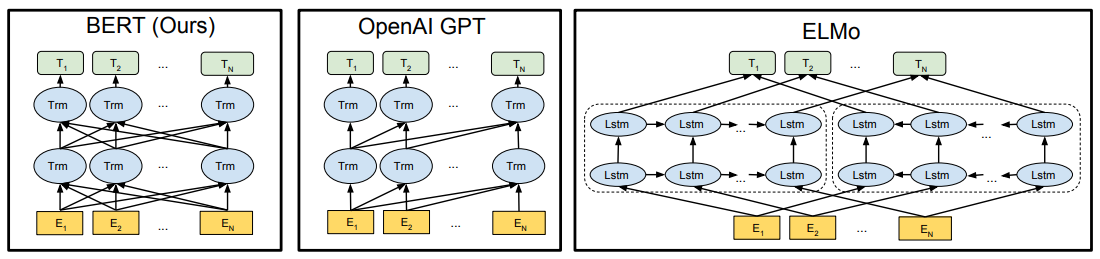
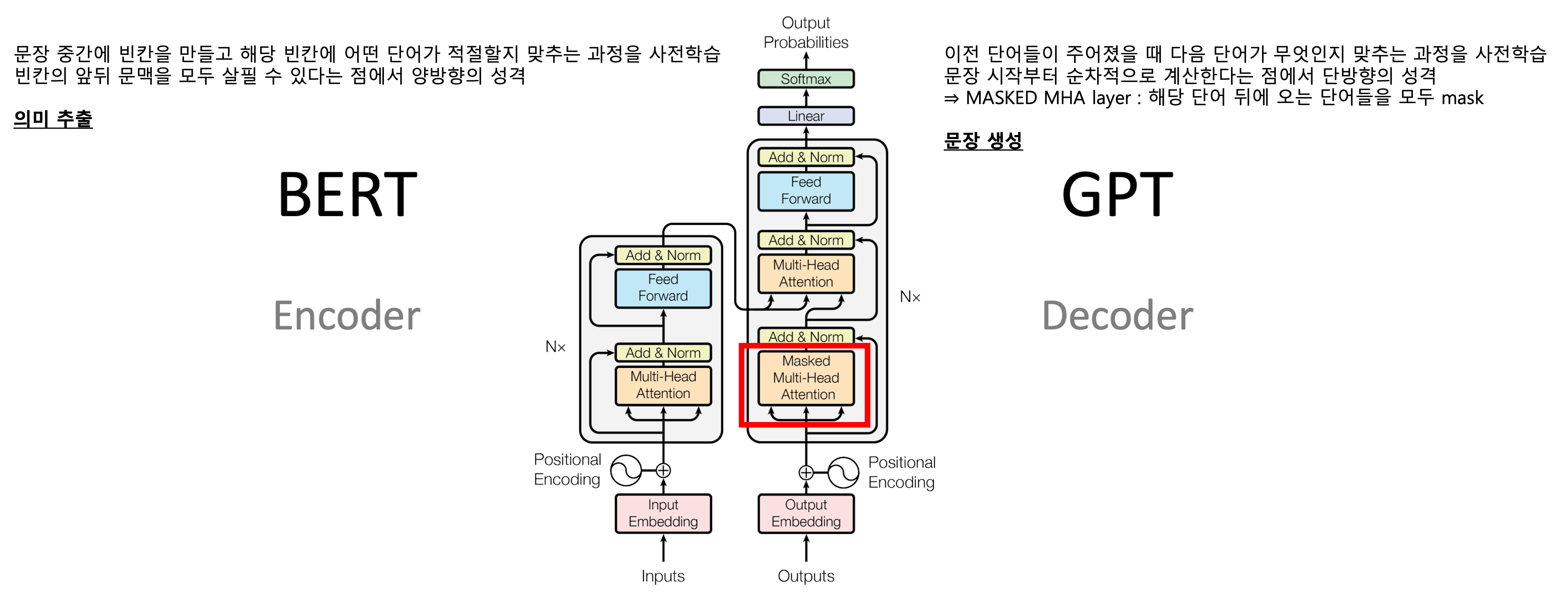
둘 다 Transformer 기반의 모델이지만 목적과 구조가 상이하다.
Transformer는 기계 번역에 특화된 self-attention 기반 모델로,
한-영 번역을 예로 들면
- encoder에서 한국어 문장에 대한 정보를 학습하고
- decoder에서 영어 문장에 대한 정보를 학습해
두 부분을 합쳐 최종적인 번역을 수행한다.
이에 반해 BERT와 GPT는 Transformer의 일부를 가져와 사용한다.
BERT
- self-attention을 통해 bidirectional하게 학습
- 현재 토큰의 좌/우 모두 참조 가능
- transformer encoder만 사용
- 빈칸 예측에 특화됨
GPT
- left-to-right 학습
- 현재 토큰의 왼쪽만 참조 가능
- transformer decoder만 사용
- 다음 단어 예측에 특화됨
References
📍 The Bidirectional Language Model
📍 [최대한 자세하게 설명한 논문리뷰] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (1)
📍 [NLP] 최대한 쉽게 설명한 Transformer
📍 [NLP | 논문리뷰] BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding 상편
📍 [딥러닝을 이용한 자연어처리 입문] 12-02 양방향 LSTM과 CRF(Bidirectional LSTM + CRF)
📍 Paper Dissected: “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding” Explained
📍 Feature-based Transfer Learning vs Fine Tuning?
📍 Large Language Models (LLM): Difference between GPT-3 & BERT
