본격적인 논문 리뷰에 들어가기에 앞서, Deeplab 시리즈에서 사용한 아이디어들을 간단하게 훑어보고 넘어가 봅시다.
Deeplab v1
Paper: SEMANTIC IMAGE SEGMENTATION WITH DEEP CONVOLUTIONAL NETS AND FULLY CONNECTED CRFS
Deep CNN을 사용하게 되면 feature map의 resolution이 계속 압축되어 물체의 위치가 바뀌더라도 좀 더 robust하게 대응할 수 있다는 장점이 있지만, segmentation에서는 이 점이 단점으로 드러나게 됩니다. pixel단위로 labeling작업을 하기에는 압축된 정보가 많아 detail한 정보들이 많이 사라지게 됩니다. 이러한 문제를 해결하기 위해, 이 논문에서는 Atrous Convolution이라는 기법을 사용합니다.
Atrous Algorithm
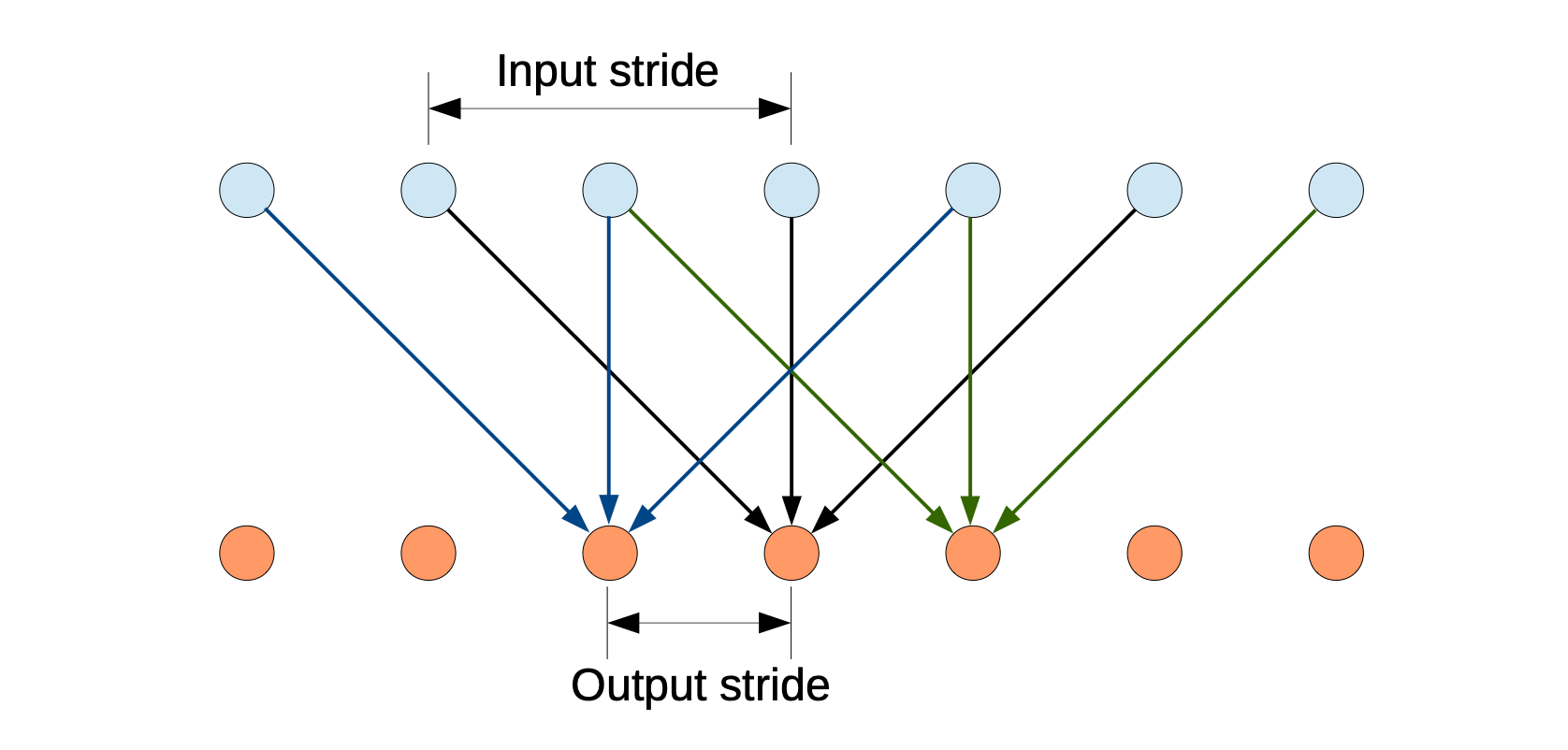
Downsampling 과정에서 일반적인 CNN은 Max pooling이나 stride convolution layer을 거치면서 정보의 압축이 일어나 detail한 정보들이 사라지는 단점을 hole(atrous) algorithm을 제안합니다.
filter의 weight 사이에 0을 넣어주어 좀 더 넓은 reception field를 갖게 하면 output stride를 유지한 채로 기존의 CNN과 유사한 효과를 얻을 수 있습니다.
Fully Connected Conditional Random Field
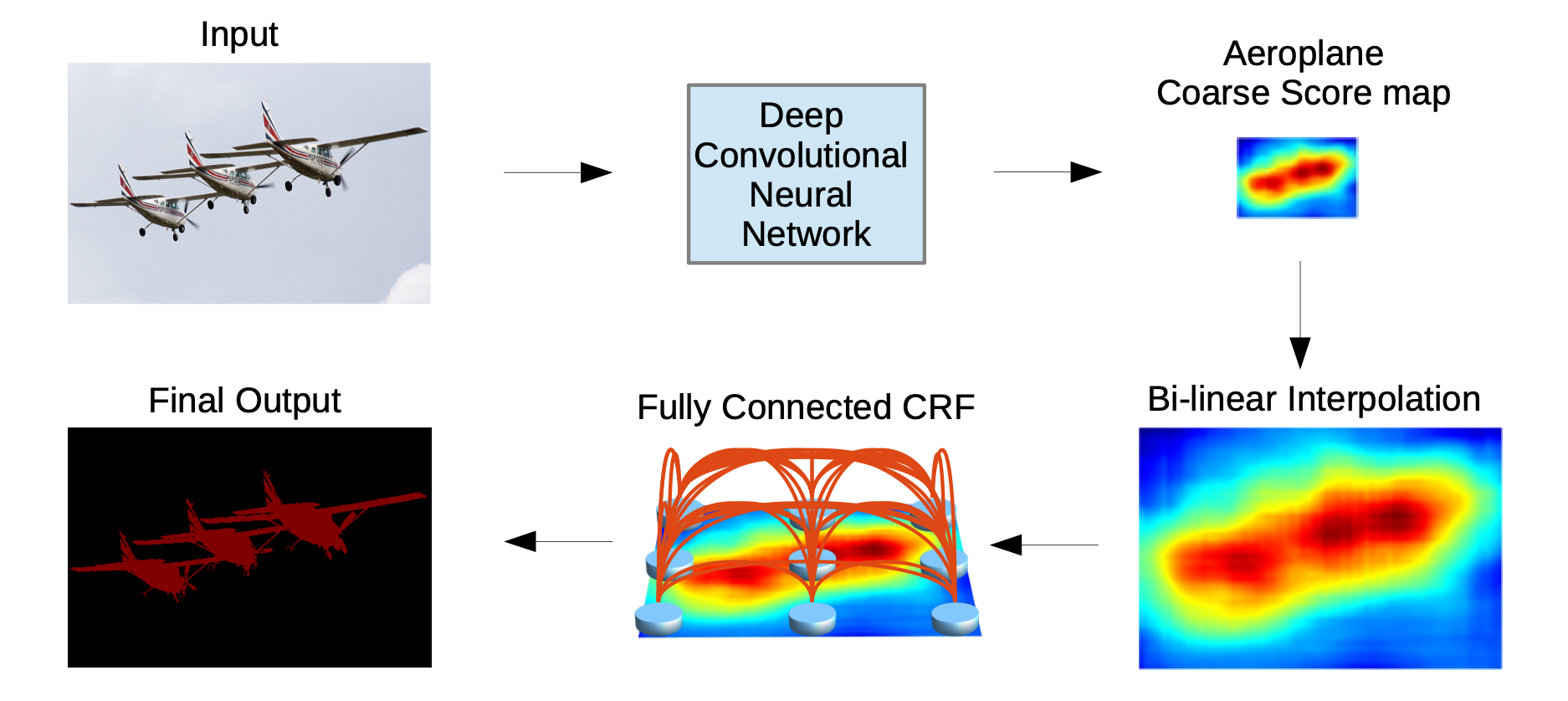
Classification이나 Detection 문제에서는 translation invariance를 만족해야 하기 때문에 CNN을 이용해 높은 성능을 낼 수 있었지만, Segmentation에서는 그렇지 않습니다. 이 부분을 다루어 주기 위해 논문에서는 fully-connected Conditional Random Field(CRF) 방식의 후처리를 제안합니다.
CRF를 수식적으로 완전히 이해하지는 못했고, CNN으로 얻은 각 픽셀의 label 예측값과 픽셀 간의 상호 관계성을 고려하여 detail한 정보들을 얻는 기법인 듯 하다.
다음과 같이 unary term과 pairwise term 두가지로 구성해 사용한다. unary term은 CNN연산을 통해 얻을 수 있으며, 픽셀 사이의 detail한 예측은 pairwise term에서 일어난다.
아래의 pairwise kernel의 수식을 살펴보면 첫번째 kernel은 비슷한 위치와 비슷한 색을 갖는 픽셀들이 유사한 label을 받고, 두번째 kernel은 비슷한 위치의 픽셀들이 유사한 label을 받을 수 있게 해주었다.
이때, 두 픽셀간의 거리가 아무리 멀어도 항상 pairwise term을 계산해주어 fully-connected라는 이름을 붙였습니다. local한 pixel간에만 적용한 local CRF에 비해 훨씬 더 디테일한 segmentation 결과를 얻을 수 있습니다.
CRF에 관한 자세한 설명: http://swoh.web.engr.illinois.edu/courses/IE598/handout/fall2016_slide15.pdf
https://shining-programmer.tistory.com/1
https://m.blog.naver.com/laonple/221017461464
Deeplab v2
Deeplab v1과 거의 유사한 모델을 사용하고, ASPP
라는 모듈이 추가됩니다.
Atrous Spatial Pyramid Pooling (ASPP)
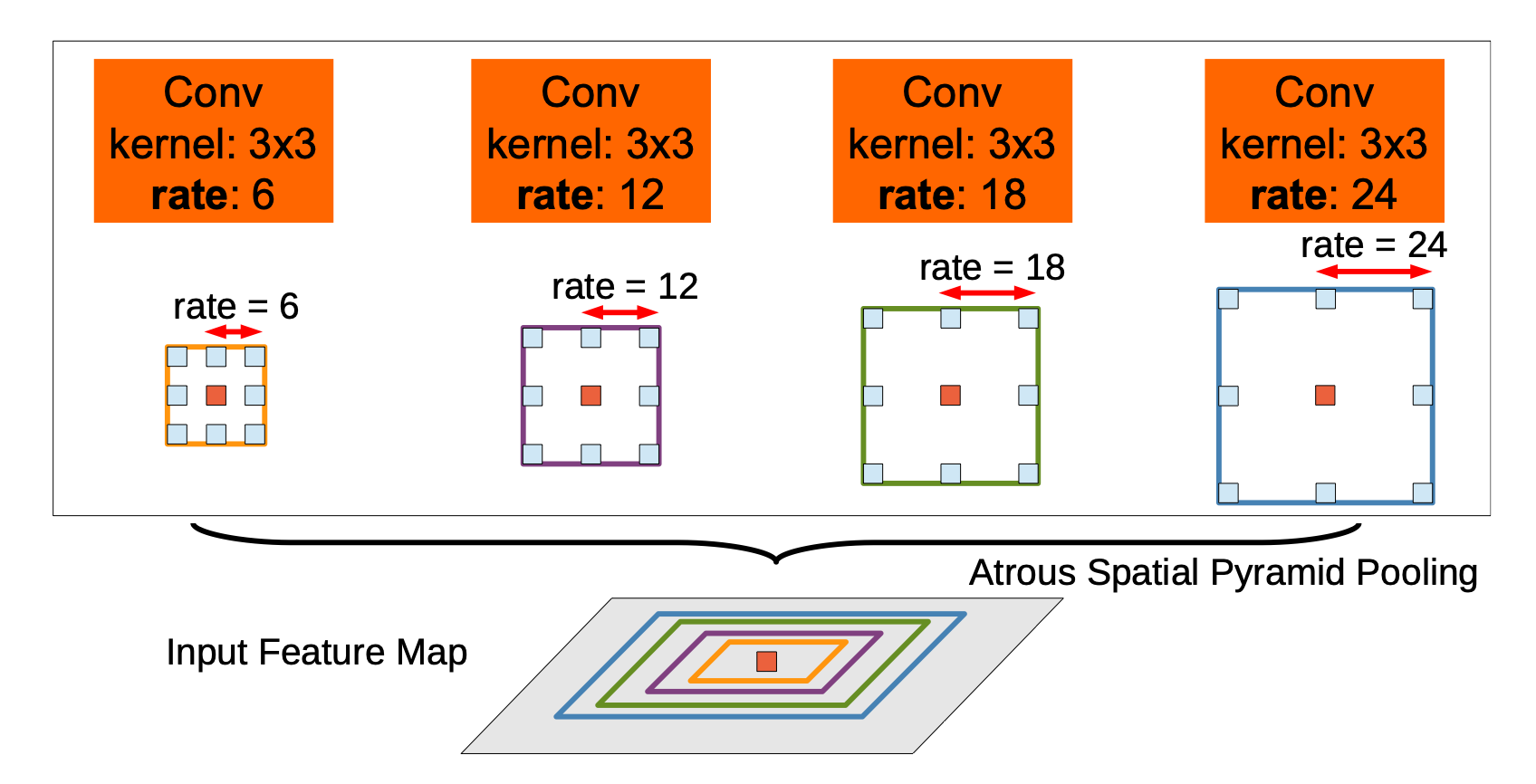
CV에서 많이 사용하는 pyramid 기법으로, FCN의 skip architecture와도 아이디어 자체는 유사합니다. 대신, DeepLab v2에서는 output stride가 다른 feature map을 여러개 사용하는 대신, Atrous Convolution의 dilation rate를 각각 다르게 하여 얻은 feature map들을 합쳐 사용합니다.
Reference
https://kangbk0120.github.io/articles/2022-02/deeplab-series
