Rethinking Atrous Convolution for Semantic Image Segmentation
Paper: Rethinking Atrous Convolution for Semantic Image Segmentation
0. Abstract
기존에 사용하던 Atrous convolution의 스케일을 살짝 변경하여 이전 버전의 문제점을 해결하고 성능을 끌어올렸습니다.
1. Introduction
이전 모델에서는 detail한 정보를 이용하기 위해 atrous convolution을 사용해 문제를 해결했다. 그리고, 다양한 크기의 object를 다루기 위한 기법으로는 다음과 같이 크게 4가지 기법이 있습니다.
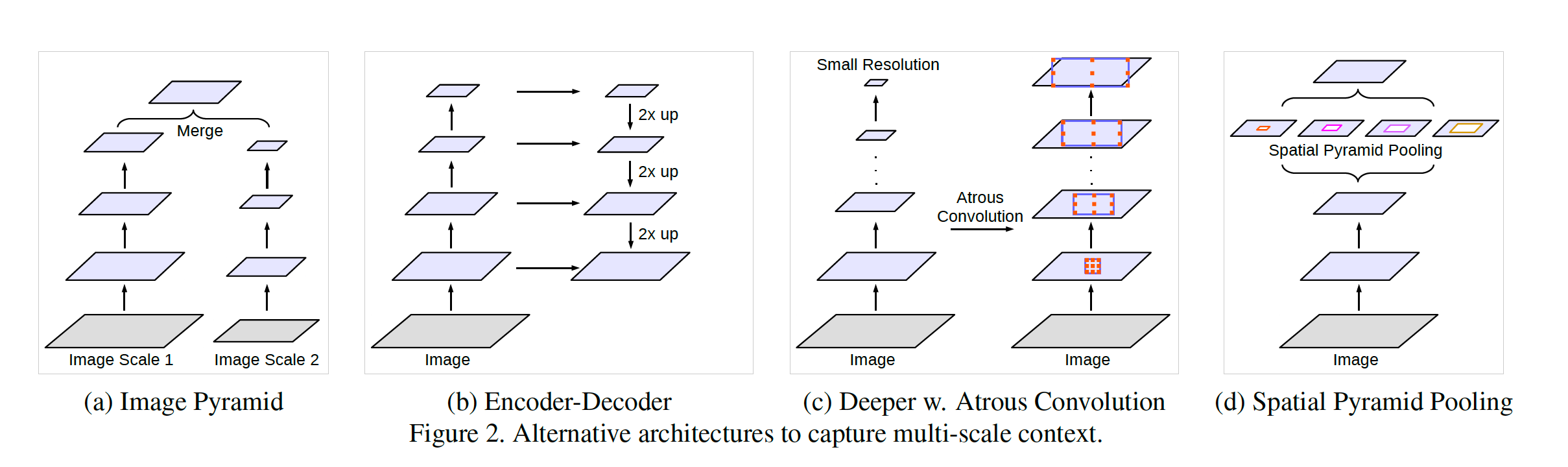
그 중 이번 논문에서는 atrous convolution을 활용한 spatial pyramid pooling 기법인 Atrous Spatial Pyramid Pooling (ASPP)을 사용합니다. 이전 모델에서도 다양한 dilation rate를 가진 3x3 filter을 사용했지만, rate가 매우 커지면 다음과 같이 1x1 convolution과 다를 바 없게 됩니다.

때문에, 이전의 방식을 변형하여 문제점을 개선해 줍니다. 3장에서 자세히 다루어 봅시다.
2. Related Work
- Image pyramid
- Encoder-Decoder
- Context module
- Spatial pyramid pooling
- Atrous convolution
3. Methods
3.1 Atrous Convolution for Dense Feature Extraction
이전에서 계속 설명했다시피, detail한 정보가 압축되어 손실된다는 CNN의 단점을 보완하기 위해 atrous convoliution을 사용합니다.
3.2 Going Deeper with Atrous Convolution
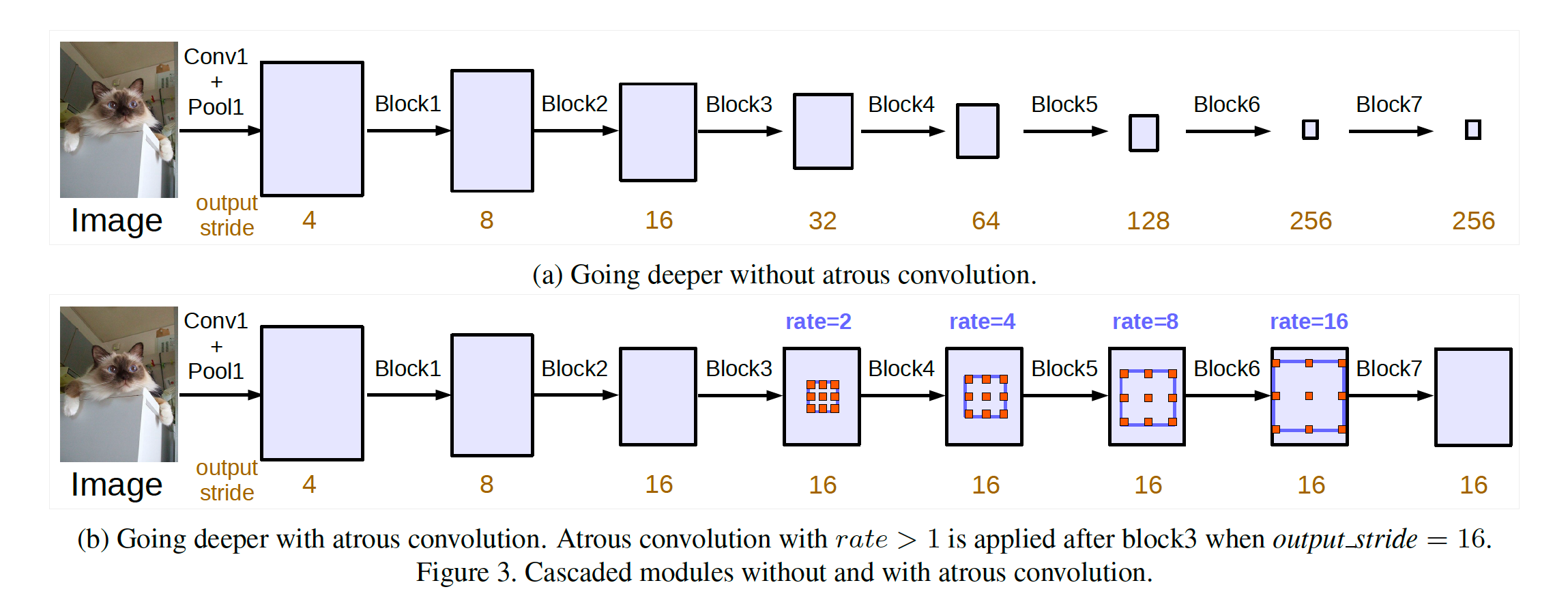
Backbone으로는 ResNet block을 사용하며, 매 block마다 output stride가 2배씩 증가한다. 그 후, atrous convolution을 사용하여 output stride를 유지한 채로 dilation rate만 변경하여 구성한다.
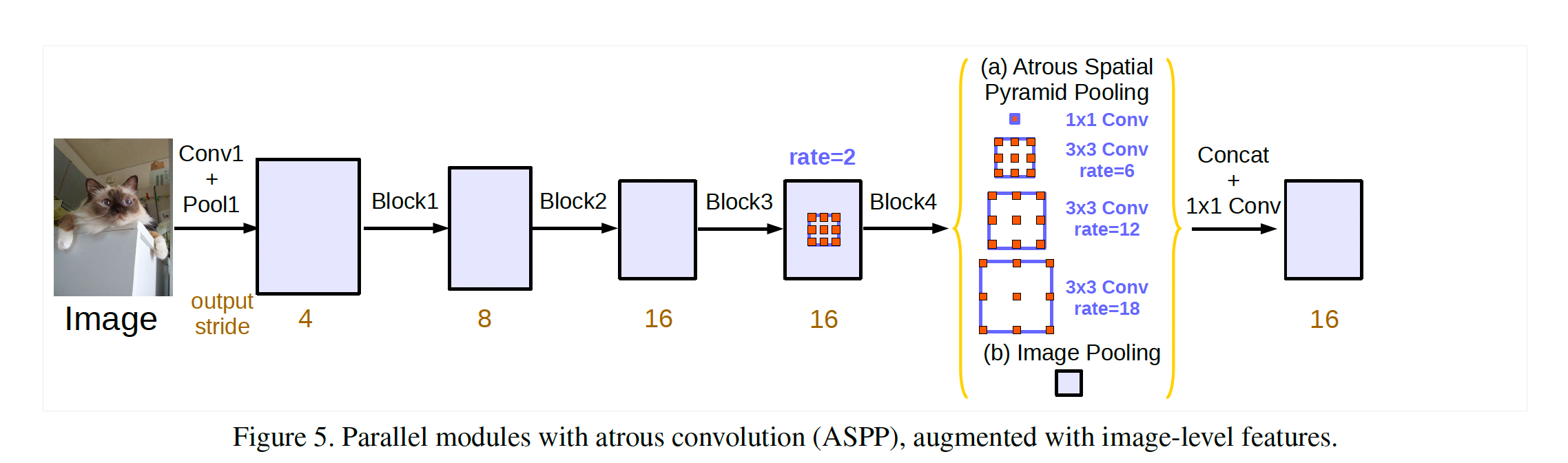
3.3 Atrous Spatial Pyramid Pooling
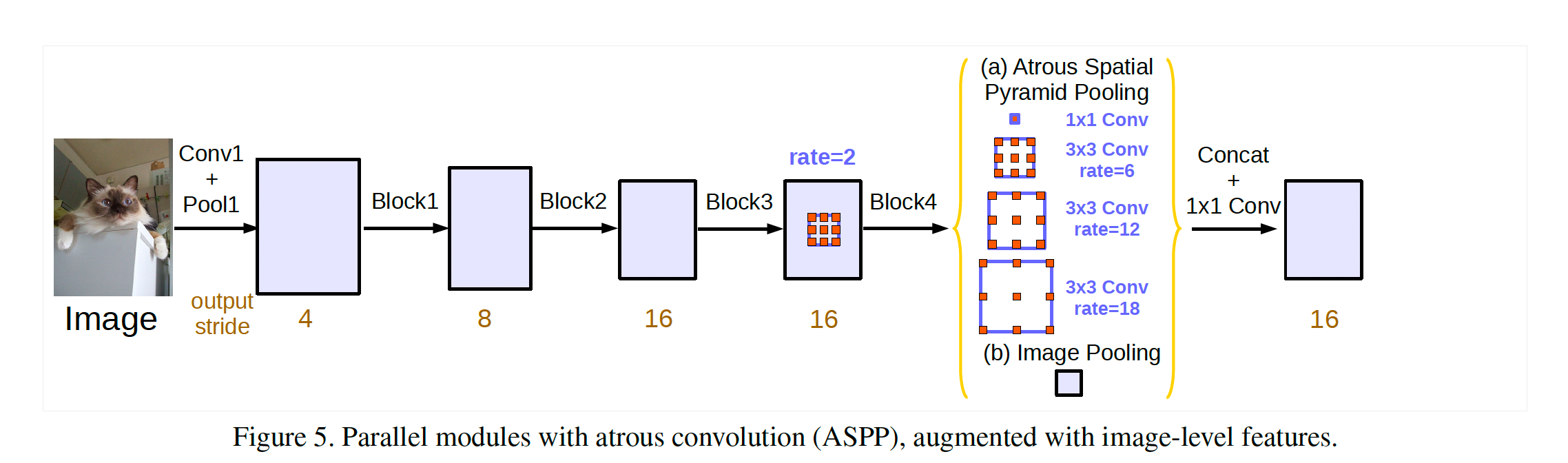
SPP에 atrous convolution을 적용한 ASPP를 사용하면 multi-scale 정보를 유지할 수 있다는 장점이 있지만, dilation rate가 커질수록 유효 filter weight (0이 아닌 weight)가 적어져 결국 1x1 convolution와 같아진다. 때문에, 1x1 convolution을 거친 image-level feature을 추가해 총 4개의 output을 합쳐 사용한다. 그 후 마지막으로 1x1 convolution을 거쳐 최종 output이 나오게 된다. 구체적인 설명은 다음과 같습니다:
① = 1x1 convolution → BatchNorm → ReLu
② = 3x3 convolution w/ rate=6 (or 12) → BatchNorm → ReLu
③ = 3x3 convolution w/ rate=12 (or 24) → BatchNorm → ReLu
④ = 3x3 convolution w/ rate=18 (or 36) → BatchNorm → ReLu
⑤ = AdaptiveAvgPool2d → 1x1 convolution → BatchNorm → ReLu
⑥ = concatenate(① + ② + ③ + ④ + ⑤)
⑦ = 1x1 convolution → BatchNorm → ReLu
4. Experimental Evaluation
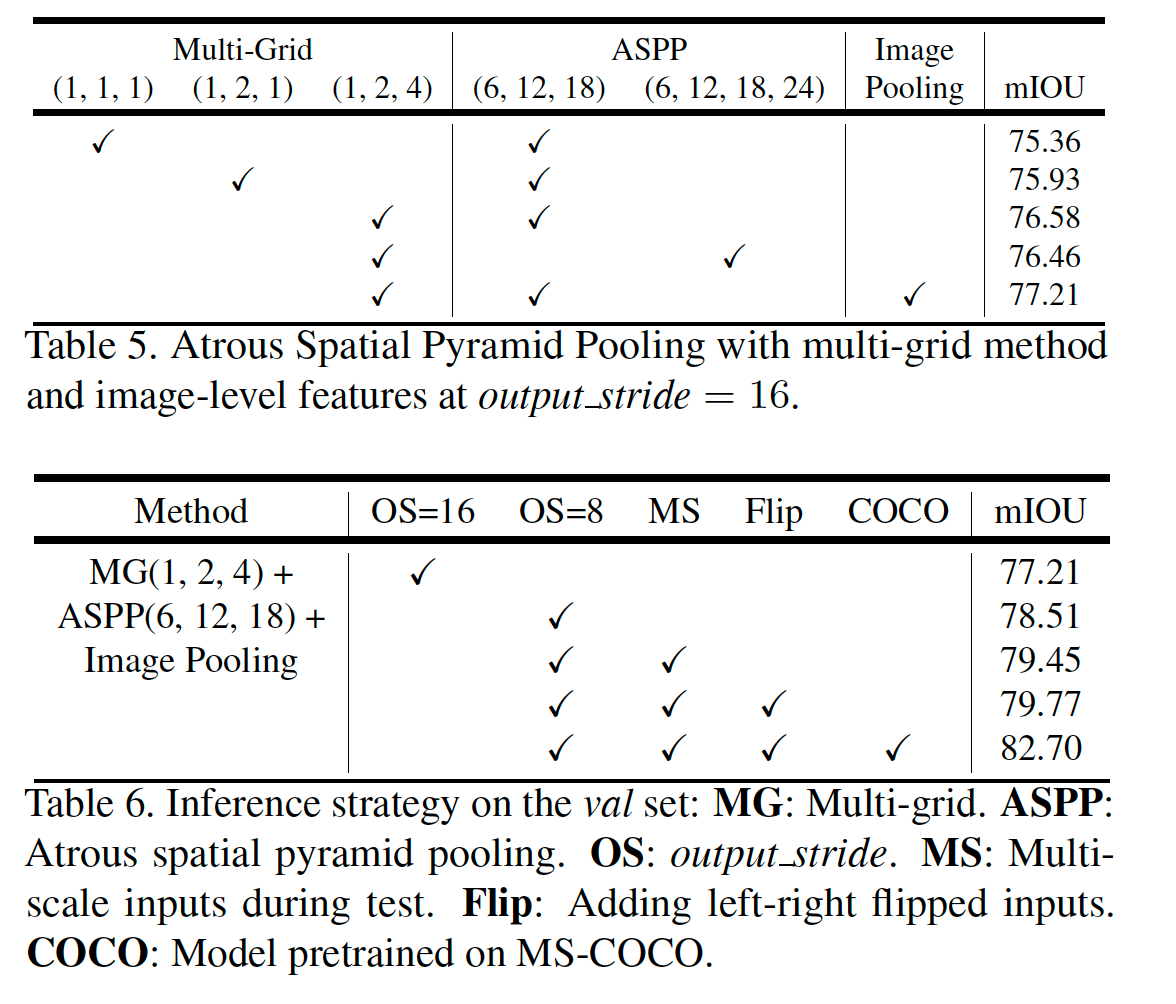
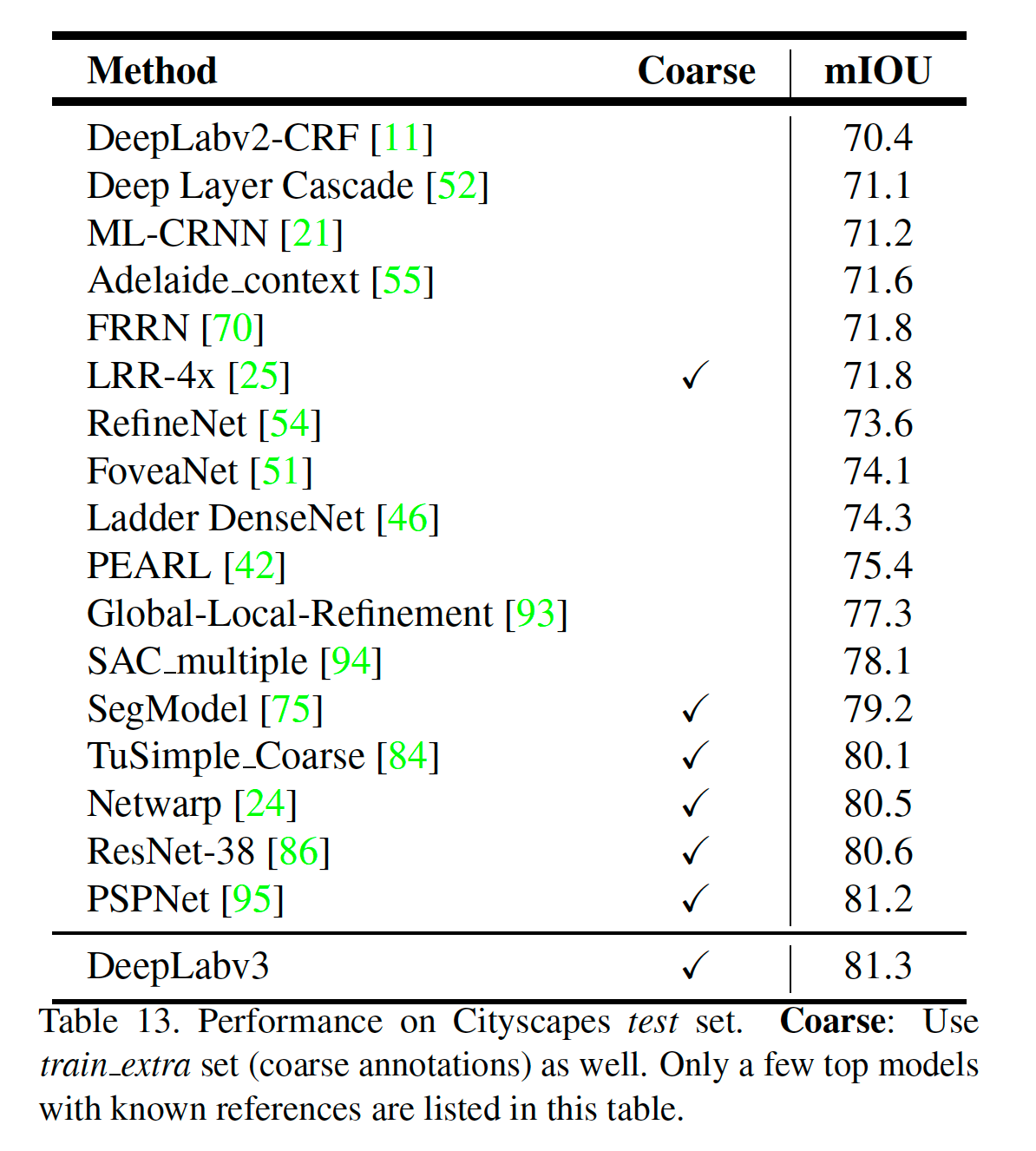
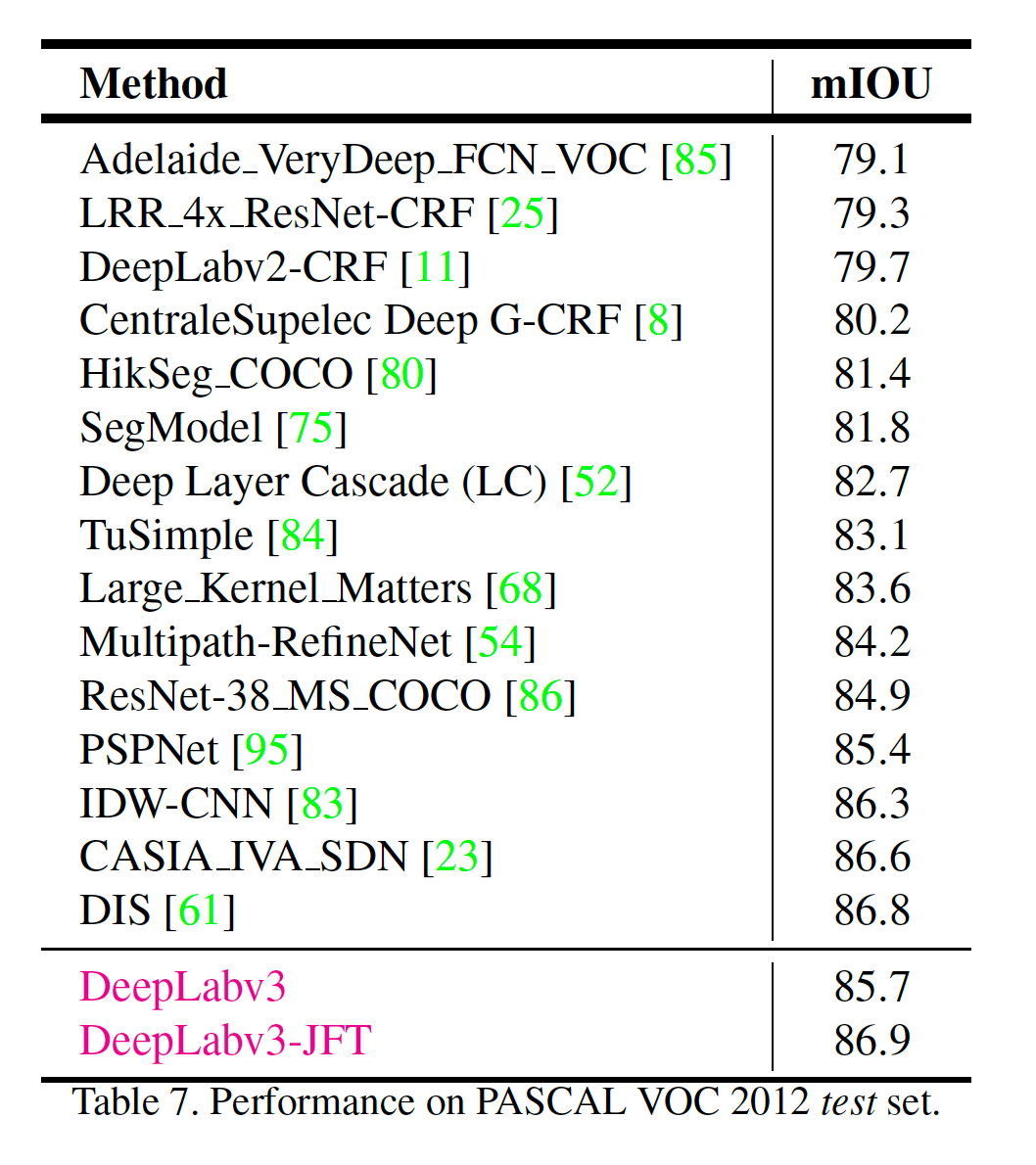
ImageNet pretrained ResNet을 사용하였으며, Multi_Grid = (1,2,4), ASPP = (6,12,18)을 적용하였을때 가장 결과과 좋습니다. 또한, Multi-Grid, Flipped input, COCO-pretrain을 적용했을 때 PASCAL VOC 2012, Cityscape dataset에서 제일 높은 결과를 얻을 수 있었습니다.
References
https://gaussian37.github.io/vision-segmentation-deeplabv3/
