swin 이전에 vision에 transformer을 먼저 적용한 Vision Transformer (ViT)에 대해 간략하게 알아봅시다.
Transformer에 대한 설명은 다음을 참고하면 좋습니다 :) Transformer
Visual Transformer
Paper: AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
NLP분야에서 매우 좋은 성능을 뽐내고 있는 Transformer 구조를 Vision 분야에 적용한 논문이다. 기존 CNN 구조를 전혀 사용하지 않고 이전의 모델들과 비슷하거나 더 높은 성능을 보여준다.
inductive bias
CNN과의 가장 큰 차이점은 CNN에서 사용한 이미지에 대한 inductive bias가 없다는 것이다. inductive bias란 간단히 말해 주어지지 않은 input에 대해 임의로 예측하고 가정한 것이다. CNN은 이미지에서 주변 픽셀들간의 관계가 나머지보다 더 중요하다는 것을 가정한다.
반면에, Transformer은 CNN의 inductive bias를 가지고 있지 않다. (Transformer에서의 inductive bias를 해석하는 글을 나중에 짧게 쓸 예정) 그래서 훨씬 많은 training dataset (JFT-300M)을 이용해 pretrain해준다.
Model Architecture
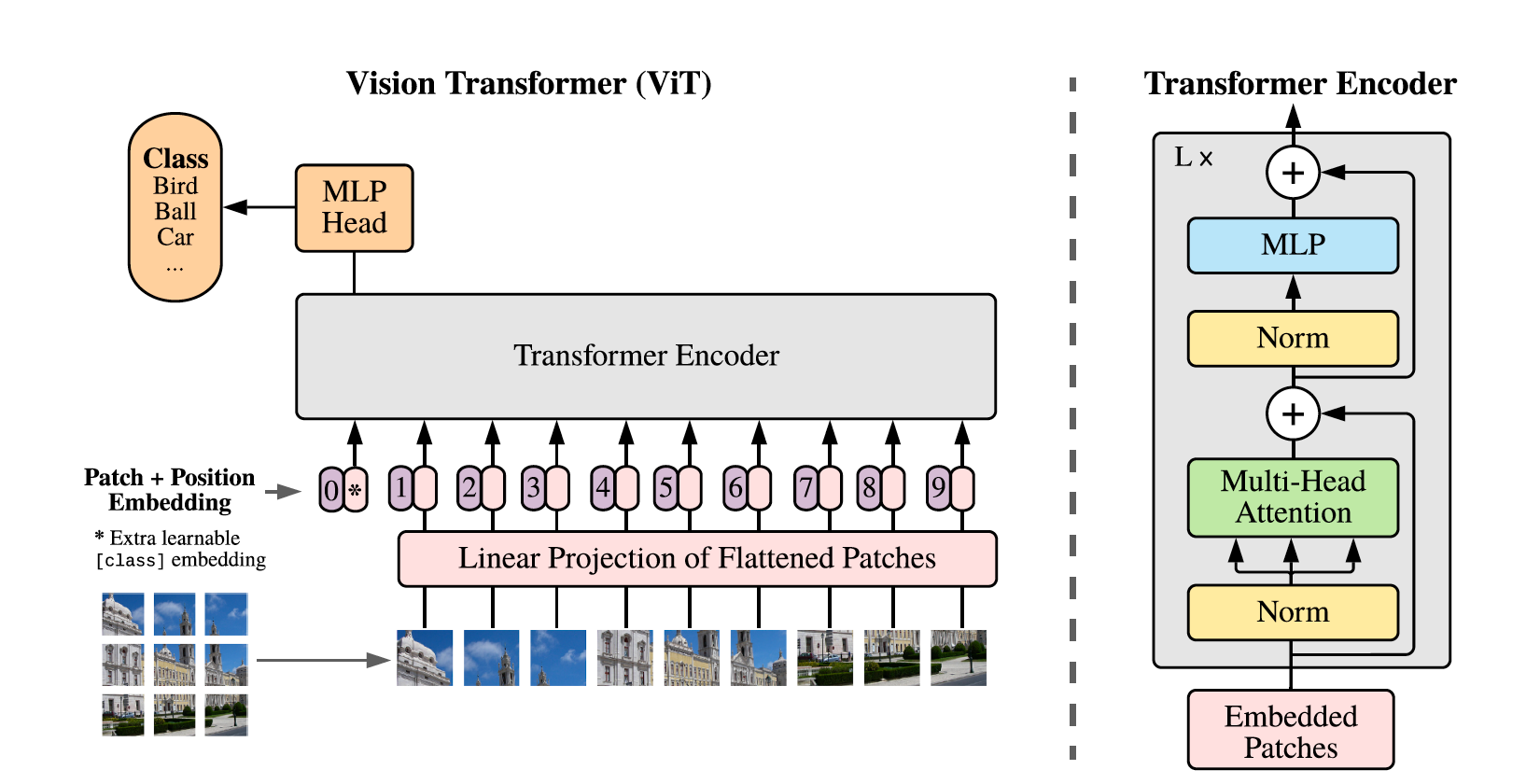
(1) 이미지를 16x16 patch로 나누어, 각각 1차원 embedding vector을 구성한다.
(2) BERT의 [class] token과 유사하게 학습 가능한 token을 맨 앞에 추가한다.
(3) 일반적인 1D Position Embedding을 embedding vector에 추가해준다.
(4) 기존의 Transformer구조와 똑같이 사용해 input으로 넣어준다.
(5) 마지막으로 MLP Head를 거쳐 Classfication을 수행한다.
Experiments
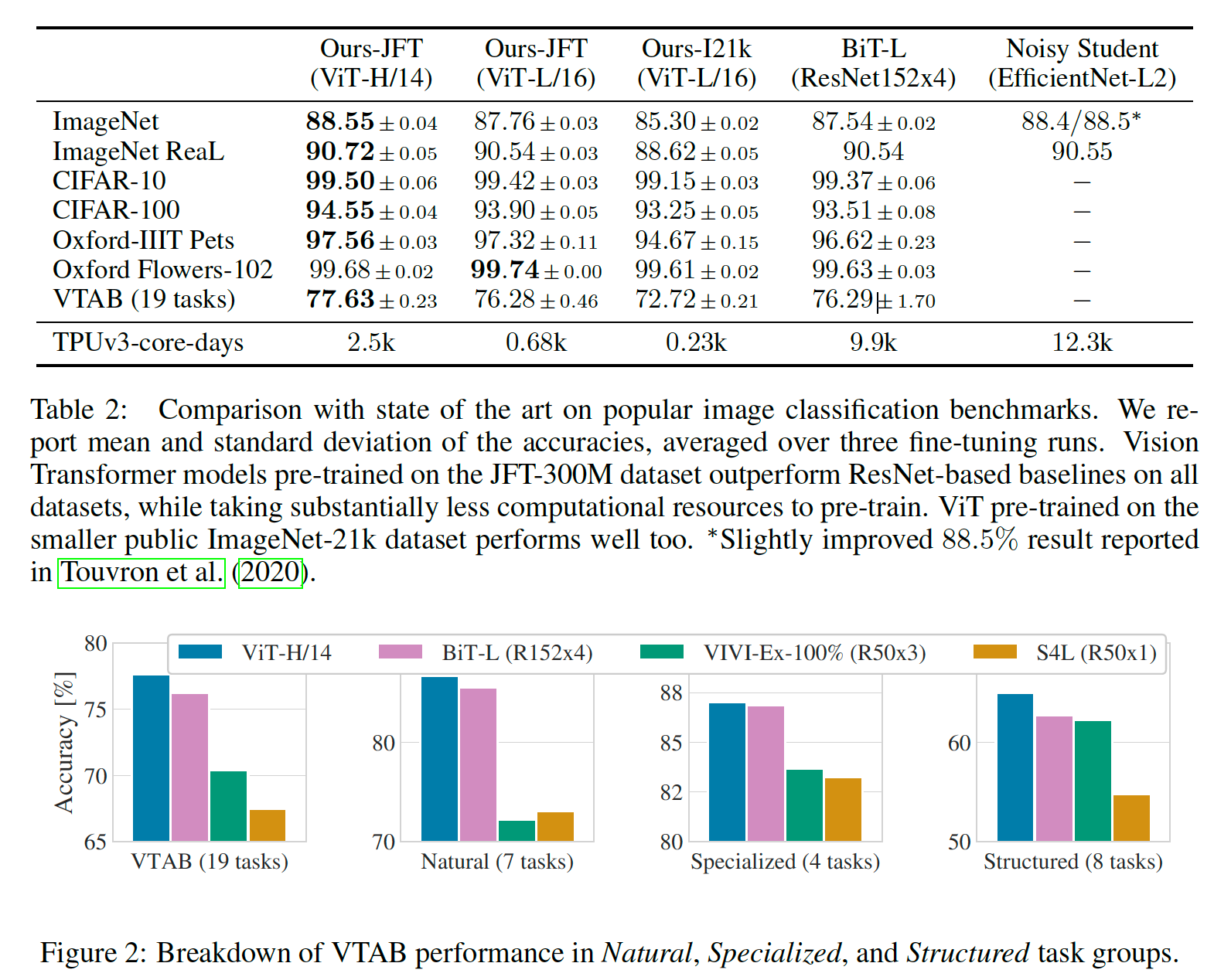
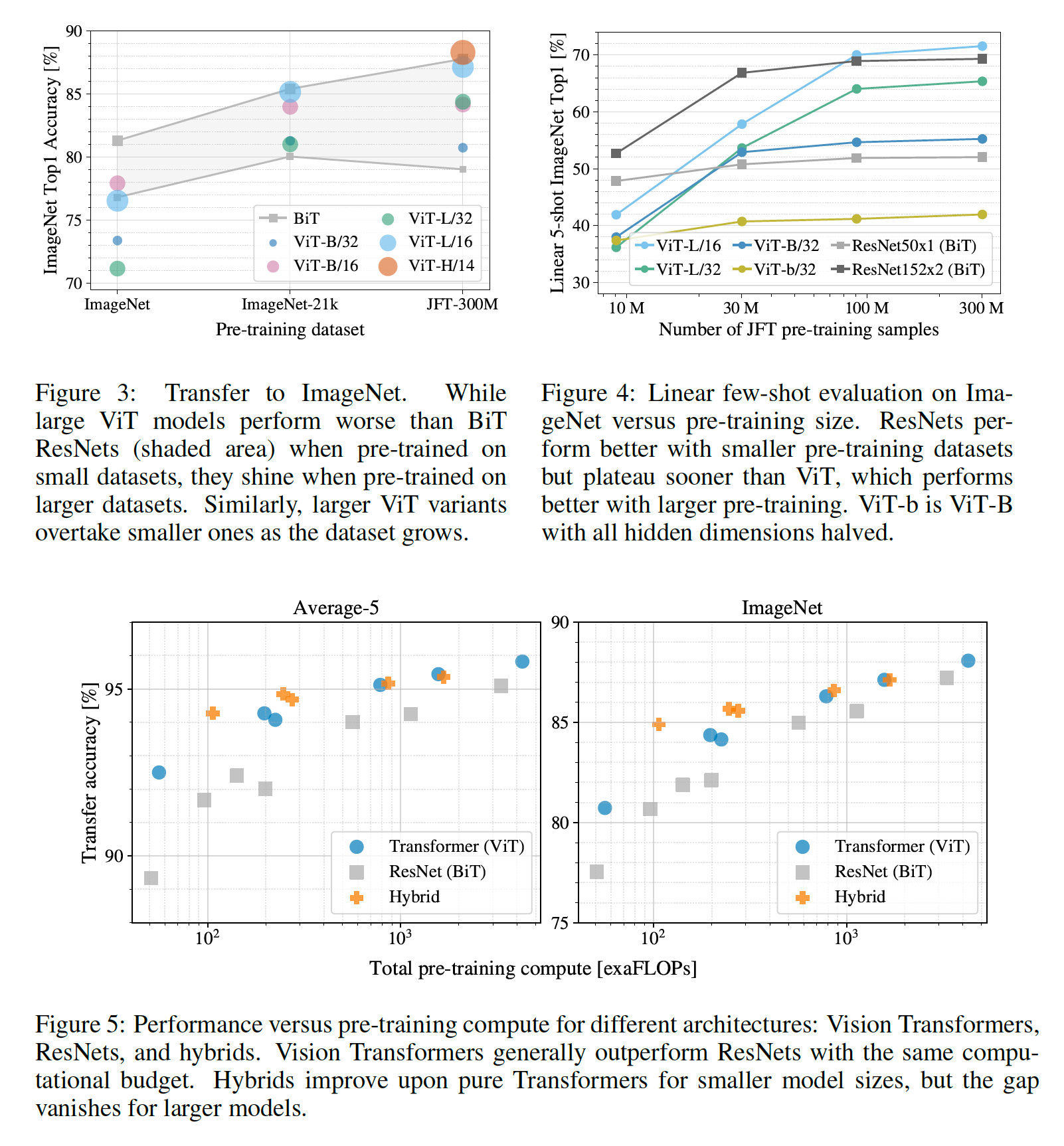
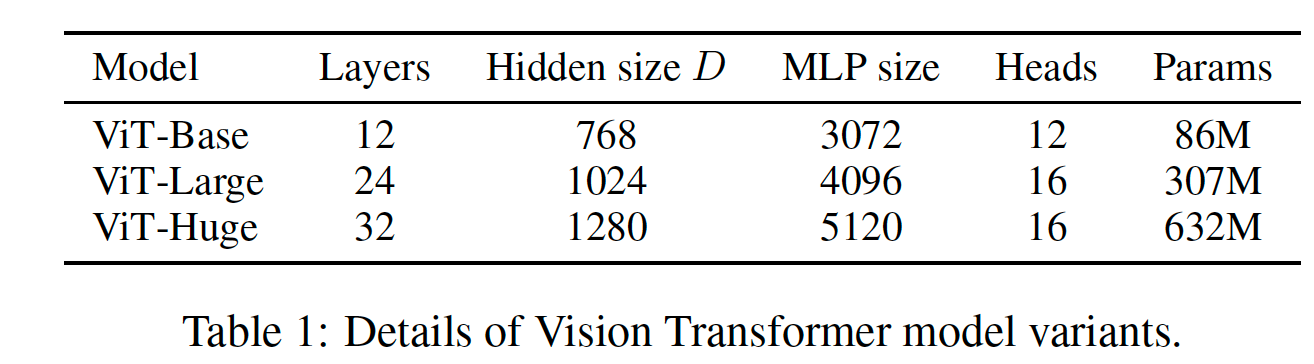
이 논문에서는 ViT를 구성해 기존 CNN모델(ResNet)과 비교했다. JFT-300M dataset을 모두 학습했을 때 ResNet보다 더 뛰어난 성능을 보여준다.
Result / Thinking
일단 CNN의 inductive bias를 사용하지 않고 대신에 압도적인 데이터셋으로 밀어붙여 성능이 더 좋게 나오긴 했는데, 차이가 엄청 크진 않네요. ResNet보다 더 성능이 좋은 다른 CNN기반 모델이 있을텐데 사용하지 않은 것으로 보아 저자는 그냥 Transformer을 사용해도 CNN과 비슷한 성능을 낼 수 있다! 정도를 보여주고 싶었던 것 같습니다.
CNN모델의 parameter 수를 ViT와 맞춰주거나 large training dataset에 최적화된 모델을 사용하여 비교해 보면 좋을 듯 합니다.
참고로 뒤이어 리뷰할 swin 논문에서는 다시 local info를 활용하여 학습합니다.
Swin Transformer: Hierarchical Vision Transformer using ShiftedWindows
Paper: Swin Transformer: Hierarchical Vision Transformer using ShiftedWindows
0. Abstract
Vision에 Transformer을 적용할 때의 문제점은 object의 scale이 이미지 내에 다양하게 존재한다는 것이다. 이 논문에서는 hierarchical Shifted WINdow방식을 제안해 문제점을 해결하고, 이미지 크기에 선형비례한 계산복잡도를 가진다.
1. Introduction
NLP에 이어 Vision분야에서도 Transformer을 사용한 모델들이 연구되고 있고, 좋은 성과를 보이고 있습니다. 하지만 자연언어와 이미지 domain 사이의 차이점을 보완해 주어야 하는데 (1) 물체의 multi-scale을 모두 포착해야 하고, (2) 단어에 비해 pixel의 resolution이 훨씬 크다는 점입니다. (이미지 크기에 quadratic한 연산량)
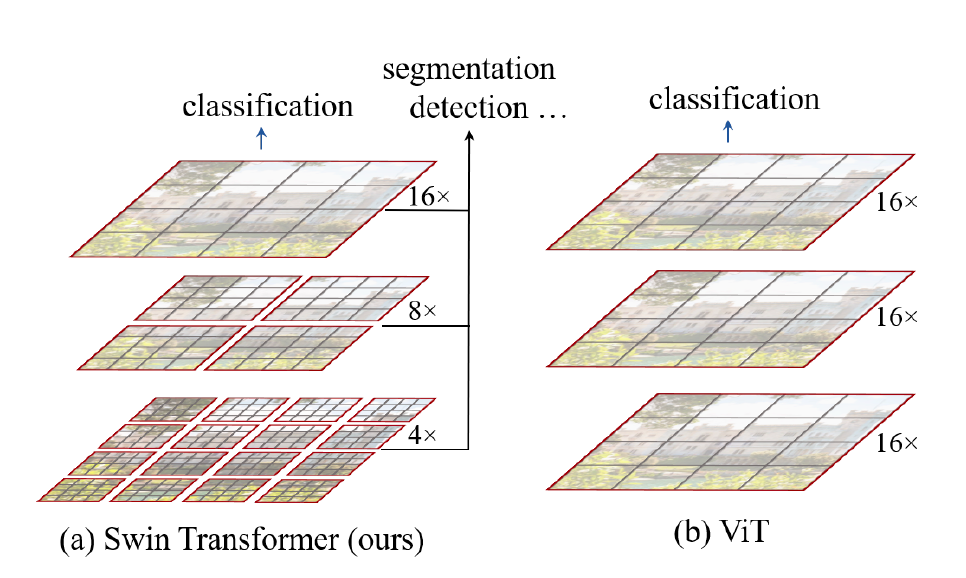
위에서 언급한 문제점들을 해결하기 위해 이 논문에서는 (1) hierarchical feature map을 사용하고, (2) window를 설정해 local self-attention연산을 통해 linear complexity를 가지는 Swin Transformer 구조를 제안합니다.
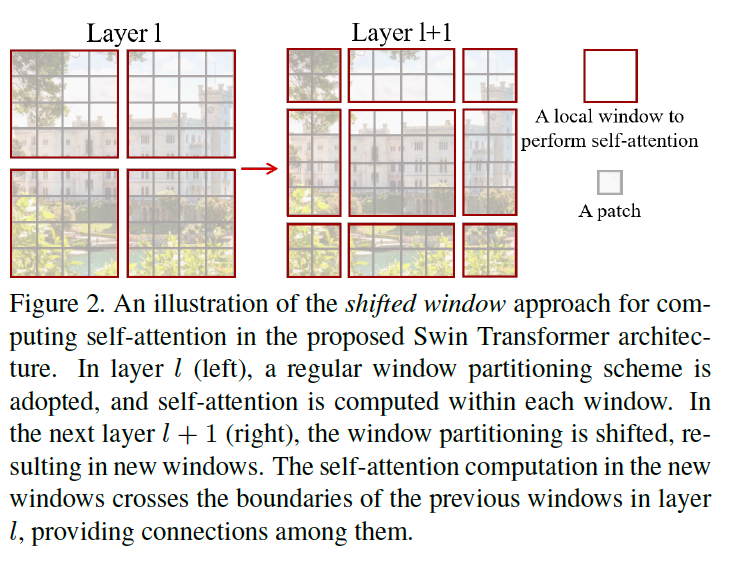
각 Transformer block을 거치면서 local window들을 2x2씩 합치면서 진행해 hierarchical 구조를 만족하고, 또한 Transformer block 안에는 local window의 경계에 있는 object에 대한 연산도 수행하기 위해 이전에 사용하던 sliding window 방식 대신에 shift window partition 을 이용해 비슷한 결과를 얻으면서도 훨씬 빠른 연산이 가능합니다.
2. Related Work
- CNN and variants:
-> DenseNet, HRNet, EfficientNet - Self-attention based backbone architectures
- Self-attention/Transformers to complement CNNs
-> CNN과 Transformer을 동시에 활용하는 모델들에 대한 소개인 듯 합니다. - Transformer based vision backbones
-> ViT, DeiT
3. Method
3.1 Overall Architecture
Swin Transformer에는 4가지 버전이 있는데(Tiny, Small, Base, Large) 아래 사진은 Tiny 버전입니다.
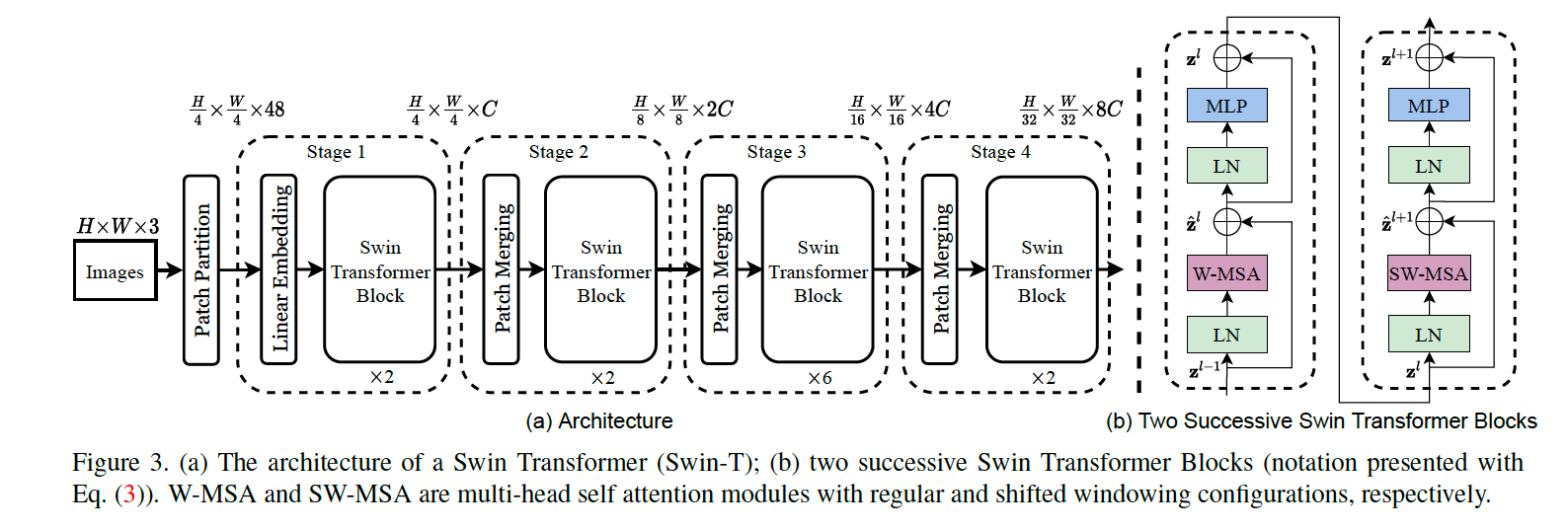
- Patch Partition: ViT와 유사하게 이미지를 patch 단위로 나눕니다. (patch size = 4x4x3)
- Stage 1: Linear layer을 통해 개의 길이 48의 patch를 linear embedding과 Swin Transformer block을 거쳐 길이 의 1D vector로 변환합니다.
- Stage 2~4: 근처의 2x2개의 patch들을 합쳐 길이가 4배인 patch를 구성합니다. 이 후 2x downsampling을 통해 최종 output dimension은 두배가 되고, patch의 갯수는 4배 줄어듭니다. 이때, window 안의 patch 갯수는 유지가 되기 때문에 stage가 지날수록 window의 크기가 점점 늘어납니다. 다른 CNN구조와 같이 resolution이 점점 줄어들기 때문에 VGG나 ResNet등 다른 block으로 바꿔서 사용할 수 있습니다.
Swin Transformer block
기존의 Transformer 구조에서 바뀐 점은 기존의 multi-head self attention (MSA)에서 window based MSA (W-MSA), shifted-window based MSA (SW-MSA)를 사용합니다.
3.2 Shifted Window based Self-Attention
global attention 대신에 local window attention을 사용하면 linear computation complexity를 만족합니다.
Self-attention in non-overlapped windows
위에서 설명한 것을 수식으로 나타내면 다음과 같습니다:
한 window 안에 개의 patch가 있다고 가정하면, 다음과 같이 MSA는 이미지의 크기에 quadratic하게 비례하지만, W-MSA는 이미지의 크기에 linear하게 비례합니다.
Shifted window partitioning in successive blocks
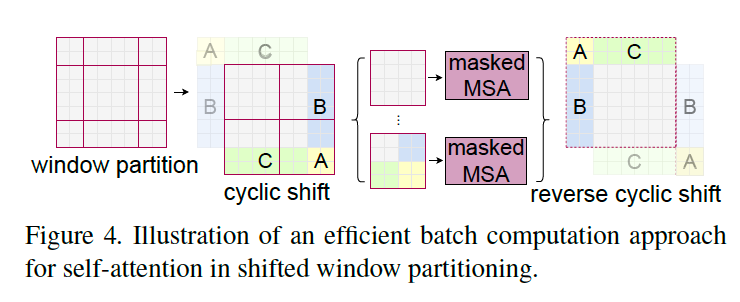
window 경계에 있는 patch들에 대해서도 attention 연산을 해주기 위해 W-MSA block을 거친 뒤에, window를 patch만큼 shift해 attention 연산을 한번 더 진행합니다.
Efficient batch computation for shifted configuration
위의 그림의 제일 왼쪽으로 partition을 나누기만 하면, 결국 window의 갯수가 2x2에서 3x3으로 늘어나게 되어 computation이 증가하게 된다. 대신에, cyclic-shift를 적용해 위의 그림과 같이 모서리 부분들끼리 붙여준다. 이때 각각 반대에 위치한 모서리끼리 합쳐진 것이기 때문에, 2사분면의 window를 제외하고는 각각 다른 mask를 씌워서 진행합니다. (* 자세한 masking 방식은 이해하지 못했습니다 ㅠ)
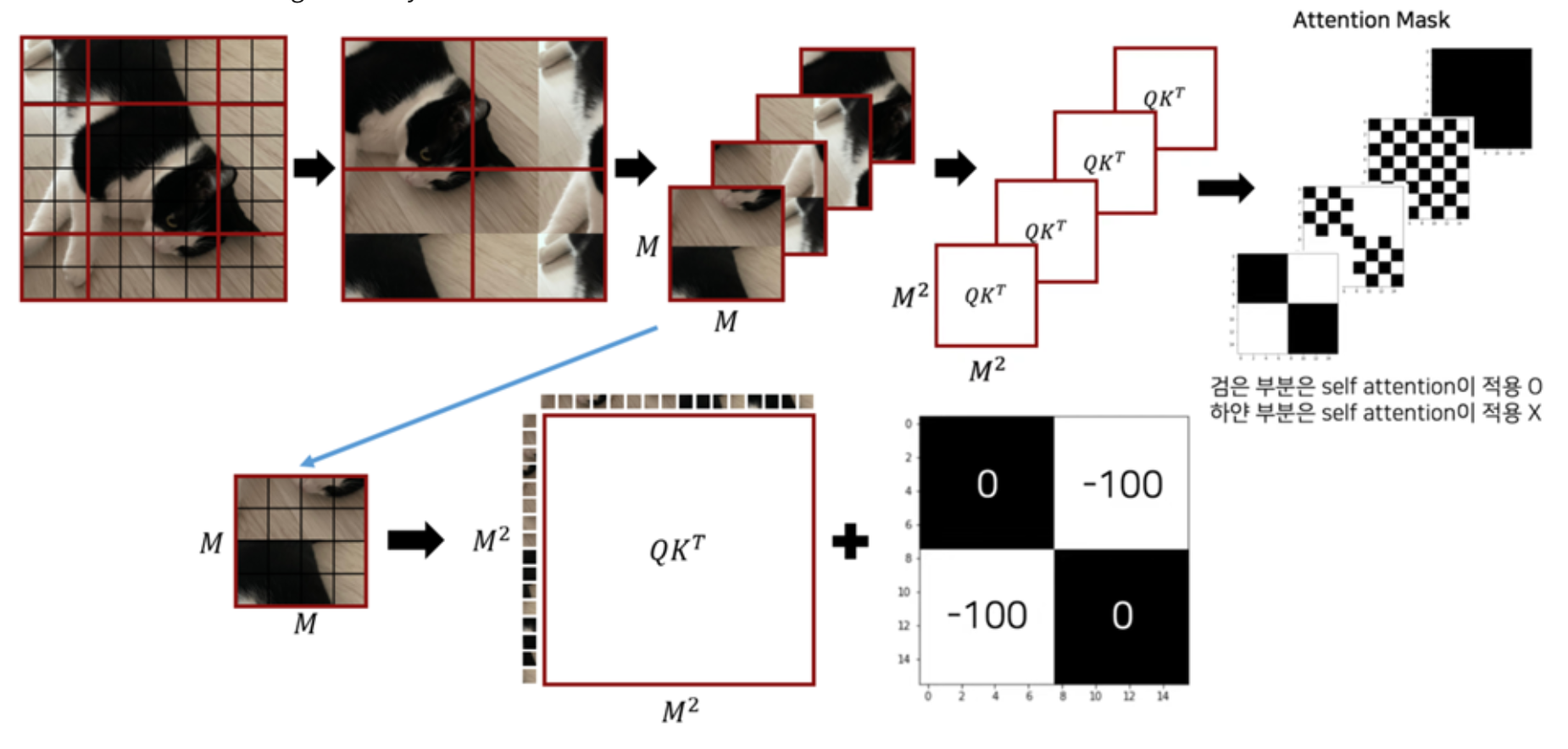
Relative position bias
ViT와 다르게 patch들의 global 위치정보를 담고 있는 position embedding을 추가하지 않는다. 대신에, self-attention 연산 과정에 window 안에서의 patch들의 상대적인 위치정보 (relative position bias, B)를 추가해 줍니다.
상대좌표를 넣어주었을 때 성능이 더 좋아서 논문에서는 이 방식을 사용합니다.
3.3 Architecture Variants
- Swin-T: C = 96, layer numbers = {2,2,6,2}
-> ResNet-50, DeiT-S와 비슷한 크기 - Swin-S: C = 96, layer numbers = {2,2,18,2}
-> ResNet-101과 비슷한 크기 - Swin-B: C = 128, layer numbers = {2,2,18,2}
- Swin-L: C = 192, layer numbers = {2,2,18,2}
4. Experiments
ImageNet-1K (Classification), COCO (Object Detection), ADE20K (Semantic Segmentation) 데이터셋을 사용하여 실험을 진행합니다.
4.1 Image Classification on ImageNet-1K
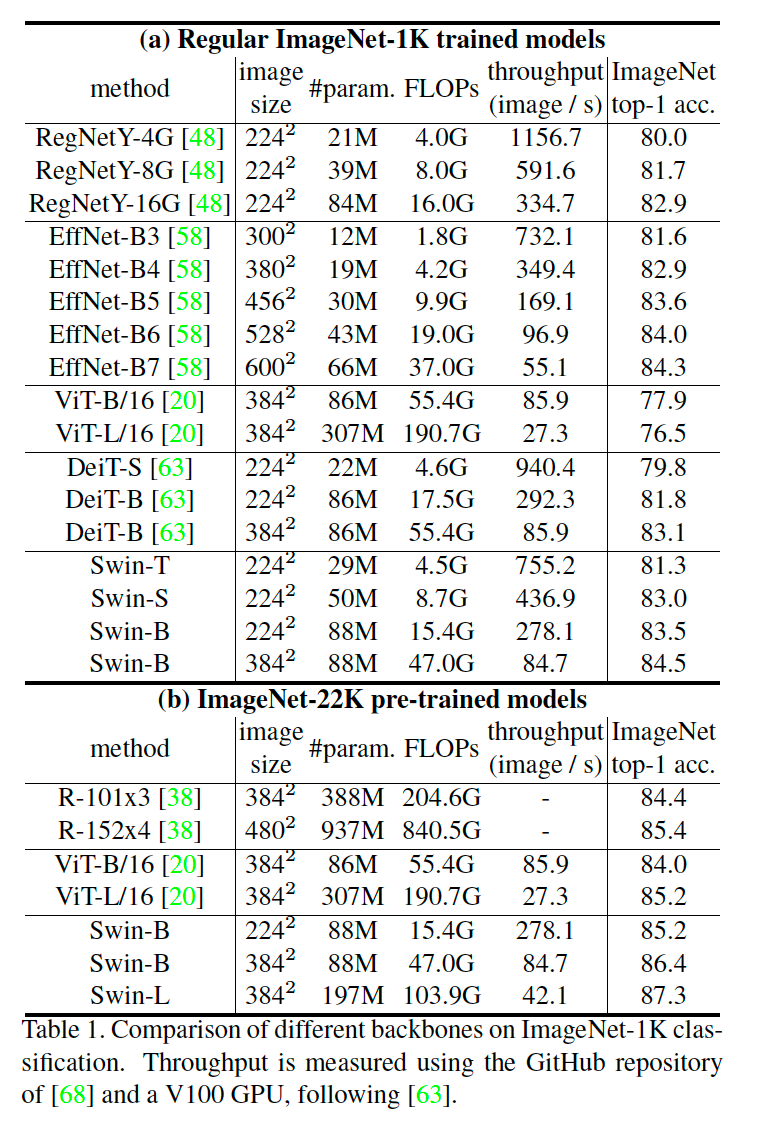
ImageNet-1K로 진행한 실험에서는 ViT보다는 연산량이나 모델 크기에 비해 성능이 좋고, DeiT보다도 근소하게 더 나은 모습을 보여줍니다. EfficientNet과는 거의 유사한 성능을 보여줍니다.
ImageNet-22K로 진행한 실험에서는 ViT와 ResNet보다 더 좋은 성능을 보여줍니다.
4.2 Object Detection on COCO
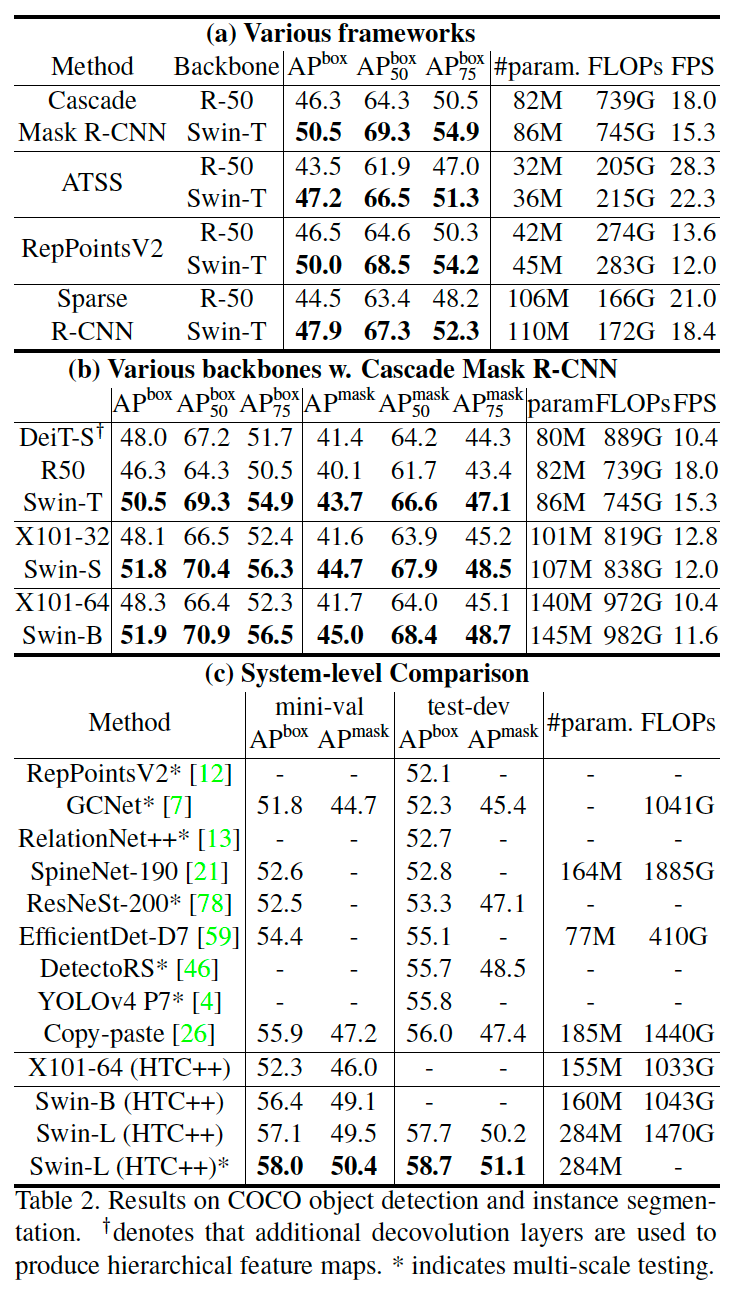
다른 모델에 비해 parameter 수는 많지만, 계산량이 비슷하고 성능은 더 좋은 모습을 보여줍니다.
4.3 Semantic Segmentation on ADE20K
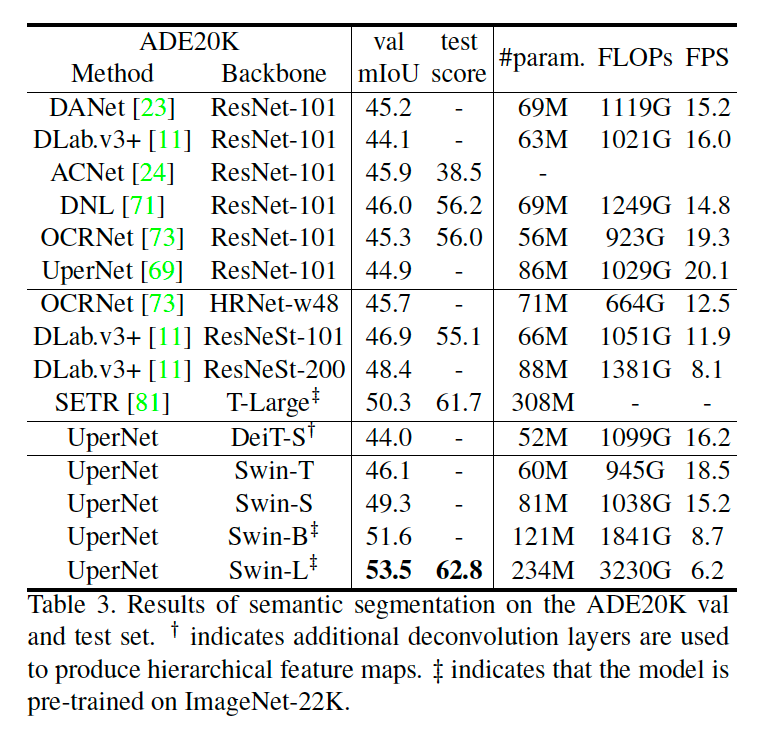
ResNet을 backbone로 사용하는 다른 모델의 SOTA와 거의 유사한 성능을 보여줍니다.
4.4 Ablation Study
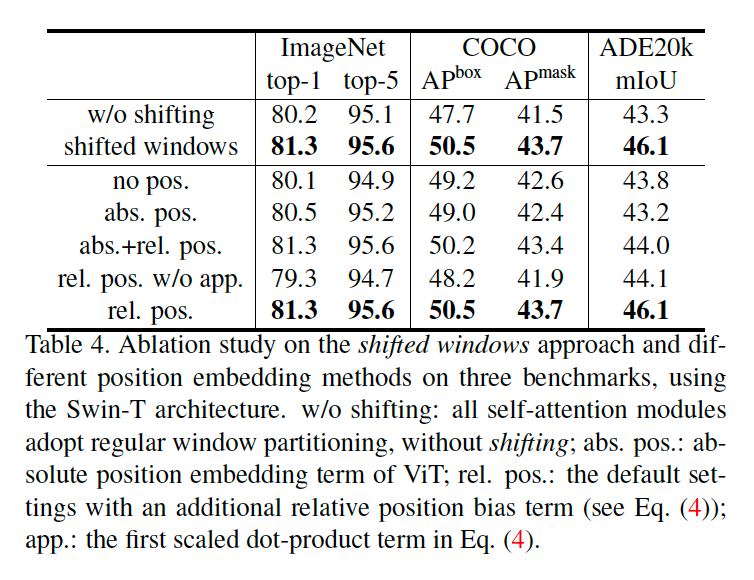
- Shifted window 기법을 사용하면 더 좋은 성능을 보여줍니다.
- relative position embedding만을 사용했을 때 제일 좋은 성능을 보여줍니다.
5. Conclusion
Swin Transformer 구조는 다양한 Vision 분야에서 CNN을 이용하지 않고 SOTA를 달성했고, 여러가지 모델의 backbone으로 사용될 수 있습니다.
Shifted window 기반의 self-attention 방식은 vision에서 충분히 좋은 성능을 보여줍니다.
Reference
https://greeksharifa.github.io/computer%20vision/2021/12/14/Swin-Transformer/
https://mvje.tistory.com/42
