리플리케이션
리플리케이션 replication 이란?
- 데이터베이스 스토리지를 복제한 것으로 실시간 복제용 데이터베이스 서버를 운용하는 것을 말한다.
- 리플리케이션은 다양한 이슈로 데이터 유실이 생길 경우를 대비하여 스토리리까지 복제함으로써 데이터의 유실을 최소화하기 위함
- 리플리케이션은 Source(Master), Replica(Slave)라는 구조
- 기준이 되는것을 마스터, 복제용은 슬라이브라고 한다.
- 애플리케이션은 데이터베이스의 SQL 명령을 통해 데이터 작업을 수행하는데 마스터 서버는 SQL명령을 수신하면 그 명령으 리플리카 서버에도 똑같이 보내어 수행하도록 한다.
- 이런 방식으로 마스터 서버와 리플리카 서버도 데이터베이스가 동기화된 상태로 유지되어야 한다.
Master/Slave 아키텍처
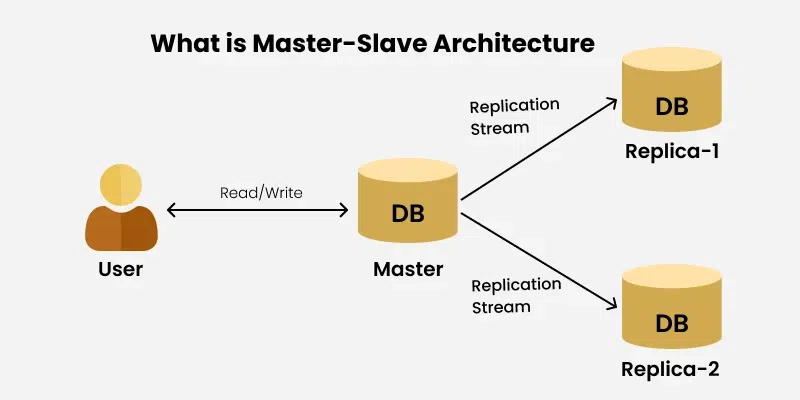
리플리케이션의 목적
도입 배경과 간단한 작동방식
- 근본적인 이유는 데이터 안정성이다. 데어터 손상되어도 백업본으로 데이터를 복구하여 사용하는것이다. 대신 백업에도 단점이 있는데 데이터백업을 주기적으로 실행되도록 설정해두었다고 해도 백업된 시간과 장애가 발생한 시간의 데이터 변경사항이 소실될 가능성도 존재하기 떄문이다.
- 리플리카 서버는 마스터서버와 약간의 딜레이가 존재하긴 하나 마스터와 데이터가 동기화되어있기 때문에 장애 복구에 도움을 줄 수 있다. 또한 리플리카도 마스터 서버로 승격될 수 있다.
- 리플리카 서버를 마스터 서버로 승격한 후 이 서버에 대한 리플리카 서버를 생성하면 복구가 완료된다.
목적들
- 스케일 아웃 : 갑자기 늘어나면서 트래픽에 대해 부하를 줄이기 위해 서버를 늘려 성능을 개선
- 백업 : 백업 과정에서 쿼리 손상을 입을 기능성이 있어 Source데이터에 영향을 미치지 않고 Replica에서 데이터 백업
- 데이터분석 : Master 서버 성능에 영향을 주지 않고 Slave에 데이터 분석을 수행할 수 있습니다.
- 데이터의 지리적 분산 : Source서버와 물리적인 거리가 있더라도 Replica서버를 통해 응답을 받을 수 있고, 속도도 높일 수 있다.
추가 설명
- 단순 백업은 2개 이상의 데이터배이스 서버와 스토리지를 Source, Replica 로 나눠서 동일한 데이터를 저장하는 방식
- 분산 방식은 Slave DB를 백업용으로 활용하기 아까워 Slave DB는 부하 분산을 하는 방식으로 사용
- Slave를 백업 용도를 활용하는 방식은 두개 이상의 데이터베이스 서버와 스토리지를 Master와 Slave로 나눠 동일한 데이터를 동기화 및 저장하는 방식
- Slave를 읽기 위한 용도로 활용하는 방식은 Master의 부하를 줄이기 위해 Select 작업을 Slave에서 하도록 구성하는 방식
- Select 작업에 시간이 걸리기 때문에 다른 작업을 하기 어렵기 때문에 Slave를 통해 분산처리할 수 있어 성능 향상에 도움을 줄 수 있다.
리플리케이션 동작흐름
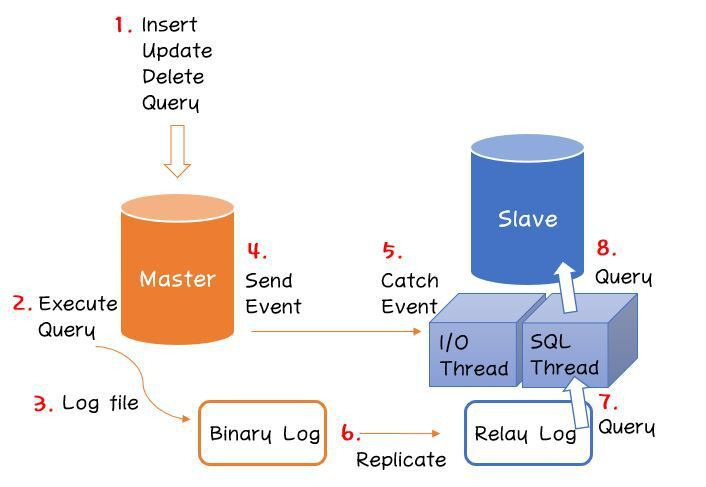
- 클라이언트 요청에 따라 master 데이터베이스 에서 데이터작업 수행하고
- 변경이력을 Binary Log 로그로 저장한다
- 발생한 DB작업 이벤트를 slave 데이터베이스에 보낸다
- slave에서는 I/O 쓰레드를 기반으로 master에서 발생한 이벤트를 인식하고
- Binary Log를 기반으로 Master에서 업데이트 log를 복제한다.
- log기반으로 SQL 생성하고 수행하여 Slave 데이터베이스를 업데이트한다.
리플리카 응용
- 리플리카는 기본적으로 읽기전용으로 사용된다.
- 그 결과 데이터베이스서버의 부하를 분산하고 애플리케이션 성능을 개선할 수 있다.
- 애플리케이션에서 읽기작업(조회)만 슬라이브 서버 그 외는 마스터 서버 에서 수행하도록 해야한다.
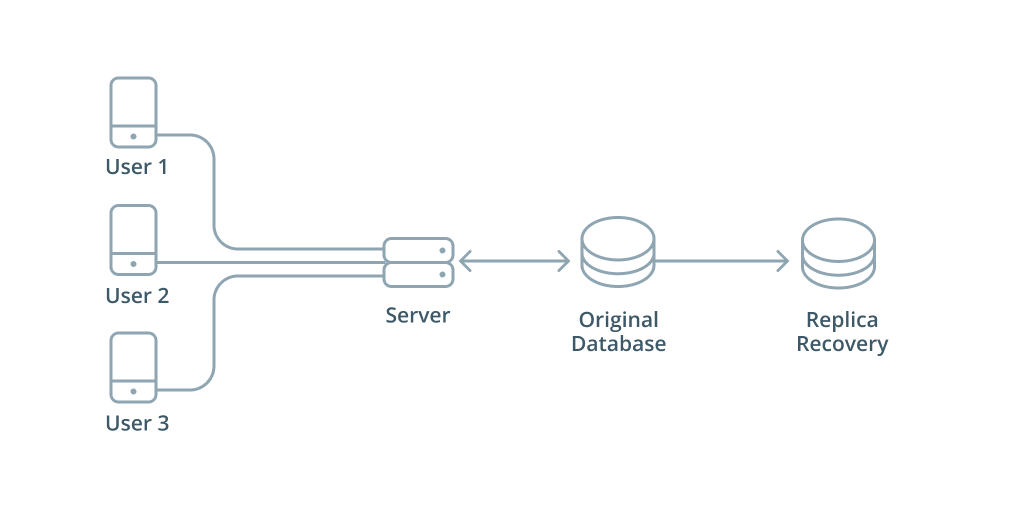
Slave 를 백업용도스토리지로 사용하는방식
- 클라이언트가 DB작업을 하면 Master서버에서 데이터작업이 이뤄지고 업데이트된 내용을 Slave 서버에서 동기화하는 추가 작업을 수행한다.
Slave를 읽기 용도로 사용하는 방식
- 클라이언트가 DB작업을 할떄 Select 작업만 Slave DB에서 처리되고 나머지 작업은 master DB에서 이루어진다.
리플리케이션의 단점
- Master, Slave는 서로 다른 데이터베이스 서버이므로 서버의 버전관리가 필요하다. 두 서버의 데이터베이스도 동기화해야한다.
- 또한 데이터의 정확성도 보장해야하므로 Master처리속도와 Slave처리속도가 비슷해야한다.
클러스터링 vs 리플리케이션
- 공통점 : 리플리케이션과 마찬가지로 데이터베이스의 확장하는 방식이다.
- 리플리케이션: 데이터 복제 중심 → 읽기 부하 분산, 장애 시 수동 복구
- 클러스터링: 시스템 전체를 하나처럼 → 자동 장애 복구, 고가용성, 동시처리 가능으로 클러스터링이 복잡하고 구축에 필요한 인프라 지식도 요구됨
아키텍처

welcome