클러스터링
클러스터링이란
- 다양한 데이터에서 유사한 속성을 가진 데이터까리 자연스러운 그룹화하는 것을 말한다.
- 이러한 그룹화된 데이터는 데이터 차원의 수를 줄여 방대한 데이터셋의 복잡성을 줄인다.
- 데이터셋을 시각화하여 데이터 속성과 클러스터간의 밀도 및 관계를 확인할 수 있다.
- 클러스터링 프로세스는 데이터의 한 가지 특징만을 사용할 수도 있으며 데이터에 존재하는 모든 특징을 사용하여 클러스팅할 수 있다.
- 이때 클러스터링 알고리즘을 사용한다.
- 클러스터를 정의하는 방법에는 여러 가지가 있다. 데이터의 크기, 데이터차원, 카테고리, 데이터셋에서의 클러스트 개수에 따라 알맞은 알고리즘이 존재하며 사용한다.
- 클러스터링에 일반적으로 사용되는 다섯가지 접근 방식이 있다.
- 중심적 기반 클러스터링
- 계층적 클러스터링
- 분산 기반 클러스터링
- 밀도 기반 클러스터링
- 격자 기반 클러스터링
데이터베이스 클러스터링이란
- 한개 이상의 데이터베이스 인스턴스나 서버를 연결하는 작업을 말한다.
- 일반적으로 마스터라고 불리는 단일 데이터베이스 서버에 의해 다수의 데이터베이스 인스턴스가 관리된다.
- 데이터베이스 설계에서 master - slave방식의 구성은 대규모 시스템처리에서 필수적이다.
- 왜냐하면 단일 데이터베이스로는 다수의 클라이언트의 요청을 처리할 수 없다.
- 그러한 이유로 다수 데이터베이스 서버를 병렬로 구성/활용하여 대규모 요청을 처리할 수 있다.
한 시스템에서의 다수 데이터베이스 서버를 둔 디자인설계
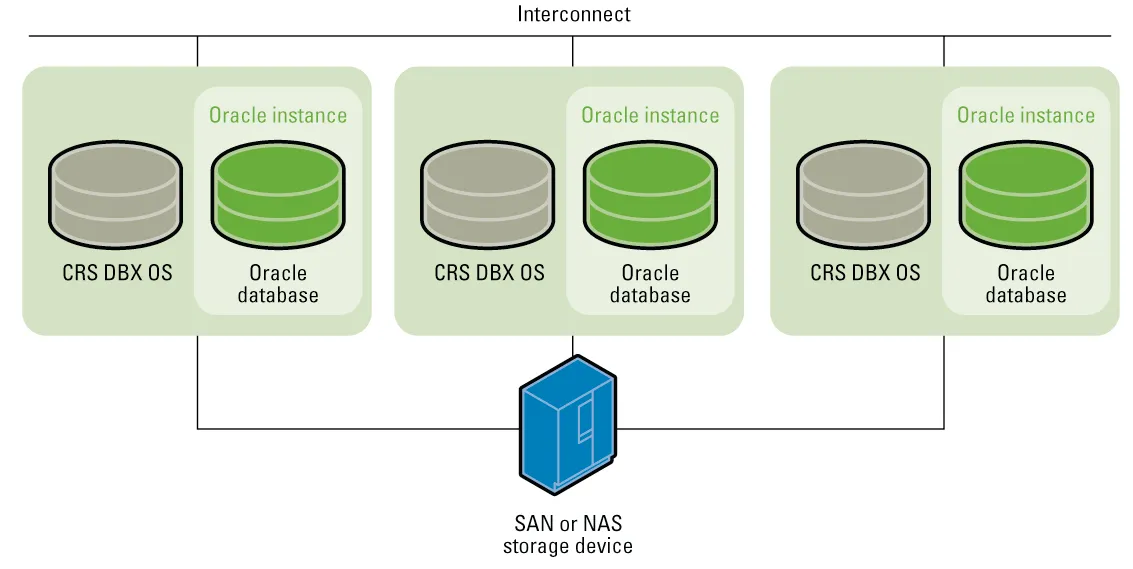
- 다수의 slave데이터베이스서버는 SAN이라는 장치에 의해 서로 연결되어 있다.
- SAN은 Storage area network의 약자로, 이미 저장되어 있는 통합된 데이터, 즉 블록단위의 데이터에 접근에 사용되는 네트워크 장치이다. (물리적 장치)
- 하는 역할은 디크 배열, 테이블 라이브러리에 있는 데이터 접근에 사용되며, 이 장치는 운영체제와 직접적으로 연결되어 있는 저장소이다.
한계와 극복
- master - slave 데이터베이스 클러스터링의 한계도 존재한다.
- 그 한계는 데이터베이스 구성이 복잡해진다는 것이다. 데이터베이스를 병렬로 추가하게 되므로 복잡성이 계속 더해진다.
- 따라서 이러한 지속적으로 늘어나는 데이터베이스 구성의 복잡성을 해결하기 위해 다수의 데이터베이스 서버는 한 차원 높은 서버에 의해 관리해야되는것이다.
- 이 서버를 master라고 하며 시스템에서 처리되는 모든 데이터의 흐름을 통제한다. (모니터링)
SAN 장치 소개
- 실제 사진

- 개념도식
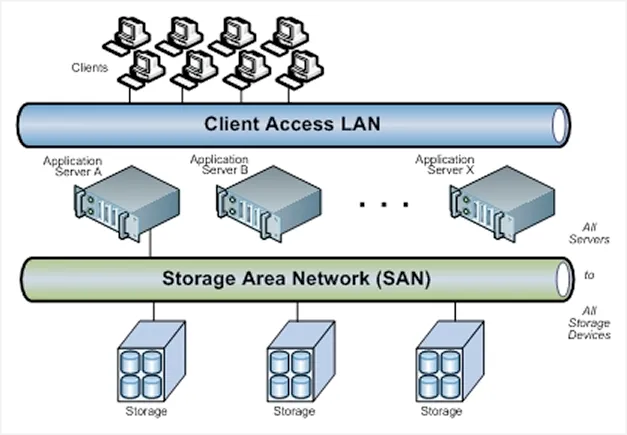
데이터베이스 클러스터 아키텍처
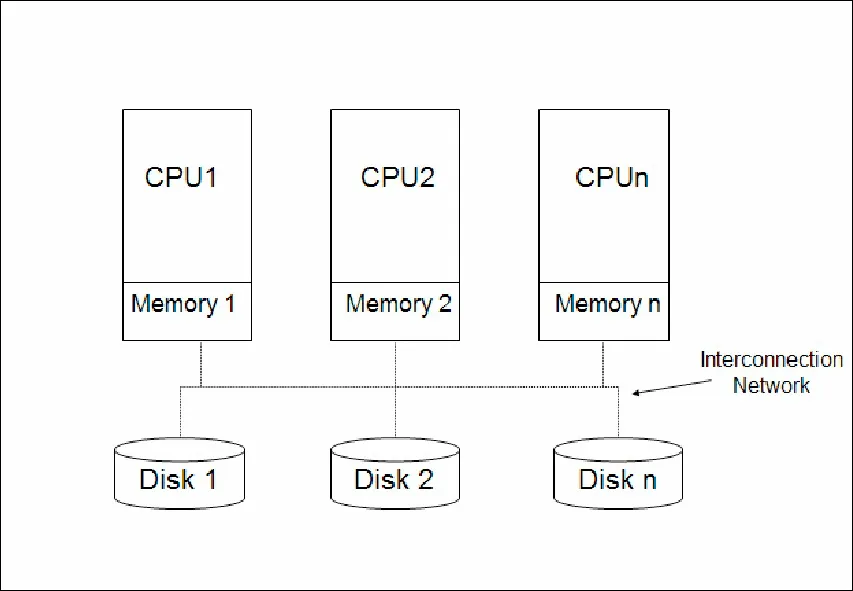
Shared-Nothing Architecture
- 각 데이터베이스 서버는 타 노드와 독립적이어야한다.
- 각 노드는 자신만의 데이터베이스 서버를 가져야 한다. 이 데이터베이스는 데이터를 접근하고 저장할 수 있다.
- 어떤 데이터베이스 서버도 master가 될 수 없다. 결론은 master가 없고 모두 동등하다.
- 시스템에 어떤 데이터에 대해서도 컨트롤하는 중앙베이터베이스 노드가 존재하지 않는다.
- 수평적 확장성을 특징으로 가진다.
- 서로 노드(데이터베이스 서버)간 어떤 자원도 공유되지 않는다. 독립되어 있다.
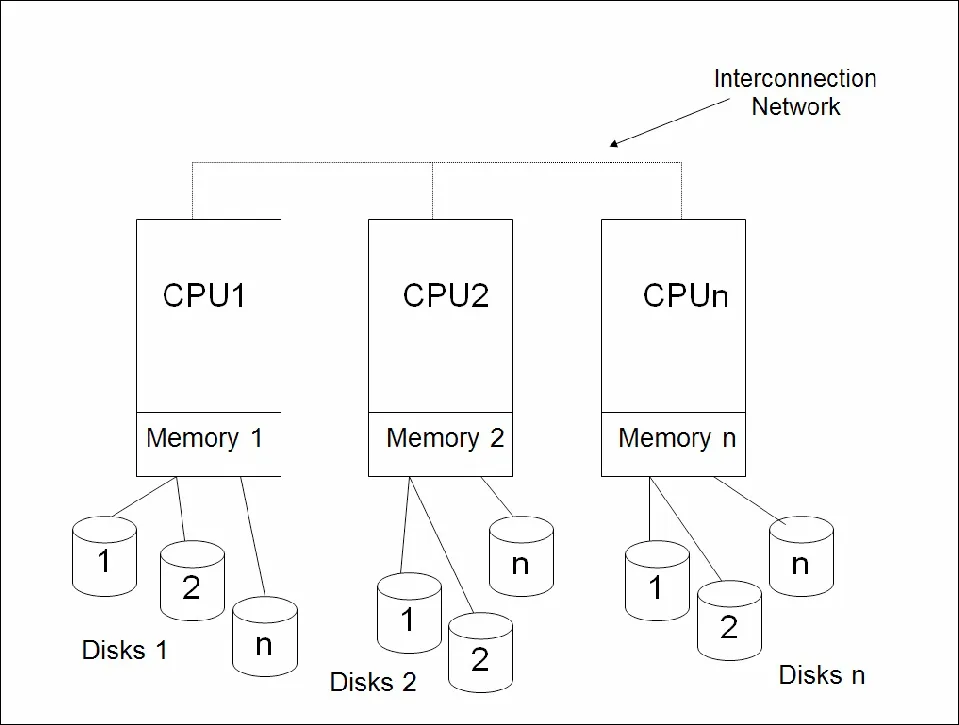
Shared-Disk Architecture
- 모든 노드(CPU)는 모든 노드에 대해 접근할 수 있다. 공유한다.
- 전체 시스템에 대한 접근이 가능
- CPU간 연결되어 있는 interconnection 서버가 있다.
- 따라서 확장성을 갖지 않는다.
- 모든 노드는 동일한 데이터에 접근할 수 있고 전체 시스템에 데이터흐름도 모니터링할 수 있다.
- 문제는 slave 노드의 개수가 일정 수준을 넘게되면 master노드는 모든 slave를 효율적으로 모니터링하지 못한다.
- 한 노드가 통제할 수 있는 slave의 개수가 한정되어 있다.
데이터베이스 클러스터링의 장점
- 시스템 부하 분산
- 더많은 이용자가 서비스를 이용할 수 있다. 데이터베이스가 크기 때문에 사용자의 수요증가에 대응하여 클러스터링하여 더 늘릴 수 있다.
- 시스템전체에 데이터가 많다. 여러 데이터베이스로 구성되기 때문에 데이터량도 많아진다.
- 애플리케이션 오류로 인한 위험성 제거

welcome