만들게 된 계기
- 사용자 보유 데이터 기반 통계 분석 API를 만들며, 데이터 집계와 성능을 고려한 경험
- 사용자들은 자신에 대한 통계를 보는 것을 꽤나 좋아함.
계획
1. 사용자 JWT 토큰 기반으로 사용자가 보유한 향수 목록 조회
2. 향수의 탑/미들/베이스 노트 중에서 자주 등장하는 노트를 각각 집계
3. 가장 많이 나온 노트 상위 3개씩을 노트 타입별(Top, Middle, Base)로 반환하는 API만들기.
예상되는 제약 사항
보유 향수가 많을 경우, 향수에 노트가 많을 경우, 응답 속도가 늦을 수 있다.
(밑에 나오지만 그냥 나의 무지성 조인이 더 문제.)
🔸 Lazy Loading vs Eager Loading
향수 → 노트 관계에서 @ManyToMany(fetch = FetchType.LAZY) 설정 여부
불필요한 N+1 쿼리 발생 방지 위해 fetch join 사용 가능
@Query("SELECT up FROM UserPerfume up JOIN FETCH up.perfume p JOIN FETCH p.topNotes tn ...")🔸 데이터 처리 위치
전체 데이터를 불러와서 자바 코드에서 처리하면 CPU 부하가 커질 수 있음.
가능하면 쿼리 레벨에서 집계하거나, 필요한 필드만 가져오도록 projection 고려
예: Redis, Spring Cache 등
🔸 응답 속도 및 테스트
작성 코드
// 가장 선호하는 노트 Top3(보유 향수 기반) 조회
@Transactional(readOnly = true)
public MyTopNotesResponseDto getMyTopNotes(){
Member currentMember = getCurrentMember();
// 사용자 보유 향수 목록 가져오기
List<PerfumeCollected> collected = perfumeCollectedRepository.findByMemberId(currentMember.getId());
// 탑,미들,베이스 노트 집계용 맵
Map<String, Map<NoteValueDto, Integer>> noteCountMap = new HashMap<>();
noteCountMap.put("top", new HashMap<>());
noteCountMap.put("middle", new HashMap<>());
noteCountMap.put("base", new HashMap<>());
for (PerfumeCollected p: collected){
Perfume perfume=p.getPerfume();
List<Perfumescent> notes = perfume.getPerfumescentList();
// 각 노트에서 집계하기
for (Perfumescent ps: notes){
Perfumenote note = ps.getPerfumenote();
if (note == null) {
System.out.println("노트가 없습니다 -" + ps.getScentKr());
continue;
}
// top, middle, base
String scentType = note.getNoteName();
String scentKr = ps.getScentKr();
String scent = ps.getScent();
NoteValueDto noteDto = new NoteValueDto(scentKr, scent);
if (noteCountMap.containsKey(scentType)) {
Map<NoteValueDto, Integer> countMap = noteCountMap.get(scentType);
countMap.put(noteDto, countMap.getOrDefault(noteDto, 0) + 1);
}
}
}
List<NoteWithCountDto> topNotes = getTop3Notes(noteCountMap.get("top"));
List<NoteWithCountDto> middleNotes = getTop3Notes(noteCountMap.get("middle"));
List<NoteWithCountDto> baseNotes = getTop3Notes(noteCountMap.get("base"));
return new MyTopNotesResponseDto(topNotes, middleNotes, baseNotes);
}
private List<NoteWithCountDto> getTop3Notes(Map<NoteValueDto, Integer> noteMap) {
return noteMap.entrySet()
.stream()
.sorted((e1, e2) -> e2.getValue().compareTo(e1.getValue()))
.limit(3)
.map(entry -> new NoteWithCountDto(
entry.getKey().getScent(),
entry.getKey().getScentKr(),
entry.getValue()
))
.toList();
}
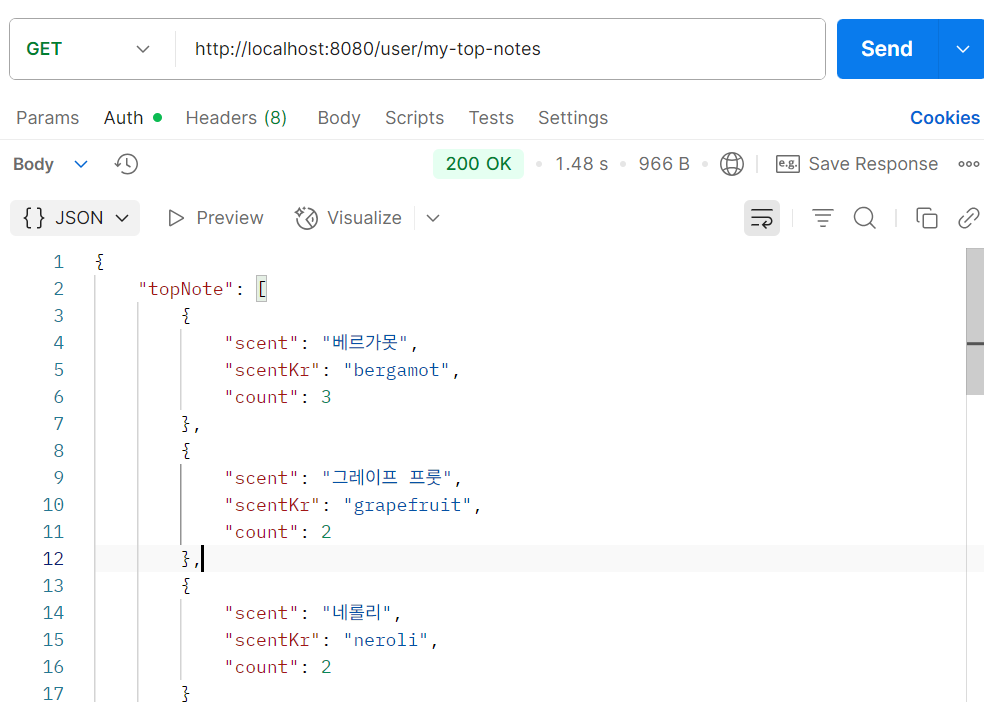
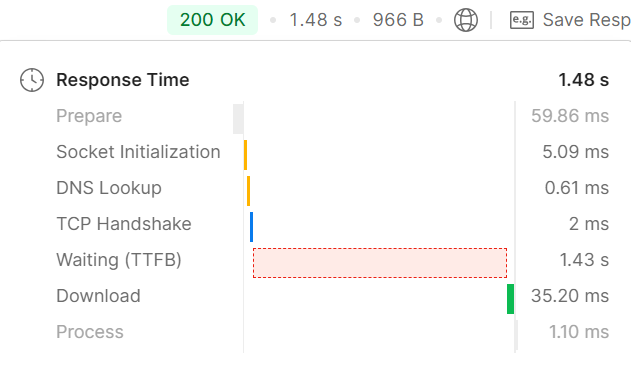
결과
잘 나온다. 포스트맨 기준으로 응답 속도는 1.48초.
※참고로 원래 count를 넣어줄 생각은 없었는데 제대로 된 결과가 나온 것인지 확인하기 위해 넣어주기로 했다.
 |  |
|---|
개선할 점
사실 1.48초면 괜찮은거 아닌가 했는데 아닌거 같다.
로딩 속도는 페이지 이탈과 아주 상관 관계가 높다. 이에 대한 자료도 많다.
구글은 모바일 웹 로딩 시간이 3초 이상 걸리면 53% 이상의 사용자가 이탈한다는 자료를 공개한 적이 있다.
지금 api는 거의 1.5초 걸리는데 기타 상황(프론트엔드, 네트워크 상태 등)을 고려하면 페이지 로딩 시간이 3초에 육박할 가능성이 아주 높다. 솔직히 뭐 엄청 대단한 작업을 처리하는 api도 아니라서 줄여야 할 것 같긴 하다. 근데 얼마나 줄여야 할지 감이 안 와서 찾아봤더니 또 기준이라 할 수 있는 시간들이 정리되어 있더라.
0.1 seconds: Ideal response time, perceived as instantaneous by users.
0.1 to 1 second: Good response time, users notice a slight delay but remain uninterrupted.
1 to 2 seconds: Acceptable for most applications, but may impact user experience in real-time systems.
2 to 5 seconds: Tolerable for non-critical operations, but users may become impatient.
5+ seconds: Generally unacceptable, likely to result in user frustration and abandonment.출처: https://odown.com/blog/what-is-a-good-api-response-time/#acceptable-api-response-times
근데 또 검색하다보니 웹사이트 전체의 로딩 속도가 중요하지, api 하나하나의 속도는 그리 중요하지 않다, 왕초보가 성능 개선을 하는 건 위험하다?('premature optimization is the devil's volleyball')라고 하는 사람들도 꽤 있다.
근데 지금은 이 간단한 걸 만들면서도 성능 문제가 생겼다는거니까 1초 정도 더 줄이면서 공부를 하기로 했다.
개선점 분석
분명히 응답 속도가 느린 원인은 모든 데이터를 가져와서 자바에서 집계하기 때문일 것이다.
어쩐지 이상하더라. 다들 이렇게 쿼리문을 쓰는데 나는 또 자바로... 편하게(?) 집계함수를 만들어버린 것이다.
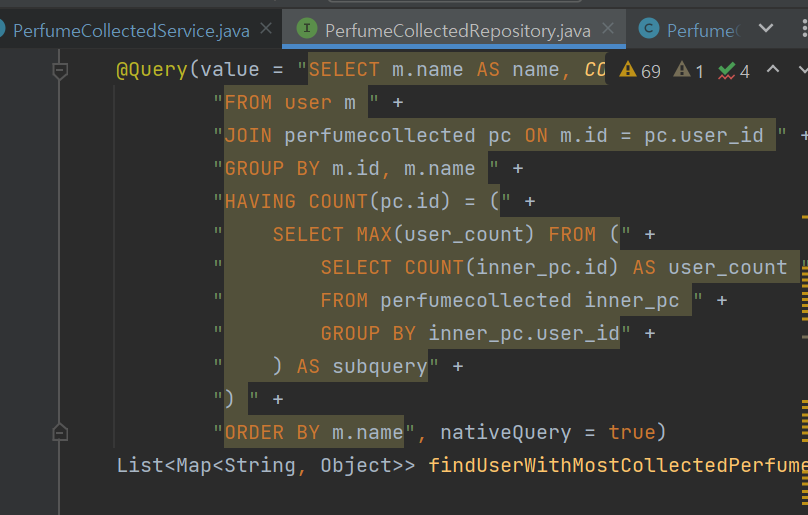
위에 사진 보면 TTFB(Time To First Byte) 시간이 제일 문제인데, 이 원인이 바로 자바에서 직접 집계하고 있던 것이었다.
조금 더 자세히 보면 현재 코드는
1. DB에서 PerfumeCollected, Perfume, Perfumescent, Perfumenote 전체를 가져옴
2. 이 많은 걸 자바가 받아서 for문을 돌리면서 Map에 집계
3. 집계 결과를 다시 DTO로 가공해서 반환
하고 있다.
1~2단계에서 시간이 오래 걸린다는 건 유치원생도 알 수 있을 것이다.
개선 방법
따라서! 나도 쿼리를 써야 한다. DB에서 직접 집계해서 결과만 자바에 전송하도록 해야 한다.
의문점
근데 왜 DB에서 집계하는게 더 빠르지?
찾아보니 DB는 집계에 최적화된 구조와 기능을 가진 전문 도구이기 때문이라고 한다.애초에 CPU, 메모리 효율이 훨씬 좋다고 한다.
사실 DB에는 인덱싱이 다 되어 있다는 점에서 그냥 끝난 이야기 같기도 하다.
반면에 자바는 모든 데이터를 네 트 워 크로 전달받아서(느림) 자바 힙 메모리에 다 올려서 Map 처리(느림)를 한다. 그리고 정렬(느림), DTO 변환(느림) 까지 다 한다.
심한 경우에는 OOM(Out Of Memory) 위험도 있다고 한다.
속도를 직접 재볼 수는 없어서 지피티한테 물어보니까
10만 개의 데이터 기준, DB 집계는 100~300ms, 자바 집계는 1~2초 이상 걸릴 것ㅇ로 예상된다고 한다.
물론 DB집계가 항상 빠른 건 아니지만 데이터가 크고 집계 대상이 명확할 때(DB에서 쿼리문으로 처리 가능한 경우)는 DB에서 처리하는 것이 대부분 빠르다고 한다.
개선 과정
쿼리문을 작성하려고 보니, 쿼리문 작성 방법이 두 가지가 있따고 한다. JPQL과 네이티브 쿼리. 지금 기존 코드는 네이티브 쿼리로 되어 있어서 네이티브 쿼리로 작성할 것 같긴 한데, JPQL이 뭔지, 둘의 장단점을 알아보아야겠다는 생각이 든다.
JPA(Java Persistence API)란?
자바 객체(ex. User, Perfume)를 DB와 연결하고 불러오게 해주는 표준 인터페이스
즉, 자바로 DB를 다룰 수 있게 하는 표준 API다.
이 JPA의 일부로 등장한 것이 JPQL이다.
JPQL(Java Persistence Query Language)이란?
DB와 소통을 해야 하는데, 전통 SQL로 하면 불편한 점이 많아서 JPA를 사용하는 개발자가 자바 객체 기반으로 쿼리를 짤 수 있도록 만들어진 언어다.
| 전통 SQL(네이티브쿼리) | JPQL |
|---|---|
| 테이블 중심 | 객체(엔티티) 중심 |
| 테이블 이름, 컬럼 이름 적어야 함 | 엔티티 이름, 필드 이름만 알면 됨 |
| DB에 따라 문법 달라짐(DB종속적) | 자바 코드처럼 일관된 문법(DB독립적, 다른 DB로 쉽게 이전 가능) |
| 결과도 테이블 형식 | 엔티티나 DTO로 바로 매핑 가능 |
| 복잡한 쿼리까지 자유롭게 사용 가능 | 일반적으로 비슷하나 복잡한 쿼리는 제약 존재 |
개선 코드
@Query(value= """
SELECT ps.scent, ps.scent_kr, COUNT(*) as count
FROM perfumecollected pc
JOIN perfume p ON pc.perfume_id=p.id
JOIN perfumescent ps ON ps.perfume_id=p.id
JOIN perfumenote pn ON ps.note_id=pn.id
WHERE pc.user_id = :memberId AND pn.note_name=:noteType
GROUP BY ps.scent, ps.scent_kr
ORDER BY count DESC
LIMIT 3
""", nativeQuery = true)
List<Object[]> findMyTopNotes(@Param("memberId") Long memberId, @Param("noteType") String noteType);무지성 조인 같지만 이거 말고는 방법이 없는걸..
자바를 잘 모르므로 하나하나 뜯어보면
@Query 어노테이션
@Query(value = "...", nativeQuery = true)스프링 데이터 JPA에서 SQL/JPQL을 직접 작성하고 싶을 때 사용하는 기능.
value 의 쌍따옴표 안에는 SQL 쿼리가 들어간다. nativeQuery=true는 네이티브 쿼리를 사용할 때 쓰고, 기본값은 false라서 JPQL을 사용할 때는 생략이 가능한 부분이다.
쌍따옴표 세 개를 쓰는 이유??
Java 15부터 지원되는 텍스트 블록(Text Block) 문법이다. 여러 줄 문자열을개행 포함해서 편하게 쓰기 위해 등장했다.
원래는 개행을 하려면 줄바꿈 문자를 넣고 양쪽에 따옴표 열고 닫고 +로 이어줘야 했다. 가독성이 나빴다는 것이다.
쿼리문 다 쓴 다음에 맨 마지막 줄은 또 왜 쓰는거야?
우선 List<Object[]>는 쿼리 결과가 행 단위로 여러 개 오고, 각 행은 Object 배열로 구성되어 있다는 것을 알려주는 것이다. 지금 결과로 나오는 것이 scent, scent_kr, count인데 이걸 한 줄씩 Object[]로 묶어서 리스트로 리턴한다.
그리고 @Param("memberId")는, 쿼리 안의 :memberId 자리에 메서드 인자 값인 Long memberId를 집어넣어주는 것이다.
개선 시도 결과
2.16초요???
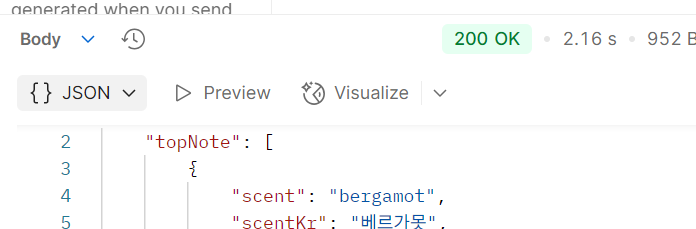
두 번째부터는 31ms~60ms 밖에 안 걸리는데, 첫 시도 때의 응답 속도가 이렇게 느린 건 문제가 있따.
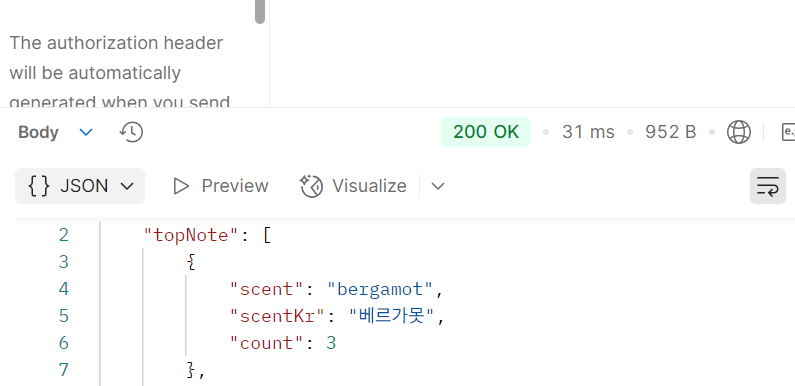
인덱스를 붙였떠니 응답 시간이 줄긴 했다.
1.78초다.