Intro (Business Context)
현재 우리 프로젝트에서 외부 분산 서비스를 다룰 때, 비동기 이벤트식 처리로서 해결하고 있다.
다만 비동기식으로 진행하다보니, 스레드 풀에 대한 설정을 해야만 했다.
올바른 스레드 풀 설정값을 찾음으로써 극강의 효율성을 챙길 수 있기 때문이다.
여기서 여러 의문점이 제기되었다.
우리는 과연 스레드에 대해서 알고 사용하는 것인가?
스레드 풀에 대한 기본설정값은 어떻게 잡혀있으며, 어떤 공식에 따라 설정할 수 있을까??
TL;DR
1. Thread Pool 의 작동방식은 1) corePoolSize 만큼 실행하다가, 2) Work Queue 에 task 를 대기하고, 3) work Queue 가 가득참에 따라 thread pool 이 maxPoolSize 만큼 늘어나는 구조로 동작한다.
2. corePoolSize 에 대해서는
"CPU 코어수 * CPU 사용률 * (1 + I/O입력시간대기효율)"공식을 사용하자.3. db connection pool 에 대해서는
"(cpu 개수 * 2) + DB 서버가 관리할 수 있는 동시 I/O 요청 수"공식을 사용하자.4. 웬만하면 queueCapacity 와 maxPoolSize 는 건드리지 말자. 성능이슈도 있고, 더군다나 사용자의 요청수를 예측할 수 없기 때문이기도 하다.
What is Thread, Process
우선적으로 스레드와 프로세스의 차이점에 대해 살펴보았다. 스택과 레지스터에 관해서 설명을 해야하지만, 주요쟁점이 아니므로 생략하도록 한다.
짧게 요약하자면, 프로세스는 실행되는 프로그램의 인스턴스를 말하며, 메모리를 가지고 있고, 여러 상태 중 하나에 놓인다.
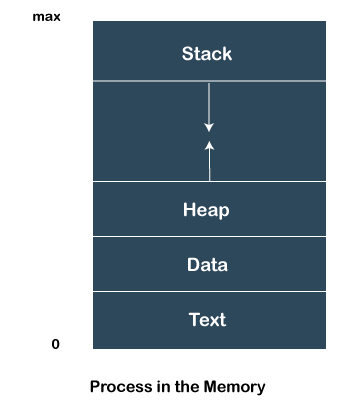
- NEW: A new process is being created.
- READY: A process is ready and waiting to be allocated to a processor.
- RUNNING: The program is being executed.
- WAITING: Waiting for some event to happen or occur.
- TERMINATED: Execution finished.
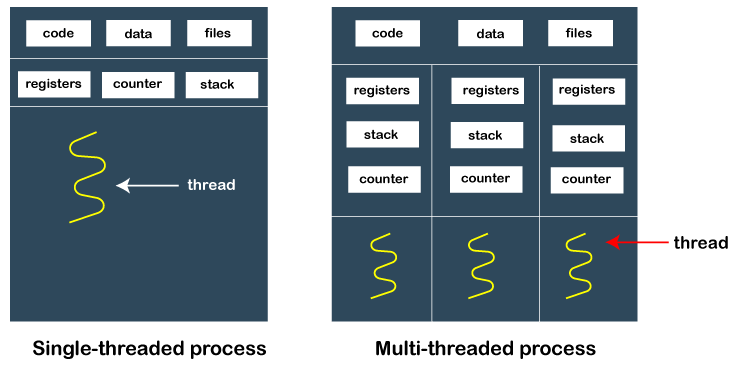
이와 달리, 스레드는 프로세스의 subset 으로서, 하나의 작업단위에 대해 하나 이상의 스레드가 할당된다.
공통 데이터 -- data segment, code segment, file 등등 -- 을 공유하지만, 각각의 스레드 별로 레지스터와 스택과 카운터가 할당된다.
user level thread / kernel level thread 와 같은 더욱 자세한 사항들은 다음 링크를 통해 살펴보자.
Why Thread pool ?
그렇다면 왜 Thread Pool 을 사용할까??
근본적인 이유는 "스레드 자체가 리소스" 이기 때문이다.
어떤 작업을 위해 스레드를 무차별적으로 생성하게 되면, CPU 자원을 -- 특히 코어를 -- 무차별적으로 낭비하게 되는 것이고, 이는 성능의 degradation으로 이어지게 된다.
따라서 "스레드를 미리 만들어두고 재사용하자"는 취지에서 스레드 풀을 정의하는 것이다.
스레드 풀의 동작 방식은 다음과 같다.
- 병렬 작업의 형태로 동시 코드를 작성한다.
- 실행을 위해 스레드 풀의 인스턴스에 제출한다.
- 제출한 인스턴스에서 실행하기 위해 재사용되는 여러 스레드를 제어한다.
Why do we setup a thread config ?
스레드 풀 환경설정의 중요성은 "메모리 낭비를 하지 않기 위함"이라고 말해도 과언이 아니다.
즉 메모리 낭비에 대한 파인 튜닝이다.
스레드 풀 내에 너무 많은 양의 스레드를 선점하게 된다면, 비효율적인 코어와 메모리를 선점하게된다.
따라서 얼만큼의 스레드가 필요할지를 측정하여 적정한 값의 세팅을 해주는 것이 중요하다.
Basic of Thread Pool
Thread Pool 작동방식
Introduction to Thread Pools in Java | baeldung
🧶 Java 에서 스레드 풀(Thread Pool) 을 사용해 보자
ThreadPoolExecutor 동작 방식 및 주의 사항
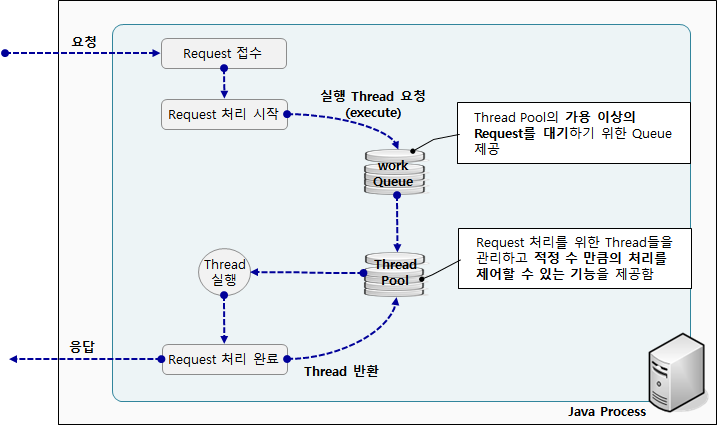
Java에서는 Thread Pool 을 사용하기 위해 ThreadPoolExecutor 을 사용한다.
ThreadPoolExecutor에는 두가지 구조의 저장 공간이 제공된다.
1. Thread 들을 제어하는 공간인 Thread Pool
2. Request 대기를 위한 Work Queue
ThreadPoolExecutor 에 사용되는 옵션들은 다음과 같다.
-
corePoolSize
- ThreadPoolExecutor가 동시에 수행할 수 있는 Thread 수 지정
-
maximumPoolSize
- ThreadPoolExecutor가 최대 수행할 수 있는 Thread 수 지정
-
keepAliveTime
- corePoolSize 보다 더 많은 Thread가 생성될 경우, 추가된 Thread를 정리(제거)하기 위한 대기 시간
-
TimeUnit
- keepAliveTime 옵션값을 위한 시간 단위(Second, millisecond등)
-
workQueue
- ThreadPoolExecutor의 실행가능한 Thread Pool이 없을 경우 Thread를 대기하기 위한 Queue 지정
위와 같은 옵션에 따라 다음과 같이 동작하게 된다.
1. 스레드 풀에서 스레드를 생성할 때 corePoolSize 의 파라미터만큼 코어 스레드를 생성한다.
2. 그리고 새로운 작업이 들어올 때 모든 코어 스레드가 사용 중이고 내부 큐가 가득 차면 스레드 풀의 최대 크기가 maximumPoolSize 만큼 커질 수 있다.
3. 만약 현재 스레드 풀이 corePoolSize 보다 많은 스레드를 가지고 있다면, 초과한 스레드에 대해서 keepAliveTime 파라미터값보다 오랫동안 할 일이 없으면 제거된다.
스레드 풀에 작업요청을 하는 방식
스레드 풀에 작업요청을 하는 방식은 execute( ), submit( ) 방식이 있다.
-
execute 방식은 작업 처리 중에 예외가 발생하면 해당 스레드가 종료되고 스레드 풀에서 제거한 뒤, 새로운 스레드를 생성하여 다른 작업을 처리한다. 또한 처리결과를 반환하지 않는다.
-
반대로 submit 은 작업 처리 중에 예외가 발생하더라도 스레드가 종료되지 않고 다음 작업에 사용된다. 또한 처리 결과를 Future<?> 로 반환한다.
따라서 스레드 풀을 사용할 때 submit 을 사용하는 점이 더 바람직하다.
corePoolSize & maxPoolSize & queueCapacity 관계에 따라 다르게 동작한다.
오라클에서 제공하는 ThreadPoolExecutor의 JavaDoc을 읽어보면, corePoolSize와 maxPoolSize에 대해 다음과 같이 기술되어 있다.
JavaDoc
A ThreadPoolExecutor will automatically adjust the pool size (see getPoolSize()) according to the bounds set by corePoolSize (see getCorePoolSize()) and maximumPoolSize (see getMaximumPoolSize()). When a new task is submitted in method execute(Runnable), and fewer than corePoolSize threads are running, a new thread is created to handle the request, even if other worker threads are idle. If there are more than corePoolSize but less than maximumPoolSize threads running, a new thread will be created only if the queue is full. By setting corePoolSize and maximumPoolSize the same, you create a fixed-size thread pool. By setting maximumPoolSize to an essentially unbounded value such as Integer.MAX_VALUE, you allow the pool to accommodate an arbitrary number of concurrent tasks. Most typically, core and maximum pool sizes are set only upon construction, but they may also be changed dynamically using setCorePoolSize(int) and setMaximumPoolSize(int).
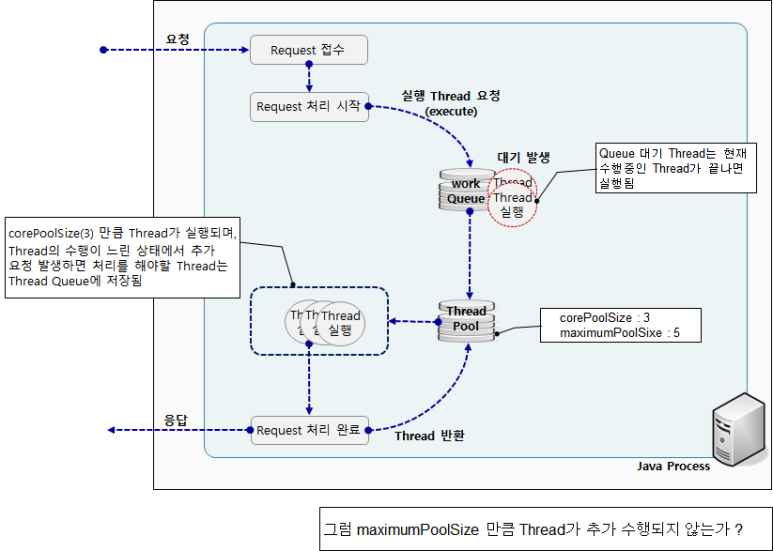
execute 혹은 submit을 통해 새로운 Runnable 실행을 ThreadPoolExecutor에게 요청했을 때, 아래와 같이 처리된다.
1. workQueue 에 Thread 대기
2. 현재 수행 중인 Thread 가 끝나면, workQueue 로부터 대기 중인 Thread 를 Thread Pool 로 옮김
3. Thread Pool 의 Thread 들이 corePoolSize 만큼 실행됨.
4. ThreadPoolExecutor는 기본적으로 corePoolSize만큼의 Thread가 수행중이라면 추가적인 요청에 대한 처리 Thread는 Queuing 처리한다.
5. Queue 가 다 차면, 그제서야 maxPoolSize 옵션이 적용된다.
-
corePoolSize보다 적은 Thread가 수행되고 있었던 경우
- 실행 요청한 Runnable을 수행하기 위한 Thread를 새로 생성하여 즉시 실행
-
corePoolSize보다 많은 Thread가 수행되고 있지만, maxPoolSize보다 적은 수의 Thread가 수행되고 있는 경우
- Queue가 가득 차지 않은 경우
- 즉시 실행하지 않고 Queue에 Runnable을 넣는다.
- Queue가 가득 찬 경우
- maxPoolSize까지 Thread를 더 만들어 실행한다.
- Queue가 가득 차지 않은 경우
Default value of Thread Pool
Configure the Spring ThreadPoolTaskExecutor.
흠 그렇다면 corePoolSize, maxPoolSize, queueCapacity 에 대한 기본설정값은 무엇이고 그에 대한 이유가 무엇일까???
javadoc
The default configuration is a core pool size of 1, with unlimited max pool size
and unlimited queue capacity. This is roughly equivalent to
java.util.concurrent.Executors#newSingleThreadExecutor(), sharing a single
thread for all tasks.
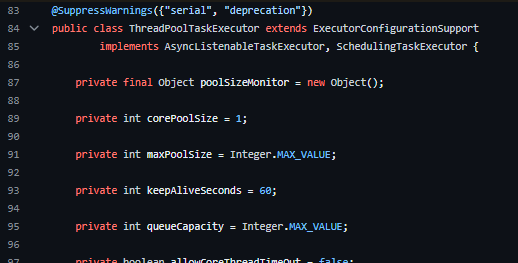
초기 스레드 풀의 크기값인 core pool size 은 1이며, max pool size와 queue capcity 는 Integer.MAX_VALUE 로 설정되어있다.
또한 keepAliveSeconds 은 60으로 설정되어있다.
core pool size 만큼 스레드가 실행되므로 하나의 스레드가 처리된다.
이 때, work queue 가 꽉 차야지만 새로운 thread가 생성되거나 maxPoolSize 까지 Thread를 생성한다.
queue capacity 와 maxPoolSize 에 대한 기본값을 unlimit 으로 설정하게 함으로써 새로운 스레드가 생성되지 못 하게끔 하게 한 것이다.
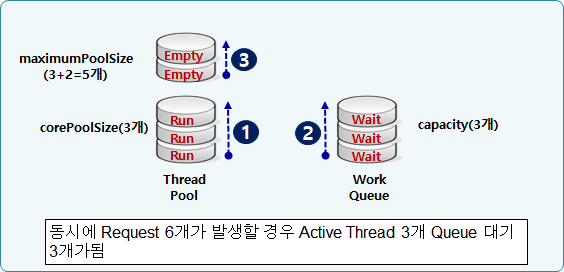
만약 아래와 같이 설정을 변경했다고 하자.
corePoolSize=3
maxPoolSize=5
queueCapacity=200그럼 아래와 같이 동작하게 될 것이다.
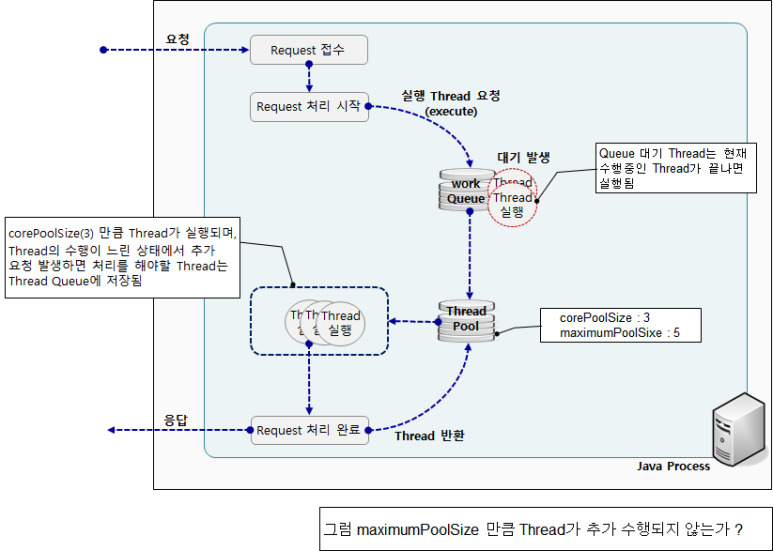
-
처음 3개의 스레드(작업)이 스레드 풀에서 실행된다.
-
이후 queue capacity 인 200까지 queue가 쌓일 때까지 실행한다. --아직까지 새로운 스레드가 생성되지 않고 스레드 풀의 스레드가 재사용된다.
-
queue 가 꽉 차게 되면, thread pool 은 maxPoolSize 인 5까지 늘어난다.
-
이제 5개의 스레드(작업)이 스레드 풀에서 실행된다.
Saturation Policies
만약 아래와 같은 시나리오와 같이 모든 게 꽉 차버리면 어떻게 될까?
- 모든 Core Threads 가 바쁨
- Work Queue 가 꽉 참
- Thread Pool 가 Max Pool Size 만큼 커짐
rejectedexecutionhandler | baeldung
In the event of a full queue and the max pool size has been reached. The next task submitted for execution will be rejected according to the configured RejectedExecutionHandler. By default this is the AbortPolicy which throws an error. Other pre-existing handers include CallerRunsPolicy, DiscardPolicy and DiscardOldestPolicy.
이를 Saturation Policies (포화 정책) 라고 한다.
다음 정책을 적용함에 따라 포화케이스에 대한 정책들에 따라 스레드를 관리한다.
- ThreadPoolExecutor.AbortPolicy -- 기본전략
- Reject 발생 시 RejectedExecutionException 발생
- ThreadPoolExecutor.CallerRunsPolicy
- Reject된 task를 실행중인 main thread에서 동작한다
- ThreadPoolExecutor.DiscardPolicy
- Reject된 task는 버려진다.
- Exception도 발생하지 않음
- ThreadPoolExecutor.DiscardOldestPolicy
- 가장 오래된 처리되지 않은 요청을 삭제하고 다시 시도한다.
- DiscardPolicy와 마찬가지로 데이터가 유실될 수 있다.
/**
public ThreadPoolExecutor(
int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
RejectedExecutionHandler handler
)
*/
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy()); // 기본은 AbortPolicy엥 그럼 계속해서 스레드를 생성하게 하는 게 좋은 거 아니야??
왜 fixed size 로 thread pool 을 관리해야할까?
요청에 대해서 스레드를 생성 및 재사용하게 해서 최대한 빨리 응답해주는 게 가장 효율적인 것 아닌가?
라고 생각할 수도 있다.
두괄식으로 결론을 짓자면, 아니다
해당 방법은 Java 에서 이미 cachedThreadPool 이라고 만들어 두었다.
cached vs fixed thread pool | baeldung
/**
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
*/
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}보다 싶이, corePoolSize는 0, maximumPoolSize는 최대로, queue 에 대해서는 new SynchronousQueue<Runnable>()); 을 사용했다.
cachedThreadPool 은 SynchronousQueue 을 사용하는데, 서로 다른 스레드가 동일한 작업에 접근하면 하나의 스레드를 Queueing 하는 식으로 동작한다.
이에 따라 새로운 task 가 요청되면, 적합한 스레드가 queue 에 있다면 부여를 하고, 꽉 찼다면 새로운 스레드를 생성한다.
cachedThreadPool 은 말 그대로 0 스레드부터 Integer.MAX_VALUE까지 사용할 수 있다.
더 나은 리소스 관리를 위해, 1분 동안 idle 상태로 남아있는 스레드는 자동적으로 제거된다.
Defact of cachedThreadPool
"오 그럼 이거 쓰면 끝이네?" 라고 생각할 수도 있다.
아니다.
cachedThreadPool 은 SynchronousQueue 를 통해 task 를 쌓아둔다.
따라서, I/O task 와 같은 실행시간이 예측불가능한 작업인 경우, 대기열이 밀리게 된다.
이에 따라 cachedThreadPool은 새로운 스레드들을 무지막지하게 생성하게 되고, 엄청난 CPU 컨텍스트 스위칭을 불러일으킨다.
따라서 cachedThreadPool은 적합한 양의 (reasonable number of) 짧은 실행시간의 작업 (short-lived tasks) 에 적합하다.
이러한 이유로 우리는 fixed thread pool 을 지향하는 것이다.
Things to consider for optimization of Thread Pool
Task : CPU-Intensive Tasks & I/O-Intensive Tasks
CPU-Intensive Tasks
CPU-intensive task 들은 복잡한 계산을 수행하거나 시뮬레이션을 실행하는 등 많은 처리 능력이 필요한 작업입니다.
이러한 작업은 종종 I/O 장치의 속도가 아니라 CPU의 속도에 의해 제한된다.
- 오디오 또는 비디오 파일 인코딩 또는 디코딩
- 소프트웨어 컴파일 및 연결
- 복잡한 시뮬레이션 실행
- 머신 러닝 또는 데이터 마이닝 작업 수행
- 비디오 게임 플레이
Optimization
멀티 스레딩 및 병렬 처리: 큰 작업을 작은 하위 작업으로 나누고 이러한 하위 작업을 여러 CPU 코어 또는 프로세서에 분산하여 동시 실행을 활용하는 병렬 처리를 통해 전반적인 성능을 향상시킬 수 있다.
하지만 웬만한 백엔드의 task 는 다음에 소개할 I/O Intesive Task 들이다.
I/O-Intensive Tasks
IO-intensive task 들은 저장 장치(예: 파일 읽기/쓰기), 네트워크 소켓(예: API 호출) 또는 사용자 입력(예: 그래픽 사용자 인터페이스에서의 사용자 상호 작용)과 상호 작용하는 작업이다.
- 디스크에 대용량 파일 읽기 또는 쓰기(예: 동영상 파일 저장, 데이터베이스 로드)
- 네트워크를 통한 파일 다운로드 또는 업로드(예: 웹 검색, 스트리밍 비디오 시청)
- 이메일 보내기 및 받기
- 웹 서버 또는 기타 네트워크 서비스 실행
- 데이터베이스 쿼리 수행
- 들어오는 요청을 처리하는 웹 서버
Optimization
최적화
- 캐싱: 자주 액세스하는 데이터를 메모리에 캐시하여 반복적인 I/O 작업의 필요성을 줄인다.
- 로드 밸런싱: I/O 바운드 작업을 여러 스레드 또는 프로세스에 분산하여 동시 I/O 작업을 효율적으로 처리가능하다.
- SSD 사용: SSD(솔리드 스테이트 드라이브)는 기존 HDD(하드 디스크 드라이브)에 비해 I/O 작업 속도를 크게 높일 수 있다.
- 해시 테이블이나 B-트리와 같은 효율적인 데이터 구조를 사용해 필요한 I/O 작업의 수를 줄이자.
- 파일을 여러 번 열고 닫는 등 불필요한 파일 작업을 피하자.
그렇다면 I/O Intensive Task 에 관한 Thread Config 는 어떻게 정할 수 있을까??
먼저 아래 코드를 통해 프로세스 코어, 즉 CPU 코어를 확인해보자.
int numOfCores = Runtime.getRuntime().availableProcessors();이에 따라 아래의 공식을 사용하여 corePoolSize 를 통해 활성스레드의 크기를 정할 수 있다.
How to Determine Java Thread Pool Size: A Comprehensive Guide
Number of threads = Number of Available Cores * Target CPU utilization * (1 + Wait time / Service time)Number of Available Cores:
애플리케이션에서 사용할 수 있는 CPU 코어 수이다.
각 CPU에는 여러 개의 코어가 있을 수 있으므로 CPU 수와 동일하지 않다는 점에 유의하자.
Target CPU utilization:
애플리케이션에서 사용하려는 CPU 시간의 백분율이다.
목표 CPU 사용률을 너무 높게 설정하면 애플리케이션이 응답하지 않을 수 있다.
너무 낮게 설정하면 애플리케이션이 사용 가능한 CPU 리소스를 완전히 활용하지 못할 수 있다.
Wait time:
스레드가 I/O 작업이 완료될 때까지 대기하는 데 소요되는 시간이다.
여기에는 네트워크 응답, 데이터베이스 쿼리 또는 파일 작업 대기 등이 포함될 수 있다.
Service time:
스레드가 계산을 수행하는 데 소요되는 시간이다.
Blocking coefficient == (Wait time / Service time):
대기 시간과 서비스 시간의 비율이다.
스레드가 계산을 수행하는 데 소요되는 시간 대비 I/O 작업이 완료될 때까지 대기하는 데 소요되는 시간을 측정한 값이다.
가령 4 CPU 코어에 대해 CPU 자원의 20% 를 사용하고자 하고, I/O 입력에 대해 40% 정도의 시간대기효율을 원한다치자.
이 때, corePoolSize 값은 아래와 같이 구할 수 있을 것이다.
Number of threads = Number of Available Cores * Target CPU utilization * (1 + Wait time / Service time)
Number of Available Cores : 4
Target CPU utilization : 0.2
Blocking coefficient : 0.4
Number of threads = 4 * 0.2 * (1 + 0.4) = 1.12 threadsUseful tips on thread pool config setup
서비스 특성에 따라 유용한 팁이 있어서 퍼와보았다.
그리고 ThreadPoolExecutor 사용 시 주요하게 고려해야 할 사항은 위에서도 언급했다 시피
업무의 특성에 따라 적절한 설정이 필요하다는 것입니다.
다시 한번 언급한다면 다음과 같습니다.
일정한 량의 처리가 필요한 업무의 경우는 corePoolSize와 maximumPoolSize를 업무 처리량에 맞춰서 동일하게 설정하고, 대신 Queue를 적절하게 설정하여 처리 대기를 시키는게 좋으며,
반대로 처리량이 시간대별로 다르게 증감이 있다면 corePoolSize와 maximumPoolSize를 다르게 설정하고 대신 Queue의 크기를 작게 설정하여
추가적인 Thread 실행이 원활하게 이루어 지도록 하는게 좋다는게 제 생각입니다.
ThreadPoolExecutor 동작 방식 및 주의 사항
DB Connection Pool Size 또한 설정값을 고려해보아야 한다.
그리고 보통 DB Connection 도 Pool Size를 조정해야하는데 이 또한 고려해야한다.
보통 아래의 수식을 사용해서 계산한다고 한다.
*Spring Boot의 기본전략인 HickariCP는 10
connections = ((core_count * 2) + effective_spindle_count)내가 만든 서비스는 얼마나 많은 사용자가 이용할 수 있을까? - 3편(DB Connection Pool)
core_count * 2 를 하는 이유 ?
여기서 말하는 core_count는 현재 사용하는 Cloud 서버 환경에서는 논리 Cpu 개수와 동일하다.
근데 왜 * 2 를 할까??
core_count * 2를 하는 이유는 Context Switching 및 Disk I/O 와 관련이 있다.
Context Switching으로 인한 오버헤드를 고려하더라도 데이터베이스에서 Disk I/O 혹은, DRAM이 처리하는 속도보다 CPU 속도가 월등히 빠르다.
이로 인해 Thread가 Disk와 같은 작업에서 Blocking 되는 시간에 다른 Thread의 작업을 처리할 수 있는 여유가 생기게 된다.
이러한 여유 정도에 따라 멀티 스레드 작업을 수행할 수 있게 된다.
Hikari CP가 제시한 공식에서는 계수를 2로 선정하여 Thread 개수를 지정하였다.
effective_spindle_count ?
effective_spindle_count는 하드 디스크와 관련이 있다.
하드 디스크 하나는 spindle 하나를 가진다.
이에 따라 spindle의 수는 기본적으로 DB 서버가 관리할 수 있는 동시 I/O 요청 수를 말한다.
디스크가 16 개가 있는 경우 시스템은 동시에 16 개의 I/O 요청을 처리할 수 있다.
물론 RAID 구성 방식에 따라서 달라질 수 있다.
해당 공식에서 디스크의 효율을 고려하여 spindle_count를 더해준 것으로 보인다.
Connection Pool 에 대해서는 Thread Pool 과 궤를 같이하고 굉장히 중요하므로 이는 따로 포스팅을 만들 예정이다.
끝나지가 않는다,, 이런 제길,,
How to caught async exception
비동기 메서드에 대한 예외는 @ControllerAdvice에서 catch 하지 못 한다.
@ControllerAdvice는 오직 동기적 예외만 잡을 수 있다.
Async will not call by controlleradvice for global exception
@ExceptionHandler was created to catch only "synchronous exceptions". If it had the ability to catch exceptions from asynchronous threads, then when several threads start and if any of them fail, the request to the server would be interrupted completely and the system could remain in an inconsistent state (due to many other active threads generated by this request)
또한, Future 반환 형이라면 Future.get() 에서 exception 을 던지지만, void 반환 형이라면 calling thread 에게 exception 이 전파되지 않는다.
spring async exception handling | baeldung
When a method return type is a Future, exception handling is easy. Future.get() method will throw the exception.But if the return type is void, exceptions will not be propagated to the calling thread. So, we need to add extra configurations to handle exceptions.
이를 위해 Spring 에서는 AsyncUncaughtExceptionHandler 인터페이스를 지원한다.
보통 아래와 같이 exception handler 를 helper class 로 분리하고, 예외 발생 시, helper class 가 처리하게끔 위임하는 것 같다.
@Slf4j
@Component
public class GlobalAsyncExceptionHandler implements AsyncUncaughtExceptionHandler {
@Override
public void handleUncaughtException(Throwable ex, Method method, Object... params) {
log.error("[ASYNC-ERROR] method: {} exception: {}", method.getName(), ex);
}
}
@Configuration
@AllArgsConstructor
public class AsyncConfiguration implements AsyncConfigurer{
private final GlobalAsyncExceptionHandler globalAsyncExceptionHandler;
// Async configuration
@Override
public Executor getAsyncExecutor(){
ThreadPoolTaskExecutor threadPoolExecutor=new ThreadPoolTaskExecutor();
threadPoolExecutor.setCorePoolSize(10);
threadPoolExecutor.setMaxPoolSize(12);
threadPoolExecutor.setQueueCapacity(50);
threadPoolExecutor.setThreadNamePrefix("test-backend-async");
threadPoolExecutor.initialize();
return threadPoolExecutor;
}
//Async Exception configuration
@Override
public AsyncUncaughtExceptionHandler getAsyncUncaughtExceptionHandler(){
return globalAsyncExceptionHandler;
}
}Testing subtle value of AsyncConfig Thread Pool
현재 우리 프로젝트는 분산서비스에 대한 Async 를 위해, Thread Pool Config 를 조정하고 있다고 일전에 소개했다.
그렇다면 어떤 값이 최적의 값일까?
테스트 코드를 통해 확인해보았다.TL;DR
결과적으로는, corePoolSize는 위에서 설명한 공식을 사용, 이외의 값은 그대로 두는 것이 가장 좋은 성능을 발휘하였다.
Default Thread Pool
우선 기본적인 AsyncConfig 를 작성해보자.
@EnableAsync
@Configuration
@Slf4j
@RequiredArgsConstructor
public class AsyncConfig implements AsyncConfigurer {
private final GlobalAsyncExceptionHandler globalAsyncExceptionHandler;
@Override
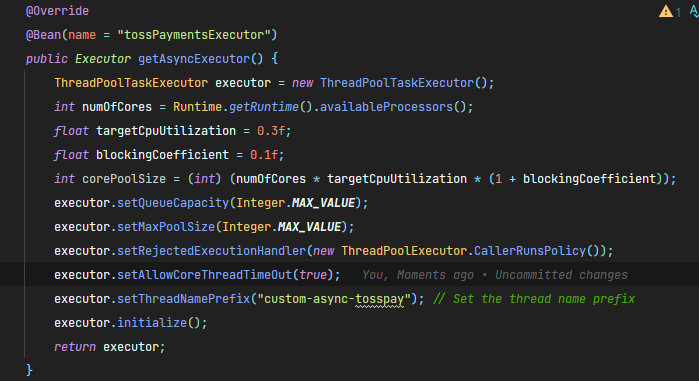
@Bean(name = "tossPaymentsExecutor")
public Executor getAsyncExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setThreadNamePrefix("custom-async-tosspay"); // Set the thread name prefix
executor.initialize();
return executor;
}
@Override
public AsyncUncaughtExceptionHandler getAsyncUncaughtExceptionHandler() {
return globalAsyncExceptionHandler;
}
}테스트를 위한 서비스를 작성해보자.
@Component
public class AsyncService {
@Autowired
private PaymentService paymentService;
@Autowired
private EntityManager entityManager;
@Async("tossPaymentsExecutor")
public void doSomethingAsync() {
// Prepare test data below :
// INSERT INTO gream.tb_toss_payment (created_at, modified_at, amount, is_pay_success, order_id, order_name, pay_fail_reason, pay_type, payment_key, user) VALUES ('2024-03-02 20:05:39.000000', '2024-03-02 20:05:40.000000', 2000, true, 'orderId', 'CHARGE_POINT', null, null, 'paymentKey', null)
String paymentKey = "paymentKey";
String orderId = "orderId";
Long amount = 2000L;
AtomicReference<TossPaymentSuccessResponseDto> responseDtoHolder = new AtomicReference<>();
Semaphore semaphore = new Semaphore(0);
// Simulate some workload
paymentService.requestFinalTossPayment(paymentKey, orderId, amount, responseDto -> {
responseDtoHolder.set(responseDto);
semaphore.release();
});
entityManager.flush();
}
}
위 서비스 코드에서는 페이먼츠 이벤트를 비동기적으로 호출하게끔 하였다.
이제 테스트 코드를 작성해볼 차례다.
@SpringBootTest
@Disabled
@ActiveProfiles("test")
public class AsyncTest {
@Autowired
private AsyncService asyncService;
@Test
@DisplayName("AsyncConfig 에 대한 설정값에 따른 성능개선치를 측정합니다.")
public void AsyncConfig_설정에따른효율_측정() {
// GIVEN
long startTime = System.currentTimeMillis();
// WHEN
int callCount = 10000;
for (int i = 0; i < callCount; i++) {
asyncService.doSomethingAsync();
}
// THEN
long endTime = System.currentTimeMillis();
long elapsedTime = endTime - startTime;
System.out.println("Total time taken: " + elapsedTime + " milliseconds");
int numOfCores = Runtime.getRuntime().availableProcessors();
float targetCpuUtilization = 0.3f;
float blockingCoefficient = 0.1f;
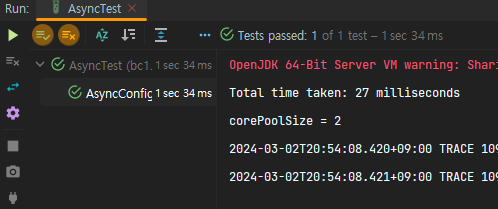
int corePoolSize = (int) (numOfCores * targetCpuUtilization * (1 + blockingCoefficient));
System.out.println("corePoolSize = " + corePoolSize);
}
}기본 세팅을 구성하는 경우 -- corePoolSize = 1; maxPoolSize,queueCapacity = Integer.MAX_VALUE; -- 실행시간은 다음과 같다.
corePoolSize 공식을 통해 성능개선을 해보자.
CPU 코어수 * CPU 사용률 * (1 + I/O입력시간대기효율)
위 공식에 따라 corePoolSize 를 정해주었다.
CPU 사용률은 30% (DB Connection Pool, I/O Task 에 대해서도 생각해야하니 이 정도가 적당하리라 싶었다)
I/O입력시간대기효율은 0.1, 즉 I/O 작업이 완료될 때까지 대기하는 데 10%의 시간 정도면 충분하다고 생각했다.
/**
CPU 코어수 * CPU 사용률 * (1 + I/O입력시간대기효율)
*/
@Override
@Bean(name = "tossPaymentsExecutor")
public Executor getAsyncExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
int numOfCores = Runtime.getRuntime().availableProcessors();
float targetCpuUtilization = 0.3f;
float blockingCoefficient = 0.1f;
int corePoolSize = (int) (numOfCores * targetCpuUtilization * (1 + blockingCoefficient));
executor.setCorePoolSize(corePoolSize);
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
executor.setThreadNamePrefix("custom-async-tosspay"); // Set the thread name prefix
executor.initialize();
return executor;
}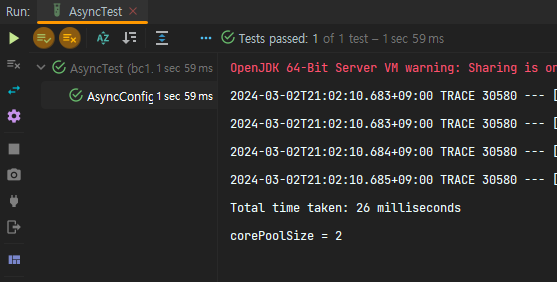
사실 별 차이 없는 것을 볼 수 있었다. ^^;;;
Queue Capacity 에 대해 fixed value 를 지정하면 성능 저하가 발생한다.
자 이제 queue capacity 를 변경해보자.
과연 성능적으로 좋아질까??
@Override
@Bean(name = "tossPaymentsExecutor")
public Executor getAsyncExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
int numOfCores = Runtime.getRuntime().availableProcessors();
float targetCpuUtilization = 0.3f;
float blockingCoefficient = 0.1f;
int corePoolSize = (int) (numOfCores * targetCpuUtilization * (1 + blockingCoefficient));
executor.setCorePoolSize(corePoolSize);
executor.setMaxPoolSize(Integer.MAX_VALUE);
executor.setQueueCapacity(1000);
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
executor.setThreadNamePrefix("custom-async-tosspay"); // Set the thread name prefix
executor.initialize();
return executor;
}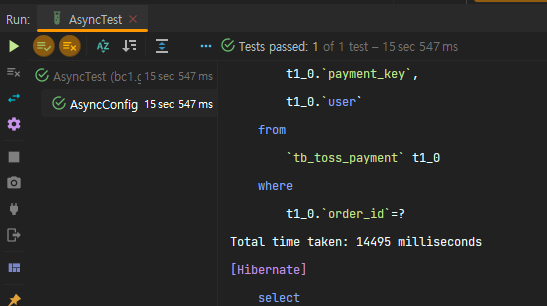
결과적으로는 아니었다. 오히려 성능이 저하되었다.
queueCapacity 인 1000 을 넘어가면 threadPool 의 corePoolSize, 즉 ThreadPoolExecutor가 동시에 수행할 수 있는 Thread 수는 maximumPoolSize 만큼 늘어난다.
그래서 우리 생각에는 corePoolSize 가 늘어나니까 빨라진다고 생각한다.
그런데 아니었다.
오히려 아래와 같이 unbounded capacity queue 가 성능이 더욱 좋았다.
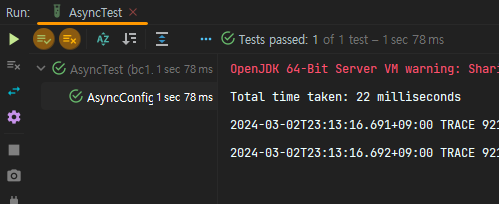
왤까?????
다음과 같은 이유로, unbounded queue 가 압도적으로 성능이 좋다는 것을 깨달았다.
고마워요 개발바닥 단톡방 천사분들,,,ㅠㅠ
-
unbounded queue 를 사용 시, 빠른 이유
: corepoolSize가 넘어도 계속 스레드를 생성하면서 처리하는게 아닌 메모리에 올려두고 처리 -
bounded queue 를 사용 시, 느린 이유
: 비싼 쓰레드 생성 비용을 지불하여 많은 쓰레드를 생성 및 처리하기에, 시간이 오래 걸림
웬만하면 queueCapacity 와 maxPoolSize 는 건드리지 말자
Reference
