Intro
현재 진행되고 있는 기프티콘 중고입찰 시스템 프로젝트에서는 RDB 를 사용한다.
우리는 시스템 확장과 SPOF 를 목적으로 함으로써 AWS RDS 의 Read-Replication 을 통해 파티셔닝을 하기로 하였다.
아래와 같이 구성해주었다.
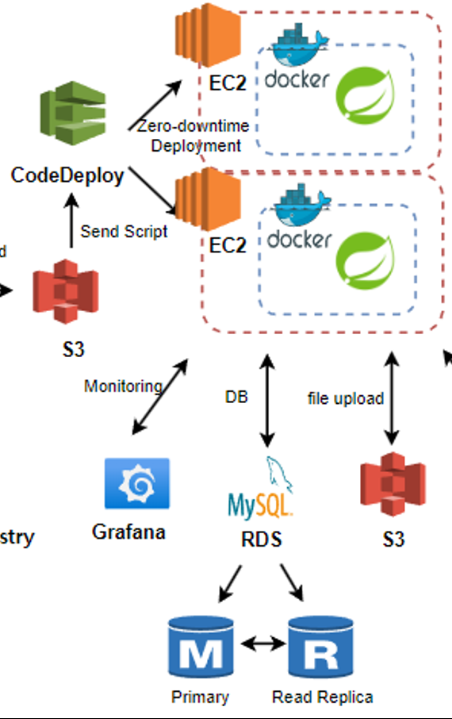
진행하고 있던 와중, 이러한 피드백이 왔다.
분산 데이터베이스 구조를 설계할 때, 적용되는 이론으로 CAP 이론이 있습니다. 이 CAP theorem은 무엇이며 이를 미루어 봤을 때, 해당 현재 Master-Slave 구조를 적용했을 때의 단점은 무엇일까요?
(키워드 : 복제지연) 또한 이러한 특성으로 인해, 해당 서비스가 문제가 될 수 있는 상황은 없을지 생각해보세요.
CAP Theorem 은 무엇이고 Master-Slave의 단점은 무엇일까??
이에 대해 알아보자.
What is CAP Theorem
CAP Theorem 은 2000년 Eric Brewer에 의해 처음 소개되었다.
세 가지 개념에 대한 약자인데, 각각의 의미는 다음과 같다.
-
Consistency
: 일관성이란 모든 읽기 작업이 최신 레코드를 가져오는 것이다. 모든 정보는 최신 상태로 유지되어야 한다. -
Availability
: 가용성은 분산 시스템이 항상 사용 가능함을 나타내는 속성이다. 시스템의 하나 이상의 노드가 죽더라도, 다른 노드를 통해 계속 액세스할 수 있어야 한다. -
Partition Tolerance
: 파티션 허용 오차는 시스템이 분할될 수 있는 능력을 말한다. 따라서 모든 노드가 다른 노드와 독립적으로 작동할 수 있다.
Features of CAP Theorem
CAP 정리에 따르면 분산 시스템은 3가지 속성 중 2가지 속성만 충족할 수 있다.
따라서 CA , AP 또는 CP 시스템 만 있을 수 있습다.
다른 두 속성이 이미 보장되어 있는 동안 세 번째 속성이 달성될 것이라고 보장할 수 없다.
결과적으로 CAP 분산 시스템은 존재하지 않는다.
What is Master - Slave (feat.Replication)
Replication, 즉 복제는 데이터베이스 확장 기술 중 하나이다.
이 기술은 하나의 데이터베이스 서버의 데이터가 하나 이상의 다른 서버(복제본이라고 함)에 지속적으로 복사(복제)될 수 있다는 아이디어를 기반으로 한다.
애플리케이션이 두 개 이상의 서버를 사용하여 모든 요청을 처리하는 것을 가능케 할 수 있다.
따라서 하나의 서버에서 여러 서버로 부하를 분산시키는 것이 가능하다.
일반적으로 메인 노드를 마스터(Master)라고 부른다.
반면 모든 복제본을 슬레이브(Slave)라고 한다.
마스터는 데이터베이스를 변경하기 위한 쓰기 작업만 지원할 수 있다.
그 후 변경 사항은 읽기 작업을 위해 모든 슬레이브의 복제본에 배포된다.
이는 데이터베이스의 일관성을 유지하는 데 도움이 된다.
이러한 복제를 마스터-슬레이브 복제라고 한다.
그러나 마스터와 모든 복제본이 읽기 및 쓰기 작업을 모두 수행할 수 있는 마스터-마스터 복제도 존재한다.
만약 MySQL 을 사용한다면 Async Replication 혹은 Semi Sync Replication 을 활용할 수 있다.
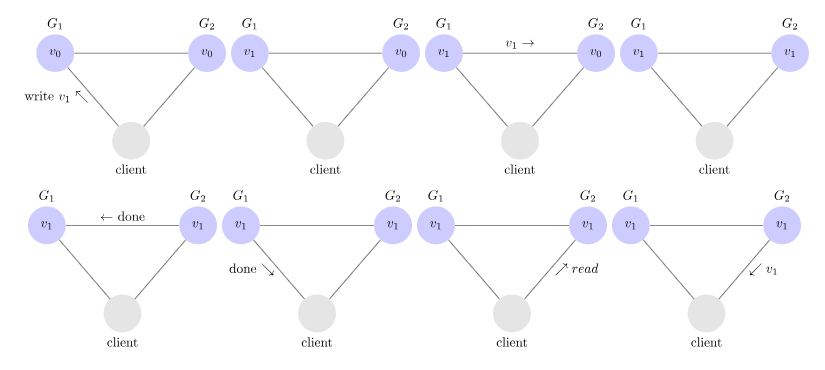
위 그림과 같이 동작한다고 볼 수 있다.
- master 에 데이터를 write
- 이에 따른 데이터를 Replication 노드에 동기화
- client 는 Replication 노드로부터 read 함으로써 일관된 데이터를 읽을 수 있다. -- consitency
이로써 consitency 를 챙길 수 있다.
Database & CAP
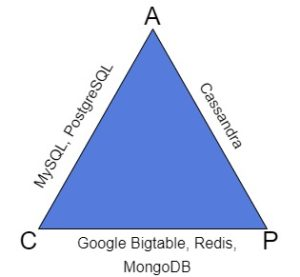
보시다시피 다양한 유형의 데이터베이스는 CA , AP 또는 CP 시스템으로 엄격하게 분류된다.
CA 시스템
CA 시스템은 일관성과 가용성을 보장한다.
대부분의 관계형 데이터베이스는 CA 시스템이다.
예를 들어 PostgreSQL에서는 마스터-슬레이브 복제와 2단계 트랜잭션 커밋 접근 방식을 통해 일관성을 지원한다.
마스터와 복제본의 동기화는 동기식 또는 비동기식이며 시스템의 가용성이 뛰어납니다.
문제는 분할할 때이다. PostgreSQL에서 파티셔닝을 사용하려고 하면 일관성이 보장되지 않기 때문이다.
AP 시스템
AP 시스템은 가용성과 파티션 허용성에 관한 것이다.
결과적으로 항상 일관성이 없을 수도 있다.
AP 시스템 의 예로는 NoSQL 데이터베이스인 Cassandra가 있습니다.
이는 실제로 AP 시스템 정의를 따르는 마스터-마스터 복제를 사용한다.
Cassandra에 대한 파티셔닝을 쉽게 수행할 수 있다.
여기서, 모든 노드는 독립적인 단위가 되는데, 이에 따라 노드 중 하나 이상이 작동하면 시스템을 사용할 수 있습니다.
그러나 분할된 노드 간의 동기화로 인해 일관성이 저하될 수 있습니다.
CP 시스템
CP 시스템은 일관성이 있고 파티션을 허용하는 시스템이다.
예를 들어 MongoDB는 NoSQL 데이터베이스이자 CP 시스템이다.
쓰기 작업에 단일 마스터 노드를 사용하면 높은 일관성을 확보할 수 있다.
또한 MongoDB는 일관성을 잃지 않고 분할될 수 있다.
그러나 파티션을 나누는 경우 사용하지 못할 수도 있다.
따라서 시스템은 모든 작업이 안전하게 저장될 때까지 쓰기 요청을 수락하지 않는다.
Defect of Master - Slave in Distributed System
분산 시스템에서의 Master-Slave 구조는 CA 지향적이다.
Master-Slave 간 동기화를 통해 일관성을 지향하고, 복제본을 통해 계속된 읽기작업을 지원하여 가용성을 지향한다.
하지만 데이터에 대해 분할, 즉 전체 데이터를 서로 다른 공간에 분할하여 서비스를 지원하는 구조를 활용할 수는 없다.
이는 분산서비스나 규모 확장에 치명적인 단점으로 남는다.
또한 Master-Slave 구조의 취약점은 사실상 하나 더 있다.
분산 시스템에서의 Master-Slave 구조의 취약점은 Slave와 Master의 동기화에 있다.
1) Master-Slave 간 동기화 지연
널리 쓰이는 MySQL 은 Master 와 Slave 간 동기화를 Async 로서 제공한다.
(Semi Sync 또한 있지만 Latency 의 간극차를 줄일 뿐 완전한 Sync 로 작동하는 건 아니다.)
따라서 읽기 작업을 하는 도중, 쓰기 작업에 따른 데이터를 반영하는 것이 불가능하다.
요컨대, 읽기 작업에 대한 데이터는 약간의 Latency가 존재하기 마련이다.
2) Master-Slave 간 Connection 유실
만약 Master 와 Slave의 연결이 끊겼다고 가정해보자.
여러 Slave 중 하나가 잃게 되더라도 가용성(Availability) 은 확보할 수 있지만, Master 와 다른 데이터를 제공하기에 동일한 데이터를 읽기를 지원하기에 일관성(Consistency)은 지원할 수 없다.
따라서 CA 중 C 만을 제공하게 된다.
How to Overcome
-
스케일 업
-
NoSQL로 이전
-
Galera Clustering
- P 에 대한 지원을 할 수 없지만, Master 와 Slave 간 Latency 를 최소화함으로서 A를 극강으로 올릴 수 있다.
-
데이터 샤딩
Reference
https://www.baeldung.com/cs/brewers-cap-theorem
https://mwhittaker.github.io/blog/an_illustrated_proof_of_the_cap_theorem/
https://medium.com/nerd-for-tech/cap-theorem-with-focus-on-partition-tolerance-1af4403cb35a
https://dongwooklee96.github.io/post/2021/03/26/cap-%EC%9D%B4%EB%A1%A0%EC%9D%B4%EB%9E%80/
