Intro
현재 진행 중인 Gream 프로젝트에서는 AWS RDS Read Replication 을 활용한 Master-Slave 구조를 사용하고 있다.
특히, CAP 에서 CA 를 최대한 만족하려고 노력했다.
-
C(Consistency) : RDB 를 사용하여 일관된 데이터를 지원
-
A(Availability) : 어떠한 노드가 죽더라도 사용자로 하여금 끊김없는 서비스 가용 확보
- Mater 노드가 죽는 경우, Slave 가 승격
- Slave 노드가 죽는 경우, 다른 Slave 노드로 트래픽 분산
안타깝게도 RDB의 Master-Slave 구조는 Partition Tolerence 를 충족하기가 어렵다.
일관된 구조의 스키마와 그에 따른 데이터로 동작하기에 여러 DB 서버를 독립적으로 운영하여 서로 다른 데이터를 저장하여 운영하기가 어렵기 때문이다.
또한 Master-Slave 간 Connection 유실 가능성이라는 취약점도 존재한다.
Master(1) 에 여러 Slave(N) 를 지원하기 때문이다.
이를 극복하기 위해 Multi Master 을 지원하는 Galera Cluster 에 대해 살펴보도록 한다.
About Galera Cluster
Why use Galera Cluster (==purpose)
Galera Cluster 의 목표는 뚜렷하다.
Aiming Ultimate Availabilty using True Multi-master
공식문서 상으로도, 아래와 같은 장점을 나열하고 있다.
- True Multi-master, Active-Active Cluster Read and write to any node at any time.
- Synchronous Replication No slave lag, no data is lost at node crash.
- Multi-threaded Slave For better performance. For any workload.
어떻게 Multi-Master 를 지원할까??
이에 앞서서 원래 MySQL Replication이 동작하는지를 살펴보아야한다.
How MySQL Replication works
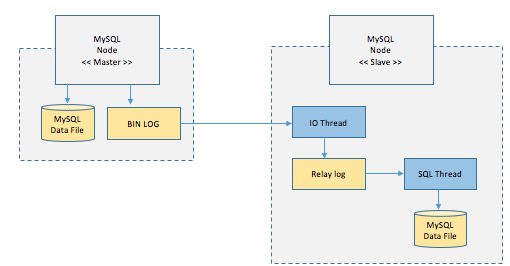
-
좌측의 Master Node에 쓰기 트렌젝션이 수행되면 Master node는 데이타를 저장하고, 트렌젝션에 대한 로그를 내부적으로 BIN LOG라는 파일에 저장한다. (시간 순서대로 수행한 업데이트 트렌젝션이 기록되어 있다.)
-
Slave Node에서는 이 BIN LOG를 복사해온다. 이 복사 작업을 IO Thread라는 스레드가 수행하는데, 이렇게 읽어온 내용은 Replay Log라는 파일에 기록이 된다.
-
이렇게 기록된 내용은 SQL Thread라는 스레드가 읽어서, 하나씩 수행을 해서 MySQL 데이타 파일에 기록을 한다.
쉽게 설명하면, insert 쿼리를 master node에서 실행했으면 그 쿼리가 master node의 bin log에 기록이 되고, 이 내용은 slave node에 복사가 된후에, slave node에서 같은 쿼리가 수행이 되서 복제가 반영되는 방식이다.
Benefits / Defects of MySQL Replication
- 신뢰도가 높은 반면, 단점으로는 읽기와 쓰기 노드를 분리해야 한다.
- 데이타 복제가 동기 방식이 아닌 비동기 방식으로 적용되기에, master node에 적용한 데이타 변경사항이 slave에 반영될때까지 일정 시간이 걸린다. 이로 인해 master와 slave node간의 순간적인 데이타 불일치성이 발생할 수 있다.
How Galera works
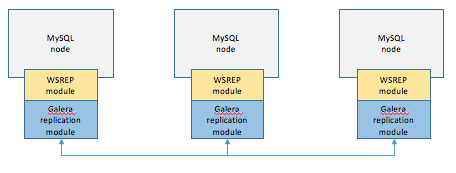
-
각각의 노드가 있을때, 아무 노드에나 쓰기나 업데이트가 발생한다.
-
모든 노드에 데이타를 복사를 완료한다.
-
업데이트 내용이 파일에 저장된다.
아키텍쳐상의 구조를 보면, 위의 그림과 같이 각 MySQL 노드에는 WSREP 라는 모듈이 있다.
이 모듈은 데이타베이스에 복제를 위한 범용 모듈로 여기에 마치 드라이버처럼 Galera replication module을 연결해준다.
만약 데이타 변경이 발생하면, 변경요청이 있을때 마다, 이 Garela replication module이 다른 mysql node로 데이타를 복제한다.
어떻게 module 이 모든 node로 Synchronous 하게 동기화하는지 자세히 더 살펴보도록 하자.
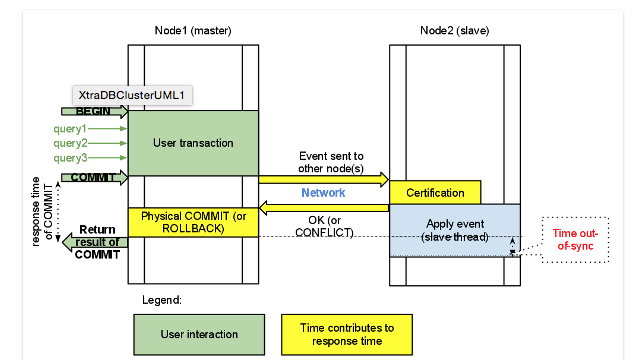
-
노드에 트랜젝션이 발생하고 COMMIT이 실행된다.
-
디스크에 내용을 쓰기 전에 다른 노드로 복제를 요청한다.
-
다른 노드에 복제 요청이 접수되었을때, 해당 노드의 디스크에 실제로 데이타를 쓰게 된다.
이러한 특성으로, 전체 노드에 데이타가 항상 일관성있게 저장되고, 모든 노드가 마스터 노드로 작동을 하며, 특정 노드가 장애가 나더라도 서비스에 크게 문제가 없다.
(MySQL Replication의 경우 마스터 노드가 장애가 나면 슬레이브 노드중 하나를 마스터로 승격을 해야하는 등 다소 운영 프로세스가 갈레라에 비해서는 복잡하다.)
외관적으로는 가용성이나 일관성 측면에서는 최적의 솔루션인 것 같다.
단점은 없을까??
Benefits / Defects of Golera Cluster
Benefits
- 모든 노드에서 Read/Write 가능
- Master-Slave 지연이 없다
- SPoF 방지 : 특정 노드 장애 발생 시,Galera Load Balancer 를 통해 다른 노드로 전환되기에 SPoF 방지 가능하다.
Defacts
여기서부터 왜 많은 유저들이 Galera Cluster를 채택하지 않는지가 나온다.
1. Performance Issue
Galera Cluster는 내부적으로 WSREP 모듈을 통해 쓰기 업데이트 데이터를 모든 노드에 복제하는 식으로 Multi-Master 를 지원한다.
이에 따라 노드가 늘어날 수록 모든 쓰기 데이터를 복제해야하고, 트래픽과 노드 수에 따라 부하가 높아진다.
반면, AWS Aurora 는 공통된 S3 스토리지를 사용하기에 데이터 복제 지연시간이 상대적으로 빠르다.
2. Not Suitable For Hot-spots
보통 많은 대기업에서는 메시지 큐 구조를 채택하여 대량의 서버/프로세스들을 활용한다.
특히 근래에 MSA 구조를 채택하는 회사들이 늘어남에 따라, 국내에서 메시지 큐는 거의 필수적으로 변했다.
(필요 없는데도 스케일업해서 모놀리식으로 운영하지 않는 이유는 잘 모르겠다만,,,)
여기서 Synchronous Replication 을 적용하리란 쉽지 않다. 성능 저하로 이어질 수 있기 때문이다.
{ 높은 실시간성 + 메시징 큐 + 동기식 복제 } 는 최악의 조합이다.
아래와 같은 performance degradation features 가 있기 때문이다.
-
메시징 큐에 대한 데이터 대기시간
-
동기복제를 위한 데이터 복제
-
실시간성을 보장하기 위해서 모든 노드에 데이터 반영되기까지 지연
3. Only Optimistic Lock Allowed
Deadlock Found during a Transaction
Galera Cluster uses optimistic row locking, as opposed to pestimistic locking used by MySQL and MariaDB. Galera’s attitude about locking rows can sometimes cause, especially in a cluster with many nodes, transactions to be partially rolled back and generate an error message about a deadlock. Understanding and awareness of the possibility of this situation can be reduce or eliminate problems.
MariaDB Galera Cluster: SELECT ... FOR UPDATE why no locking?
Galera has a "optimistic" looking. This means that only after a change of data the nodes looks who was the first. the other gets a deadlook. this must be handled from the application –
Bernd Buffen
MySQL과 MariaDB에서 사용하는 비관적 락과 달리 Galera Cluster는 낙관적 락을 사용한다.
만약 교착상태 -- 데드락과 같이 -- 가 발생한다면, 트랜잭션이 부분적으로 롤백되고 오류 메시지를 생성하게 처리한다.
즉, ~FOR UPDATE 와 같은 PESSIMISTIC LOCK 은 허용하지 않는다.
따라서 Application Layer 에서 개발자가 예외케이스에 대한 롤백 처리를 지원해야한다.
추가적으로 보통 사용하지 않지만 SERIALIZABLE 또한 지원하지 않는다.
4. Costs vs Efficiency
기본적으로 Galera Cluster 는 AWS 에서 지원되지 않는다.
따라서 EC2 를 사용하여 이를 지원해주어야 한다.
아래와 같이 비교를 해보자.
Galera 를 활용한 3개의 Master 구성 VS RDS 를 활용한 Master : Slave = 1 : 1 구성


RDS 가 상대적으로 EC2 에 비해 비싸지만, Multi-AZ 와 Failover 에 대한 기능제공까지 감안했을 때는 70$ 정도밖에 차이가 나지 않음을 볼 수 있다.
물론 소기업 입장에서는 비싸다고 느껴지지지만, 대기업 입장에서 EC2 관리허들과 Query Log 관리까지 감안한다고 생각할 때는 되려 RDS가 더 효율적이라고 느껴질 것이다.
YAGNI,,

대부분의 경우 Multi-Master 를 필요로 하기 보다 더 효율적인 옵션을 선택하는 게 옳다고 생각한다.
Multi-Master 는 이론상 훌륭해보이지만, defact 들이 비즈니스 컨텍스트에 적용할 수 없을 정도로 심하다.
다른 옵션을 통해 이를 work around 하는 게 더 좋은 옵션안 아닐까 생각한다.
Reference
