회귀 기초
- 아래는 일반적인 문제해결 절차이다
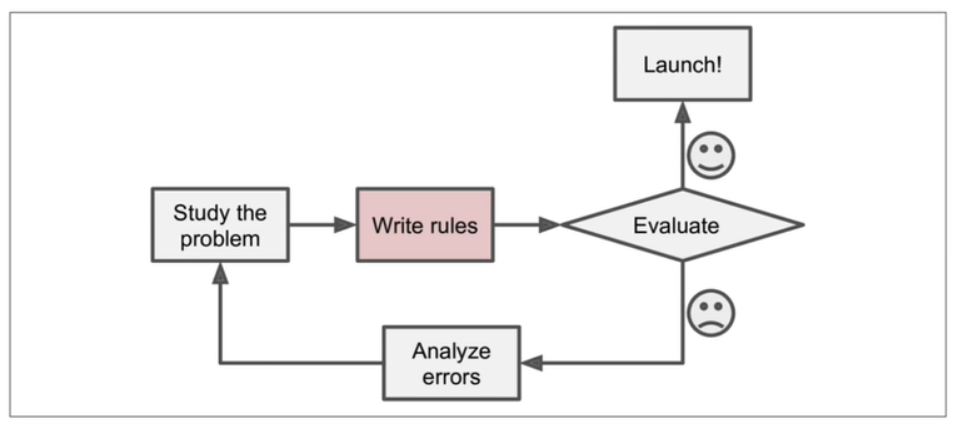
- 기반이 데이터라면?
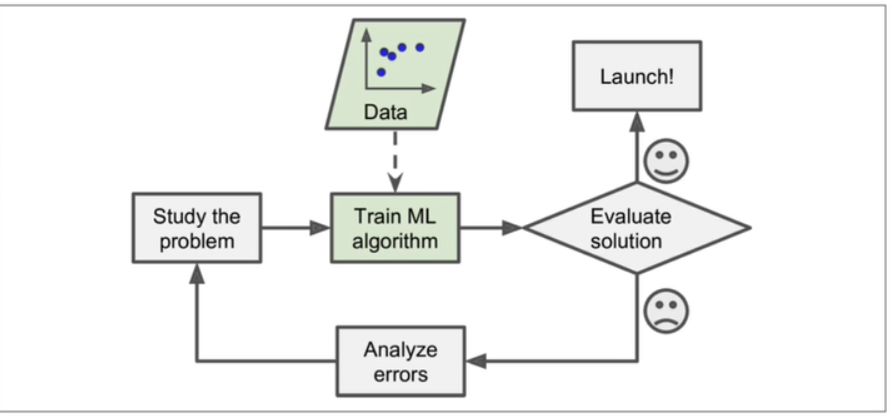
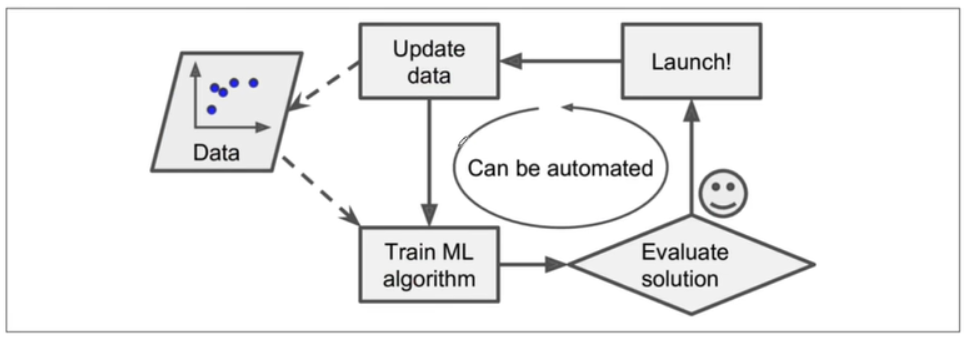
- 모델 스스로 데이터를 기반으로 변화에 대응가능
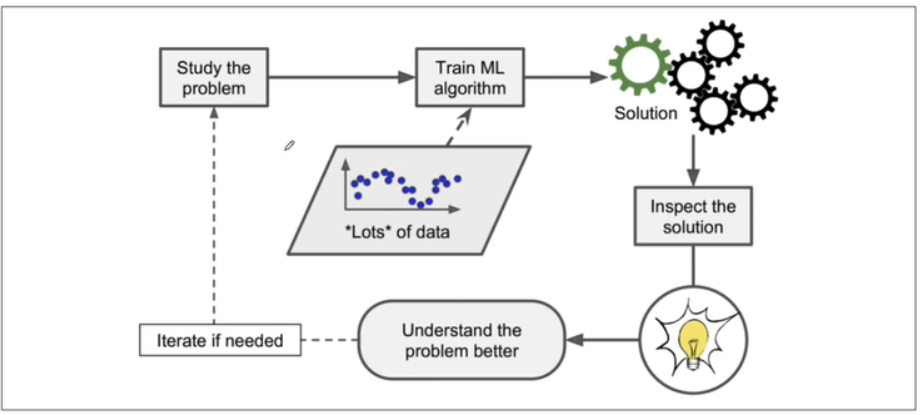
- 심지어 머신러닝을 통해 우리가 배울수도 있다!
만약 주택의 넓이와 가격이라는 데이터가 있고 주택가격을 예측한다면?
=> 학습데이터에 라벨이 있으므로 지도학습이고, 주택 가격을 연속된 값으로 예측하는 것이므로 회귀(Regression)문제임.
- 입력변수 x가 하나인 경우, 선형회귀(Linear Regression)문제는 주어진 학습데이터와 가장 잘 맞는 Hypothesis 함수 h를 찾는 문제가 됨.
OLS
OLS : Ordinary Linear Least Square
-
Y = AX를 풀어서 구함
-
n by n 매트릭스가 아닌경우 그냥 트랜스포즈된걸 곱함.(곱해서 n by n 으로 사이즈 맞춰주려고)
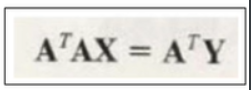
- 성능은 E(error)를 사용해 파악가능.
import pandas as pd
import statsmodels.formula.api as smf
data = {'x' : [1, 2, 3, 4, 5], 'y':[1, 3, 4, 6, 5]}
df = pd.DataFrame(data)
lm_model = smf.ols(formula='y ~ x', data=df).fit()
# 'y ~ x' : y=ax+b
lm_model.params
# output :
Intercept 0.5
x 1.1
dtype: float64
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
plt.figure(figsize=(12,10))
sns.lmplot(x='x', y='y', data=df);
plt.xlim([0, 5])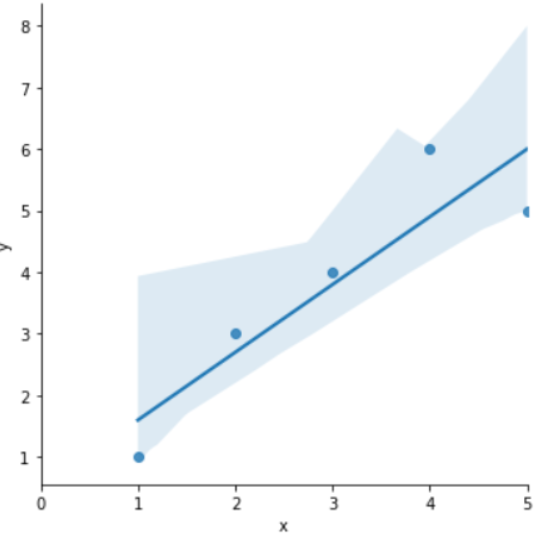
잔차 평가(residue)
- 잔차는 평균이 0인 정규분포를 따르는 것이어야함
- 잔차 평가는 잔차의 평균이 0이고 정규분포를 따르는지 확인
resid = lm_model.resid
resid
# output :
0 -0.6
1 0.3
2 0.2
3 1.1
4 -1.0결정계수 R-Squared
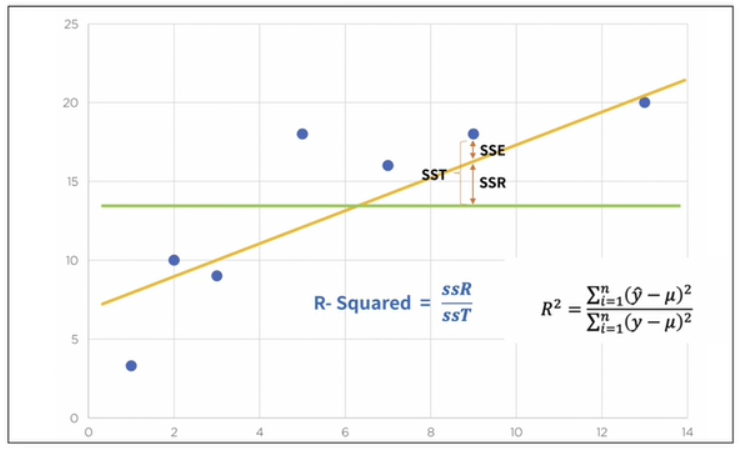
-
초록선이 평균 (mu)
-
y_hat은 예측된 값
-
예측 값과 실제 값(y)가 일치하면 결정계수는 1이 됨(즉, 결정계수가 높을 수록 좋은 모델)
import numpy as np
mu = np.mean(df['y'])
y_hat = lm_model.predict()
np.sum((y_hat -mu) 2) / np.sum((y - mu) 2)
라이브러리 사용
lm_model.rsquared
sns.distplot(resid, color='black')
