하이퍼파라미터 튜닝
교차검증
-
고정된 train, test set을 가지고 모델을 학습시키는 과정을 반복하면 결국 오버피팅이 일어난다
-
이를 해결하고자 train set을 다시 train+validaion으로 분리 후 validation set을 이용해 검증한다
-
장점
- 모든 데이터셋을 훈련에 활용할 수 있다
- 모든 데이터셋을 평가에 활용할 수 있다, 즉 데이터의 편중 방지 가능
-
단점
- 반복회수가 많아 모델의 훈련/평가 시간이 오래 걸린다.
(단순히 train, test로만 데이터를 나누는건 hold out이라함)
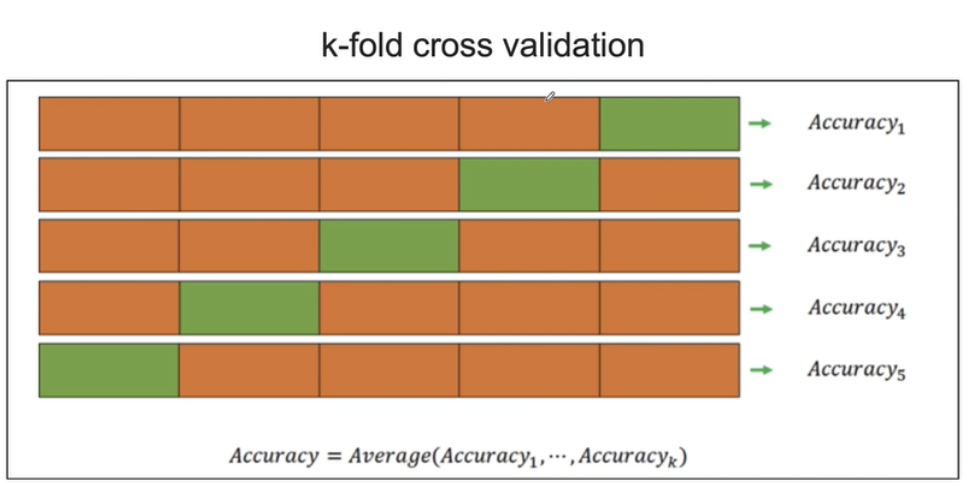
- train data를 k등분해서 k-1개로 train하고 1개로 validation하고 평균을 취함
import numpy as np
from sklearn.model_selection import KFold
X = np.array([[1, 2], [3, 4], [1, 2], [3, 4]])
y = np.array([1, 2, 3, 4])
kf = KFold(n_split=2)
print(kf.get_n_splitx(X))
print(kf)
for train_idx, test_idx in kf.split(X):
print('Train idx : ', train_idx) # 2,3 번인덱스를 처음 그다음 0, 1
print('Test idx : ', test_idx)
print('-----train data-----')
print(X[train_idx])
print('-----validation data-----')
print(X[test_idx])- 와인데이터로 K-fold!
import pandas as pd
red_wine = pd.read_csv('./data/winequality-red.csv', sep=';')
white_wine = pd.read_csv('./data/winequality-white.csv', sep=';')
red_wine['color'] = 1
white_wine['color'] = 0
wine = pd.concat([red_wine, white_wine])
wine['taste'] = [1. if grade>5 else 0 for grade in wine['quality']]
X = wine.drip(['taste', 'quality'], axis=1)
y = wine['taste']from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
X_train, X_test, y_train, y_test = train_test_split(X_mms_pd, y, test_size=0.2, random_state=42)
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=42)
wine_tree.fit(X_train, y_train)
y_pred_tr = wine_tree.predict(X_train)
y_pred_test = wine_tree.predict(X_test)
print('Train Acc : ', accuracy_score(y_train, y_pred_tr))
print('Train Acc : ', accuracy_score(y_test, y_pred_test))데이터를 이렇게 분리하는게 최선인가? 저 정확도를 어떻게 신뢰할 수 있는가?
from sklearn.model_selection import KFold
kfold = KFold(n_split=5)
wine_tree_cv = DecisionTreeClassifier(max_daepth=2, random_state=42)
# KFold는 인덱스를 반환함
for train_idx, test_idx in kfold.split(X):
print(len(train_idx), len(test_idx))
cv_accuracy = []
for train_idx, test_idx in kfold.split(X):
X_train, X_test = X.iloc[train_idx], X.iloc[test_idx]
y_train, y_test = y.iloc[train_idx], y.iloc[test_idx]
wine_tree_cv.fit(X_train, y_train)
pred = wine_tree_cv.predict(X_test)
cv_acvvuracy.append(accuracy_score(y_test, pred))
cv_accuracy- 각 acc의 분산이 크지 않다면 평균을 대표값으로 한다
np.mean(cv_accuracy)
from sklearn.model_selection from StratifiedKFold
skfold = StratifiedKFold(n_splits=5)
wine_tree_cv = DecisionTreeClassifier(max_daepth=2, random_state=42)
cv_accuracy = []
# 어떤걸 기준으로 stratified하는지 설정해야함 여기서는 y
for train_idx, test_idx in skfold.split(X, y):
X_train, X_test = X.iloc[train_idx], X.iloc[test_idx]
y_train, y_test = y.iloc[train_idx], y.iloc[test_idx]
wine_tree_cv.fit(X_train, y_train)
pred = wine_tree_cv.predict(X_test)
cv_acvvuracy.append(accuracy_score(y_test, pred))- cross validation을 보다 간편히 하는 법!
from sklearn.model_selection import cross_val_score
skfold = StratifiedKFold(n_solits=5)
wine_tree_cv = DecisionTreeClassifier(max_depth=2, random_state=42)
cross_val_score(wine_tree_cv, X, y, scoring=None, cv=skfold)- train score와 함께 보고 싶다면
from sklearn.model_selection import cross_validate
cross_validate(wine_tree_cv, X, y, scoring=None, cv=skfod, return_train_score=True)하이퍼파라미터 튜닝
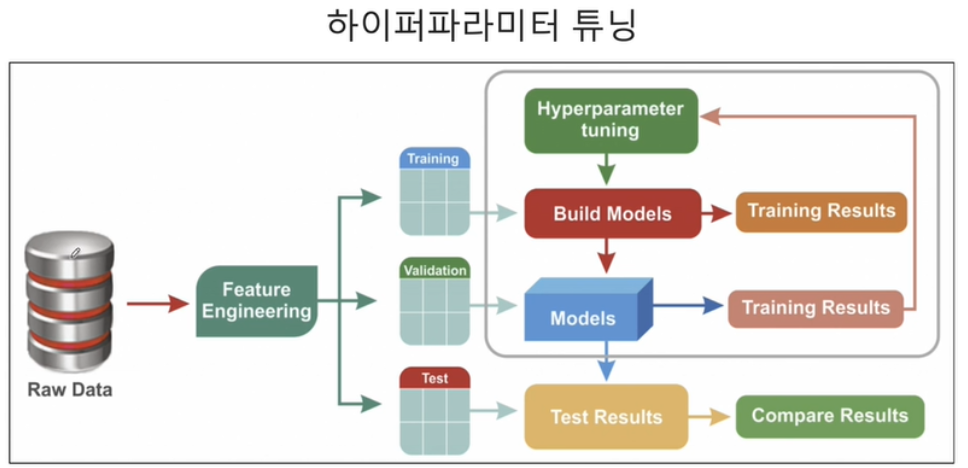
-
모델의 성능을 확보하기 위해 조절하는 설정 값
-
GridSearchCV : 결과를 확인하고 싶은 파라미터만 정의하면 됨
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeClassfier
prarams = {'max_depth' : [2, 4, 7, 10]}
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=42)
# train_test_split도 알아서 해줌
gridsearch = GridSearchCV(estimator=wine_tree, param_grid=params, cv=5)
gridsearch.fit(X, y)# GridSearchCV의 결과
import pprint
pp = pprint.PrettyPrinter(indent=4)
pp.pprint(gridsearch.cv_results_)# 최적의 성능을 가진 모델은?
gridsearch.best_estimator_
# 최고의 정확도는?
gridsearch.best_score_
# 최고의 파라미터는?
gridsearch.best_params_- 만약 pipeline을 적용한 모델에 GridSearch를 적용하고 싶으면?
from sklearn.pipeline import Pipeline
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import StandardScaler
estimators = [('scaler', StandardScaler()),
('clf', DecisionTreeClassifier())]
pipe = Pipeline(estimators)
param_grid = [{'max__depth' : [2, 4, 7, 10]}]
Gridsearch = GridSearchCV(estimator=pipe, param_grid=param_grid, cv=5)
Gridsearch.fit(X, y)- 표로 성능 확인해보자
import pandas as pd
score_df = pd.DataFrame(GridSearch.cv_results_)
score_df['params', 'rank_test_score', 'mean_test_score', 'std_test_score']