AI
1.머신러닝(IRIS데이터 예측)
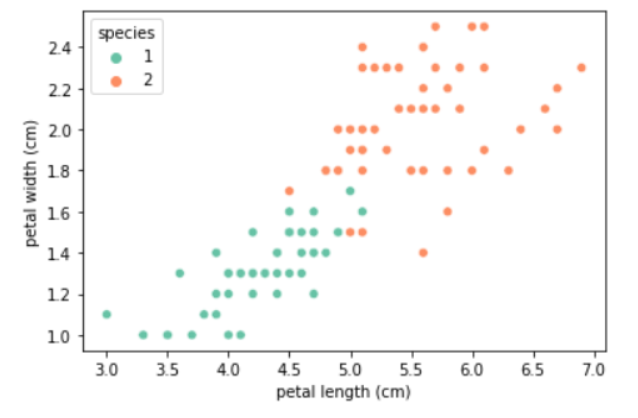
명시적으로 프로그래밍하지 않고도 컴퓨터에 학습할 수 있는 능력을 부여하는 학문즉, 명시적인 프로그램에 의해서가 아니라 기계가 주어진 데이터를 통해 규칙을 찾는 것.IRIS 데이터 분류꽃잎, 꽃받침의 길이/너비를 이용해서 품종구분이 가능할까?데이터 관찰먼저 상황을 파악해
2.머신러닝(타이타닉 생존자 예측)
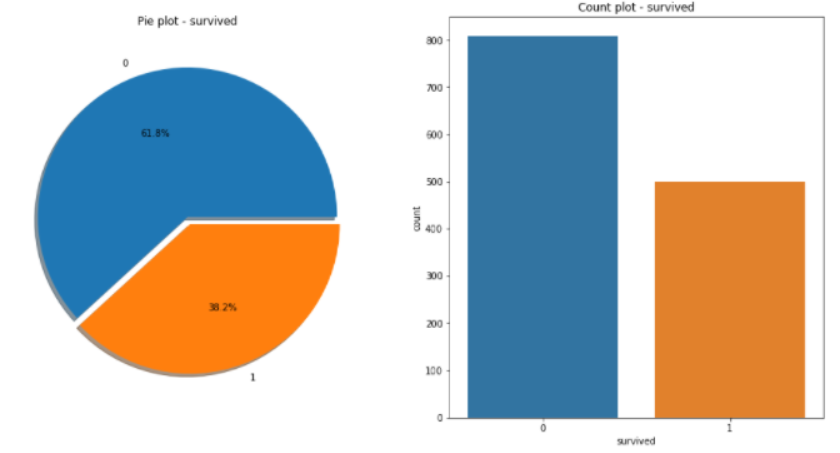
머신러닝에서 거의 연습문제 1번같은 느낌타이타닉배는 1910년대 당시 최대 여객선이고 영국에서 미국 뉴욕으로 가던 국제선아래는 해당 데이터 칼럼의 의미이다.성별에 따른 생존 현황남성의 생존 가능성이 더 낮음, 거의 1/4만 살아남음1등실의 생존률이 다른 두군데보다 매우
3.Encoder and Scaler

사이킷런에서 라벨은 숫자여야함label Encoder란?문자를 숫자로 바꿔줌fit과 transform을 한번에 실행min-max scaling 이란?서로 다른 크기를 통일하기 위해 크기를 변환하는 개념, 여기는 최소를 0 최대를 1로 변환원데이터 분포를 유지하면서 정규
4.Decision Tree를 이용한 와인데이터 분석
분류 문제에서 많이 사용하는 iris만큼 알려지지는 않았지만, 그래도 많이 사용함!인류 역사에서 최초의 술로 알려져 있다플라톤이 와인 짱 좋아함근데 사실 Decision Tre에서는 영향 없음 주로 Cost Function을 최적화할 때 유효할 때가 있음.어떤 스케일러
5.Pipeline
지금까지 불편한 점은?코드를 하나씩 실행하다보면 혼돈이 크다Jupyter Notebook 상황에서 데이터의 전처리와 여러 알고리즘의 반복실행, 하이퍼 파라미터의 튜닝을 과정을 번갈아 하다 보면 코드의 실행 순서에 혼돈이 있을 수 있다.이런 경우 Class로 만들어 진행
6.모델평가
우리가 만든 모델은 얼마나 좋은 것일까?데이터 수집/가공/변환 ↔ 모델학습/예측 ↔ 평가모델을 좋다, 그저그렇다, 나쁘다 등으로 평가할 방법은 없다.대부분 다양한 모델, 다양한 파라미터를 두고, 상대적으로 비교한다.회귀모델들은 실제 값과의 error를 가지고 계산분류
7.하이퍼 파라미터 튜닝
고정된 train, test set을 가지고 모델을 학습시키는 과정을 반복하면 결국 오버피팅이 일어난다이를 해결하고자 train set을 다시 train+validaion으로 분리 후 validation set을 이용해 검증한다장점모든 데이터셋을 훈련에 활용할 수 있다
8.Basic of Regression
아래는 일반적인 문제해결 절차이다기반이 데이터라면?모델 스스로 데이터를 기반으로 변화에 대응가능심지어 머신러닝을 통해 우리가 배울수도 있다!만약 주택의 넓이와 가격이라는 데이터가 있고 주택가격을 예측한다면?=> 학습데이터에 라벨이 있으므로 지도학습이고, 주택 가격을 연