3장 사이킷런을 타고 떠나는 머신 러닝 분류 모델 투어
사이킷런 - 붓꽃 데이터셋
datasets.load_iris() 이용해 붓꽃 데이터셋 적재
from sklearn import datasets
import numpy as np
iris = datasets.load_iris()
X = iris.data[:, [2, 3]]
y = iris.target
print('클래스 레이블:', np.unique(y))test_size=0.3를 통해서 70%는 훈련 데이터 30%는 테스트 데이터로 분할(계층화)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=1, stratify=y)데이터 특성 변환하는 도구들은 사이킷런의 preprocessing 모듈 들인데 그 중
특성 표준화는 StandardScaler에 정의되어있음 fit으로 표준화점수로 바꾸고 trasform 으로 실제 로 변환해준다.
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
sc.fit(X_train)
X_train_std = sc.transform(X_train)
X_test_std = sc.transform(X_test)특성 변환할 때는 샘플이 어떤 클래스인지 알 필요 없어서 fit에 입력데이터만 줬지만, 지도학습은 항상 타깃 데이터 함께 전달 必
잘못 분류된 샘플 개수 계산 -> predict랑 test랑 다른 거 개수 처리 -> sum인거 true로 처리해서 개수 다 더해준다.
y_pred = ppn.predict(X_test_std)
print('잘못 분류된 샘플 개수: %d' % (y_test != y_pred).sum())전형적 분류문제에서는 잘못 분류된 개수보다는 비율로 처리! -> 정확도로 계산
사이킷런에서는 accuracy_score 로 계산가능.
추가로 사이킷런의 분류 클래스들은 모델클래스에 스코어 메소드들을 제공한다!
그러므로 정확도 계산 위해선
from sklearn.metrics import accuracy_score
print('정확도: %.3f' % accuracy_score(y_test, y_pred))또는 아래로 정확도 계산
print('정확도: %.3f' % ppn.score(X_test_std, y_test))분류일 경우는 정확도
회귀일 경우는 r²값 계산 (결정계수)
예측할 때 클래스 레이블 반환이 아니라
예측한 확률을 반환해서 얼만큼 강하게 확신하면서 반환하는지 확인 -> 로지스틱 회귀
회귀로 써있지만 회귀는 아니고 분류모델임
로지스틱 회귀를 사용한 클래스 확률 모델링
로지스틱 회귀 알고리즘
오즈비 : 특정 이벤트가 발생할 확률로 성공 가능확률 p일 때 p /{1-p}로 계산한다.
그것에 로짓함수 취한걸 logit(P) = log(p/{1-p})
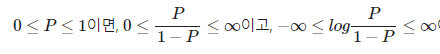
범위가 달라짐에 따라 로짓함수는 -inf에서 inf사이의 값을 가지므로, 선형 방정식으로 사용가능.
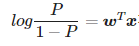
즉 p에 대해 다시 정리한다면
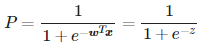
이 함수를 시그모이드 함수 혹은 로지스틱 함수라고 부르기도한다.
파이썬 코드로는
def sigmoid(z):
return 1.0 / (1.0 + np.exp(-z))시그모이드 함수가 0과1사이 값을 갖기 때문에 확률로 생각하기 편하다.
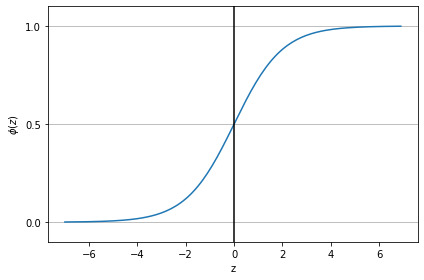
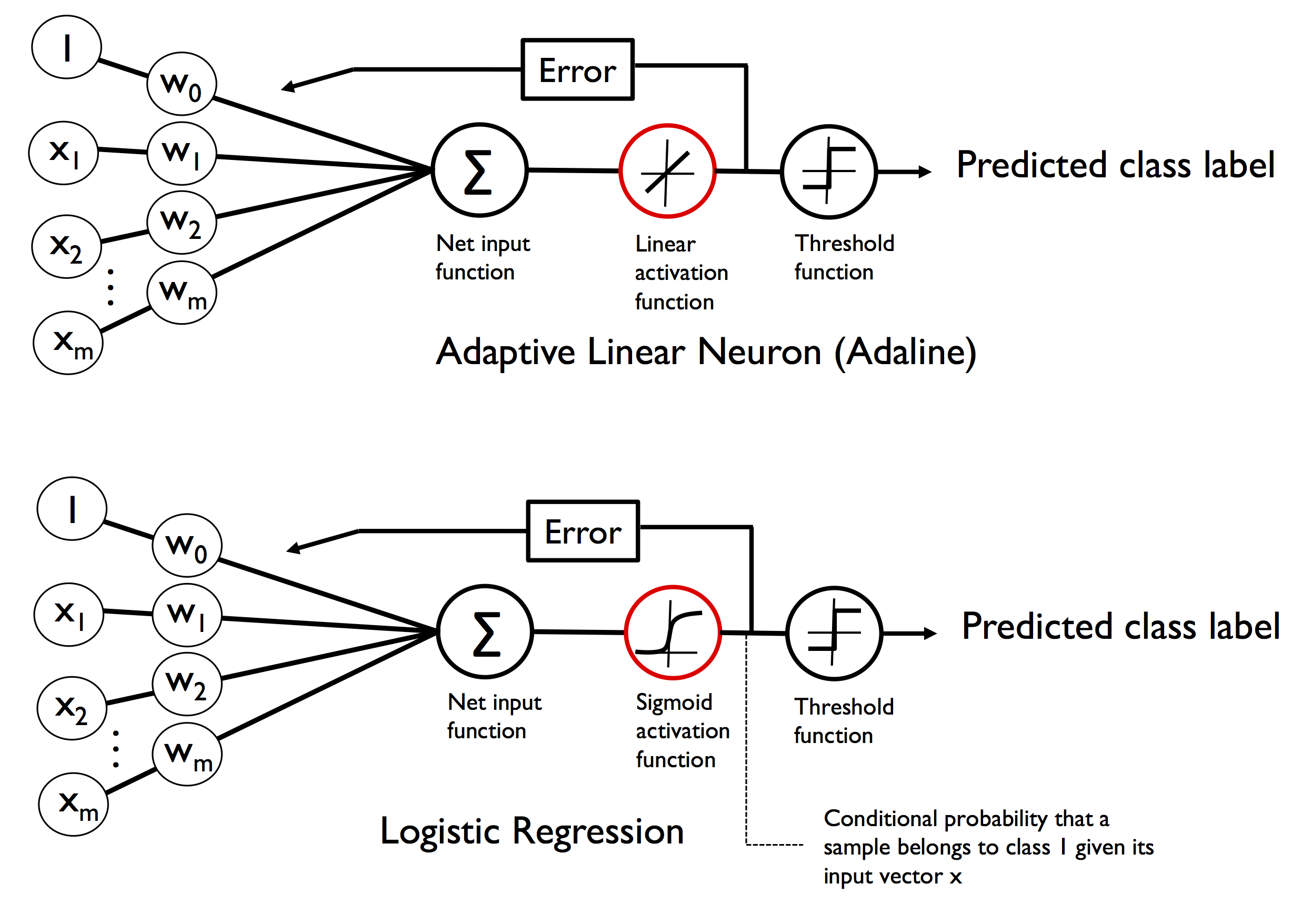
시그모이드 함수의 적용은 아달린 알고리즘의 활성화함수가 선형 함수( 항등함수) 였던 것처럼
Logistic Regression일 경우엔 활성함수를 시그모이드 함수로 사용한다. 시그모이드 활성함수 통과하면서 임의의 실수값이 0과 1사이로 압축이 되고 이것을 확률로 생각 가능하다! 결과가 0.5보다 크거나 같으면 양성클래스, 작으면 음성클래스로 생각
로지스틱 비용 함수의 가중치 학습
로지스틱 비용 함수의 정의
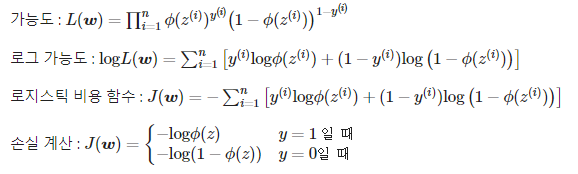
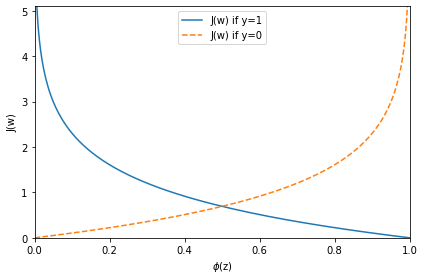
y=1일 때 Φ(z) 가 1에 가까워야 손실이 최소화되고
y=0일 때 Φ(z) 가 0에 가까워야 손실이 최소화된다.
이제 경사하강법으로 문제 풀 수 있다.
class LogisticRegressionGD(object):
"""경사 하강법을 사용한 로지스틱 회귀 분류기
매개변수
------------
eta : float
학습률 (0.0과 1.0 사이)
n_iter : int
훈련 데이터셋 반복 횟수
random_state : int
가중치 무작위 초기화를 위한 난수 생성기 시드
속성
-----------
w_ : 1d-array
학습된 가중치
cost_ : list
에포크마다 누적된 로지스틱 비용 함수 값
"""
def __init__(self, eta=0.05, n_iter=100, random_state=1):
self.eta = eta
self.n_iter = n_iter
self.random_state = random_state
def fit(self, X, y):
"""훈련 데이터 학습
매개변수
----------
X : {array-like}, shape = [n_samples, n_features]
n_samples 개의 샘플과 n_features 개의 특성으로 이루어진 훈련 데이터
y : array-like, shape = [n_samples]
타깃값
반환값
-------
self : object
"""
rgen = np.random.RandomState(self.random_state)
self.w_ = rgen.normal(loc=0.0, scale=0.01, size=1 + X.shape[1])
self.cost_ = []
for i in range(self.n_iter):
net_input = self.net_input(X)
output = self.activation(net_input)
errors = (y - output)
self.w_[1:] += self.eta * X.T.dot(errors)
self.w_[0] += self.eta * errors.sum()
# 오차 제곱합 대신 로지스틱 비용을 계산합니다.
cost = -y.dot(np.log(output)) - ((1 - y).dot(np.log(1 - output)))
self.cost_.append(cost)
return self
def net_input(self, X):
"""최종 입력 계산"""
return np.dot(X, self.w_[1:]) + self.w_[0]
def activation(self, z):
"""로지스틱 시그모이드 활성화 계산"""
# 대신 from scipy.special import expit; expit(z) 을 사용할 수 있습니다.
return 1. / (1. + np.exp(-np.clip(z, -250, 250)))
def predict(self, X):
"""단위 계단 함수를 사용하여 클래스 레이블을 반환합니다"""
return np.where(self.net_input(X) >= 0.0, 1, 0)
# 다음과 동일합니다.
# return np.where(self.activation(self.net_input(X)) >= 0.5, 1, 0)사이킷런은 로지스틱 회귀 모형이 이미 훈련되어있고 선형모델있는 sklearn.linear_model 라이브러리 안에 LogisticRegression 클래스 import
LogisticRegression 객체 생성하고 fit으로 훈련 데이터와 타깃 데이터 넣고 (사이킷런은 다중 클래스 잘 지원하고 있어서 클래스 3개 넣어줌) 결정 경계를 보면 정확도 거의 비슷하고 3개로 나뉜 결과 볼 수 있음.
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression(C=100.0, random_state=1)
lr.fit(X_train_std, y_train)
plot_decision_regions(X_combined_std, y_combined,
classifier=lr, test_idx=range(105, 150))
plt.xlabel('petal length [standardized]')
plt.ylabel('petal width [standardized]')
plt.legend(loc='upper left')
plt.tight_layout()
# plt.savefig('images/03_06.png', dpi=300)
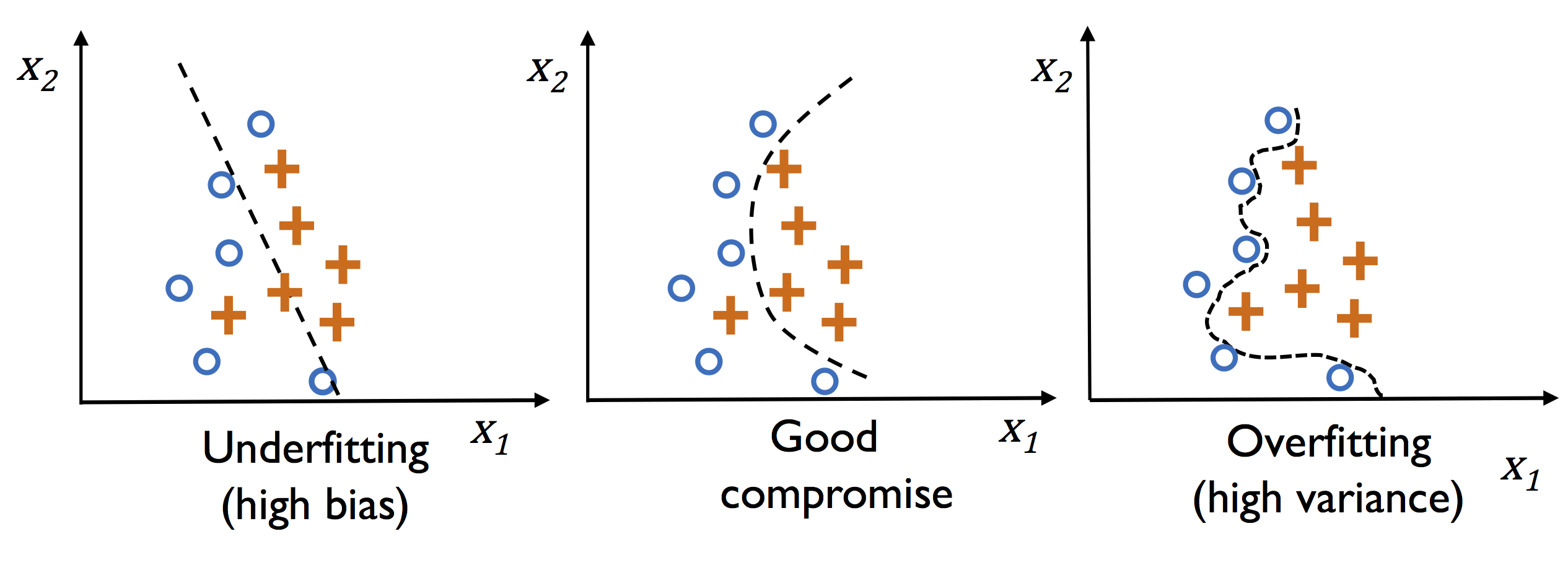
plt.show()규제와 과대적합
곧은 왼쪽 직선과 구불구불한 오른쪽 직선을 보면
왼쪽은 과소적합, 편향이 크다고 표현하고
오른쪽은 과대적합, 분산이 크다고 이야기한다.
과대적합의 경우 모델 조금 바꾸거나 새로운 샘플 조금만 추가되도 크게 결정계가 달라진다.
그러므로 가운데처럼 각 클래스의 대체적인 위치의 경향을 잘 반영하는 그래프가 좀 더 분산과 편향을 tradeoff한 결정이다.
모델이 과대 적합되어있다면 규제를 높여서 과대적합 줄어들도록 만들고
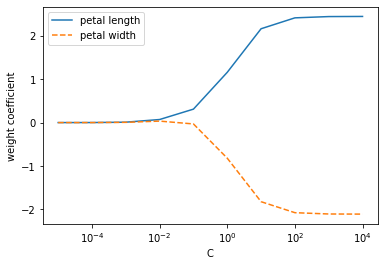
과소적합 되어있다면 규제를 낮춰서 좀 더 복잡한 모델을 만든다. 이런 규제를 하는게 위의 코드에서 LogisticRegression(C=100.0 .. C 이다.
C값이 작아지면 규제가 커져서 가중치 값이 매우 작아진다. (단순한 모델)
C값이 커지면 규제가 풀어져서 가중치 값이 커진다.