결정 트리 학습
decision tree 분류기는 설명이 중요할 때 아주 유용한 모델.
결정 트리는 훈련 데이터에 있는 특성을 기반으로 샘플의 클래스 레이블을 추정할 수 있는 일련의 질문을 학습.
결정 알고리즘을 사용하면 트리의 root에서 시작해서 정보이득(IG, Information Gain)이 최대가 되는 특성으로 데이터 나눔. 반복 통해 리프 노드가 순수해질때까지 분할 작업 반복.
각 노드의 모든 훈련 샘플은 동일한 클래스에 속함. 일반적으로 트리의 최대 깊이를 제한해 가지치기.
🤣
트리 알고리즘 최적화할 목적 함수 : 각 분할에서 정보 이득 최대화
이진결정 트리에 널리 사용되는 세개의 불순도 지표 또는 분할 조건은 지니 불순도, 엔트로피, 분류 오차
😃
결정 트리는 특성 공간을 사각 격자로 나누기 때문에 복잡한 결정 경계 만들 수 있는데, 결정 트리 깊어질 수록 결정 경계 복잡해지고 과대적합 되기 쉽기 때문에 주의
결정 트리 만들기
from sklearn.tree import DecisionTreeClassifier
tree_model = DecisionTreeClassifier(criterion='gini',
max_depth=4,
random_state=1)
tree_model.fit(X_train, y_train)
X_combined = np.vstack((X_train, X_test))
y_combined = np.hstack((y_train, y_test))
plot_decision_regions(X_combined, y_combined,
classifier=tree_model,
test_idx=range(105, 150))
plt.xlabel('petal length [cm]')
plt.ylabel('petal width [cm]')
plt.legend(loc='upper left')
plt.tight_layout()
# plt.savefig('images/03_20.png', dpi=300)
plt.show()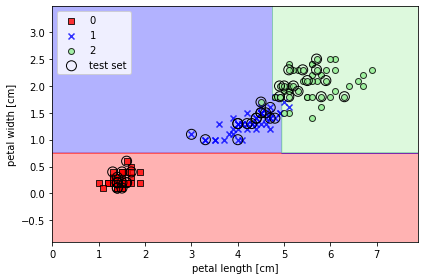
또는 사이킷런에서 제공하는 훈련 끝난 결정 트리 모델 시각화 함수 plot_tree()를 보면
from sklearn import tree
plt.figure(figsize=(10,10))
tree.plot_tree(tree_model)
plt.show()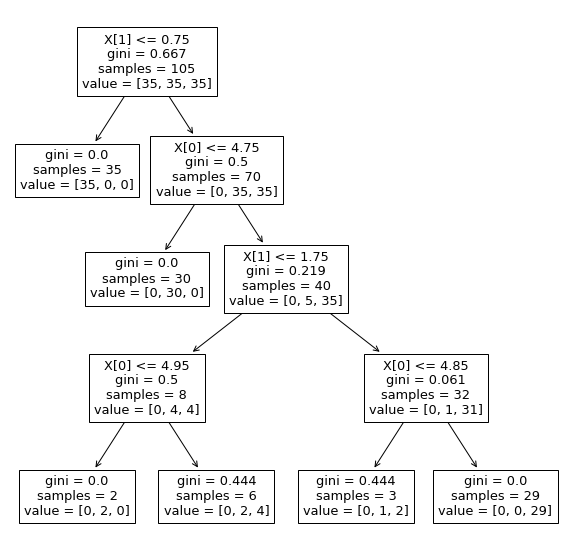
😄 랜덤 포레스트로 여러 개의 결정 트리 연결
랜덤 포레스트는 결정 트리의 앙상블로 생각 가능. 랜덤 포레스트 이면 idea는 여러 개의 (깊은) 결정 트리를 평균 내는 것. 개개 트리는 분산 높은 문제 있으나 앙상블은 견고한 모델만들어 일반 화 성능 높이고 과대적합 위험 줄임
from sklearn.ensemble import RandomForestClassifier
forest = RandomForestClassifier(criterion='gini',
n_estimators=25,
random_state=1,
n_jobs=2)
forest.fit(X_train, y_train)😅 K-최근접 이웃 (KNN)
지도학습 알고리즘 중 knn은 전형적인 게으른 (lazy)학습기. 훈련 데이터에서 판별 함수를 학습하는 대신 훈련 데이터셋을 메모리에 저장하기 때문이다.
😆
모수 모델: 새로운 데이터 포인트를 분류할 수 있는 함수를 학습하기 위해 훈련 데이터셋에서 모델 파라미터를 추정, 훈련 끝나면 학습데이터 불필요.
비모수 모델 : 고정된 개수의 파라미터로 설명될 수 없고 훈련 데이터가 늘어남에 따라 파라미터 개수도 늘어남.
모수 비모수로 머신 러닝 알고리즘을 나눌 때 전형적 모수 모델은 퍼셉트론, 로지스틱회귀, 선형 svm. 비모수 모델은 결정 트리/랜덤 포레스트와 커널 svm + knn
knn은 비모수 모델에 속하며 인스턴스 기반 모델이라고 한다. 인스턴스 기반 모델은 훈련 데이터셋을 메모리에 저장하는 것이 특징.
