4장은 데이터 전처리 에 대해서 다루고 있는데 가장 집중해서 들어야 하는 장 같음. 파이팅 하좌!
이 장은
- 누락된 데이터 다루기
- 범주형 데이터 다루기
- 데이터셋을 훈련 데이터셋과 테스트 데이터셋으로 나누기
- 특성 스케일 맞추기
- 유용한 특성 선택
- 랜덤 포레스트의 특성 중요도 사용
의 목차를 가지고 있다.
잘 된 머신러닝 알고리즘 학습을 결정하는 중요한 요소인 데이터 품질과 데이터에 담긴 유용한 정보의 양, 그러므로 전처리는 매우 중요하다.
데이터 셋에서 누락된 데이터 제거하거나 대체하기
😉 누락된 값 식별 in 테이블 형태 데이터
isnull()을 통해 셀이 수치 값을 담고 있는지 또는 누락되어있는지 확인
isnull().sum() 을 통해 누락된 값의 개수 확인
😊누락된 데이터 다루는 가장 쉬운 방법 : 데이터셋에서 해당 훈련 샘플이나 특성 (행이나 열) 삭제하는 것
누락된 값이 있는 훈련 샘플이나 특성 제외
dropna()이용
# 누락된 값이 있는 행을 삭제합니다
df.dropna(axis=0)
# 누락된 값이 있는 열을 삭제합니다
df.dropna(axis=1)
# 모든 열이 NaN인 행을 삭제합니다
df.dropna(how='all')
# NaN 아닌 값이 네 개보다 작은 행을 삭제합니다
df.dropna(thresh=4)
# 특정 열에 NaN이 있는 행만 삭제합니다(여기서는 'C'열)
df.dropna(subset=['C'])누락된 데이터 제거하는게 간단해보이지만 단점은, 너무 많은 데이터 제거시 안정된 분석 불가. 또 너무 많은 특성 열 제거시 분류리가 클래스 구분하는 정보 잃을 위험 有
=> 보간 기법 (interpolation)
😋누락된 값 대체
보간 기법 이용해 데이터셋에 있는 다른 훈련 샘플로부터 누락된 값을 추정
가장 흔한 기법은 평균으로 대체 -> SimpleImputer 클래스
# 행의 평균으로 누락된 값 대체하기
from sklearn.impute import SimpleImputer
import numpy as np
imr = SimpleImputer(missing_values=np.nan, strategy='mean')
imr = imr.fit(df.values)
imputed_data = imr.transform(df.values)
imputed_data위의 strategy 매개변수에 지금은 mean 넣고 있지만, 중앙값이나 most_frequent가 있음. 이 옵션은 범주형 특성 값 대체시 유용.
더 쉬운 방법은 판다스의 fillna 메서드에 매개변수로 누락된 값 채울 방법 전달.
bfill 또는 backfill은 누락된 값을 다음 행의 값으로 채움. ffill 또는 pad는 누락된 값을 이전 행의 값으로 채움.
from sklearn.impute import KNNImputer
kimr = KNNImputer()
kimr.fit_transform(df.values)
df.fillna(df.mean())😎 사이킷런 추정기 API
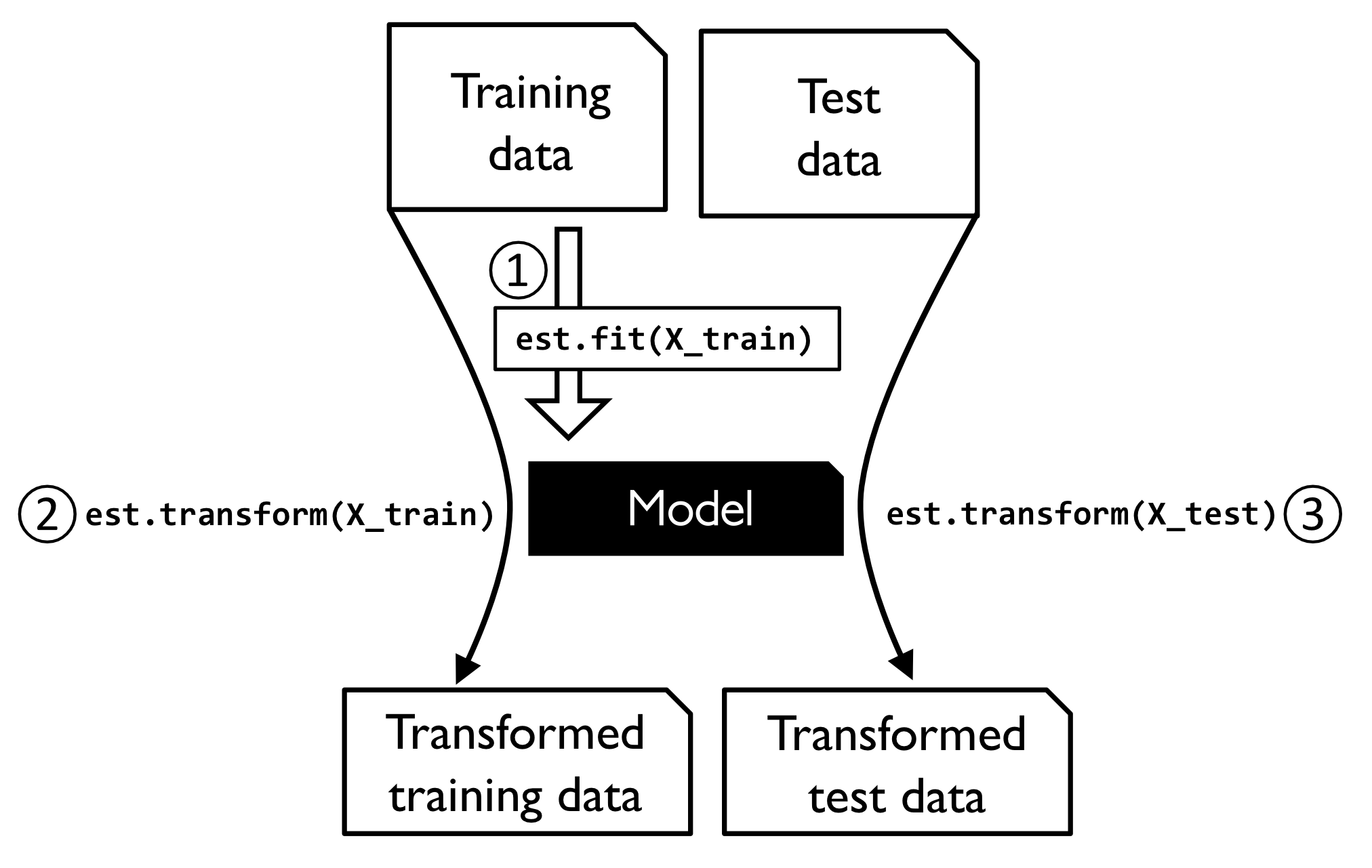
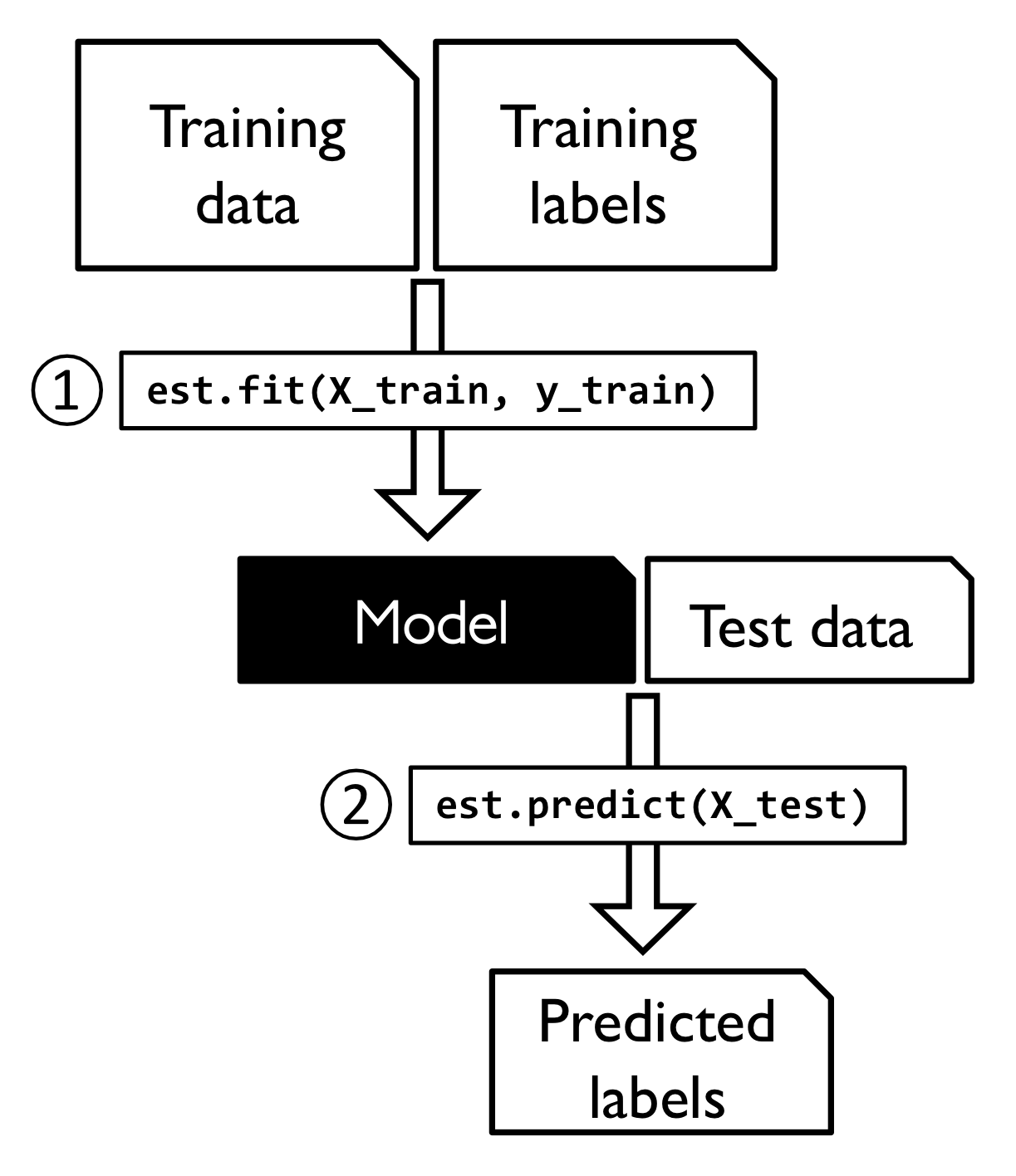
데이터셋에 있는 누락된 값 대체하는 걸 변환이라 함. 데이터 변환에 사용되는 것을 사이킷런의 변환기 클래스 라고 한다.
추정기의 주요 메서드 두개는 fit transform
추정기는 predict 메서드 있지만 transform 메서드도 가질 수 있음.
-- 사이킷런 변환기 훈련과 변환 과정 그림
-- 사이킷런 추정기의 훈련과 예측 과정 그림
머신 러닝 알고리즘 위해 범주형 데이터 변환하기
범주형 데이터 이야기할 때 순서가 있는지 없는지 확인해야함. 순서가 있는 특성은 정렬하거나 차례대로 놓을 수 있는 범주형 특성으로 생각 가능.
판다스를 사용한 범주형 데이터 인코딩
import pandas as pd
df = pd.DataFrame([['green', 'M', 10.1, 'class2'],
['red', 'L', 13.5, 'class1'],
['blue', 'XL', 15.3, 'class2']])
df.columns = ['color', 'size', 'price', 'classlabel']
df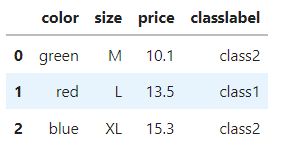
이렇게 만든 데이터는 순서가 없는 특성 (color)와 순서가 있는 특성 (size), 수치형 특성 (price)이 있음.
😍 순서가 있는 범주형 특성 매핑
순서 특징 인식 위해서는 범주형 문자열 정수로 바꾸어야함!
++ 클래스 레이블 역시 인코딩 하려면 정수로 변환하고 정수 배열로 전달하는 것이 좋다.
(클래스 레이블은 순서가 없음)
😘 순서가 없는 특성 : 윈-핫 인코딩
범주형 데이터를 정수로 인코딩하는 OrdinalEncoder와 판다스 데이터프레임의 열마다 다른 변환을 적용하도록 도와주는 ColumnTransformer를 이용하면 여러 개의 열을 한 번에 정수로 변환 가능
그러나 이렇게 배열을 분류기에 주입하면 범주형 데이터 다룰 때 특성이 순서가 없지만 학습 알고리즘은 순서 있다고 가정한다. 이 가정이 옳진 않지만 의미있는 결과 나올 수 있다. 하지만 최선 결과는 아님.
그래서 원-핫 인코딩 (one-hot encoding)기법을 통해 순서없는 특성에 들어있는 고유 값마다 새로운 dummy 만드는 아이디어로, 사이킷런 preprocessing 모듈의 OneHotEncoder 사용해 변환 수행
from sklearn.preprocessing import OneHotEncoder
X = df[['color', 'size', 'price']].values
color_ohe = OneHotEncoder()
color_ohe.fit_transform(X[:, 0].reshape(-1, 1)).toarray()
#######
from sklearn.compose import ColumnTransformer
X = df[['color', 'size', 'price']].values
c_transf = ColumnTransformer([ ('onehot', OneHotEncoder(), [0]),
('nothing', 'passthrough', [1, 2])])
c_transf.fit_transform(X)OneHotEncoder의 dtype 매개변수를 np.int로 지정하여 정수로 원-핫 인코딩
원-핫 인코딩 된 데이터셋 사용할 때 다중공선성 문제 유념하기!!!
(특성 간 상관관계 높으면 역행렬 계산 어려워 수치적 불안정 도래)
# get_dummies에서 다중 공선성 문제 처리
pd.get_dummies(df[['price', 'color', 'size']], drop_first=True)
# OneHotEncoder에서 다중 공선성 문제 처리
color_ohe = OneHotEncoder(categories='auto', drop='first')
c_transf = ColumnTransformer([ ('onehot', color_ohe, [0]),
('nothing', 'passthrough', [1, 2])])
c_transf.fit_transform(X)🥰 데이터셋을 훈련 데이터셋과 테스트 데이터셋으로 나누기
편향되지 않은 성능 측정 위해 모델을 실전에 투입하기 전에 테스트 데이터셋에 있는 레이블과 예측 비교 필요.
사이킷런의 model_selection 모듈의 train_test_split 함수 사용하면 간편하게 데이터 랜덤 훈련 데이터셋과 테스트 데이터셋 나눌 수 있음.
