모델과 관련이 높은 특성 선택하기
특성 스케일 조정은 전처리 파이프라인에서 중요한 단계.
결정 트리와 랜덤 포레스트는 특성 스케일 조정에 걱정 필요 無
스케일이 다른 특성을 맞추는 대표적 방법
1. 정규화 (normalization)
2. 표준화 (standardization)
🥰 정규화
대부분의 정규화는 특성 스케일 [0,1] 범위로 맞춤. (최소-최대 스케일 변환은 특별 케이스)
- 최소-최대 스케일링(min-max scaling):
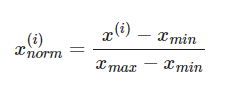
최소-최대 스케일링 변화 통한 정규화는 정해진 범위의 값이 필요할 때 유용하게 사용.
😗표준화 (standardization)
표준화는 이상치 정보가 유지되기 때문에 제한된 범위로 데이터 조정하는 최소-최대 스케일 변환에 비해 이상치에 덜 민감
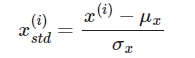
😙RobustScaler
사이킷런에서 특성 스케일 조정 다른 방법 RobustScaler -> 이상치 많이 포함된 작은 데이터셋 다룰떼나 데이터셋 적용되는 머신러닝 알고리즘이 과적합되기 쉽다면 추천
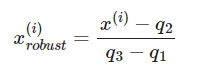
RobustScaler는 중간값(q2) 값을 빼고 1사분위(q1)와 3사분위(q3)의 차이로 나누어 데이터의 스케일을 조정
모델이 테스트 데이터셋보다 훈련 데이터셋에서 성능이 훨씬 높다면 과대적합(overfitting)에 대한 강력한 신호.
모델 분산이 너무 크다 : 새로운 데이터는 잘 일반화 하지 못하기 때문
과대적합 이유 : 주어진 훈련 데이터에 비해 모델이 너무 복잡
so, 일반화 오차 감소 위해 사용 방법
- 더 많은 훈련 데이터
- 파라미터가 적은 간단한 모델
- 규제를 통한 복잡도 제어
- 데이터의 차원 축소
😚 규제를 통한 복잡도 제어-> L1 규제와 L2 규제
L2 규제: 개별 가중치 값 제한해 모델 복잡도 줄이는 방법
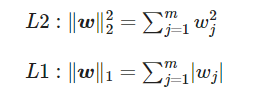
L1 규제: (l2의 가중치 제곱을 가중치 절댓값으로 바꿔 )모델 복잡도 줄이는 방법
🙂 순차 특성 선택 알고리즘
일반화 오차 감소 위힌 방법 중 데이터의 차원 축소 (dimensionality reduction)
규제가 없는 모델에서 특히 유용 .
차원 축소 기법에는 특성 선택과 특성 추출이 있음.
특성 선택은 원본 특성 중 일부 선택, 특성 추출은 일련의 특성에서 얻은 정보로 새로운 특성 생성
순차 특성 선택은 greddy 탐색 알고리즘으로 초기 d 차원의 특성 광간을 k<d인 k차원 특성 부분 공간으로 축소.
전통적 순차 특성 선택 알고리즘은 순차 후진 선(SBS, Sequential Backward Selection)
SBS: 새로운 특성의 부분 공간이 목표하는 특성 개수 될 때까지 전체 특성에서 순차적으로 특성 제거
SBS 알고리즘은 아직 사이킷런에 구현 X
이 알고리즘의 파이썬 코드
from sklearn.base import clone
from itertools import combinations
import numpy as np
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
class SBS():
def __init__(self, estimator, k_features, scoring=accuracy_score,
test_size=0.25, random_state=1):
self.scoring = scoring
self.estimator = clone(estimator)
self.k_features = k_features
self.test_size = test_size
self.random_state = random_state
def fit(self, X, y):
X_train, X_test, y_train, y_test = \
train_test_split(X, y, test_size=self.test_size,
random_state=self.random_state)
dim = X_train.shape[1]
self.indices_ = tuple(range(dim))
self.subsets_ = [self.indices_]
score = self._calc_score(X_train, y_train,
X_test, y_test, self.indices_)
self.scores_ = [score]
while dim > self.k_features:
scores = []
subsets = []
for p in combinations(self.indices_, r=dim - 1):
score = self._calc_score(X_train, y_train,
X_test, y_test, p)
scores.append(score)
subsets.append(p)
best = np.argmax(scores)
self.indices_ = subsets[best]
self.subsets_.append(self.indices_)
dim -= 1
self.scores_.append(scores[best])
self.k_score_ = self.scores_[-1]
return self
def transform(self, X):
return X[:, self.indices_]
def _calc_score(self, X_train, y_train, X_test, y_test, indices):
self.estimator.fit(X_train[:, indices], y_train)
y_pred = self.estimator.predict(X_test[:, indices])
score = self.scoring(y_test, y_pred)
return scoreimport matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=5)
# 특성을 선택합니다
sbs = SBS(knn, k_features=1)
sbs.fit(X_train_std, y_train)
# 선택한 특성의 성능을 출력합니다
k_feat = [len(k) for k in sbs.subsets_]
plt.plot(k_feat, sbs.scores_, marker='o')
plt.ylim([0.7, 1.02])
plt.ylabel('Accuracy')
plt.xlabel('Number of features')
plt.grid()
plt.tight_layout()
# plt.savefig('images/04_08.png', dpi=300)
plt.show()데이터셋 유용 특성 선택 방법 - 앙상블 기법인 랜덤 포레스트 사용
랜덤 포레스트 사용하면 앙상블에 참여한 모든 결정 트리에서 계산한 평균적인 불순도 감소로 특성 중요도 측정 可
사이킷런의 RandomForestClassifier 모델 훈련 후 freatureimportances)) 속성에서 확인 가능
from sklearn.ensemble import RandomForestClassifier
feat_labels = df_wine.columns[1:]
forest = RandomForestClassifier(n_estimators=500,
random_state=1)
forest.fit(X_train, y_train)
importances = forest.feature_importances_
indices = np.argsort(importances)[::-1]
for f in range(X_train.shape[1]):
print("%2d) %-*s %f" % (f + 1, 30,
feat_labels[indices[f]],
importances[indices[f]]))
plt.title('Feature Importance')
plt.bar(range(X_train.shape[1]),
importances[indices],
align='center')
plt.xticks(range(X_train.shape[1]),
feat_labels[indices], rotation=90)
plt.xlim([-1, X_train.shape[1]])
plt.tight_layout()
# plt.savefig('images/04_09.png', dpi=300)
plt.show()