1. 오버 샘플링
오버 샘플링(Over Sampling)은 데이터 간의 불균형을 해결하기 위한 기법 중 하나로, 상대적으로 데이터가 적은 쪽의 데이터를 데이터가 많은 쪽의 데이터양과 맞춰주는 것이다.
2. RandomOverSampler
RandomOverSampler는 데이터 분석 라이브러리인 sklearn에서 제공하는 클래스로, 이미 존재하는 데이터를 무작위로 추출하여 새로운 데이터를 생성하는 것이다. 즉, 중복된 데이터를 기존의 데이터에 추가하여 데이터의 절대적인 양을 늘리는 것이다.
2.1 예시
from sklearn.datasets import make_classification
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
random_seed = 42
X,y = make_classification(n_samples = 1000, n_features = 2, n_classes = 3,
weights = [0.1, 0.33, 0.57], n_informative = 2, n_repeated = 0, n_redundant = 0,
n_clusters_per_class = 1, random_state = random_seed, class_sep = 1)
counters = [0]*3
for y_ in y:
counters[y_] +=1
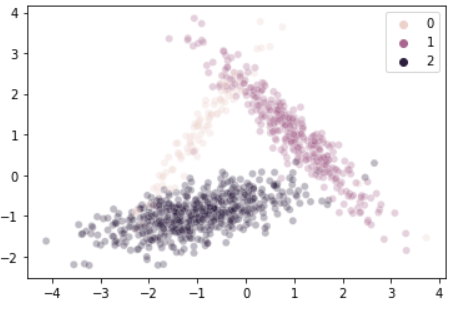
print(f"0:{counters[0]}, 1:{counters[1]}, 2:{counters[2]}") # 102, 329, 569실험을 위하여 임의의 데이터셋을 하나 생성하였다.
2차원의 데이터를 총 1000개 생성했으며, 각 데이터는 [0,1,2] 셋 중 하나의 클래스를 가진다. 다만 각 클래스의 데이터는 균일하지 않은데, 각 클래스는 [102, 329, 569]개의 데이터를 가지고 있다.
이를 시각화하면 다음과 같다.
sns.scatterplot(data = X, x = X[:,0], y = X[:,1], hue = y, alpha = 0.3)
# randomoversampling
from imblearn.over_sampling import RandomOverSampler
ros = RandomOverSampler(random_state = random_seed)
X_ros, y_ros = ros.fit_resample(X,y)
sns.scatterplot(data = X_ros, x = X_ros[:,0], y = X_ros[:,1], hue = y_ros, alpha = 0.3)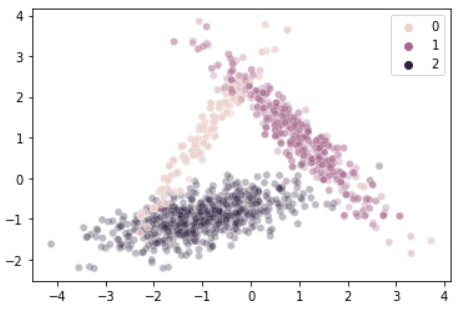
연한 살구색으로 표현된 label = 0의 데이터가 좀 더 진한색으로 표현되었음을 확인할 수 있다.
기존의 그래프에서는 각 데이터가 30%의 투명도를 가지도록 설정되었는데, 같은 위치의 데이터가 중첩되다 보니 보다 불투명한 점으로 표현된 것이다.
counters = [0]*3
for y_ in y_ros:
counters[y_] +=1
print(f"0:{counters[0]}, 1:{counters[1]}, 2:{counters[2]}") # 569, 569, 569증강된 데이터의 개수를 확인해보니, 모든 데이터가 569개로 균일하게 맞춰진 것을 확인할 수 있다. 어떤 데이터를 증가시킬지는 RandomOverSampler 인스턴스를 생성할 때 sampling_strategy 파라미터를 통해 정할 수 있다.
-
float형식으로 입력한다면 다수 클래스(majority) 대비 소수 클래스(minority)의 비율을 설정할 수 있다. -
str형식으로 입력한다면 타깃을 설정할 수 있다.
-minority: 소수 클래스만 resample 한다.
-not minority: 소수 클래스를 제외한 모든 클래스를 resample한다.
-not majority, auto (default): 다수 클래스를 제외한 모든 클래스를 resample한다.
-all: 모든 클래스를 resample한다.
2.2 Shrinkage
RandomOverSampler를 통해 새로 생성된 데이터는 기존의 데이터와 완전히 일치한다. 다만, shrinkage 파라미터를 통하여 일종의 변주(perturbation)를 줄 수 있다. (파라미터 값은 0 이상이어야 한다.)
# shrinkage
shrs = [0, 0.3, 0.5, 1.0, 2.0]
dfs = []
for shr in shrs:
temp_ros = RandomOverSampler(random_state = random_seed, shrinkage = shr)
temp_X, temp_y = temp_ros.fit_resample(X,y)
temp_df = pd.DataFrame(np.hstack([temp_X, temp_y.reshape(-1,1)]), columns = ["x0","x1","y"])
temp_df["shrinkage"] = [shr] * len(temp_df)
dfs.append(temp_df)
df = pd.concat(dfs)
sns.relplot(data = df, x = df.x0, y = df.x1, col = df.shrinkage, hue = df.y, col_wrap = 3)shrinkage 파라미터를 0에서부터 2까지 점점 늘려가며 변주를 줬을 때의 데이터는 다음과 같이 변화한다.
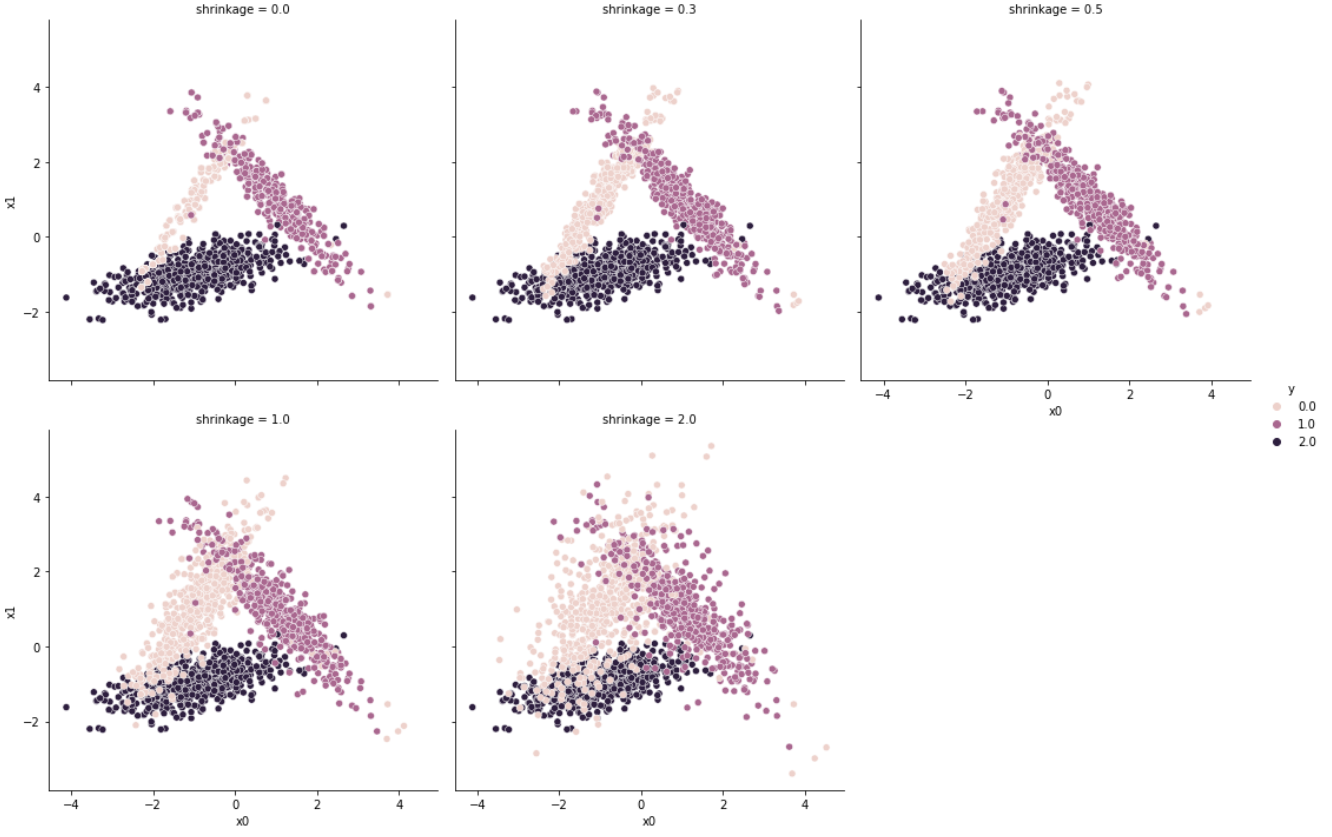
값이 커질수록 데이터가 더 많이 확산되어 resample되는 것을 확인할 수 있다.
3. SMOTE
SMOTE (Synthetic Minority Over-sampling Technique)는 가장 대중화된 오버샘플링 기법 중 하나로, 같은 클래스에 속한 데이터 사이의 거리를 임의의 값으로 내분하는 지점에 새로운 데이터를 생성하는 것이다.
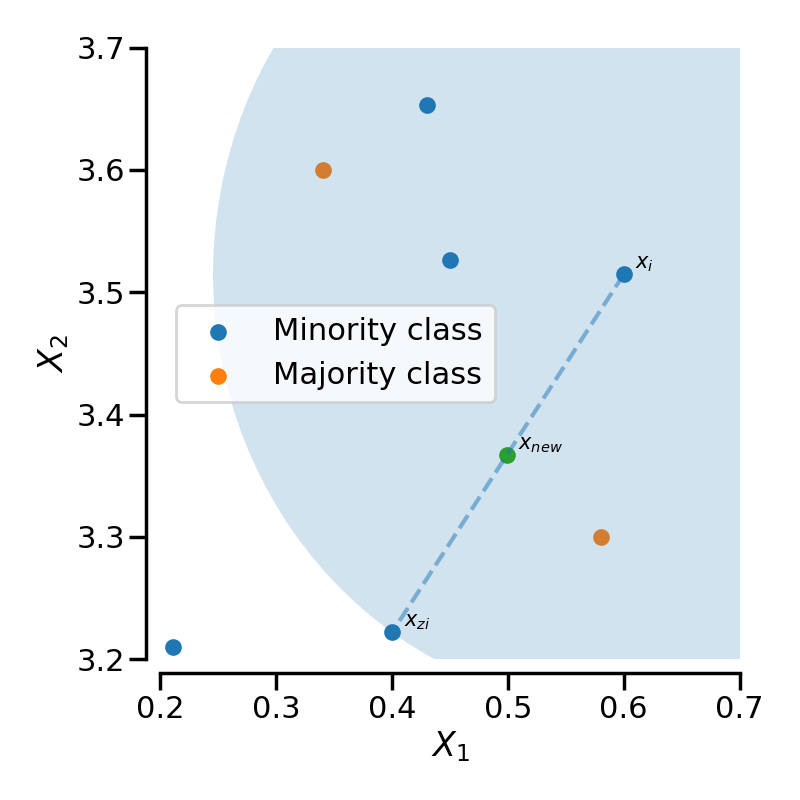
SMOTE는 KNN (K-nearest neighbors) 알고리즘을 기반으로 한다.
임의의 한점 에서 와 같은 클래스를 가진 데이터 중, 가장 가까운 개(여기서는 )의 데이터를 찾는다. 해당 점과 그 중 한 점()을 연결하는 선분 상에 임의의 데이터()를 생성한다.
기존의 KNN 알고리즘은 특정 데이터()가 있을 때, 이웃한 데이터들의 클래스를 고려하지 않는데 비해, SMOTE에서의 KNN은 이웃한 데이터들의 클래스를 고려한다는 차이점이 존재합니다.
기존의 KNN 알고리즘에서 탐색 범위(파란 원) 내에 총 5개의 데이터가 존재하므로 이 때의 값은 5입니다.
3.1 예시
# Oversampling with SMOTE
from imblearn.over_sampling import SMOTE, ADASYN
smote = SMOTE()
X_smote, y_smote = smote.fit_resample(X,y)
# 새로이 생성된 데이터 확인
original = np.hstack([X,y.reshape(-1,1)]) # 1000
smote_aug = np.hstack([X_smote, y_smote.reshape(-1,1)]) #1707
total = np.vstack([original, smote_aug])
df_total = pd.DataFrame(total, columns = ["x0","x1","y"])
df_total['is_aug'] = [0]*len(df_total)
df_aug = df_total.drop_duplicates(keep = False)
df_aug['is_aug'] = [1]*len(df_aug)
df_total = pd.concat([df_total, df_aug])
sns.relplot(data = df_total, x = df_total.x0, y = df_total.x1, hue = df_total.y, col = df_total.is_aug, style = df_total.is_aug)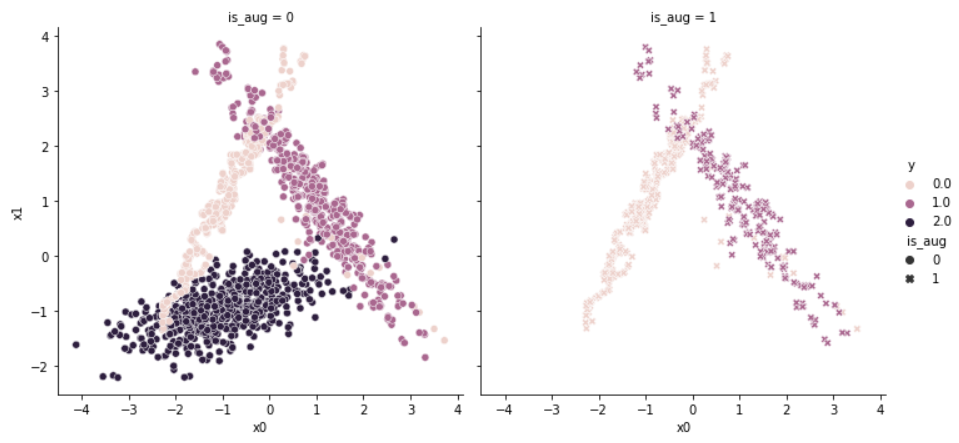
왼쪽은 SMOTE 알고리즘을 통해 증강된 데이터이며, 오른쪽은 새로이 생긴 증가분만을 시각화한 것이다. (왼쪽에는 원래 증강 전 원본 데이터를 시각화하려 하였지만, 코딩을 잘못했다는 것을 문서 작성할 때 확인했습니다.)
해당 그래프만으로는 데이터를 잇는 선분 사이에 새로운 데이터가 생성되었다는 것을 확인하기는 어렵지만, 새로이 생긴 데이터가 기존의 데이터와 비슷한 분포를 가진다는 것을 확인할 수 있다.
4. ADASYN
ADASYN(Adaptive Synthetic)은 SMOTE 알고리즘의 단점을 보완하기 위한 기법이다. SMOTE 알고리즘은 데이터를 전반적으로 증강시키기 때문에 학습이 어려운 데이터를 고려하지 못한다는 단점을 가졌다.
가령, 1의 클래스에 속하는 데이터 주위에 1의 클래스에 속하는 데이터만이 존재한다고 해보자. 이 경우, 특정 데이터가 1의 클래스에 속한다는 것을 쉽게 확인할 수 있다.
그러나 해당 클래스 주위에 1의 클래스에 속하는 데이터가 3개, 2의 클래스에 속하는 데이터가 3개 있다고 가졍해보자. 이 경우, 해당 데이터가 어느 클래스에 속하는지 확인하기 어렵다.
ADASYN은 특정 데이터 주변에 특정 데이터와 다른 클래스에 속하는 데이터의 수를 고려하여 데이터를 증강시킨다.
즉, 특정 데이터와 다른 클래스에 속한 데이터가 주변에 많을수록, 특정 데이터와 같은 클래스에 속한 인위적 (synthetic) 데이터를 많이 생성하여, 클래스 간의 경계를 더욱 확고히 하고자 한다.
4.1. 예시
# Oversampling with ADASYN
from imblearn.over_sampling import SMOTE, ADASYN
adasyn = ADASYN()
X_ada, y_ada = adasyn.fit_resample(X,y)
# adasyn로 증강된 데이터
sns.scatterplot(data = X_ada, x = X_ada[:,0], y = X_ada[:,1], hue = y_ada)
# 새로이 생성된 데이터 확인
original = np.hstack([X,y.reshape(-1,1)]) # 1000
ada_aug = np.hstack([X_ada, y_ada.reshape(-1,1)]) #1707
total = np.vstack([original, ada_aug])
df_total = pd.DataFrame(total, columns = ["x0","x1","y"])
df_total['is_aug'] = [0]*len(df_total)
df_aug = df_total.drop_duplicates(keep = False)
df_aug['is_aug'] = [1]*len(df_aug)
df_total = pd.concat([df_total, df_aug])
sns.relplot(data = df_total, x = df_total.x0, y = df_total.x1, hue = df_total.y, col = df_total.is_aug, style = df_total.is_aug)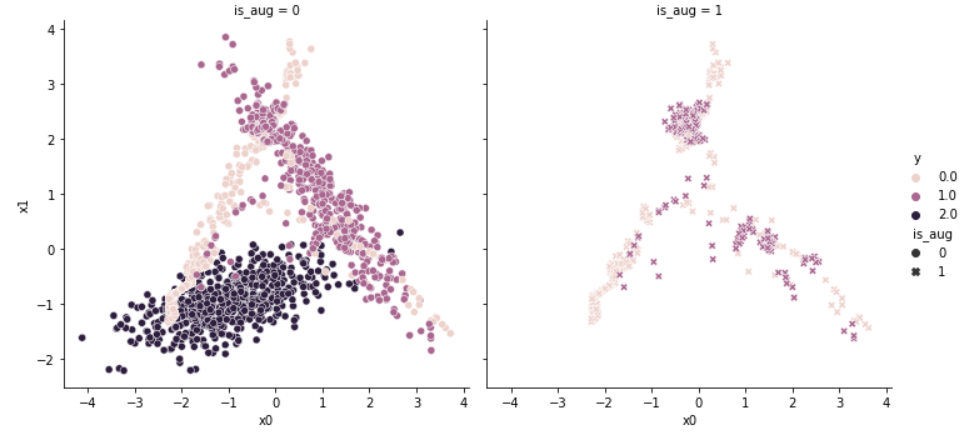
왼쪽 그래프는 ADASYN 알고리즘을 통해 증강된 결과이며, 오른쪽 그래프는 증강분만을 나타낸 결과다.
SMOTE 알고리즘과 달리, 각 군집이 겹치는 부분을 위주로 데이터가 새로이 생성되었음을 확인할 수 있다.
5. 참조
-
Sklearn : Over-sampling
-
SMOTE : Nitesh V Chawla, Kevin W Bowyer, Lawrence O Hall, and W Philip Kegelmeyer. Smote: synthetic minority over-sampling technique. Journal of artificial intelligence research, 16:321–357, 2002.
-
ADASYN : Haibo He, Yang Bai, Edwardo A Garcia, and Shutao Li. Adasyn: adaptive synthetic sampling approach for imbalanced learning. In 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), 1322–1328. IEEE, 2008.

안녕하세요! random oversampling에 대해 공부하고 있는데 저는 shrinkage가 없는 파라미터라고 에러가 뜨는데 혹시 imbalanced-learn 버전 알 수 있을까요?ㅠㅠㅠ