OpenPose
We present an approach to efficiently detect the 2D pose of multiple people in an image. The approach uses a nonparametric representation, which we refer to as Part Affinity Fields (PAFs), to learn to associate body parts with individuals in the image. The architecture encodes global context, allowing a greedy bottom-up parsing step that maintains high accuracy while achieving realtime performance, irrespective of the number of people in the image. The architecture is designed to jointly learn part locations and their association via two branches of the same sequential prediction process. Our method placed first in the inaugural COCO 2016 keypoints challenge, and significantly exceeds the previous state-of-the-art result on the MPII Multi-Person benchmark, both in performance and efficiency.
Cao, Zhe, et al. "Realtime multi-person 2d pose estimation using part affinity fields." Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.
OpenPose Pipeline
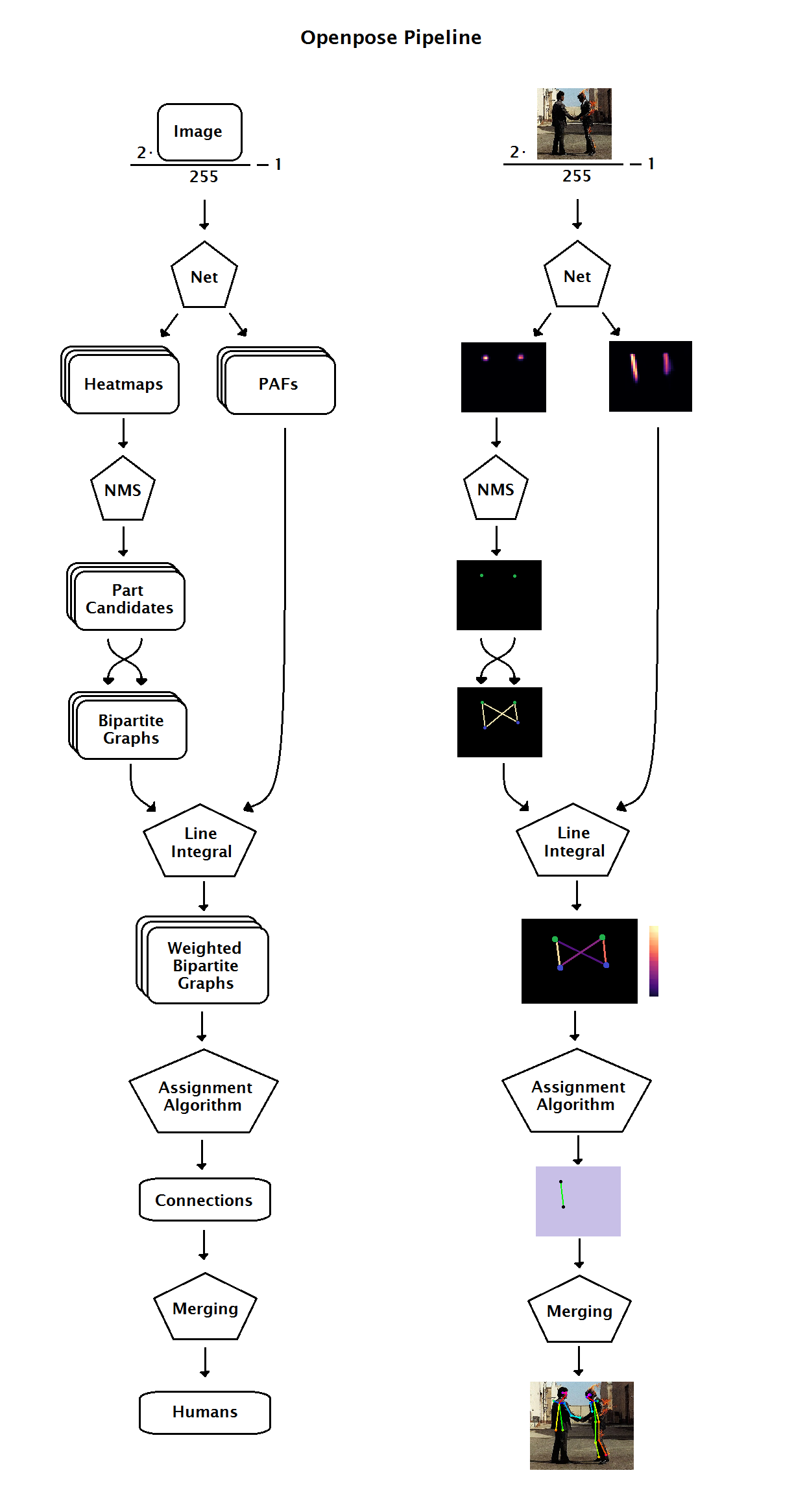
OpenPose Structure
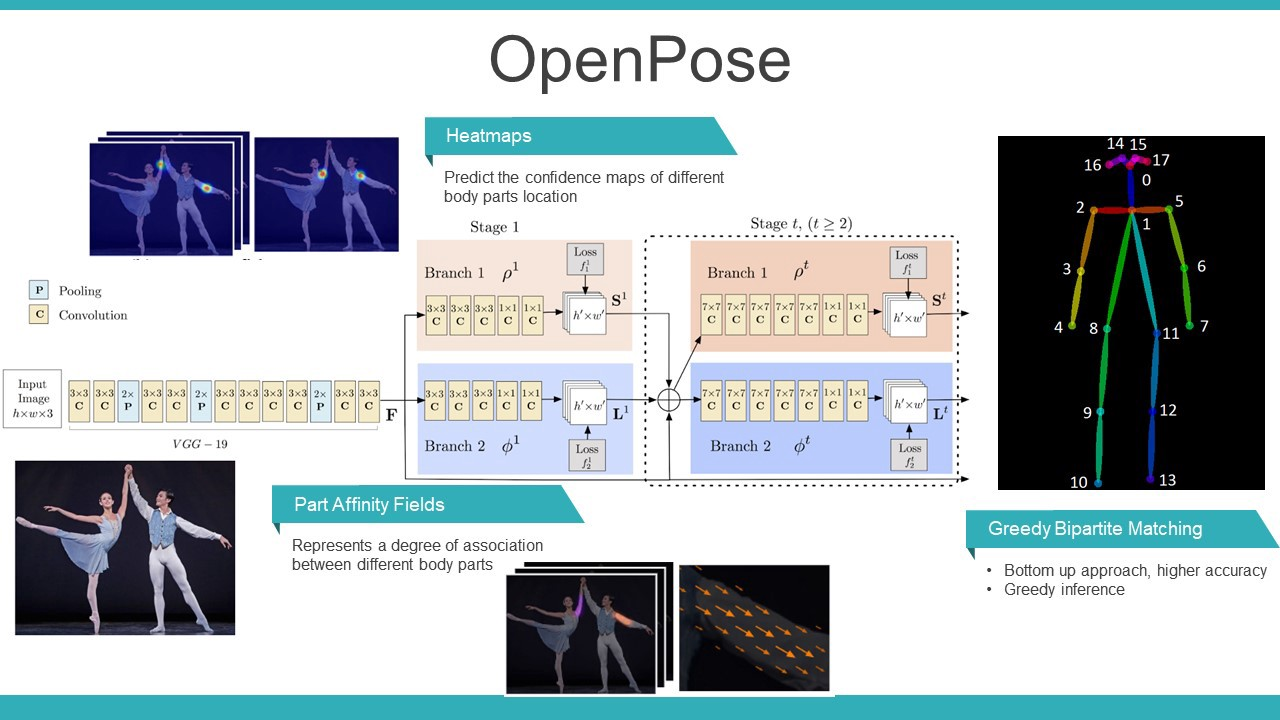
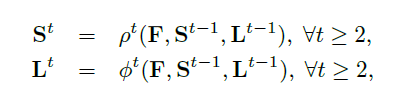
이미지를 VGG-19 네트워크에 통과시켜 feature map(F)을 만들어내고 이를 각각 confidence heatmap, PAF라는 두 브랜치의 입력으로 사용한다. 브랜치의 아웃풋과 feature map을 concat 하여 다음 stage의 입력으로 사용할 feature map을 만든다.
Keyword
- part (또는 joint, keypoint) : 관절
- limb (또는 part pair, part connection) : 두 관절의 연결(단, 실제 관절의 연결이라고는 볼 수 없는 pair도 있음.ex. 코 - 왼쪽 눈 연결)
VGG-19
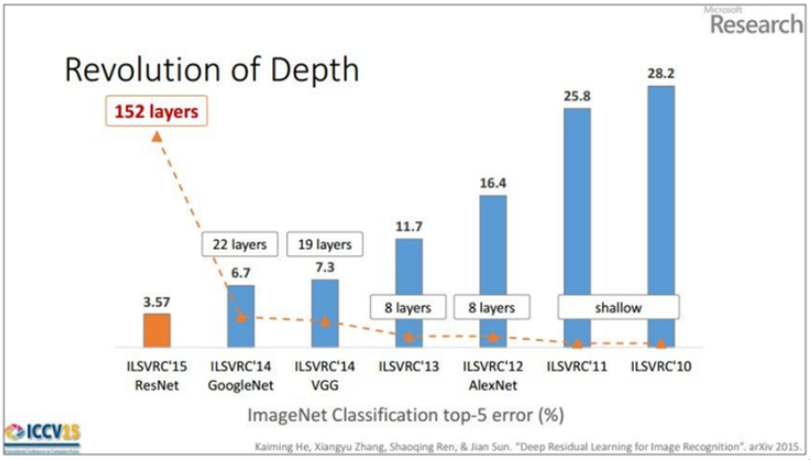
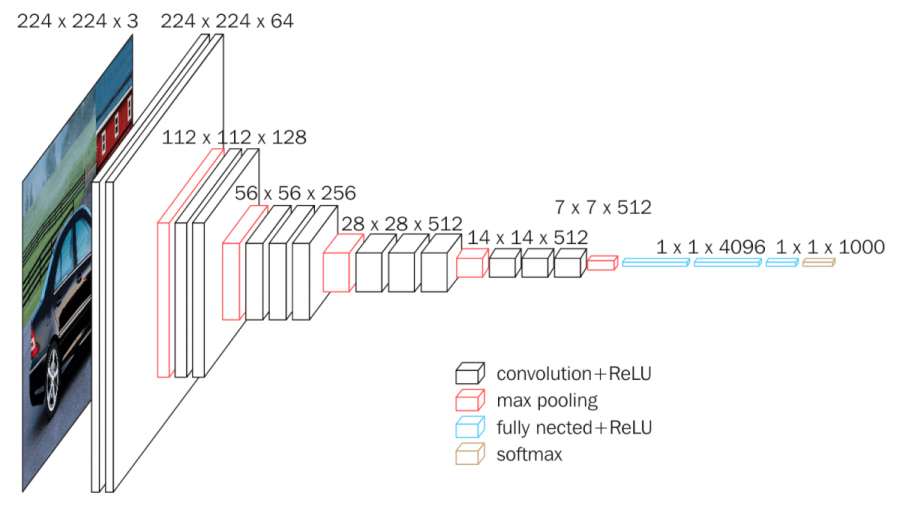
VGG net이란 2014년도 ILSVRC(ImageNet Large Scale Visual Recognition Challenge)에서 준우승을 한 네트워크로써 3x3 conv를 사용하여 간단한 내부구조를 가지고 있는 특징을 가지고 있어 다양한 연구 분야의 기초로써 사용되고 있다.
Confidence heatmap

사람의 자세를 추적하기 위해 관절을 찾는 네트워크이다.
각각의 dim(part)마다 관절이 있을만한곳을 예측하여 heatmap으로 표시한다.

confidence heatmap dim = 관절 포인트의 갯수
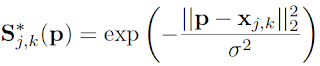
렌드마크를 이미지에 표시하기 위한 정규분포 식
: the ground-truth position of body part j for person k in the image.
: 이미지 내 픽셀의 위치
PAF(Part Affinity Field)
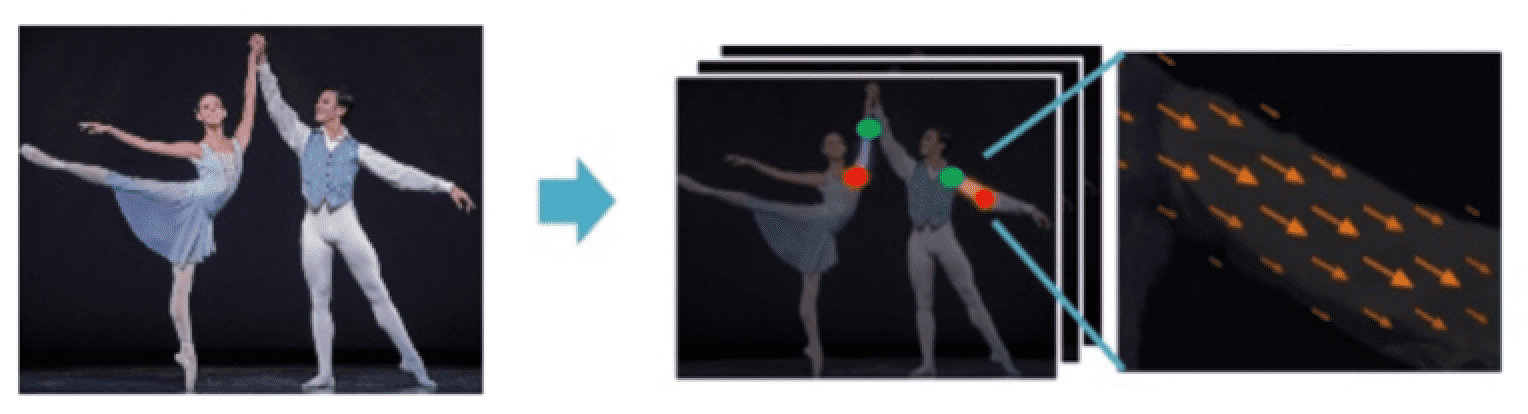
관절간의 연관성을 판단하기 위해 방향과 위치 정보를 가진 텐서라고 생각할 수 있다.
사람의 관절과 관절 사이에 있는 방향관계를 표현함으로써 그 관절들이 다음 관절이 맞을지를 예측하는 텐서이다.
Keypoint
confidence map을 사용해 관절을 찾고,
PAF를 사용해 관절간의 연결관계를 찾는다.
Tensorflow Basic
Build a machine learning model
# 모델 선언
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10)
])
# LOSS 함수 선언
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
# 모델 compile
model.compile(optimizer='adam',
loss=loss_fn,
metrics=['accuracy'])Train and evaluate your model
# train
model.fit(x_train, y_train, epochs=5)
# eval
model.evaluate(x_test, y_test, verbose=2)tf2 에서는 이러한 과정을 거쳐 모델을 훈련시키고 결과를 리턴 한다.
하지만 tf-PoseEstimator는 tf1 을 사용하고 있다. tf1에서는 Session이라는 모듈을 사용해 모델을 인퍼런스 시키는데 이 Session 모듈은 tf2에서는 이제 사용하지않는다.
Tf-PoseEstimator
run_webcam.py
while True:
ret_val, image = cam.read()
logger.debug('image process+')
humans = e.inference(image, resize_to_default=(w > 0 and h > 0), upsample_size=args.resize_out_ratio)
logger.debug('postprocess+')
image = TfPoseEstimator.draw_humans(image, humans, imgcopy=False)
logger.debug('show+')
cv2.putText(image,
"FPS: %f" % (1.0 / (time.time() - fps_time)),
(10, 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5,
(0, 255, 0), 2)
cv2.imshow('tf-pose-estimation result', image)
fps_time = time.time()
if cv2.waitKey(1) == 27:
break
logger.debug('finished+')이미지를 캠에서 read() 하여 모델에 inference 하면 모델의 렌드마크가 humans에 리턴되어져 온다.

이후 TfPoseEstimator.draw_humans 함수를 사용해 사진의 사람을 찾아 자세를 추적한 이미지를 리턴하여 cv2.imshow으로 보여준다.
estimator.py -> Class TfPoseEstimator -> def inference
def inference(self, npimg, resize_to_default=True, upsample_size=1.0):
if npimg is None:
raise Exception('The image is not valid. Please check your image exists.')
if resize_to_default:
upsample_size = [int(self.target_size[1] / 8 * upsample_size), int(self.target_size[0] / 8 * upsample_size)]
else:
upsample_size = [int(npimg.shape[0] / 8 * upsample_size), int(npimg.shape[1] / 8 * upsample_size)]
if self.tensor_image.dtype == tf.quint8:
# quantize input image
npimg = TfPoseEstimator._quantize_img(npimg)
pass
logger.debug('inference+ original shape=%dx%d' % (npimg.shape[1], npimg.shape[0]))
img = npimg
if resize_to_default:
img = self._get_scaled_img(npimg, None)[0][0]
# self.persistent_sess = tf.compat.v1.Session(graph=self.graph, config=tf_config) << 으로 Session 선언
peaks, heatMat_up, pafMat_up = self.persistent_sess.run(
[self.tensor_peaks, self.tensor_heatMat_up, self.tensor_pafMat_up], feed_dict={
self.tensor_image: [img], self.upsample_size: upsample_size
})
# 사진의 peaks, heatMat_up, pafMat_up 추출
peaks = peaks[0]
self.heatMat = heatMat_up[0]
self.pafMat = pafMat_up[0]
logger.debug('inference- heatMat=%dx%d pafMat=%dx%d' % (
self.heatMat.shape[1], self.heatMat.shape[0], self.pafMat.shape[1], self.pafMat.shape[0]))
t = time.time()
humans = PoseEstimator.estimate_paf(peaks, self.heatMat, self.pafMat)
logger.debug('estimate time=%.5f' % (time.time() - t))
return humansTfPoseEstimator -> def inference 에서는 한장의 이미지에서 peaks, heatMat_up, pafMat_up를 구하여 Class PoseEsimator -> def estimate_paf 으로 넘겨주어 이미지에 렌드마크의 위치를 humans 에 담아 리턴한다.
estimator.py -> Class PoseEsimator -> def estimate_paf
@staticmethod
def estimate_paf(peaks, heat_mat, paf_mat):
pafprocess.process_paf(peaks, heat_mat, paf_mat)
humans = []
for human_id in range(pafprocess.get_num_humans()):
human = Human([])
is_added = False
for part_idx in range(18):
c_idx = int(pafprocess.get_part_cid(human_id, part_idx))
if c_idx < 0:
continue
is_added = True
human.body_parts[part_idx] = BodyPart(
'%d-%d' % (human_id, part_idx), part_idx,
float(pafprocess.get_part_x(c_idx)) / heat_mat.shape[1],
float(pafprocess.get_part_y(c_idx)) / heat_mat.shape[0],
pafprocess.get_part_score(c_idx)
)
if is_added:
score = pafprocess.get_score(human_id)
human.score = score
humans.append(human)
return humanspafprocess.py -> def process_paf
def process_paf(p1, h1, f1):
return _pafprocess.process_paf(p1, h1, f1)
process_paf = _pafprocess.process_paf
def get_num_humans():
return _pafprocess.get_num_humans()
get_num_humans = _pafprocess.get_num_humans
def get_part_cid(human_id, part_id):
return _pafprocess.get_part_cid(human_id, part_id)
get_part_cid = _pafprocess.get_part_cid
def get_score(human_id):
return _pafprocess.get_score(human_id)
get_score = _pafprocess.get_score
def get_part_x(cid):
return _pafprocess.get_part_x(cid)
get_part_x = _pafprocess.get_part_x
def get_part_y(cid):
return _pafprocess.get_part_y(cid)
get_part_y = _pafprocess.get_part_y
def get_part_score(cid):
return _pafprocess.get_part_score(cid)
get_part_score = _pafprocess.get_part_score다른 모듈(C)에서 작성한 parprocess 를 동적으로 import하여 사용함
estimator.py -> def draw_humans
@staticmethod
def draw_humans(npimg, humans, imgcopy=False):
if imgcopy:
npimg = np.copy(npimg)
image_h, image_w = npimg.shape[:2]
centers = {}
for human in humans:
# draw point
for i in range(common.CocoPart.Background.value):
if i not in human.body_parts.keys():
continue
body_part = human.body_parts[i]
center = (int(body_part.x * image_w + 0.5), int(body_part.y * image_h + 0.5))
centers[i] = center
cv2.circle(npimg, center, 3, common.CocoColors[i], thickness=3, lineType=8, shift=0)
# draw line
for pair_order, pair in enumerate(common.CocoPairsRender):
if pair[0] not in human.body_parts.keys() or pair[1] not in human.body_parts.keys():
continue
# npimg = cv2.line(npimg, centers[pair[0]], centers[pair[1]], common.CocoColors[pair_order], 3)
cv2.line(npimg, centers[pair[0]], centers[pair[1]], common.CocoColors[pair_order], 3)
return npimg body_part = human.body_parts[i]에서 점의 좌표를 얻어 cv2.circle로 그려주고
pair을 찾아 선을 그려준다.
