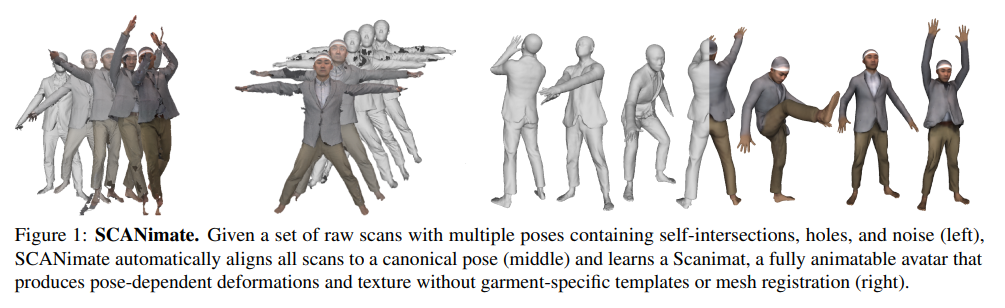
Abstract
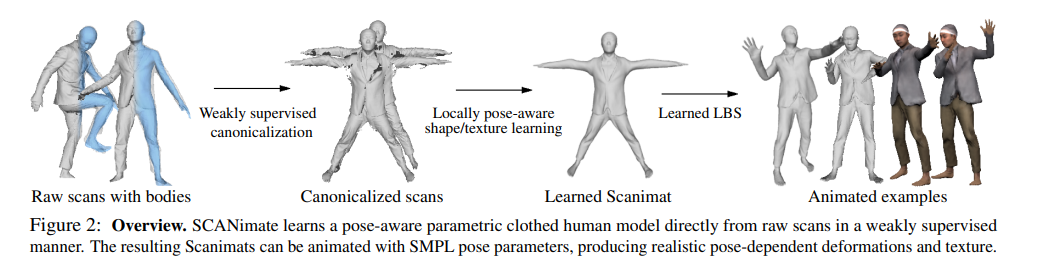
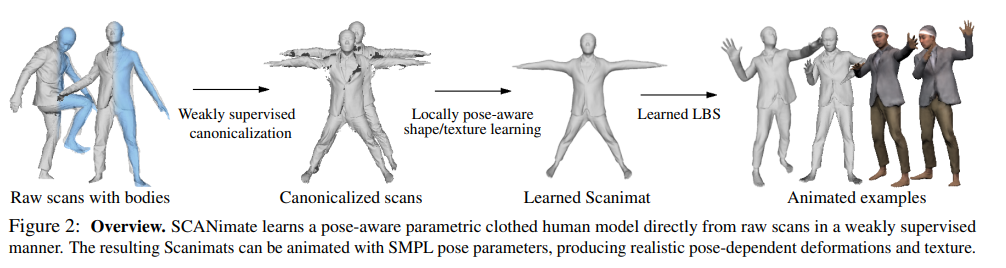
We present SCANimate, an end-to-end trainable framework that takes raw 3D scans of a clothed human and turns them into an animatable avatar. These avatars are driven by pose parameters and have realistic clothing that moves and deforms naturally. SCANimate does not rely on a customized mesh template or surface mesh registration. We observe that fitting a parametric 3D body model, like SMPL, to a clothed human scan is tractable while surface registration of the body topology to the scan is often not, because clothing can deviate significantly from the body shape.
기존에 사용하던 SMPL 같은 모델은 옷을 입은 사람의 3d 스캔을 추출할 수 있지만, 옷 때문에 인간의 몸에 대한 정확한 3d 측정이 어려움. 따라서 SCANimate는 미리 정해진 메쉬 템플릿이나 표면을 사용하지 않음
We also observe that articulated transformations are invertible, resulting in geometric cycle-consistency in the posed and unposed shapes. These observations lead us to a weakly supervised learning method that aligns scans into a canonical pose by disentangling articulated deformations without templatebased surface registration. Furthermore, to complete missing regions in the aligned scans while modeling posedependent deformations, we introduce a locally pose-aware implicit function that learns to complete and model geometry with learned pose correctives. In contrast to commonly used global pose embeddings, our local pose conditioning significantly reduces long-range spurious correlations and improves generalization to unseen poses, especially when training data is limited. Our method can be applied to poseaware appearance modeling to generate a fully textured avatar. We demonstrate our approach on various clothing types with different amounts of training data, outperforming existing solutions and other variants in terms of fidelity and generality in every setting.
관절 변환이 가역적인것에 기인하여 3d raw 화면에 포착된 포즈를 일관적인 포즈로 정렬하여 학습하는 방법을 사용하였음.
Introduction
Parametric models of 3D human bodies are widely used for the analysis and synthesis of human shape, pose, and motion. While existing models typically represent “minimally clothed” bodies [4, 26, 43, 52, 66], many applications require realistically clothed bodies. Our goal is to make it easy to produce a realistic 3D avatar of a clothed person that can be reposed and animated as easily as existing models like SMPL [43].
논문의 목표는 SMPL같은 자세변경이 가능하고 쉽게 애니메이션할 수 있는 (옷을입은)사실적인 3d 아바타를 쉽게 생성하는 것
SCANimate has the following properties:
(1) we learn an articulated clothed human model directly from raw scans, completely eliminating the need for surface registration of a custom template or synthetic clothing simulation data,
(2) our parametric model retains the complex and detailed deformations of clothing present in the original scans such as wrinkles and sliding effects of garments with arbitrary topology,
(3) a Scanimat can be animated directly using SMPL pose parameters, and
(4) our approach predicts pose-dependent clothing deformations based on local pose parameters, providing generalization to unseen poses.
SCANimate의 속성
1) raw 스캔(아무런 처리를 거치지 않은 3d 스캔)에서 사람이 입은 옷을 학습하므로 의류 템플릿을 미리 등록할 필요가 없음
2) 의복의 주름같은 변형을 유지함
3) SMPL을 사용하여 시스템 사용자가 3d 모델을 직접 애니메이팅 할 수 있음
4) SMPL을 사용해 새로운 포즈에 대한 의류 변형을 예측함
Although one can learn from synthetic data generated by physics-based clothing simulation [23, 25, 54], the results are less realistic, the data preparation is time consuming and non-trivial to scale to the real-world clothing.
To address these issues, SCANimate learns directly from raw scans of people in clothing. Body scanning is becoming common, and scans can be obtained from a variety of devices. Scans contain high-frequency details, capture varied clothing topology, and are inherently realistic.
기존의 방법들은 3d 의복 데이터를 만들어내기 위해 많은 코스트가 소모되는 편
이를 해결하기 위해 SCANimate는 raw scan 데이터에서 직접 옷에 대한 학습을 진행함
Canonicalization and Implicit Skinning Fields
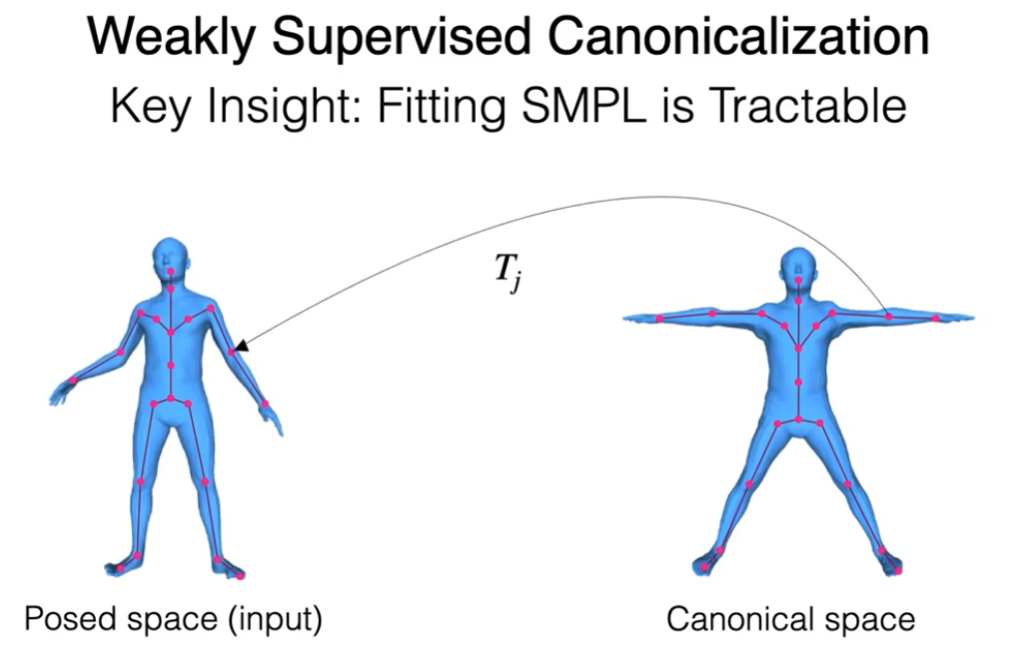
Instead, we learn continuous functions of 3D space that allow us to transform posed scans to a canonical pose and back again.
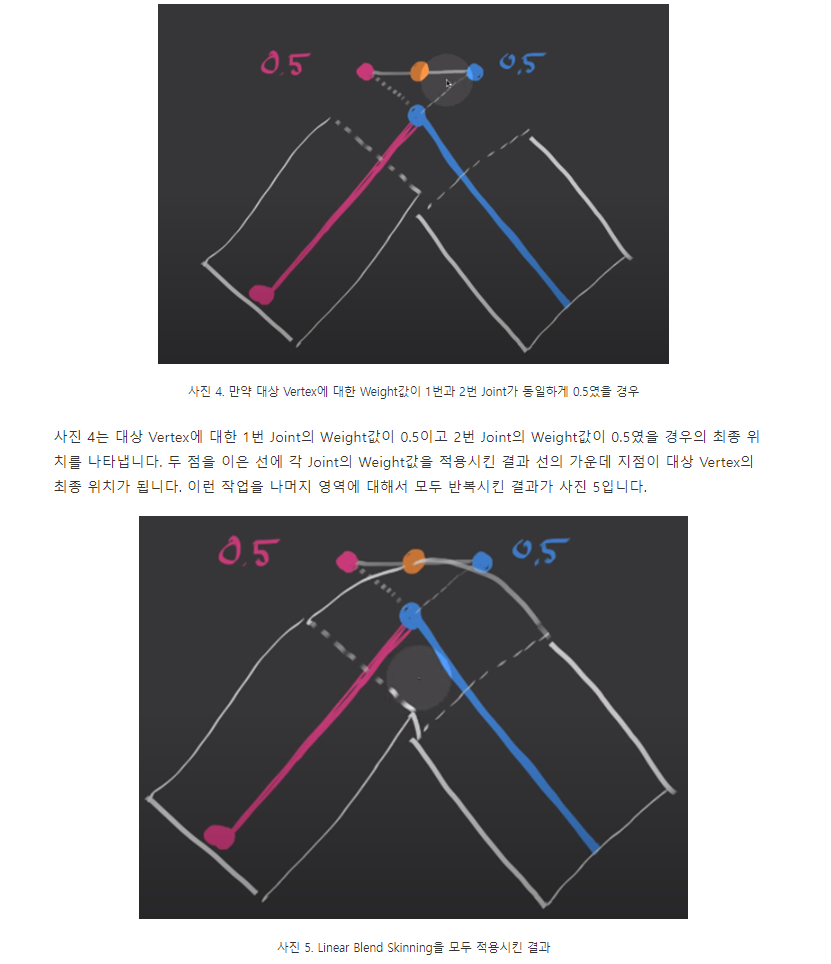
The key idea is to build this on linear blend skinning (LBS), which traditionally defines weights on the surface of a mesh that encode how much each vertex is influenced by the rotation of a body joint.
An inverse LBS function uses the regressed skinning weights to “undo” the pose of the body and transforms the points into the canonical space.
몸체 관절의 회전에 영향을 받는 메시 표면의 가중치를 LBS를 기반으로 구축(학습??)하는것으로 raw 스캔에서 나온 사람의 포즈를 표준 포즈로 되돌리는 함수(LBS의 역함수)를 학습시킨다.
Specifically, given a 3D location x, we regress a continuous vector function g represented by a neural network, g(x) : R 3 → R J , which defines the skinning weights.
3d 좌표 x 에 대해 표면 가중치를 정의하는 연속 백터 함수 G를 NN을 사용해서 근사할 수 있음
What is a "continuous vector"?
Continuous vector simply means that each value of the vector is allowed to be a real number, in contrast of integer values used in other categorical encoding techniques like one-hot encoding (only 0 and 1) or class-value mapping (a different integer per class).
Furthermore, we can easily generate animations of the parametric clothed avatar by applying forward LBS to the clothed body in the canonical pose with the learned pose correctives..
LBS를 통해 옷을 입은 3d 아바타의 애니메이션을 쉽게 생성할 수 있음
Cycle Consistency
Despite the desirable properties of canonicalization, learning the skinning function is ill-posed since we do not have ground truth training data that specifies the weights.
실측 데이터(GT)가 없기 때문에 표면 가중치를 결정하는 표면 함수를 "학습"할 수 없으므로
First, as demonstrated in previous work [27, 69, 72], fitting a parametric human body model such as SMPL [43] to 3D scans is more tractable than surface registration.
We leverage SMPL’s skinning weights, which are defined only on the body surface, to regularize our more general skinning function.- SMPL: a skinned multiperson linear model -
SMPL이 사용하는 skinning weights을 평균내어 표면 함수를 정규화하는데 사용함.
(SMPL 같이 미리 파라매트릭된 3d 사람 모델을 3d scan 결과에 가져다 맞추는게 표면을 직접 등록하는것보다 쉽다.)
Second, the transformations between the posed space and the canonical space should be cycle-consistent.
포즈 공간과 기저벡터공간 사이의 변환에서 주기적인 일관성이 존재하여야 함
Namely, inverse LBS and forward LBS together should form an identity mapping as illustrated in Fig. 3, which provides a self-supervision signal for training the skinning function.
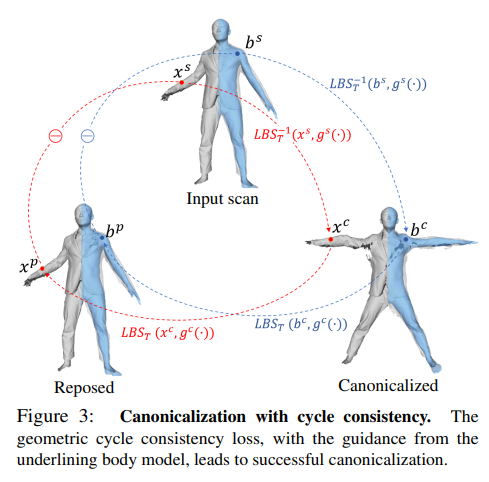
즉 역함수 LBS 와 LBS는 그림과 같이 동일한 매핑을 형성해야하며 이것이 skinning 함수를 훈련시키는 자기지도학습(비지도학습) 데이터를 제공함.
After training the skinning function, we obtain the canonicalized scans (all in the same pose).
skinning 함수를 훈련한 다음, 같은 포즈로 정규화된 스캔을 얻을 수 있음
-> skinning 함수 = 포즈 정규화 함수인지 확실하지 않음
Learning Implicit Pose Correctives
Given the canonicalized scans, we learn a model that captures the pose-dependent deformations.
However a problem remains: the original raw scans often contain holes, and so do the canonicalized scans.
To deal with this and with the arbitrary topology of clothing, we use an implicit surface representation [13, 47, 53].

주워진 정규화 스캔을 기반으로 모델은 'the pose-deqendent deformations'(포즈에 따라 달라지는 변형)을 학습한다.
하지만 인풋으로 주워진 스캔들은(정규화된 스캔 역시) 구멍들을 가지고 있고, 또한 옷이 발생시키는 임의의 토폴로지(모델의 폴리곤) 변화를 다루기 위해 implicit surface 함수를 사용하여 3d 모델을 표현함.
As multiple canonicalized scans will miss different regions, with this approach, they complement each other, while retaining details present in the original inputs.
표준화된 스캔들은 서로 다른 영역에 구멍이 뚫려 있으므로 implicit surface 접근방식을 사용하면 스캔들에 대하여 서로 보완하면서 원본 입력의 디테일한 정보들을 유지할 수 있다.
"TAILORNET: PREDICTING CLOTHING IN 3D AS A FUNCTION OF HUMAN POSE, SHAPE AND GARMENT STYLE"
Furthermore, unlike traditional approaches [39, 46, 54, 70], where pose-dependent deformations are conditioned on entire pose parameters, we spatially filter out irrelevant pose features from the input conditions by leveraging the learned skinning weights
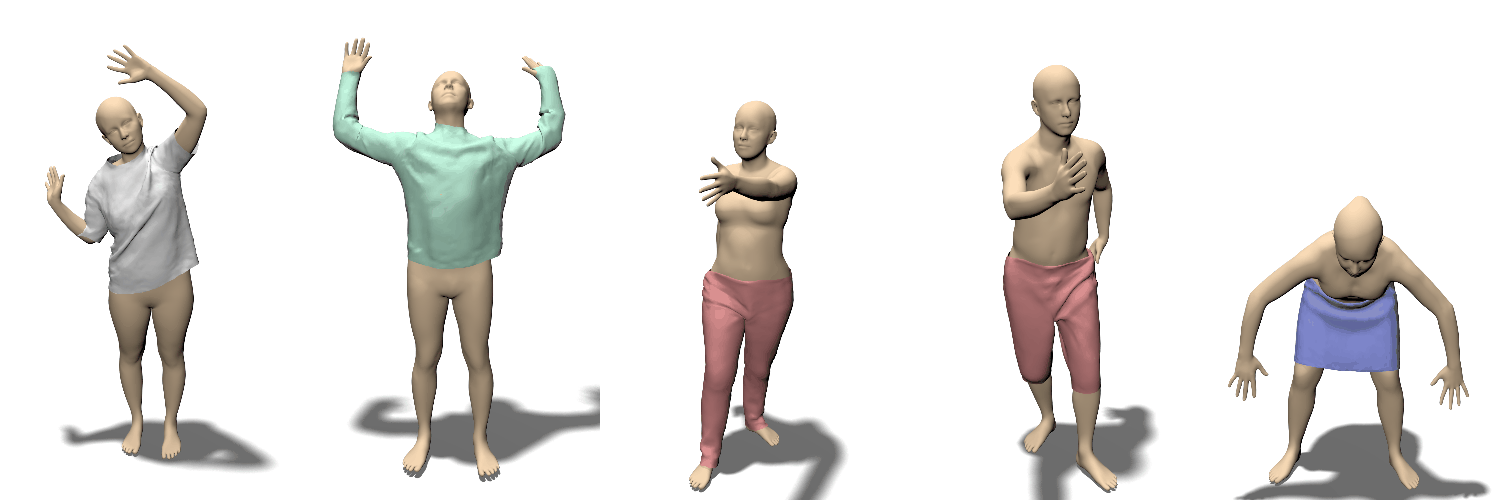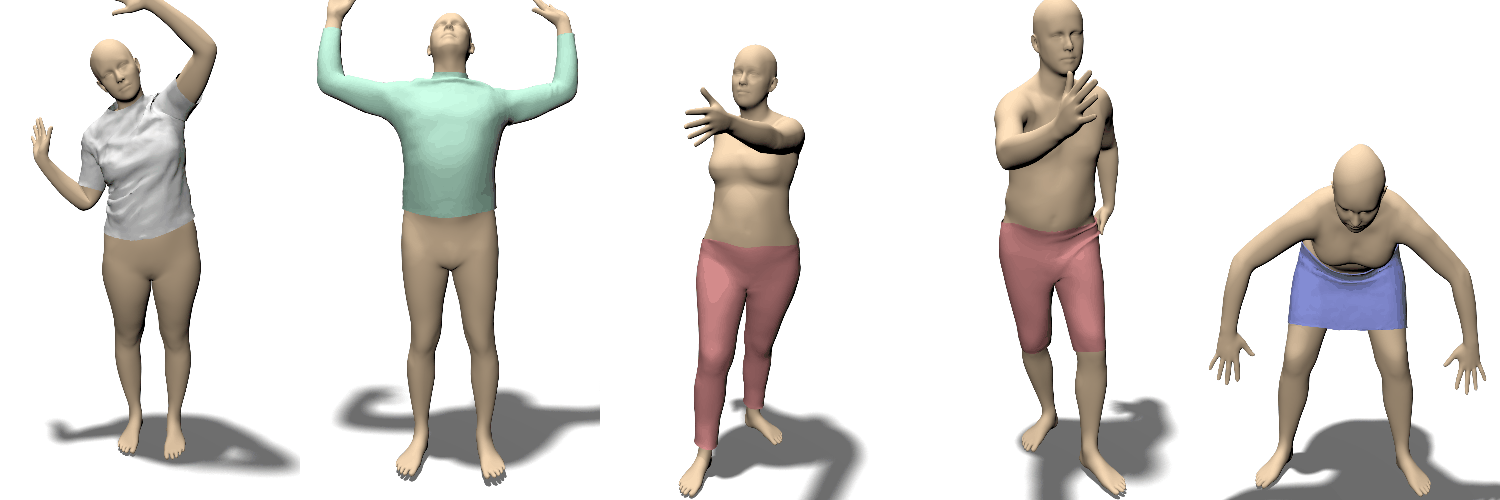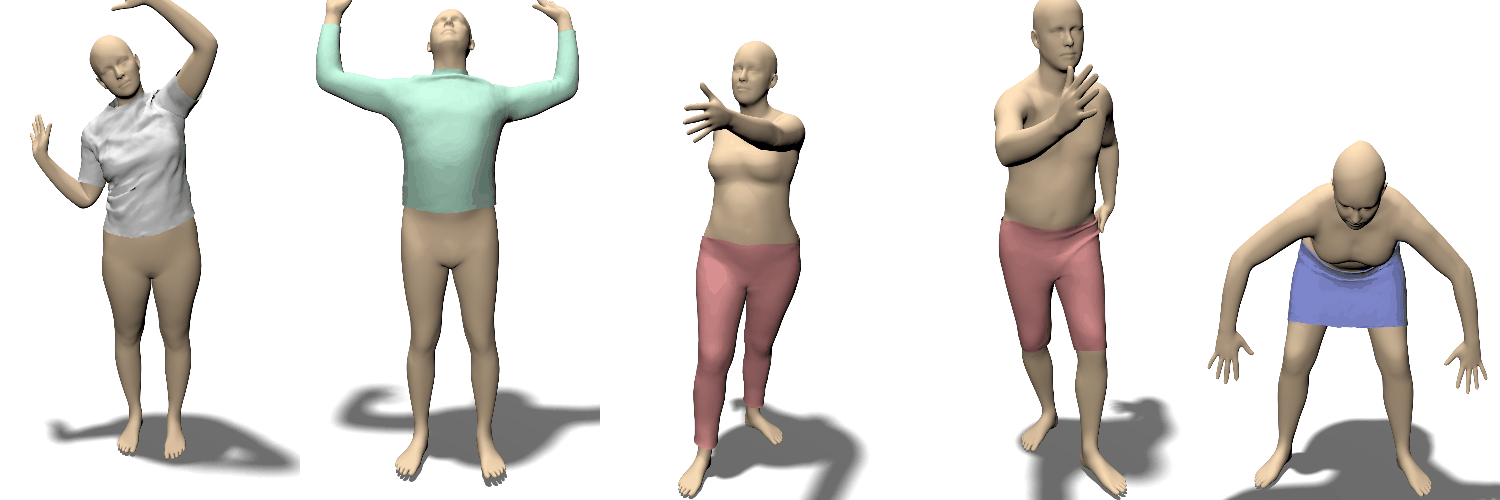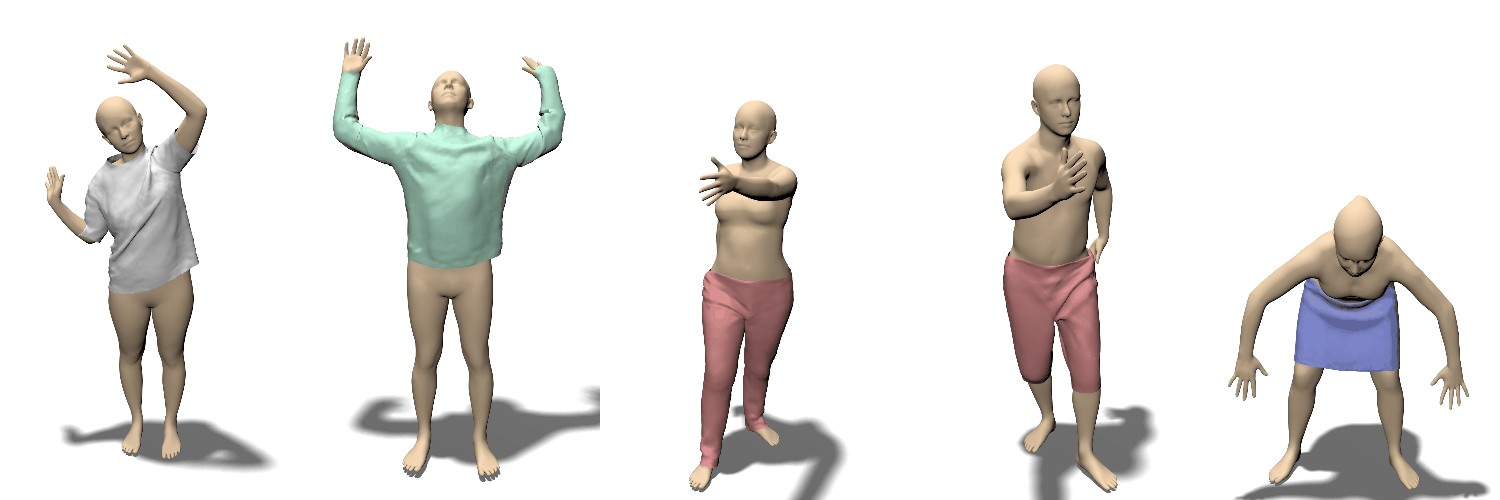
번역원문 :
또한, 포즈 의존적 변형이 전체 포즈 매개 변수에 대해 조건화되는 기존 접근 방식[39, 46, 54, 70]과 달리, 우리는 학습된 스킨 가중치를 활용하여 입력 조건에서 관련 없는 포즈 특징을 공간적으로 걸러낸다.
'pose parameters'에 조건화 되어야 했던 기존 접근방식들(옷의 3d 모델을 구성하는 전체 피라미터들에 대해 조건화 = 입력되는 포즈에 따라 변화되는 옷의 변형만 예측 가능(일반화가 잘 안됨))와는 다르게 본 논문의 모델은 학습된 skinning 가중치를 사용해 입력된 pose들의 매개변수들에서 쓸모없는 feature들을 걸러낸다. -> 학습하지 않은 포즈들에 대한 옷의 변화를 예측하는 모델(일반화가 잘 된 모델)
In this way, we effectively prune long-range spurious correlations between garment deformations and body joints, achieving plausible pose correctives for unseen poses even from a small number of training scans.
이러한 방식으로 인체관절과 의류 변형 사이의 쓸모없는 상관관계들을 효과적으로 제거할 수 있었고, 적은 수의 training 스캔으로도 관찰하지 않은 포즈에 대해 그럴듯한 예측이 가능했음
The resulting learned 'SCANimate' can be easily reposed and animated with SMPL pose parameters.
결과적으로 훈련된 SCANimate와 SMPL 파라미터를 통해 옷을 입은 3d 아바타의 제포징, 애니메이션이 보다 쉽게 가능해짐
main contribution summary
In summary,
our main contributions are (1) the first endto-end trainable framework to build a high-quality parametric clothed human model from raw scans,(2) a novel weaklysupervised formulation with geometric cycle-consistency that disentangles articulated deformations from the local pose correctives without requiring ground-truth training data,
and (3) a locally pose-aware implicit surface representation that models pose-dependent clothing deformation and generalizes to unseen poses.
- 1 : 원시 스캔에서 고품질의 매개변수화 된(리포징이 가능한) 옷을 입고 있는 3d 모델을 뽑아낼 수 있는 end to end 프레임워크
- 2 : 로컬 포즈의 교정에 따라 변형되는 관절 변형을 풀어주기 위한 훈련 데이터가 필요없는 비지도학습 방식
- 3 : 포즈를 인식하여 옷의 변형을 예측하는 implicit surface 모델(관찰되지 않은 포즈에 대해서도 일반화됨)
Related Work
Parametric Models for Human Bodies and Clothing
-parametric body model-
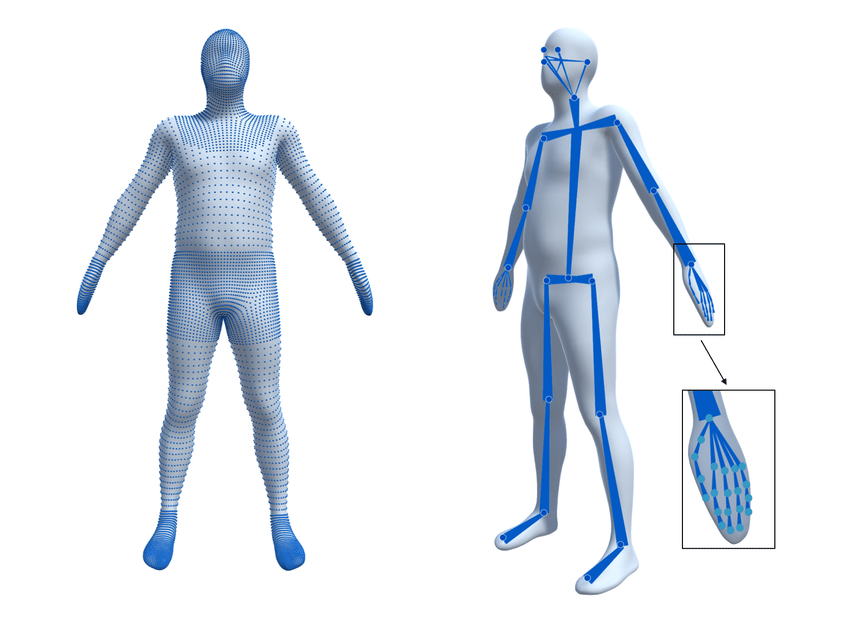
Parametric body models [4, 26, 43, 52, 66] learn statistical body shape variations and pose-dependent shape correctives that capture non-linear body deformation and compensate for linear blend skinning artifacts [3, 30, 37, 38, 41].
번역원문 :
파라메트릭 바디 모델 [4, 26, 43, 52, 66]은 비선형 바디 변형을 포착하고 선형 블렌드 스킨 가공물을 보상하는 통계적 체형 변화 및 자세 의존적 형상 보정을 학습한다 [3, 30, 37, 38, 41].
기존의 파라메트릭 바디 모델들(비선형적인 몸의 변형과 'linear blend skinning artifacts'을 보완하는)은 통계적인 체형 변화와 자세에 따라 달라지는 몸의 형태를 학습함.
이러한 접근 방식은 옷을 입지 않은 신체에 초점이 맞추어져 있음.
비슷한 아이디어로써 의류 레이어를 추가함으로써 옷을 입은 3d shape로 모델을 확장하였다.
-Non-rigid deformation-
'연성체의 변형' 본 논문에서는 아마 사람의 몸을 연성체라고 표현한 것 같음
These parametric clothed human models decompose garment deformations into articulated deformations and local deformations such that pose correctives only focus on nonrigid local deformations.
Thus, it is essential to obtain the inverse skinning transformation [54] by using the surface registration of a well-defined template [39, 43, 46, 70, 72] or using synthetic simulation data [15, 23, 25, 54].
이러한 파라메트릭한 옷을 입은 인간 3d 모델은 의복의 변형을 관절의 변형과 지역적인 변형으로 분해하여 구현하고 이는 "nonrigid local deformations" 에만 집중되고, 따라서 모델은 역-표면 변형을 추가하기 위해 잘 정의된 템플릿 표면을 등록하던가 인공적인 시뮬레이션 데이터를 사용한다.
-> 옷에 대한 표현이 고정적이고 단순한 의류만 사용이 가능하여 접근성이 떨어짐
In contrast, our work uses a weakly supervised approach to build a parametric clothed human model from raw scans without the requirement of a template and surface registration.
대조적으로 본 논문에서는 비지도학습 접근방식을 사용하여 원시 스캔에서 표면 등록이나 템플릿 없이 옷을 입은 인간 3d 모델을 만들어낸다.
We canonicalize posed scans and learn an implicit surface with arbitrary topology [22] conditioned on pose parameters by leveraging a fitted human body model to the scan data [5, 8, 69, 71, 72].
포즈 스캔들을 정규화시켰고, implict surface 함수를 임의의(구멍뚫린) 토폴로지를 가진 조건화된 포즈들(원본 스캔에서 추출한)로 학습시켰다.
Pose Canonicalization via Inverse LBS
The key to successful canonicalization is learning transformations in the form of skinning weights in a continuous space.
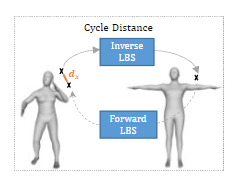
성공적인 표준화의 키는 연속 공간에서의 표면 가중치들의 형태(form) 변환을 학습시키는것이다.
->표면 가중치는 그래프 컨볼루션 네트워크를 사용해 학습함
Given a neutral-posed template, these networks predict skinning weights together with a skeleton [68] or posedependent deformations [7].
중립 자세 템플릿이 주어지면 이러한 [7, 42, 68] 그래프 컨볼루션 네트워크는 골격과 표면 가중치 그리고 포즈에 종속적인 변형을 예측함
-> 표면 메시의 GT와 표준화된(표준화되지않은)포즈에서의 표면 가중치 GT가 없는 상황에서 표면 가중치를 학습하는것이 문제
-> 다른 논문들에서는 표면 가중치를 미리 정해놓고 사용하여 학습시키지 못함(입력의 재현성이 줄어듬)
-> 이를 해결하기 위해 4.1절에서 표면 가중치를 jointly 하게 학습시키는 방법을 사용하였음
-cycle consistency-
Inspired by recent unsupervised methods using cycle consistency [12, 75], we leverage geometric cycle consistency between the canonical space and posed space to learn skinning weights in a weakly supervised manner without requiring any ground-truth training data.
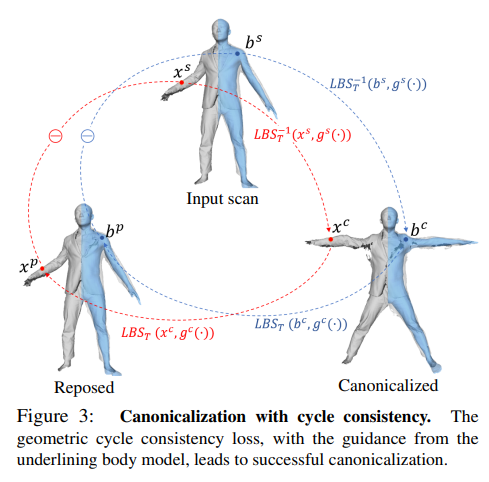
본 논문에서는 주기 일관성을 활용해 실측 training 데이터 없이 비지도학습을 시켜서 표면 가중치를 학습시킨다.
Reconstructing Clothed Humans
While many works focus on the minimally clothed human body [11, 24, 32, 36, 40], recent approaches show promise in reconstructing clothed human models from RGB inputs using the SMPL mesh with displacements [1, 2, 74], external garment layers [10, 31], depth maps [19, 62], voxels [63, 73], or implicit functions [29, 59, 60].
현제 많은 연구들이 RGB 입력에서 옷을 입은 인간의 3d 모델을 reconstruction 하려는 시도를 하고 있다.
하지만 이러한 연구들은 자세의 변형에 따른 옷의 변형(pose-dependent deformation of garments)을 학습하지 않고 단순히 reconstruction 된 shape에 관절의 변형을 적용시키기 때문에
This results in unrealistic pose-dependent deformations that lack garment specific wrinkles.
자세의 변형에 따른 옷의 변형 대해 비현실적이며, 옷감의 주름에 대해서도 구체적이지 못함
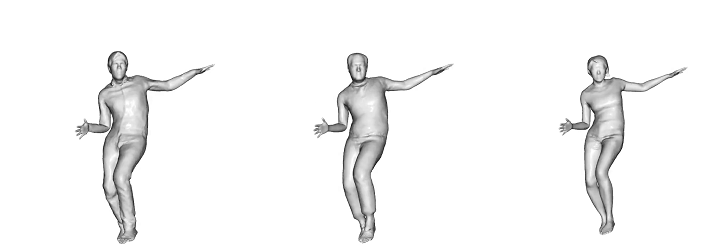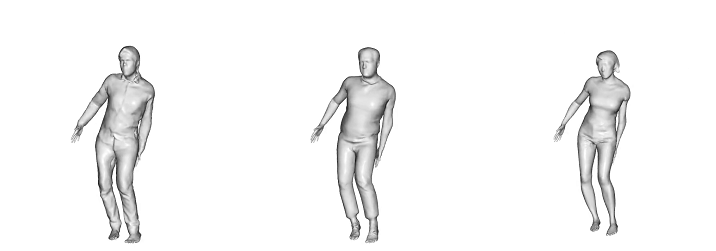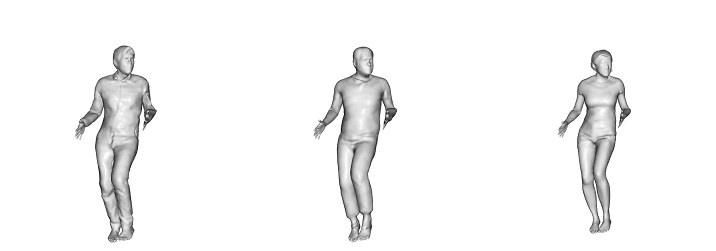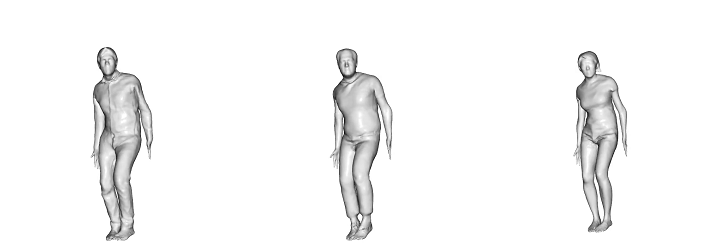
-> 본 논문에서는 raw scan에서 자세의 변형에 대한 옷의 변형 역시 학습할 수 있다는것에 초점을 맞춤
3. Method
-Overview-
Here we use the SMPL model [43] fit to the scans to obtain body joints and blend skinning weights, which we exploit in learning.
-
모델의 입력은 Clothed Raw scan + Body model 임
Body model 을 얻기 위해 SMPL model을 사용하였음
-> 왜냐면 SMPL은 다루기 쉽기 때문에
-> SMPL은 인체의 관절과 skinnig 가중치를 얻기 위해 사용됨 -
위의 입력이 주워지면 공간좌표함수(function of space coordinates)를 사용해 skinning 가중치를 예측하여 모델이 포즈된 공간<->모델이 정규화된 공간 의 양방향 변환하는 함수를 학습함 (입력된 자세<-양방향변환(역함수)->교정된 자세) 3.1절
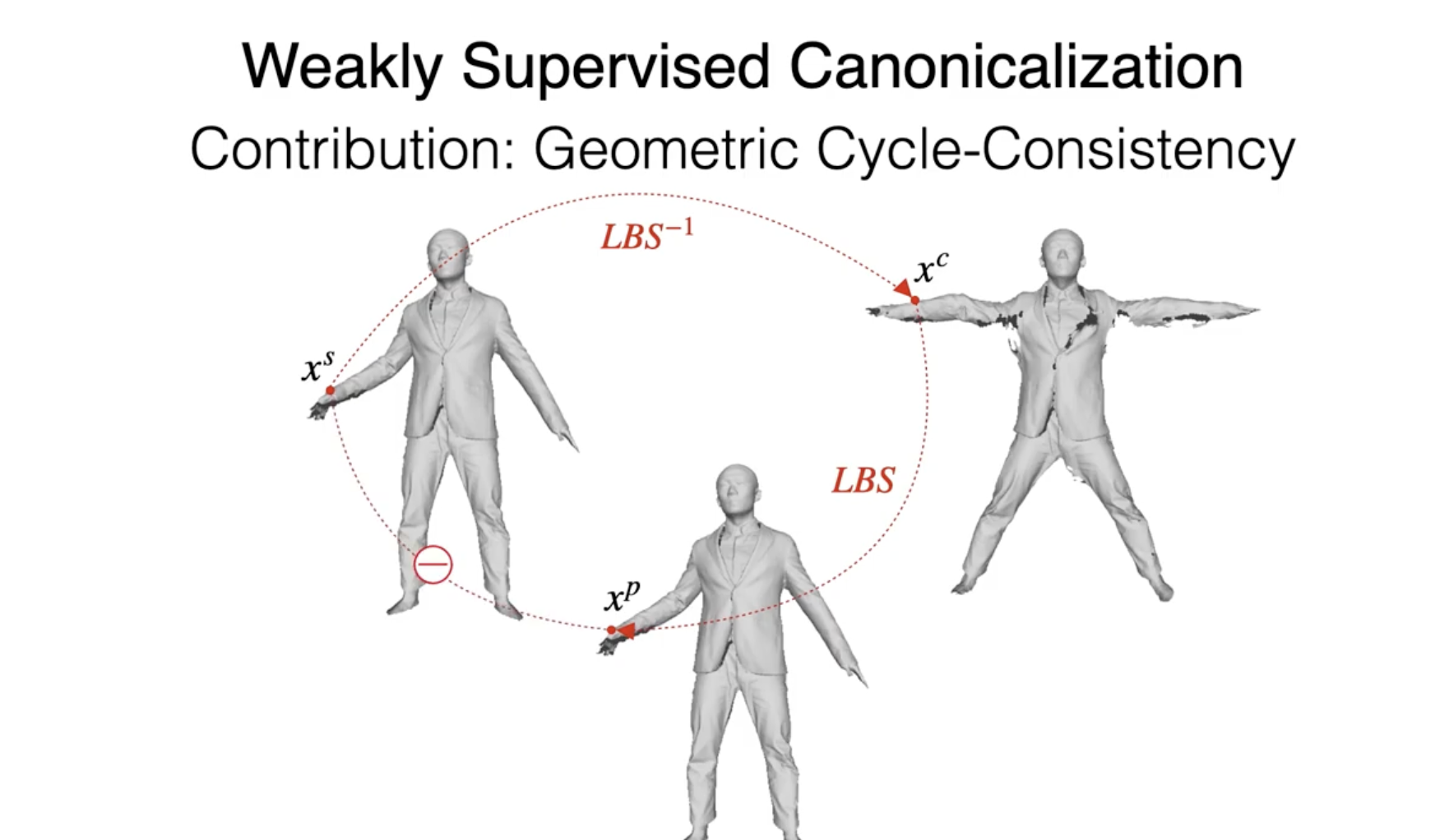
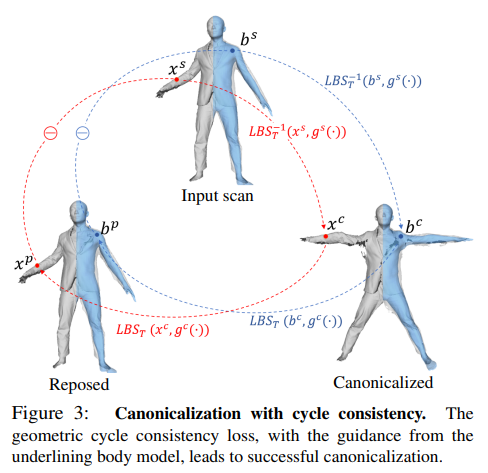
-> 스캔 데이터의 GT가 부족하므로 이를 해결하기 위해 cycle consistency 를 활용하여 연속적인 공간에서의 표면 함수를 학습하게 됨
-> 즉 포즈가 된 스캔(raw scan)에서 포즈 정규화를 시킨 후 이를 다시 원래 포즈로 변환시켜서 로스를 측정함
3.1. Canonicalization
표면에 있는 각 점에 대하여 각각 가중치를 할당하는 기존 방식에 비하여 본 논문에서는 countinuous 한 함수를 사용함으로써 가중치를 할당한다.
we train a model that takes any point in the space as input and outputs its skinning weight vector w.
본 논문에서는 표면 가중치를 계산하는것에 있어 공간상의 어떤 점을 인풋으로 받아 아웃풋으로 가중치 백터 W를 리턴하는 함수를 훈련시켰다.
We specifically focus on points from two surfaces, the clothing surface X and the body surface B.
특히 의류 표면의 점 X 와 신체 표면의 점 B를 구분하여 사용하였다.
공간을 정리하자면 posed space는 각각의 스캔으로 정의되고 canonical space는 모든 스캔들에 대하여 공유되는 공간임
: raw scan에서의 정점들
: 스캔의 프레임 인덱스
: 정규화된 포즈에서의 정점
하지만 아직 표준 공간의 좌표 를 알 수 없으므로 포즈된 스캔을 표준 포즈로 정렬시켜야 하는 매핑이 필요하다.
While the mapping function can be arbitrarily defined, we observe that this can be formulated as a composition of the known rigid transformations of body joints, , which come from the fitted SMPL model.
이러한 매핑 기능은 SMPL 모델에서 얻을 수 있는 신체 관절의 변환으로 공식화시킬수 있다.
J : 관절의 갯수 -> 즉 표면의 점이 영향을 받는 관절의 수
More specifically, given a set of blending weights w, we define linear blend skinning (LBS) and inverse linear blend skinning (LBS−1) functions as follows:
where are the vertices of the reposed scans and ideally should have the same value as .
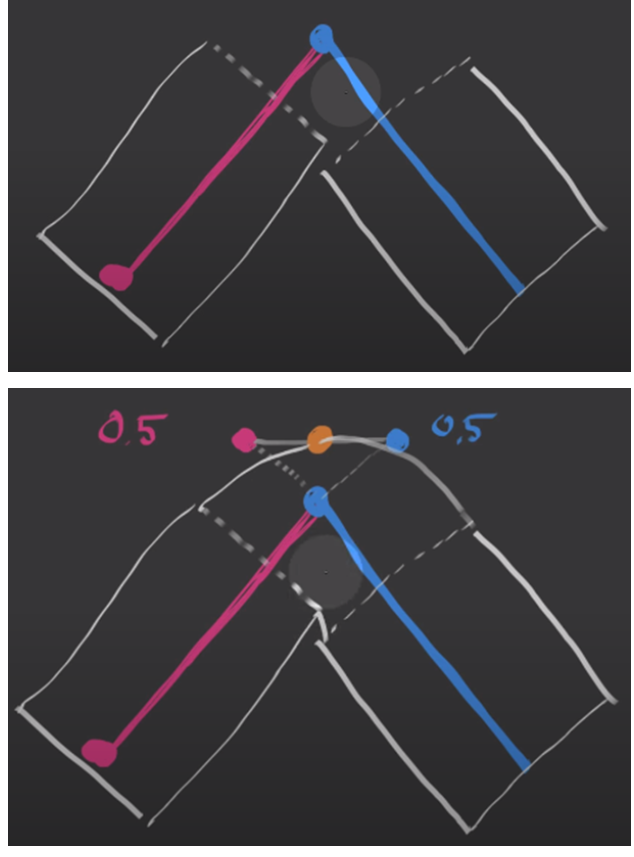
즉 LBS는 어떤 점 x가 어떤 장면 i 에서 j개의 관절에 대해 관절Tj이 가지고있는 가중치 wj의 영향을 받아 "구부러질때" 위치하게 되는 좌표 x'를 리턴하는 함수
-> 관절이 구부러질때 어떤 점이 그 관절의 구부러짐에 대해 얼마의 영향(가중치) 를 받아 새로운 위치로 이동하는 것
LBS와 LBS의 역함수를 다음과 같이 정의하는데 는 리포즈된 공간의 점이므로 raw scan 된 공간의 점인 와 동일한 값을 가져야 함
즉 raw scan 공간->표준화 공간->리포즈 공간
blending weight : SMPL 모델 피라미터

즉 LBS 함수는 표준 공간의 점을 로 표시된 표준화된 공간의 점으로 매핑하고
역 LBS 함수는 표준화된 공간의 점을 다시 포즈된 공간의 점으로 매핑함
Implicit Skinning Fields
(LBS는 포즈 변형을 표현하기 위해 정규화 된 상태에서의 점의 가중치)
Fortunately, we can learn them in a weakly supervised manner, such that all the scans can be decomposed into articulated deformations and non-rigid deformations.

원시 스캔 데이터에 대한 표면 가중치들은 알 수가 없음.
그래도 비지도 방식으로 표면 가중치들을 학습할 수 있음
-> 모든 스캔들을 관절 변형과 비강성(단단하지 않은) 변형으로 분해할 수 있도록?..
두가지 신경망 모델이 필요함
1. 순방향 표면 가중치 네트워크
2. 역방향 표면 가중치 네트워크
순방향 :
역방향 :
: 임베딩 공간
: MLP
순방향 네트워크는 표준화된 공간에서 LBS의 표면 가중치를 예측함
역방향 네트워크는 raw scan 공간에서 LBS의 표면 가중치를 예측함
Empirically we observe that jointly learning z s i in an auto-decoding fashion [53] leads to superior performance compared to taking pose parameters as input;
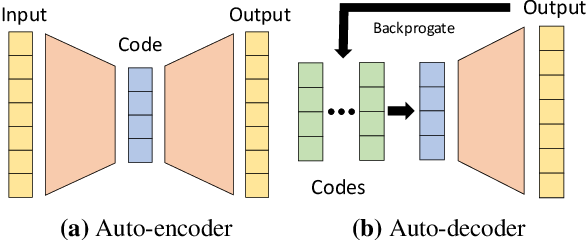
또한 포즈 파라미터를 직접 입력으로 설정하는것보다 오토디코더 형식으로 분포를 학습하면 더 좋은 결과를 얻어내는것을 확인하였음
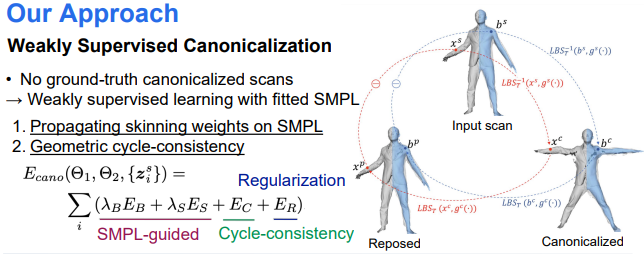
Learning Skinning
GT 없이 를 훈련시키기 위해 다음의 2가지 핵심 observations 을 사용함
(1) the regions close to the human body model are highly correlated with the nearest body parts where ground-truth skinning weights are available;
- (1) 인체의 body model(SMPL)과 가까운 raw scan 표면은 표면 가중치가 존재하는 SMPL의 가장 가까운 표면과 높은 상관관계가 있다.
(2) any points in the posed space should be mapped back to the same points after reapplying LBS to the canonicalized points.
- (2) 포즈된 공간에 있는 어느 점이던 교정된 공간에서의 점을 LBS를 재적용하면 다시 같은 점으로 맵핑되어야 함.
본 논문에서는 (1)을 활용하기 위해 SMPL의 LBS 표면 가중치를 포즈된 공간과 교정된 공간에서의 지침으로 사용하였음
More specifically, at points on the scans are loosely guided by the nearest neighbor point on the body model and its SMPL skinning weights, propagating skinning weights from body models to the input scans.
raw scan의 점에서 은 가장 가까운 부분에 있는 SMPL 모델의 표면의 점에 느슨하게 안내되어지고 그 점의 표면 가중치는 input scans으로 전파되어진다.
-> 옷을 입은 raw scan의 한 점은 SMPL 모델에서 가장 가까운 점의 표면 가중치를 전파받고 이를 통해 포즈된 공간을 교정된 공간으로 바꿀 수 있음
-> 그리고 교정된 공간을 "다시" 원래의 포즈대로 만들어버리는 LBS 를 통해 비지도학습을 달성함
Most importantly, observation (2) plays a central role in the success of the weakly supervised learning.
가장 중요한건 (2)가 비지도학습에 있어서 메인 역활을 한다는 것이다.
-> (1),(2)를 통해 주기적 일관성을 달성하고 를 학습시킨다.
Objective Function
: MLP
: 임베딩 스페이스
: SMPL 유도 loss
: SMPL 모델의 표면 가중치를 예측하는 네트워크의 로스
: 회귀 로스인데 어떤 점에 대해 예측한 표면 가중치와 해당 점에서 가장 가까운 점의 LBS의 결과로 나온 가중치와의 로스
: 주기 일관성 로스
: 정규화 항목이라는데 뭔지모르겠음
: 각각 표준화 공간과 스캔 공간에 있는 버택스들
: SMPL 모델의 LBS 가중치
-> 즉 g는 각각의 공간에서 가중치를 예측하는 네트워크이고 w는 SMPL의 가중치
이 외 추가적으로 을 사용해서 본 논문에서는 주기 일관성을 달성한다.
: 어떤 점에 대해 교정된 공간과 포즈된 공간 사이의 표면 가중치 로스
: 포즈된 공간 사이간의 점들에 대한 로스(LBS를 거쳐서 repose 된 공간과 raw scan 한 공간의 로스)
비지도학습이 끝난 후 스캔되어진 모든 버텍스에 역LBS 를 적용해 모든 스캔에 대해 정규화를 진행함
-> 스캔들을 전부 정규화시켜서 자세 변수 없에고 를 가진 (옷만 입은) 인간 3d 모델을 학습하기 위해 (옷을 학습하기 위해)사용함
3.2. Locally Pose-aware Implicit Shape Learning
표준화된 스캔이 주워졌을때 옷을 입은 3d 모델을 학습할 수 있음
we base our shape representation on an implicit surface representation [13, 47, 53] as it supports arbitrary topology with fine details.
우리는 다양한 표현의 옷을 표현하기 위한 shape representaion 방식으로 implicit surface 방식을 선택하였음
하지만 실제 스캔에 존재하는 구멍들 때문에 매시가 완전하지 않기 때문에 표면을 학습하기 위한 GT를 얻는게 어려움
To handle partial scans as input, we learn a signed distance function fΦ(x) based on a multilayer perceptron (for brevity, we omit the network parameters Φ), using implicit geometric regularization (IGR) [22] by minimizing the following objective function:
이를 해결하기 위해 다음과 같은 목적함수를 설계하였음
-> 논문에서는 implict geometric regularization 이라는 표현을 사용하였음 아마 빵꾸뚫린 메시를 어느정도 매꾸는 방식으로 처리하는 듯
Objective function
:
-level set-
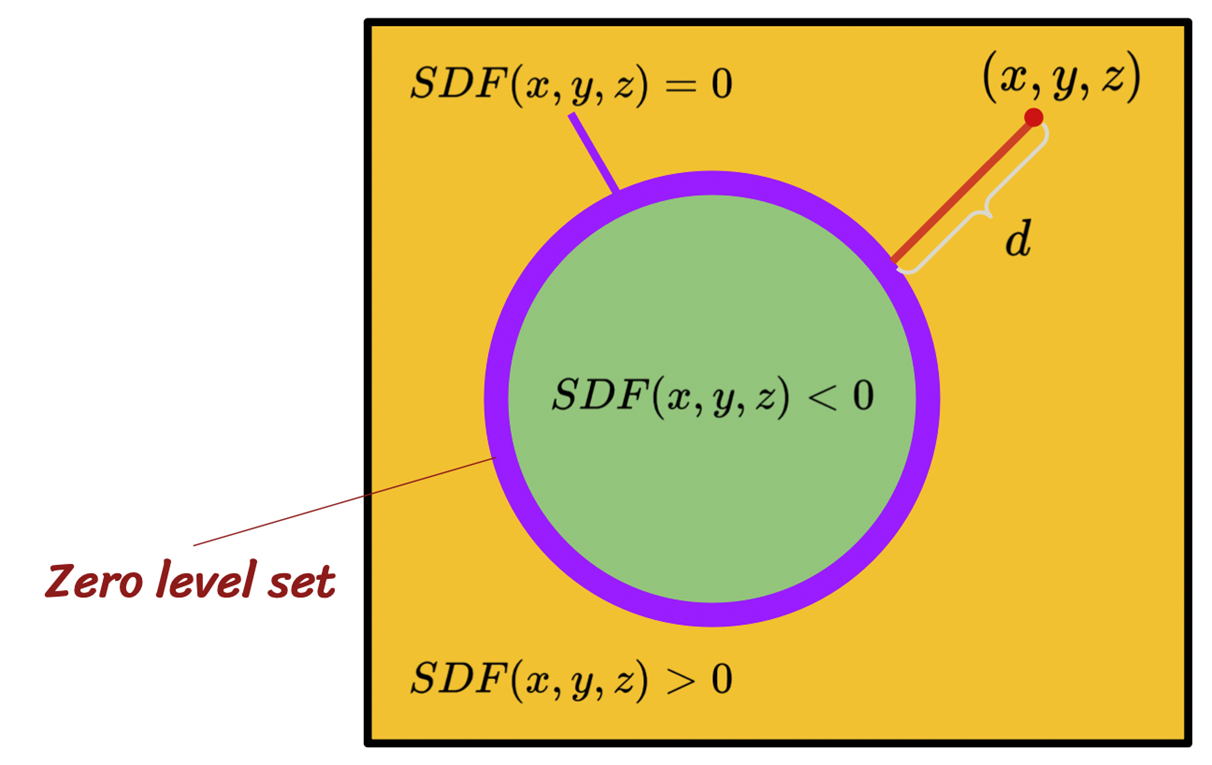
: 입력 스캔의 어떤 표면에 대해 그 표면의 법선과 정렬된 법선으로 예측된(스캔된 표면을 예측한 sdf 표면) sdf의 경계를 zero level 하는 로스
: the Eikonal regularization term 빛의 굴절률을 계산하는 함수
경계(bound)관련된 함수인듯 한데... 뭔지확실하게 모르겠음
: 표면이 아닌 SDF 가 zero level 에 근접하지 않도록 해주는 함수 (SIRENs)
Since the relationship between body joints and clothing deformation tends to be non-local [67], it is also important to limit the influence of irrelevant joints to reduce spurious correlations
몸의 관절과 옷의 변형은 비국소적(non-local) 경향을 가지기 때문에 옷의 변형에 영향을 끼치는 관절을(features) 구분(attention)하는것이 중요하다.
Examples of some SMPL limitations. Heat maps illustrate the magnitude of the pose-corrective offsets highlighting the spurious long-range correlations learned by the SMPL pose corrective blend shapes. Bending one elbow results in a visible bulge in the other elbow.
SMPL은 온 몸의 표면이 영향을 다 받는것에 비해, STAR은 관절 근처의 표면만 영향을 받는다.
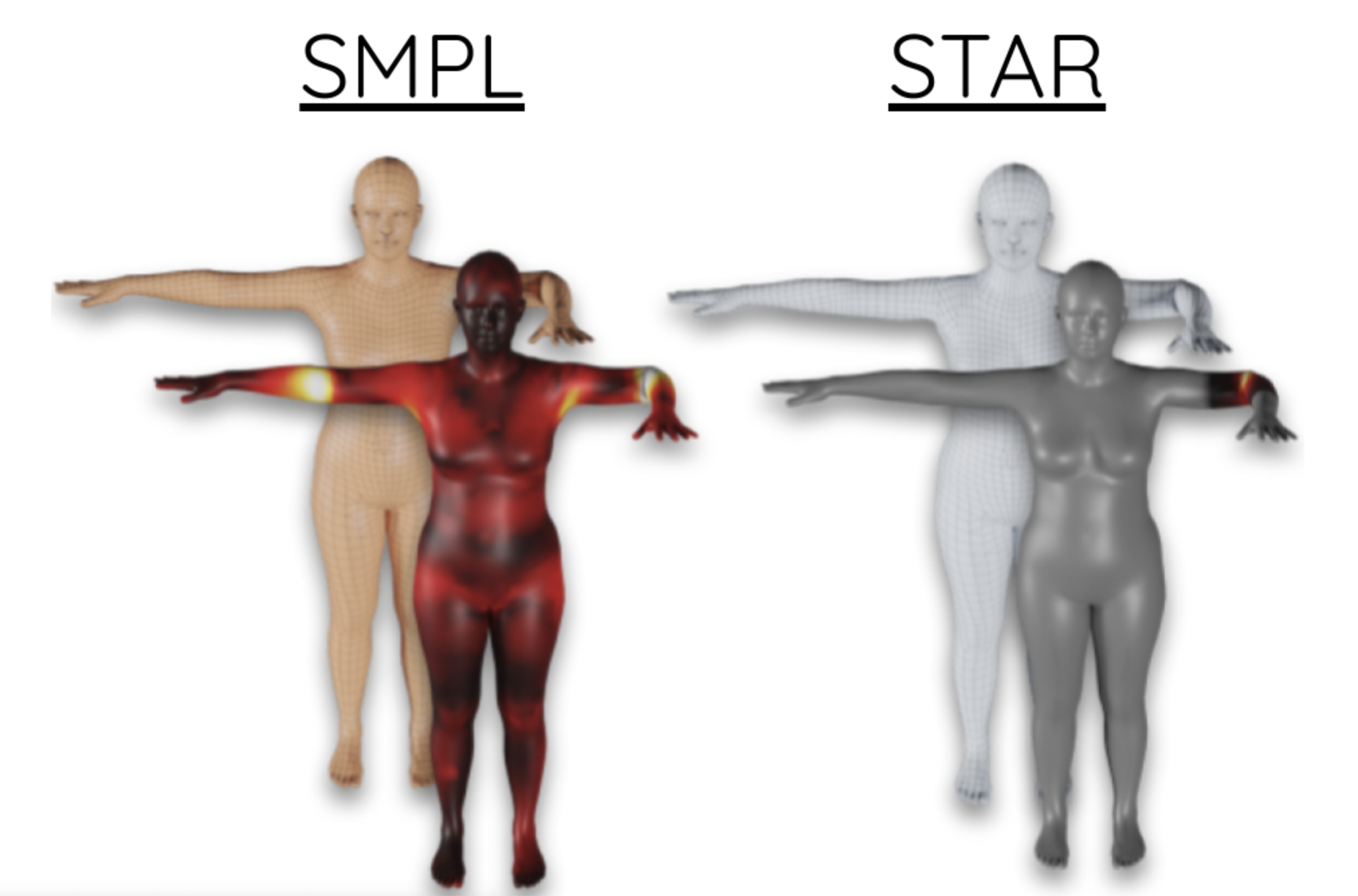
: 포즈에 대한 의류의 변형을 조건화하는 함수 f (STAR)
: 3.1절에서 학습한 스키닝 네트워크(LBS 표면 가중치를 예측함)
: 표면 가중치를 attention 가중치로 변환하는 가중치

: 같은 크기의 두 행렬의 각 성분을 곱하는 연산 Hadamard product
->어텐션 함수 f 는 n이라는 관절에 있는 옷의 점이 m이라는 관절에 영향을 받으면 가중치를 1로 설정함
The weight map is essential because the movement of one joint will be propagated to regions associated with neighboring body joints (e.g. raising the shoulders lifts up an entire T-shirt).
In this paper, we set Wn,m = 1 when n th joint is within 4-ring neighbors of mth joint in the kinematic tree.
4. Experimental Results
Dataset and metric.
나중에.
4.1. Evaluation
Canonicalization.
표준화의 목표는 효과적인 shape 학습을 위해 관절 변형을 관절과 관계없는 변형을 분리하는겄이다.
-> 즉 관절변형을 빼면 남은것은 옷을 입은 shape만 남으니까(옷)
한번 표준화를 했다가 다시 되돌림
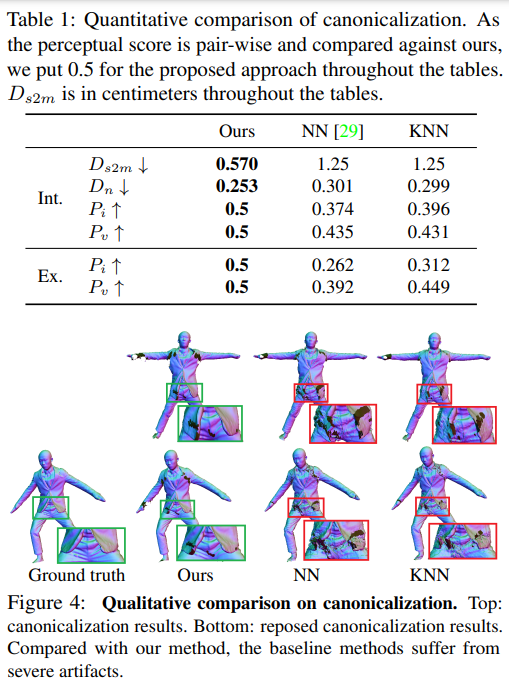
이를 비교하기 위해 두가지 방법을 이용했음
1) 가장 가까운 SMPL 모델의 표면 가중치를 옷의 표면 가중치에 복사하는 방법 : NN
2) k-nearest neighbors 방법을 사용해 주변의 가중치를 보간해서 사용하는 방법 : KNN
Locally Pose-aware Shape Learning.
포즈에 따라 달라지는 의류의 영향
train data set의 양에 따라서 대조
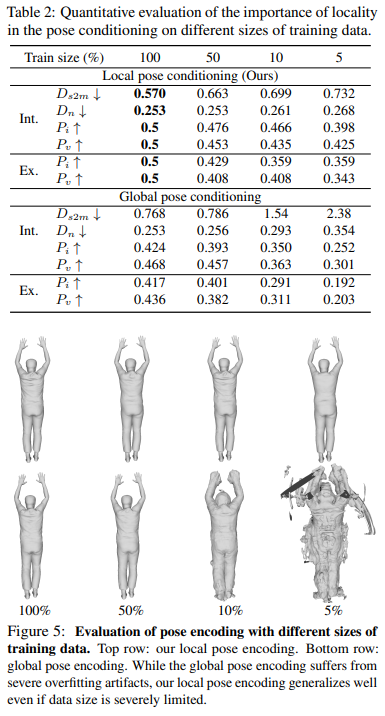
훈련 데이터가 줄어들면 글로벌 피쳐를 사용하는 경우(bottom row) 과적합문제가 발생함
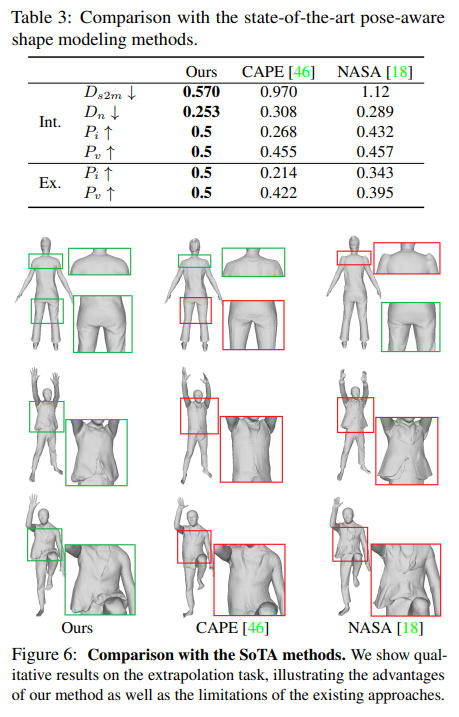
Comparison with SoTA.
소타와 비교 NASA, CAPE
5. Discussion and Future Work
나중에
