Abstract
헤드마운트 기기에 설치된 어안렌즈 카메라에서 촬영된 이미지로부터 3d body pose estimation을 가능하게 하는 프레임워크를 제안함

본 논문의 주요한 컨트리뷰션으로써
1.2d 이미지에서 추정하는 관절의 불확실성을 설명하기 위한 이중 디코더 구조 아키텍쳐

2.헤드마운트 기기에서 촬영된 여러가지 환경변수를 고려한 합성 데이터셋 XR-Egopose

가 있다.
또한 Human3.6M로 아키텍쳐를 평가하여 객관적인 평가를 진행하였음.
1. Introduction
xR(AR,VR,MR)기술은 여러 분야세서 다양한 응용이 이루어졌음.
이러한 기술들은 HMD를 사용하여 사용자를 렌더링한 가상 환경에 몰입시키는것에 집중함.
지금까지의 솔루션은 주로 영상이나 오디오에 집중되어 있음.
이를 해결하기 위해 컨트롤러 장치를 사용하여 위치를 추정하여 손을 렌더링하는 방식을 사용하였음.
신체의 나머지 부분을 추론하는 방법은 존재하지만(역운동학) 부정확함
본 논문에서는 HMD에 설치된 단안 카메라를 사용하여 전신의 3D 포즈를추정하는 프레임워크를 제안함.
또한 카메라는 머리에서 2cm정도(코에서 떨어질 정도의) 가까운 거리에 설치되어 있는 상황임
이러한 시점에 의해 하체의 대부분은 가려저 있음. + 어안렌즈를 사용하기 때문에 화면에 큰 왜곡이 존재하고 이에 거리에 따른 해상도에 차이가 발생함
이를 해결하고자 2d와 3d 어노테이션을 모두 가진 광범위한 데이터셋을 생성하였음
또한 관절의 불확실성한 위치를 올바르게 추정하는 프레임워크를 제안함
구체적으로
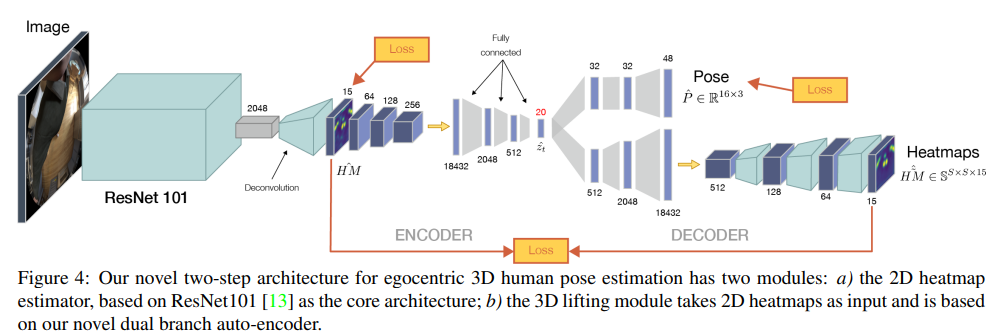
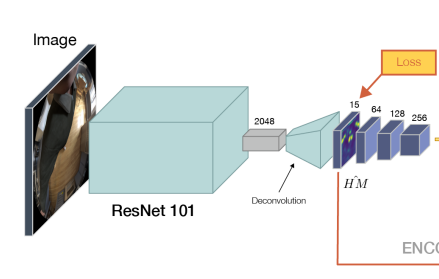
1.입력 이미지에서 직접 3d 포즈를 예측하는것이 아니라 일단 신체의 관절을 예측하는 2d 히트맵을 추출하는 모델을 훈련시키고,
2.이렇게 2d 히트맵을 출력한 다음 이를 다시 인코더->듀얼디코더 모델에 입력하여
하나의 디코더는 다시 2d 히트맵을 훈련시키는 쪽으로 AE를 훈련시키고 다른 디코더는 훈련된 레이턴트 백터롤 사용해 pose를 추정함

레이턴트 스페이스는 2d 추정의 불확실성을 줄이기 위해 사용됨
같은 이유로 오토인코더를 사용해 폐색된 신체 부위나 불확실성을 줄이고 정확한 관절을 추정하기에 도움이 됨
이 두 디코더는 분리가 가능하기 때문에 따로 훈련시킨 다음 마지막에 endtoend로 훈련시킴
학습은 실제 데이터와 합성 데이터를 사용하였고 합성 데이터는 공개하였음
컨트리뷰션 요약
1. 2d 히트맵을 다시 재구성하도록 훈련되는 디코더의 도입이 3d 포즈 추정에 많은 도움이 됨
2. 외부의 전면 카메라를 대체할 수 있는 표준이 될 수 있음
3. 대규모 훈련 데이터셋
2. Related Work
PASS
3. Challenges in Egocentric Pose Estimation
본 논문의 아키텍쳐는 극단적인 관점에서 발생하는 폐색과 이와같이 발생하는 상체와 하체의 관절 사이에서의 불확실성을 인코딩하도록 설계되었음
기존의 유일한 단안 데이터 셋(Mo2Cap2 : Real-time mobile 3d motion capture with a cap-mounted fisheye camera.)과 비교하여 더 좋은 photorealism 을 지니고 있고 데이터의 변동성 또한 더 높다.
정량적 평가를 위해 실제 VR 포즈 주석 역시 제공함
4. xR-EgoPose Synthetic Dataset
체형의 다향성을 고려 키의 분포를 155CM 에서 189CM 까지 설정하였음
피부의 톤은 백인부터 흑인까지 포함
무작위 셰이더를 적용하여 피부톤의 다양성 증가
운동복 바지, 청바지, 반바지, 드레스, 스커트, 재킷, 티셔츠, 긴소매, 탱크탑 등의 의류 다양성
샌들, 드레스슈즈, 애슬레틱, 크록스
1024X1024
8bit
30fps
메타데이터 제공,(3d 조인트, 키, 환경, 카메라 포즈, 바디 세그멘트 등)
maya 사용하여 렌더링
5. Architecture
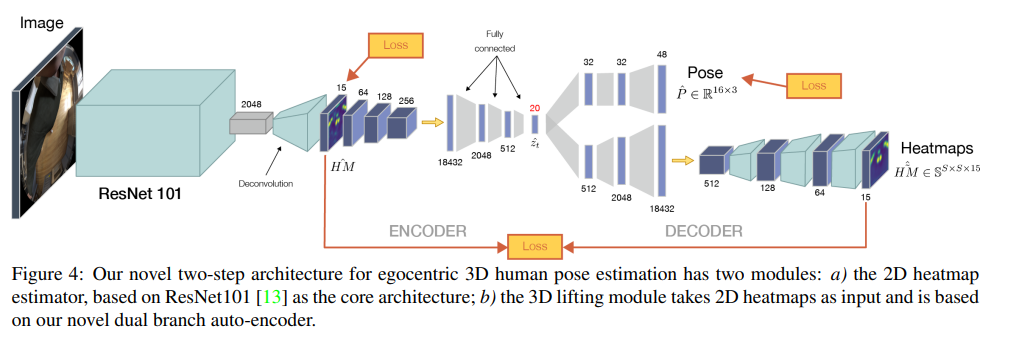
- resnet 아키텍처를 사용해서 2d히트맵을 회귀함
- 회귀한 2d 히트맵을 인코더의 입력으로 사용하여 이중분기 디코더에 입력으로 집어넣음
이때 분기된 디코더는 독립적으로 훈련이 가능하기 때문에
For instance, if a sufficiently large corpus of images with 3D annotations is unavailable, the 3D lifting module can be trained instead using 3D mocap data and projected heatmaps without the need of paired images.
-> 3d 데이터가 충분하지 않을 경우 렌더링한 히트맵으로 대신 훈련이 가능하다?..
아무튼 사용된 모듈들은 전부 미분가능하기 때문에 전체 아키텍쳐를 end to end로 훈련시킬 수 있음
+ 디코더중 2d 히트맵을 회귀하는 부분은 실제 테스트시에는 필요없기 때문에 테스트시에 더 좋은 퍼포먼스를 냄
5.1. 2D Pose Detection
368x368x3을 입력으로 하면 2d pose를 회귀하는 47x47x15 히트맵을 리턴함. (1차원당 하나의 관절을 회귀함)
이때 resnet 아키텍쳐를 사용함. 마지막 fc 레이어는 디컨볼루션 레이어로 교체됨
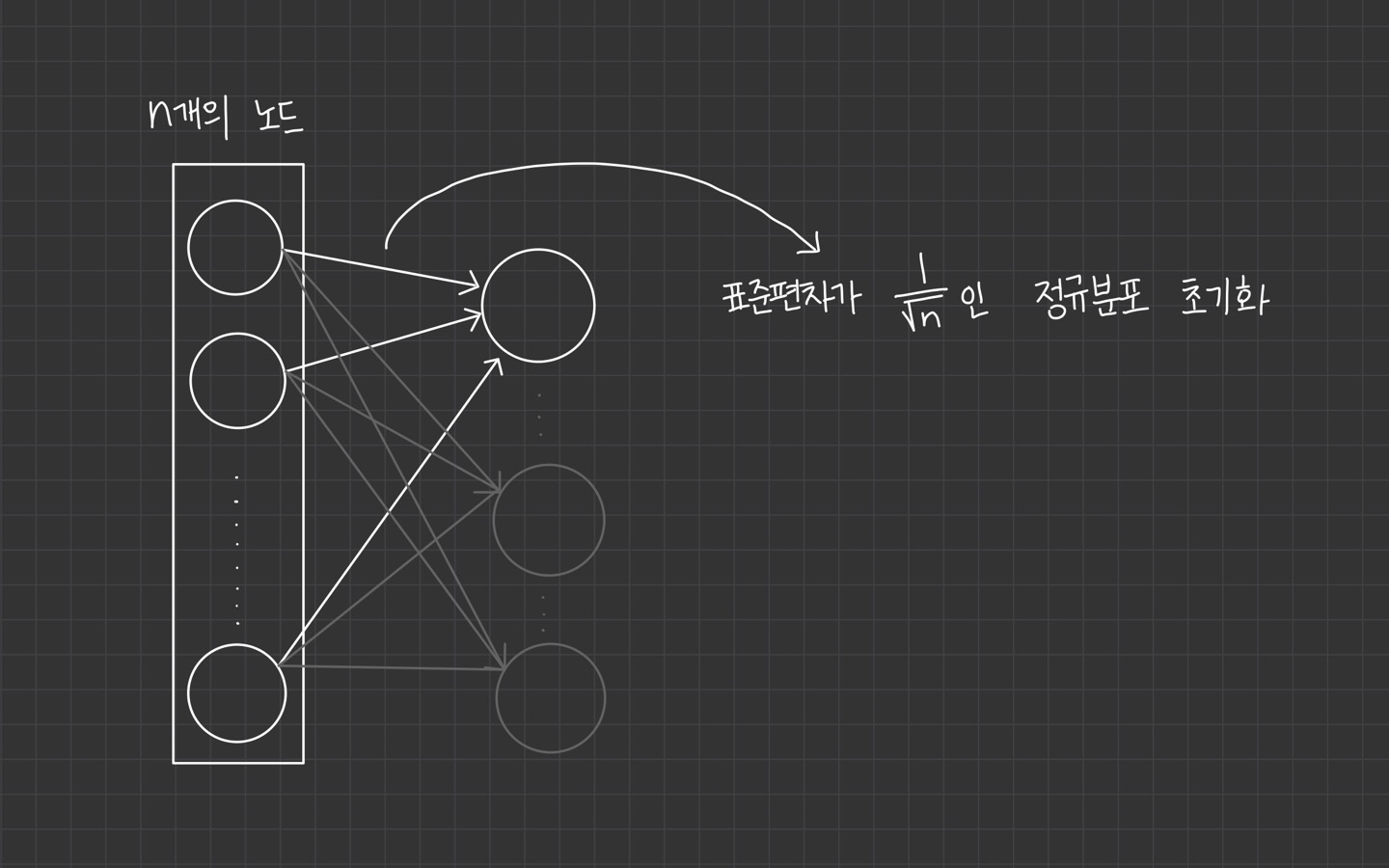
가중치는 Xavier initialization을 사용해 초기화 됨
너무 크지도 않고 작지도 않은 weight을 사용하여 gradient가 vanishing하거나 exploding하는 문제를 막습니다.
뉴런의 개수가 많을수록 초깃값으로 설정하는 weight이 더 좁게 퍼짐을 알 수 있습니다.
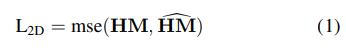
오브젝트 함수는 히트맵들간의 MSE를 사용하였음
5.2. 2D-to-3D Mapping
3d 포즈 모듈은 이전 과정에서 나온 2d 히트맵을 입력으로 받아서 16x3 짜리 3d pose 벡터를 회귀함
보통 접근 방식에서 the 3D lifting module은(2d에서 3d 관절을 회귀하는 모델) 보통 2d 조인트의 좌표를 입력으로 사용하는데
[33]
The main advantage is that these carry important information about the uncertainty of the 2D pose estimates.
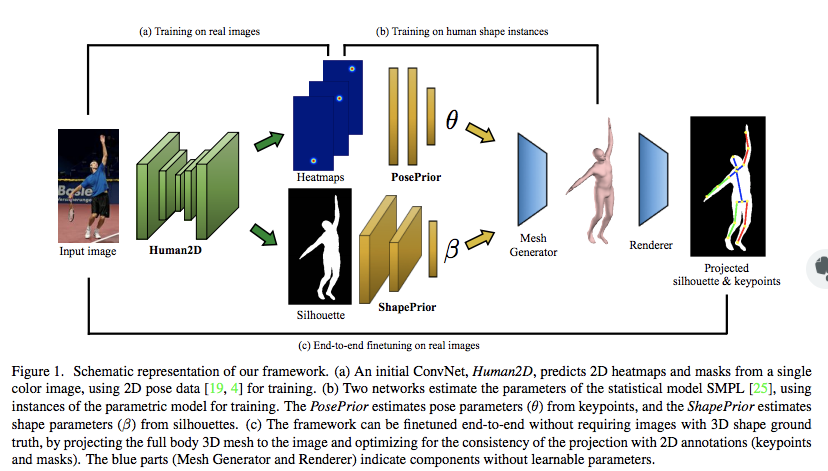
우리 아키텍쳐는 히트맵을 입력으로 사용함
히트맵의 장점으로써 히트맵은 2d 포즈 추정의 불확실성에 대한 정보를 포함한다는 것이다(?)

아키텍처의 노벨리티는 이러한 2d 포즈 추정에서의 불확실성에 대한 정보가 손실되지 않는다는 것이다.
-> 왜 히트맵은 불확실성한 정보가 손실되지 않고 좌표는 불확실성에 대한 정보가 손실되는지 모르겠음
디코더는 두가지 분기를 가지고 있는데 하나는 레이턴트 스페이스에서 3d 포즈를 회귀하는것이고 하나는 입력 히트맵을 다시 회귀하는것
히트맵을 회귀하는 이유는 히트맵의 분포를 인코더가 학습하게 하도록 하기 위함이다.(AE 학습을위해)
오토인코더의 오프젝트 함수는 다음과 같음
HM~은 근사한 히트맵, HM^은 resnet 인코딩한 히트맵
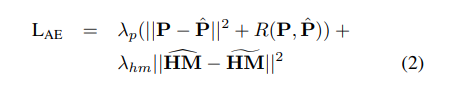
R 은 3d 포즈에 대한 loss


코사인 유사도 에러 + 관절길이 에러를 사용함( 관절길이랑 관절의 각도를 로스로 사용)
이 로스를 사용함으로서 2d 데이터와 3d 데이터를 같이 옵티마이징 할 수 있음
5.3. Training Details
The model has been trained on the entire training set for 3 epochs, with a learning rate of 1e − 3 using batch normalization on a mini-batch of size 16. The deconvolutional layer used to identify the heatmaps from the features computed by ResNet has kernel size = 3 and stride = 2. The convolutional and deconvolutional layers of the encoder have kernel size = 4 and stride = 2. Finally, all the layers of the encoder use leakly ReLU as activation function with 0.2 leakiness. The λ weights used in the loss function were identified through grid search and set to λhm = 10−3 , λp = 10−1 , λθ = −10−2 and λL = 0.5 . The model has been trained from scratch with Xavier weight initializer.
PASS
6. Quantitative Evaluation
다양한 ego pose 데이터 셋에 대해 정량적인 평가를 진행 하였음
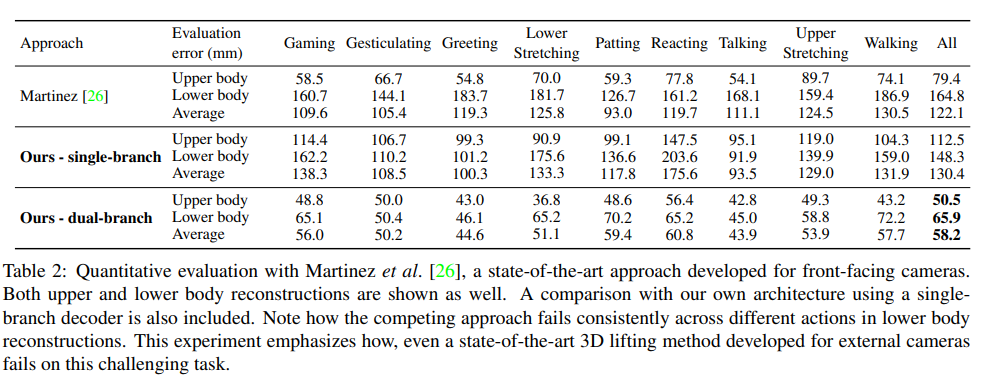


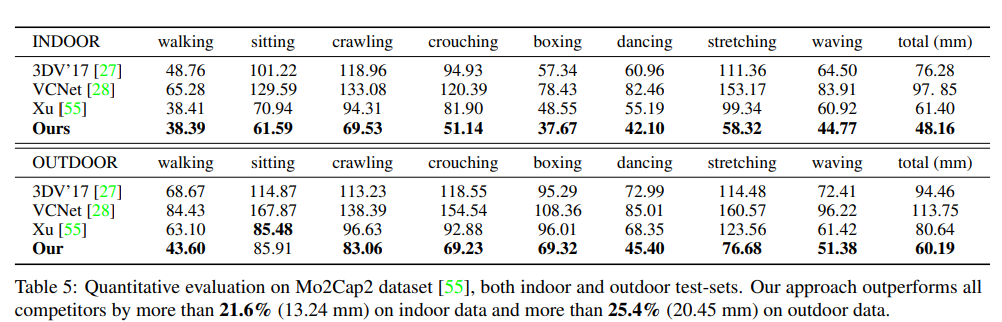
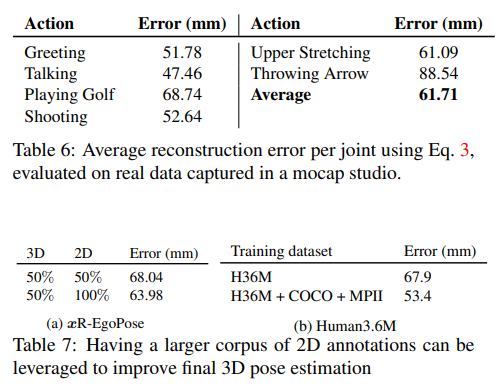
- xr egopose 데이터셋
- real 데이터셋
- mo2cap2 데이터셋
- human3.6m 데이터셋
관절간의 포지션 에러를 사용하여 평가를 진행함 (MPJPE)

