SMPL-X : Expressive Body Capture: 3D Hands, Face, and Body from a Single Image
Abstract
To facilitate the analysis of human actions, interactions and emotions, we compute a 3D model of human body pose, hand pose, and facial expression from a single monocular image.
To achieve this, we use thousands of 3D scans to train a new, unified, 3D model of the human body, SMPL-X, that extends SMPL with fully articulated hands and an expressive face.
single 이미지에서 인체의 자세나 손, 얼굴 표현 3d 모델을 인식하는 프레임워크
이를 달성하기 위해 SMPL을 확장하는 SMPL-X를 제안하였음
Learning to regress the parameters of SMPL-X directly from images is challenging without paired images and 3D ground truth.
SMPL-X 의 파라미터들을 바로 학습하는건 3d gt가 없으면 어려움
Consequently, we follow the approach of SMPLify, which estimates 2D features and then optimizes model parameters to fit the features. We improve on SMPLify in several significant ways:
그래서 SMPLify의 접근방식을 사용함 -> 2d 피쳐를 사용해 파라미터를 뽑음
그리고 SMPLify을 다음과 같은 방법으로 개선함
(1) we detect 2D features corresponding to the face, hands, and feet and fit the full SMPL-X model to these;
(2) we train a new neural network pose prior using a large MoCap dataset;
(3) we define a new interpenetration penalty that is both fast and accurate; (4) we automatically detect gender and the appropriate body models (male, female, or neutral);
(5) our PyTorch implementation achieves a speedup of more than 8× over Chumpy.
1 : 얼굴 손 발에 대한 2d 피쳐를 추출하고 여기에 전체적인 SMPL-X 모델을 맞춤
2 : MoCap 데이터셋을 사용해서 pose를 추정하는 새로운 NN을 학습시켰음
3 : 새로운 object function을 정의하였음
4 : 적절한 신체 모델을 자동으로 감지함(남성,여성,중성)
5 : 파이토치를 사용해 구현하여 빠름
We use the new method, SMPLify-X, to fit SMPL-X to both controlled images and images in the wild.
SMPLify-X라는 방법을 사용해서 입력된 이미지에 SMPL-X모델을 fit 시킴
We evaluate 3D accuracy on a new curated dataset comprising 100 images with pseudo ground-truth. This is a step towards automatic expressive human capture
from monocular RGB data. The models, code, and data are available for research purposes at https://smpl-x.is.tue.mpg.de.
100개의 이미지로 된 데이터셋에서 정확도 평가를 진행함
1. Introduction
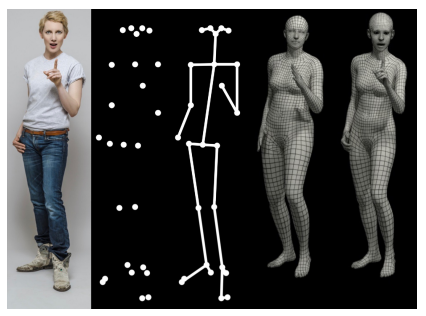
왼쪽부터 인풋 이미지, 주요 관절 예측, 골격 예측, SMPL 모델, SMPL-x 모델
SMPL-X 가 더 표현력이 풍부한 캡쳐를 가능하게 함
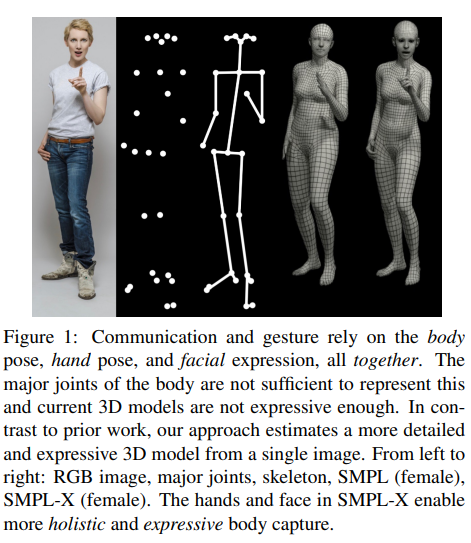
Recent methods have shown rapid progress on estimating the major body joints, hand joints and facial features in 2D [15, 31, 69].
2d 에서 신체의 주요한 관절이나 얼굴 피쳐를 뽑아내는것은 많은 진전을 보였음
->그래도 3D를 뽑아내는게 중요함
따라서 최근 연구들의 동향을 살펴보면 단일 이미지에서 직접 주요한 관절과 러프한 3d 추정이 이루어지는것을 확인 할 수 있었음
그러나 디테일한 정보가 부족하고 이에 몸이나 손 얼굴 전체의 3d 표면이 필요함
하지만 아직 데이터의 부족으로 인해 이러한 task를 수행하는 프레임워크가 존재하지 않음
따라서 이를 해결하기 위해
1 : 복잡한 사람의 얼굴, 손, 몸의 포즈를 표현할 수 있는 3d body 모델이 필요함
2 : 이러한 모델을 이미지에서 뽑아낼 수 있는 방법이 필요함
신경망 네트워크와 빅데이터의 조합으로 2d 이미지에서 사람의 포즈를 추정하는 기술은 많은 발전을 이루었음
포즈 : 란 주로 몸의 주요한 관절을 의미하지만 이것만 가지고는 사람의 행동을 충분하게 표현할 수 없음
또한 손과 얼굴을 3d 로 모델링하는것은 많은 연구가 진행되고 있지만 이를 신체에 통합하는 연구는 진행되고 있지 않거나 이제 막 연구가 시작되는 중(Frank model : SMPL + hand rig + face) 하지만 현실적이지 않음(따로따로 연결되기 때문에)
Here we learn a new, holistic, body model with face and hands from a large corpus of 3D scans.
따라서 우리는 대규모 3d scan 데이터로부터 얼굴과 손을 포함한 전체적인 신체 모델을 학습하였음
SMPL-X 는 SMPL을 기반으로 하여 그래픽 소프트웨어와의 호환성, 매개변수화, 효율성 등 기존 SMPL 모델의 장점을 이어받음
We combine SMPL with the FLAME head model [43] and the MANO hand model [67] and then register this combined model to 5586 3D scans that we curate for quality.
SMPL-X는 SMPL모델에 얼굴 모델인 FLAME 그리고 손 모델은 MANO 을 결합한 다음 이를 통합하기 위해 5천장의 3d 스캔을 준비하였음
이러한 대량의 데이터로부터 모델은 신체와 얼굴 그리고 손의 자연스러운 상관관계를 학습할 수 있게 됨
기존의 몇몇 방법들은 단일 이미지에서 SMPL의 매개변수를 예측할 수 있도록 하였지만
손과 얼굴을 통해 3d body를 예측하기 위한 적절한 데이터셋이 존재하지 않음
이를 해결하기 위해 SMPLify 의 접근방식을 사용함
1 : openpose를 사용하여 신체의 관절이나 얼굴, 손 발등의 피쳐를 찾음(2D 에서)
2 : SMPLify-X라는 방법을 사용해 추출한 피쳐들을 사용해 SMPL-X 모델을 fit 시킴
이를 위해 기존의 SMPLify 에 몇가지 개선사항을 적용하였음
VAE 를 사용해 더 다양한 포즈를 학습하게 함
-> 2d 피쳐에서 3d 포즈로의 매핑을 위해 VAE를 사용함
또한 SMPLify 이 사용하던 object 함수보다 더 정확한 object 함수를 사용함
또한 성별 탐지기를 학습하여 어느 신체 모델을 사용할지 결정하게 함
기존의 SMPL 매개변수를 측정하는 SMPLify 의 느린 속도를 개선하기 위해 GPU를 사용할 수 있는 pytorch를 사용함
이러한 SMPLify-X를 평가하기 위한 데이터도 우리가 만들었음
-> 다양한 포즈나 제스쳐를 사용한 평가 자세 데이터셋 만들었음 우리가.
이렇게 만든 데이터셋은 신체와 얼굴 손까지 정량평가 할 만큼 정확함 ㅎㅎ
우리는 이 작업의 의의가 단일 이미지에서 신체 손 얼굴을 같이 표현하는데 중요한 단계라고 생각함 ㅇㅇ
https://smpl-x.is.tue.mpg.de. 에서 확인 ㄱ

2. Related work
2.1. Modeling the body
Bodies, Faces and Hands.
기존에 있던 3d 몸체를 모델링하는 과정에서 생기는 문제들을 해결하는 방식은 몸을 별도로 모델링하는것이었음
하지만 대부분의 접근법은 머리 전체가 아니라 얼굴 영역에만 초점을 맞춤
이와 다르게 FLAME 은 머리 전체를 모델링함 + 머리의 회전 + 목 까지 모델링함
논문의 저자들은 몸과 머리를 연결시키는것에 있어서 이를 중요하게 생각함
또한 초기 연구들은 손이나 얼굴을 생각하지 않고 체형이나 포즈를 모델링하는것에 초점을 맞추고 있음
손 모델링 접근법 역시 신체를 생각하지 않음
-> 기본적인 템플릿을 사용하던가 수작업으로 생성되던가 함
논문에서 사용하기에 적절한 모델은 MANO 라는 모델로써 3D 스캔을 통해 넓은 표현이 가능한 포즈 공간과 풍부한 모양을 갖춘 매개변수가 가능한 모델임
본 논문과 비슷한 접근방법을 가진 프레임워크로서 SMPL+H 가 있지만 이는 손의 변형을 제대로 표현하지 못하므로 어색함
따라서 우리는 SMPL + FLAME + MANO 를 사용해 자연스러운 모양 변형,포즈 의존 변형을 데이터셋을 통해 학습함
-> 또한 SMPL을 베이스로 사용하므로 기존에 SMPL을 사용하였던 어플리케이션에서 쉽게 적용할 수 있음
2.2. Inferring the body
이미지나 RGB-D이미지로부터 얼굴이나 손을 추정하는 방법은 많이 존재함
또한 이미지에서 3d 관절을 추정하는 방법은 이미 많음
따라서 이 논문에선 전체적인 3d body의 메쉬를 추출하는 방법에 중점을 둠
이미지에서 SMPL 모델을 예측하는 몇가지 방법이 있지만 정확하지 않음
SMPLify라는 방법은 2d 이미지의 피쳐를 하향식으로 탐지하고 이러한 피쳐에 대해 SMPL 모델을 상향식으로 맞추는 방법을 사용하였음
-> 나중에 데이터셋을 만드는데 이 알고리즘을 사용함
There are also many multi-camera setups for capturing 3D pose, 3D meshes (performance capture), or parametric 3D models [7, 20, 24, 30, 35, 46, 53, 65, 71]. Most relevant is the Panoptic studio [35] which shares our goal of capturing rich, expressive, human interactions. In [36], the Frank model parameters are estimated from multi-camera data by fitting the model to 3D keypoints and 3D point clouds. The capture environment is complex, using 140 VGA cameras for the body, 480 VGA cameras for the feet, and 31 HD cameras for the face and hand keypoints. We aim for a similar level of expressive detail but from a single RGB image.
뭐 암튼 지들이 만든게 좋다고 함
3. Technical approach
In the following we describe SMPL-X (Section 3.1),
and our approach (Section 3.2) for fitting SMPL-X to single
RGB images. Compared to SMPLify [10], SMPLify-X uses a better pose prior (Section 3.3), a more detailed collision penalty (Section 3.4), gender detection (Section 3.5), and a faster PyTorch implementation (Section 3.6).
3.1 : SMPL-X 모델에 대해 설명
3.2 : 이미지에서 SMPL-X 을 fit하는 과정 설명
3.3 : 포즈를 추정하는 SMPLify-X 설명
3.4 : object function
3.5 : 성별감지기
3.6 : pytorch
3.1. Unified model: SMPL-X
SMPL-X는 vertex-based linear blend skinning을 사용한 모델로, 10475개의 vertice(3D point)와 54개의 관절들로 구성되어 있다. 간단하게 사람의 mesh를 모델링하는 방법으로 이해했다.
SMPL-X는 위에서 설명했듯이 파라미터를 이용하여 human avatar를 모델링했는데, 이에 대해선 다음과 같이 나타낸다.
T : temp mesh
-> 즉 M이라는 함수는 포즈,body,facial에 대한 파라미터를 입력받아 SMPL-X를 변형하는 함수
->저런 파라미터들을 받아서 SMPL-X라는 메시를 변형시킴 ㅇㅋ?
학습을 통해서 얻어진 기본적인 template mesh를 기반으로, 이 3개의 파라미터들을 조절함으로써 avatar의 pose를 바꾸거나 체형을 조절할 수 있다.
: pose에 관한 파라미터로, 좀 더 자세하게는 jaw joint, finger joint, body joint로 구성된다.
: body shape에 관한 파라미터
: facial expression에 관한 파라미터다. 여기서 구체적으로는, linear blend skinning function W 안에 있는 blend weight도 들어간다.
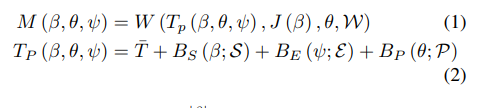

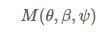
Bp : 포즈백터 세타를 모델과 맵핑하는 함수인듯. Rodrigues formula 사용
Bs : the shape blend shape function,
Be : the expression blend shape function
블랜드쉐잎에 shape 함수랑 expression 함수가 따로 있나봐요
아마 shape 는 몸쪽인거같고 expression 은 얼굴쪽인듯 맞네 가 얼굴인데
는 몸임



아무튼 파라미터는 총 119개로, 75개는 global body rotation과 body, eyes, jaw에 관한 것이고, 24개는 손, 10개는 shape에 관한 것이고, 나머지 10개는 facial expression에 관한 것이다. 이걸 기본 템플릿인 T 에 더해서 사용
3.2. SMPLify-X: SMPL-X from a single image
SMPL-X 를 이미지에 있는 사람에 맞추기 위해 SMPLify를 적용했지만 잘 맞지 않아서 우리만의 오브젝트 함수를 만들었습니다.
object function
: full pose 벡터
: body pose 백터 -> 32차원 포즈 공간
: face pose 백터
: 손에 대한 파라미터
Emh,E세타f,E베타,E엡실론 : 각각 손, 얼굴포즈, 몸, 얼굴표현 정규화 공간을 만들기 위한 정규화 텀
E 베타 : shape 파라미터와 트레이닝 데이터셋의 shape 분포의 거리 Mahalanobis distance로 잼
E 알파 : 과도한 관절 접힘을 방지
E 세타b : VAE 기반 포즈 정규화 텀
Ec : mesh 겹침 패털티 (interpenetration penalty)
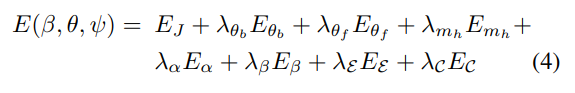

는 데이터 정규화 텀(투영 loss)
재투영 로스 : 이미지에서 측정한 2d 관절 Jest랑 만들어진 3d 에서 관절을 투영해서 나온 관절이랑 비교하는 텀인듯
R : 포즈벡터 세타에 따라 관절을 변형해주는 함수
는 사영함수 인데 카메라 파라미터 k 에 따라서 사영시킴
2d 관절 측정은 openpose를 사용하였ㅇ므
탐지에 의해 생기는 노이즈들에 대응하기 위해 가중치를 추가하였음
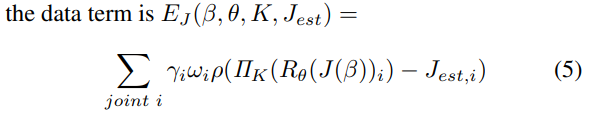

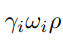
3.3. Variational Human Body Pose Prior
SMPLify는 불가능한 포즈를 막기 위해 MoCap data 를 사용해서 가우시안 분포를 학습하였음
-> 모델이 표현 가능한 포즈공간을 학습하였다고 생각하면 됨
근데 잘 안되서 우리껄로 바꿈 ㅎ;
이 논문에서는 Variational Encoder를 사용한 VPoser라는 모델을 학습시켰다. 이 모델은 사람 pose에 대한 latent representation을 학습하고, latent code의 distribution을 normal distribution으로 regularize 하는 모델이다. (설명이 어려워 보이지만, VAE가 하는 일을 서술한 것뿐이다. 적용 대상이 사람 pose가 됐을 뿐!)
pose prior에 대해서 서술하는데, 2D 에서 3D로 mapping 하는 것은 ambiguous 하기 때문에, 중요한 term이라고 한다.
아무튼 그래서 R 은 각각의 관절 3x3 회전행렬인데 인풋으로 들어감
R햇 : 입력과 동일한 차원의 아웃풋
위에서부터 각각
7 : KL loss,
8 : VAE 정규화 텀(리컨스트럭션 로스),
9,10 : 회전행렬 로스,
11 : 과적합방지항

이 VPoser이라는 VAE 모델을 사용하니까 세타b 를 직접적으로 사용하는것보다 더 좋은 성능을 보여주었음
3.4. Collision penalizer
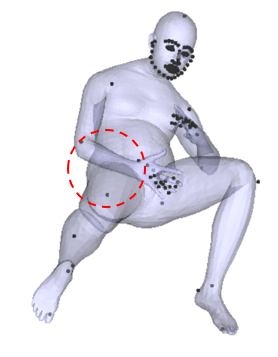
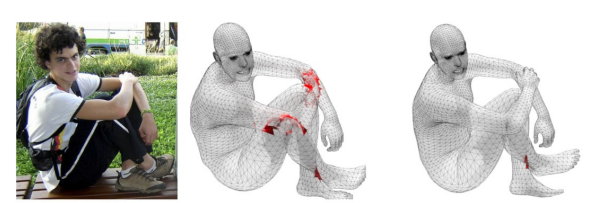
최적화를 하다보면 body part들끼리 겹치는 문제점들이 생긴다. 실제로는 사람 신체들이 겹치는 것이 불가능하므로, 이에 대한 penalty를 주기 위한 loss term이다. avatar는 vertex로 이루어져 있고 vertex 3개로 triangle을 만든다. 이때 서로 겹치는 triangle을 찾고, (Bounding Volume Hierarchies를 이용했다고는 함) 이들의 거리가 멀어질 수 있도록 최적화를 한다.
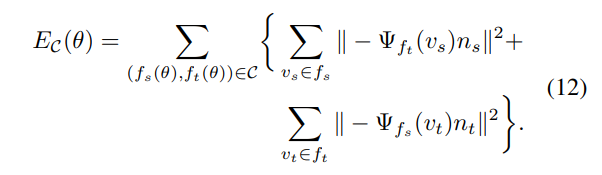
패널티 텀에 의하면 충돌이 깊을수록 많은 패널티를 얻어감
충돌이 일어난 삼각형 fs,ft는 양방향임 따라서 충돌삼각형을 이루는 버텍스들끼리의 거리를 측정하여 loss로 사용함
즉 BVH로 충돌이 일어난 메시를 찾고 이를 패널티 텀 Ec 로 계산하여 loss로 사용하였음
3.5. Deep Gender Classifier
Openpose의 관절 정보를 기반으로 성별 분류기를 훈련함
분류기를 학습시키기위해 LSP,LSP+,MPII,MS-COCO,LIPdataset 등의 대규모 데이터셋을 사용하였음
->resnet 파인튜닝함
분류할 수 없을경우 중립 신체 모델을 적용함
3.6. Optimization
optimization function

optimization function을 multi-stage로 최적화한다. 최적화는 pytorch optimizer를 이용해서 진행했다.
먼저 unknown camera translation과 global body orientation을 맞춘다. Template avatar의 위치와 기울어진 정도를 조절해서, projected된 3D joint들에 더 잘 맞게 하는 과정이다. 이후에 이 두 가지를 고정시키고, body shape과 pose에 관한 파라미터를 최적화한다. face와 hand의 경우 part 자체는 작으나 joint수가 많아서, 전체적인 pose를 잡는 동안에는 가중치를 둬서 그 영향을 더 작게 했다. 각 term들마다 pose에 주는 영향이 다를 텐데 이들을 조절하는 가중치가 optimization function 앞에 있는

이다.
4. Experiments
4.1. Evaluation datasets
기존의 데이터셋중에 몸, 손, 얼굴이 같이 있는 데이터셋이 없음
그래서 우리가 만들었음
Expressive hands and faces dataset (EHF)
SMPL+H 데이터셋에 전체적인 몸 이미지를 추가하였음 그다음 SMPL-X를 4d 스캔을 통해 정렬했음.
전문적인 어노테이터가 수동으로 GT를 만들었음
이 GT는 vertex to vertex error를 측정할 수 있음
표면 에러와 뼈의 회전은 생각하지 않음
4.2. Qualitative & Quantitative evaluations
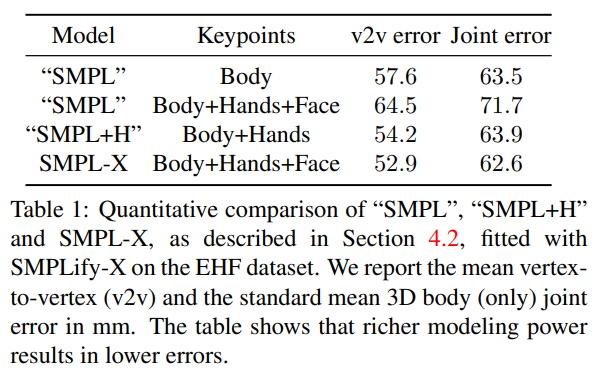
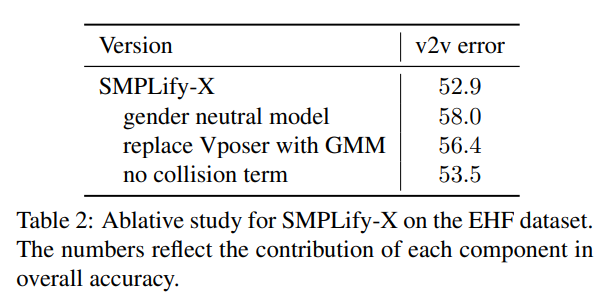

5. Conclusion
얼굴, 손, 몸이 같이 있는 모델인 SMPL-X를 제안하였음 또한 SMPL-X모델을 이미지에서 추출한 피쳐를 통해 fit 시킬 수 있는 프레임워크인 SMPLify-X 역시 같이 선보였음
