이번 포스트에서는 Random Forest에 대해서 다룹니다.
Background
Decision Tree는 오버 피팅에 대한 문제가 있다. Pruning을 통해 어느 정도 오버 피팅을 방지하려고 하지만 드라마틱 하게 해결이 되진 않는다. Random Forest는 Decision Tree의 오버 피팅 문제를 해결하기 위해 고안된 Machine Learning 기법으로, 여러 개의 Decision Tree를 이용하여 사용하기 때문에 숲을 이룬다는 뜻의 Forest라는 이름이 붙었다.
Random Forest
Random Forest는 Ensemble 방법을 기반으로 한다.
Ensemble
Ensemble이란 여러 개의 모델을 조화하여 학습 및 결과 예측을 하는 것을 말한다.
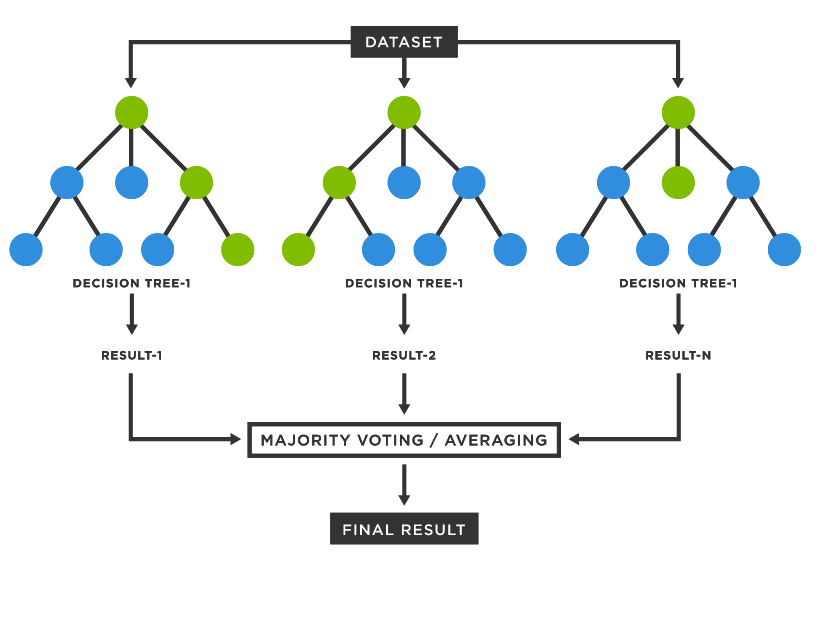
위의 그림처럼 여러 개의 Decison Tree의 결과를 조화하여 최종 결과를 도출한다. (여러 사람의 의견을 종합한다고 생각하면 이해하기 쉬울 것이다.) 하나의 Decision Tree는 오버 피팅 될 수 있지만 여러 개의 Decision Tree의 모든 결과를 조화하기 때문에 일반화 성능이 향상되어 오버 피팅이 저하된다.(1명의 의견을 수용하는 것 보다 1000명의 의견을 수용한다고 이해해보자.)
Bagging
Bagging이란 학습 Dataset의 수를 모델 수만큼 나눈 뒤 각각 학습 시키는 것을 의미한다. 예를 들어 1000개의 Dataset이 있고, 10개의 모델로 Ensemble Learning을 한다고 가정하면 총 10개의 모델이 각 100개의 Sub-dataset에 대해서 학습을 한다. 그 후 Test Dataset에 대해 10개의 모델의 예측의 평균 등을 사용하여 최종 결과를 도출한다.
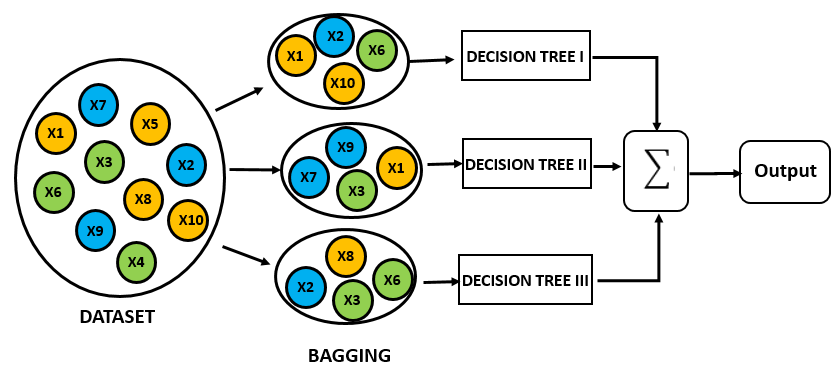
물론 각 Sub-dataset에서 Data의 Overlap을 한다면 더 많은 수의 모델로 학습을 할 수 있다. Random Forest에선 Sub-dataset의 Overlap Sampling 방식으로 많은 수의 Decision Tree를 학습한다.
Bagging Feature
Decision Tree에서는 Infromation Gain이 높게 형성되는 Feature와 분기 지점을 학습한다. 하지만 Random Forest는 n개의 Feature를 랜덤하게 선택하여 Decision Tree를 학습한다. 예를 들면 과일 분류기에 대한 Feature들이 다음과 같이 있다고 가정해보자.
- 크기
- 모양
- 제철 시기
- 가격
- 당도
Random Forest는 위에서 n개의 Feature를 선택하여 Decision Tree를 학습한다. 정리하여 말하자면 Random Forest는 각각 n개의 Feature를 선택한 여러 개의 Decision Tree를 학습한다.
Reference
https://www.tibco.com/reference-center/what-is-a-random-forest
https://medium.com/greyatom/a-trip-to-random-forest-5c30d8250d6a
