1. 사전 기본 개념
1-1. 자료구조란
- 자료구조: 자료들을 정리하고 조직화하는 구조
자료구조 |--- 단순 자료구조
| |--- 직접 접근
|--- 복합 자료구조 --자료접근방법--|
| |--- 순서 접근
|
|--데이터 나열 방식-----|---- 선형 구조
|
|---- 비선형 구조- 단순 자료구조 : 정수, 실수, 문자와 같이 프로그래밍 언어에서 기본적으로 제공하는 데이터 타입
- 복합 자료구조 : 단순 자료구조를 기반으로 만들어낸 배열, 스택, 트리와 같은 자료 구조
- 직접 접근 : 한 번만에 접근
- 순서 접근(순차 접근) : 시작 노드부터 순차적으로 접근
- 선형 구조 : 데이터가 순차적으로 나열 {배열, 연결 리스트, 스택, 큐, 덱}
- 비선형 구조 : 하나의 데이터 뒤에 여러 개의 데이터가 올 수 있는 구조 {트리, 그래프}
- 알고리즘 : 문제를 해결하는 절차
1-2. 트리
- 계층적 자료 표현하는 자료 구조
(1) 트리 용어
A <- 루트 노드
/ \
B C <- 내부 노드 (자식 있음)
/ \ \
D E F <- 리프 노드 (자식 없음)- 노드
- 루트 노드
- 내부 노드 : 자식 노드가 있는 노드 (루트 노드도 포함)
- 서브 트리
- 엣지
- 부모노드
- 자식 노드
- 형제
- 조상 노드
- 자손 노드
- 단말노드(리프노드 leaf node) : 자식 없는 노드
- 비단말 노드
- 차수 : 어떤 노드가 가지고 있는 자식의 수 → 트리의 차수 : 노드 차수 중 가장 큰 값
- 레벨(0부터 시작) → 트리의 높이: 트리 최대 레벨
- 논문이나 자료마다 0부터 시작하는지 1부터 시작하는지 다름
- 포레스트 : 트리들 집합
1-3. 이진 탐색 트리(BST)
- 부모 노드를 기준으로 왼쪽노드는 항상 작고 오른쪽 노드 항상 큼
- 자녀노드는 최대 두개까지
2. B-Tree 개념 및 특징
2-1. 개념
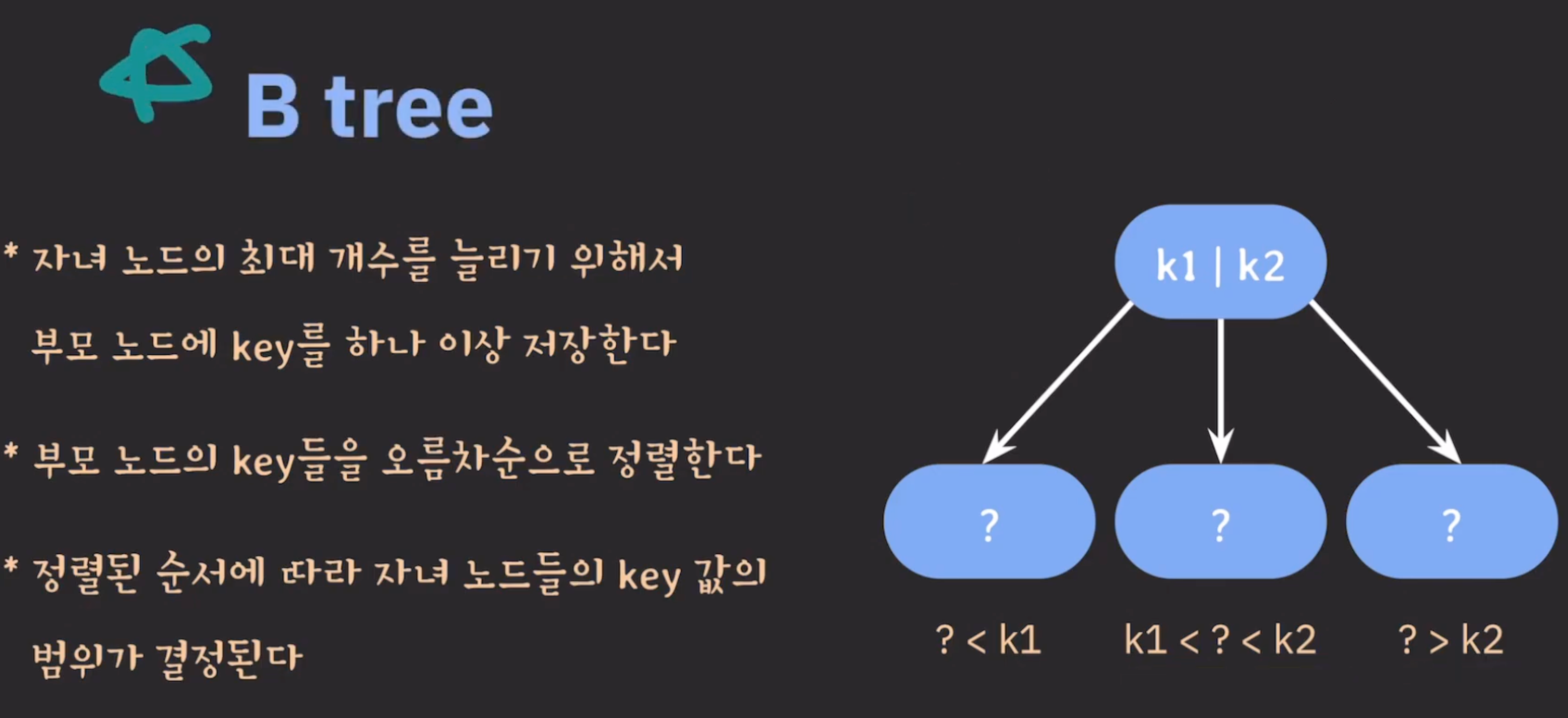
- 이진 탐색 트리를 확장해 하나의 노드가 가질 수 있는 자식 노드의 최대 숫자가 2보다 큰 트리
- 데이터베이스와 파일 시스템에 널리 사용되는 트리 자료구조의 일종
- 이진 트리와 다르게 하나의 노드에 많은 수의 정보(데이터 ⇒ key)를 가질 수 있음 → 노드에 정렬된 키 값과 포인터 가짐, 각 노드는 특정 범위의 값을 관리, key는 정렬된 상태로 저장됨
- 데이터와 key가 혼재되어 사용되지만, 사실 B-Tree는 데이터의 특정 키를 인덱스로 지정하고 해당 인덱스를 계층적인 구조로 정렬한 것이기 때문에 데이터보다는 key라는 표현이 더 정확함
- 최대 M개의 자식을 가질 수 있는 B-Tree를 M차 B-Tree라고 함
- Binary Search Tree를 일반화한 tree라고 할 수 있음 → 자녀노드의 최대 개수를 정할 수 있어서
2-2. 특징
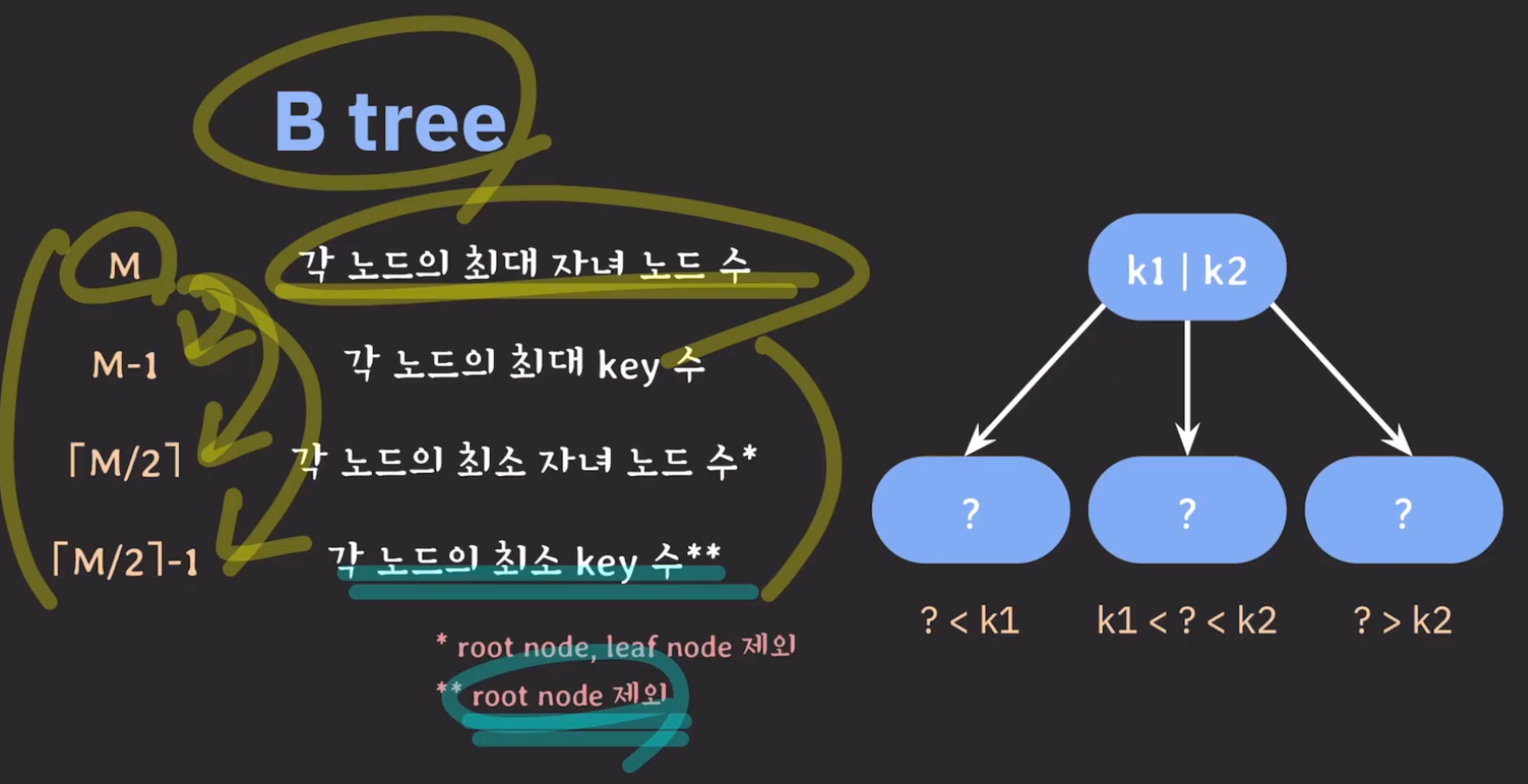
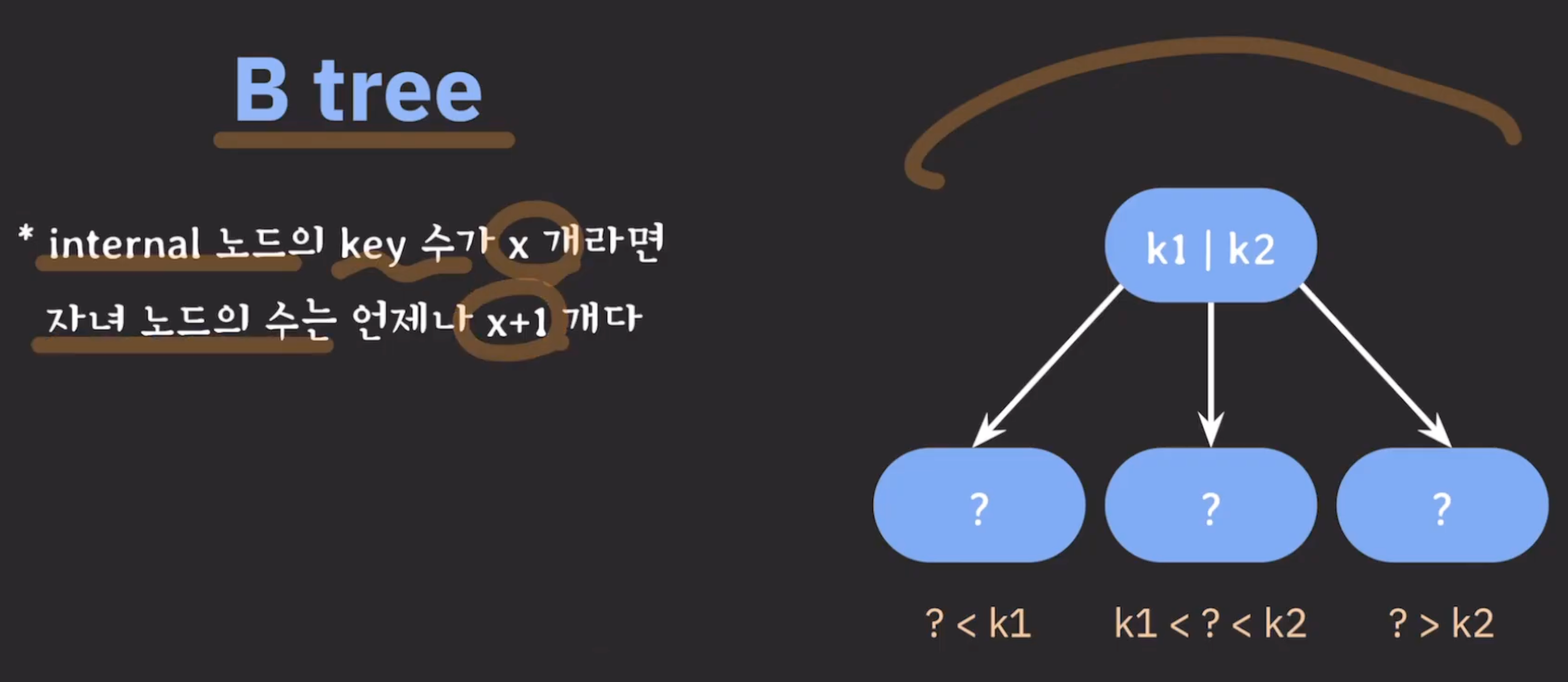
- 노드에는 2개 이상의 데이터(key)가 들어갈 수 있으며, 항상 정렬된 상태로 저장된다.
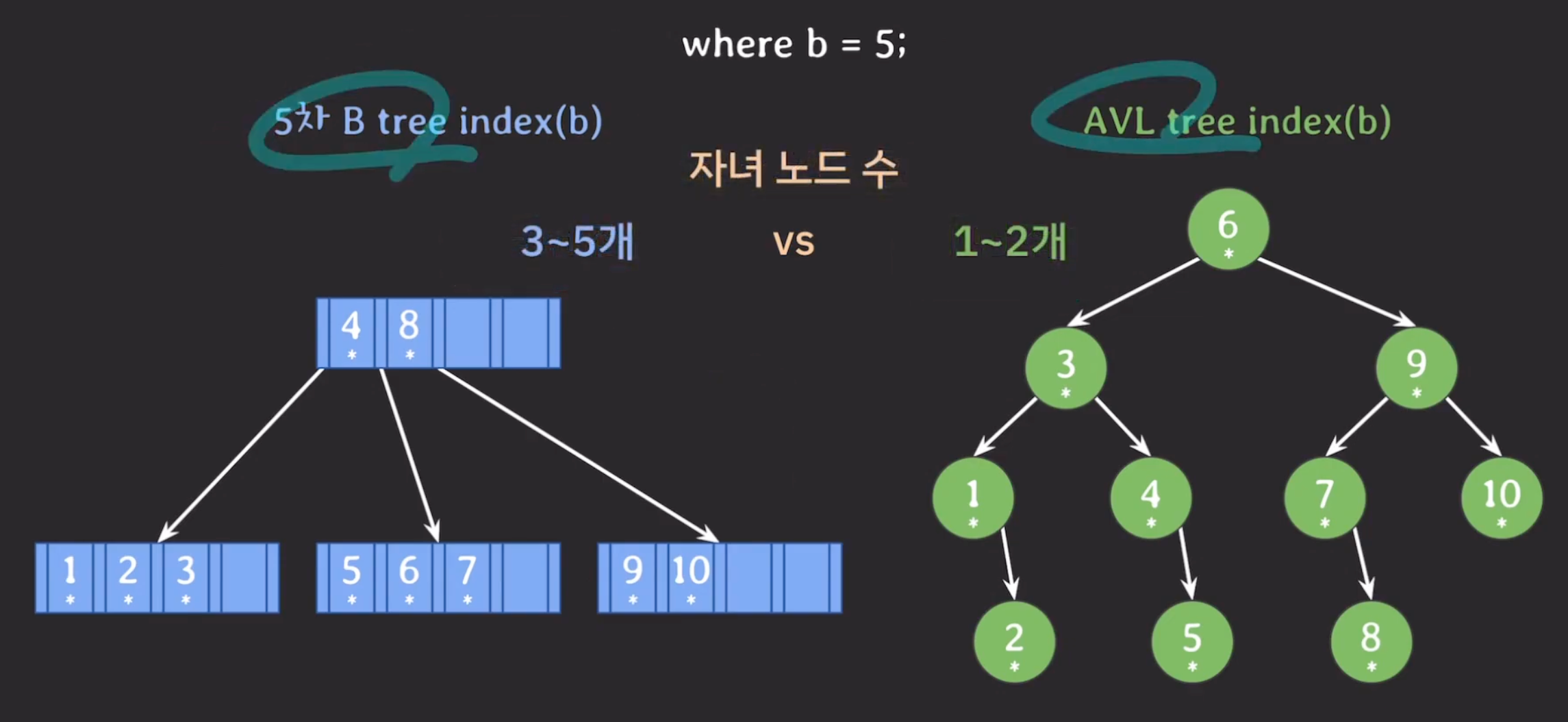
- 내부 노드는 ceil(M/2) ~ M개의 자식노드를 가질 수 있다. → ceil 올림 함수
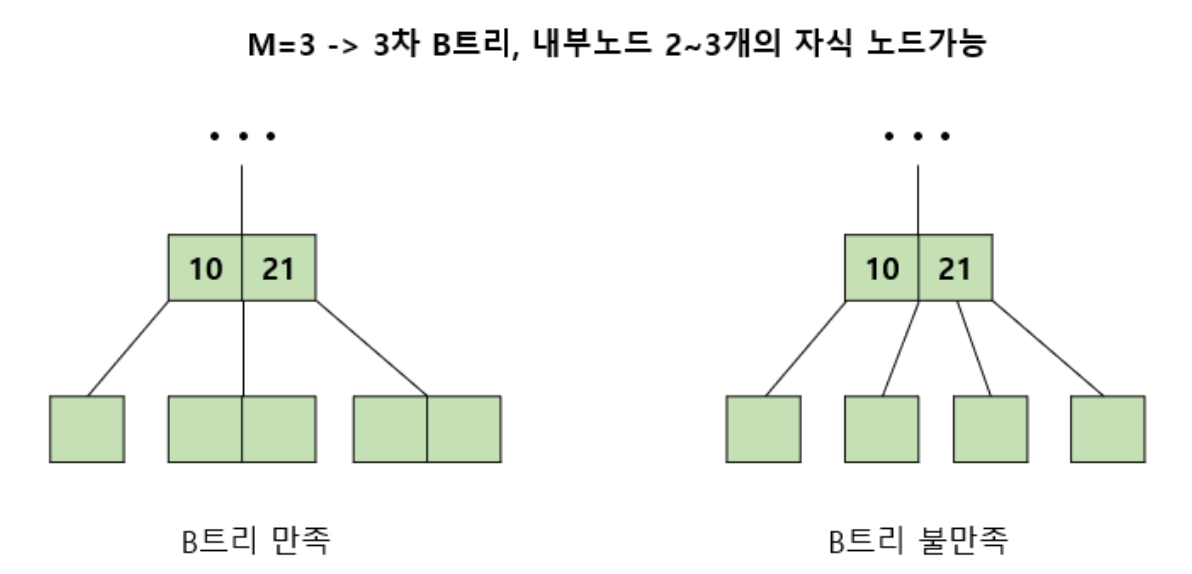
- 특정 노드의 데이터(key)가 k개라면 자식 노드의 개수는 k+1개여야 한다.
- 노드가 최소 하나의 KEY는 가지기 때문에 몇 차 인지에 상관없이 internal 노드는 최소 두개의 자녀는 가진다.
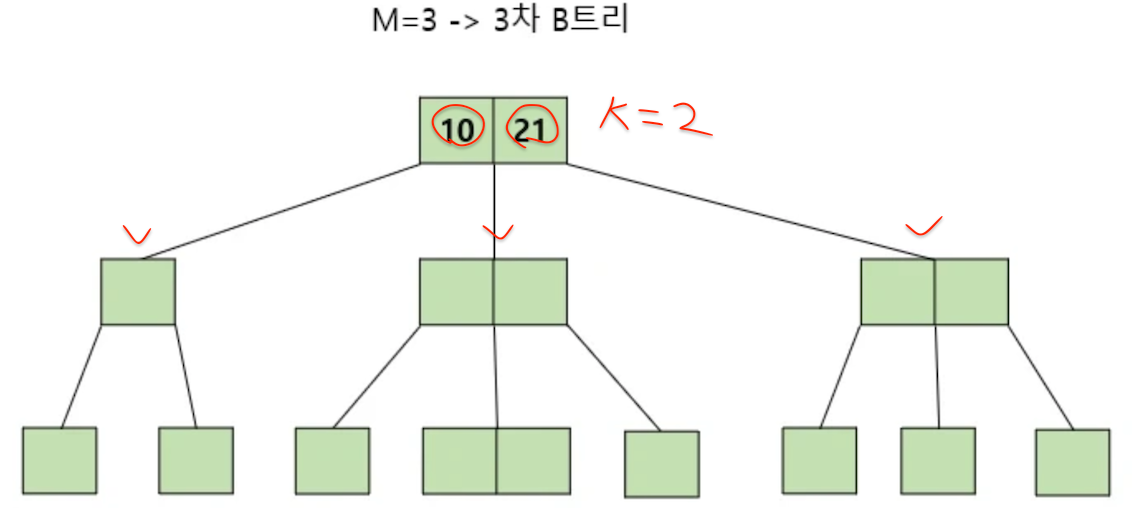
- 특정 노드의 왼쪽 서브 트리는 특정 노드의 key보다 작은 값들로, 오른쪽 서브 트리는 큰 값들로 구성된다.
- 10의 왼쪽 서브 트리는 10보다 작은 값이 위치하고, (10,21) 사이의 서브 트리는 10보다 크지만 21보다 작은 값들이 위치하고, 21 오른쪽 서브 트리는 21보다 큰 값이 위치한다.
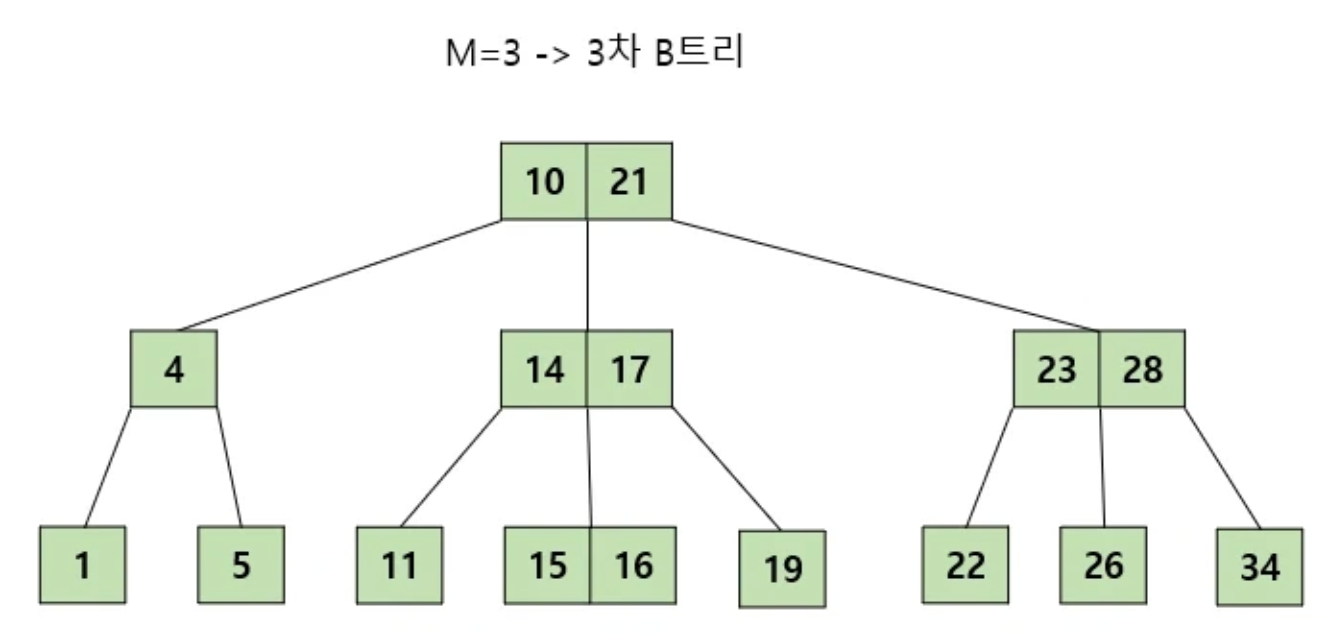
- 노드 내의 데이터(key)는 ceil(M/2)-1개부터 최대 M-1개까지 포함될 수 있다.
- 3차 B트리는 1~2개의 노드 내 데이터를 가짐
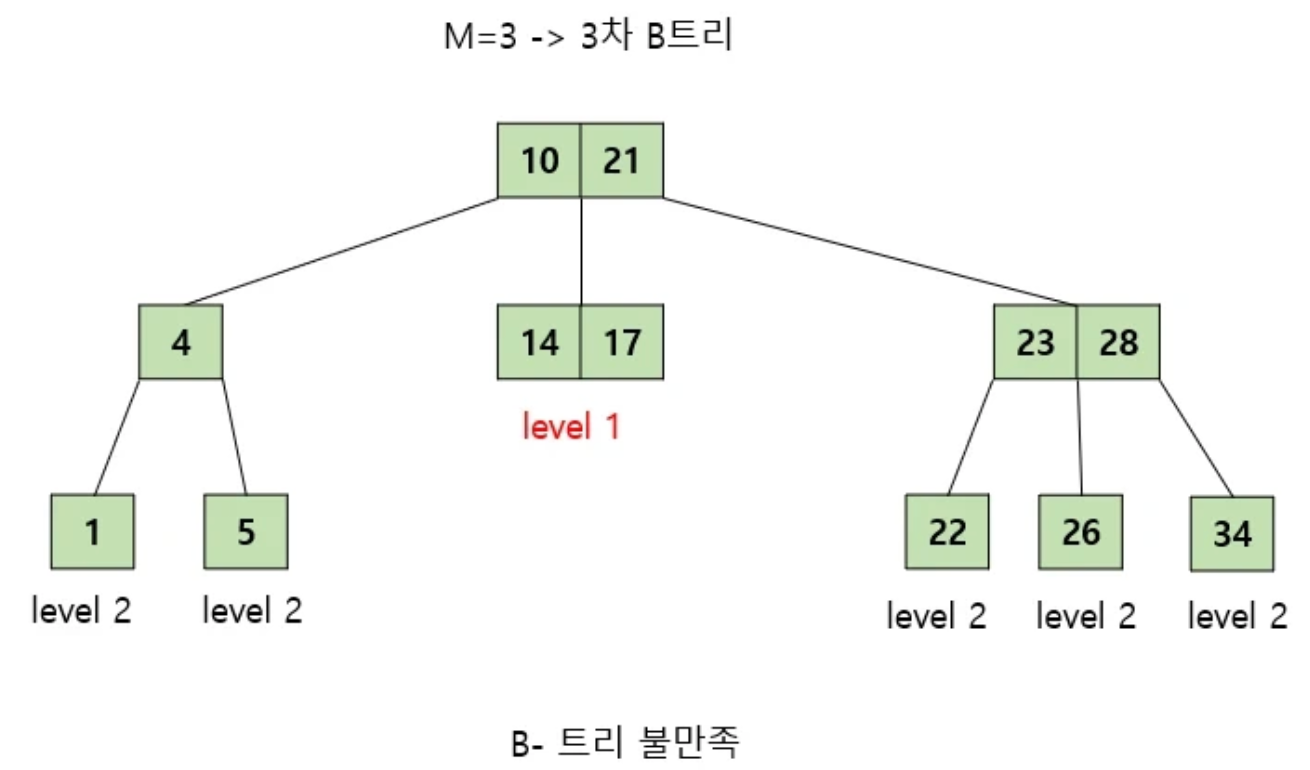
- 모든 리프 노드들은 같은 레벨에 존재한다.
- balanced tree(모든 서브 트리의 높이 차이가 최대 하나인 이진트리) → 검색 평균,최악 모두 O(log N)을 가지게 됨
→ 불만족 예시
3. B-Tree 조회 삽입 삭제
3-1. 조회(검색)
- k 값을 조회한다면
- 루트노드에서 하위 노드로 조회를 한다
- k가 해당 노드보다 작으면 포인터를 따라 왼쪽 자식 노드로 이동
- k가 해당 노드보다 크면 포인터를 따라 오른쪽 자식 노드로 이동
3-2. 삽입
- 데이터 추가는 항상 리프노드에 한다. → 이때 조회를 통해 적절한 리프 노드에 추가한다.
- 노드가 넘치면 가운데 key를 기준으로 좌우 key들을 분할하고 가운데 key는 승진한다.
- 부모 노드에 자리가 있으면 부모 노드로 승진
- 부모 노드에 승진 시키고 부모 노드가 넘치면 가운데 key 기준으로 좌우 분할 후 가운데 key 승진
- 노드가 넘친다 = 각 노드의 최대 key값을 넘치는 경우, M-1값을 넘는 경우
예시 → 2추가

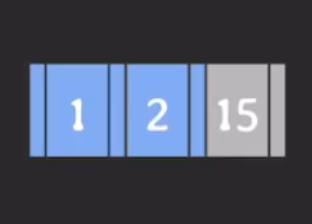
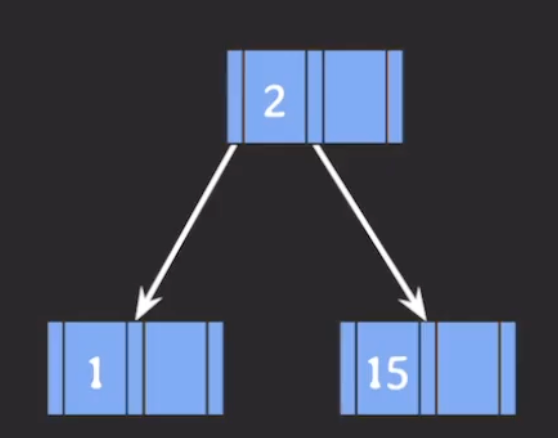
예시 → 10추가
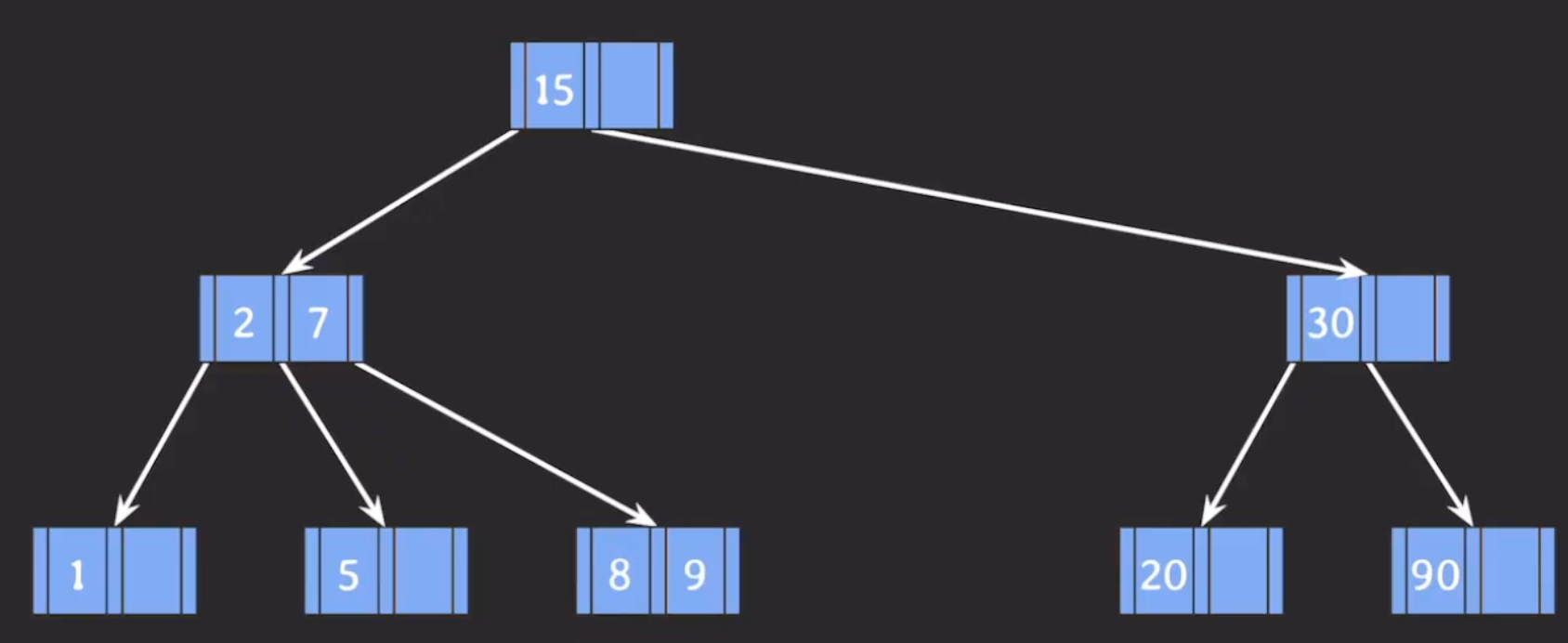
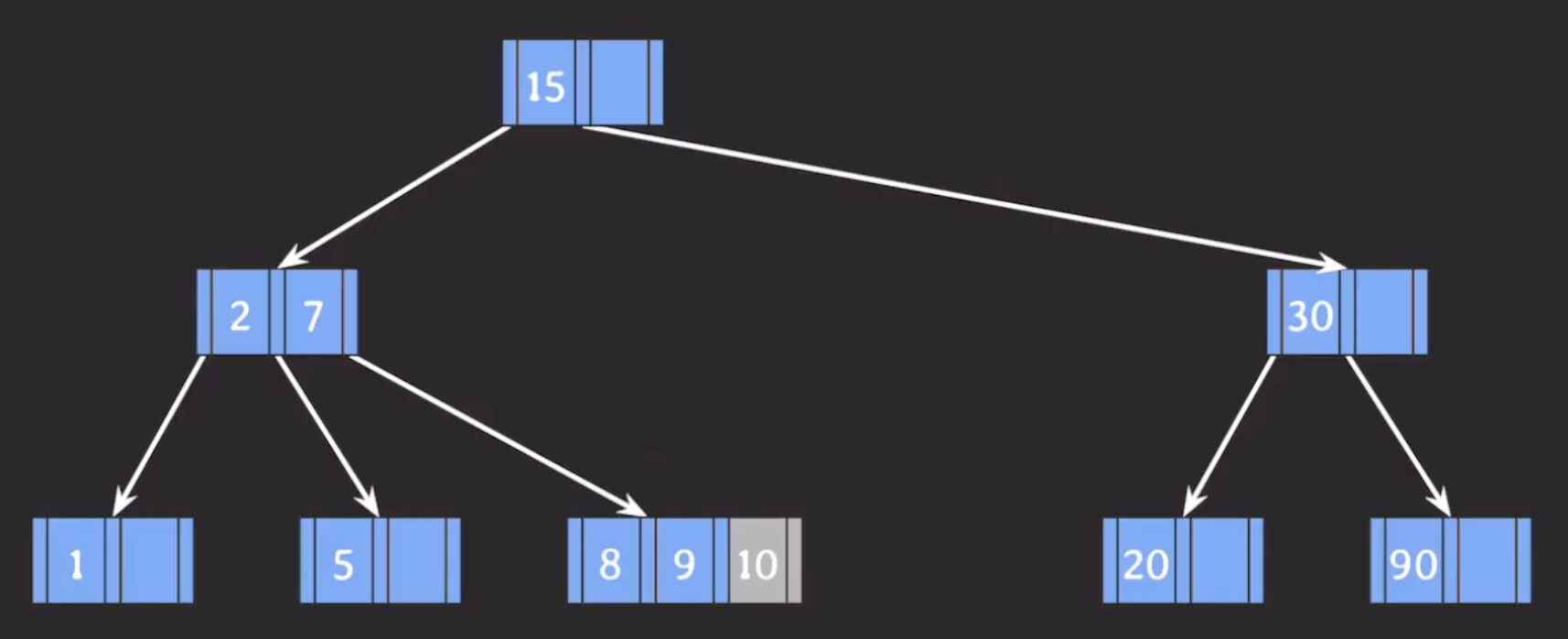
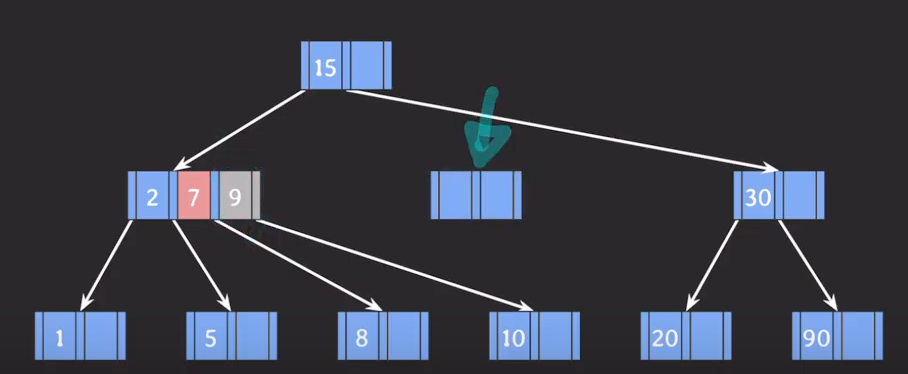
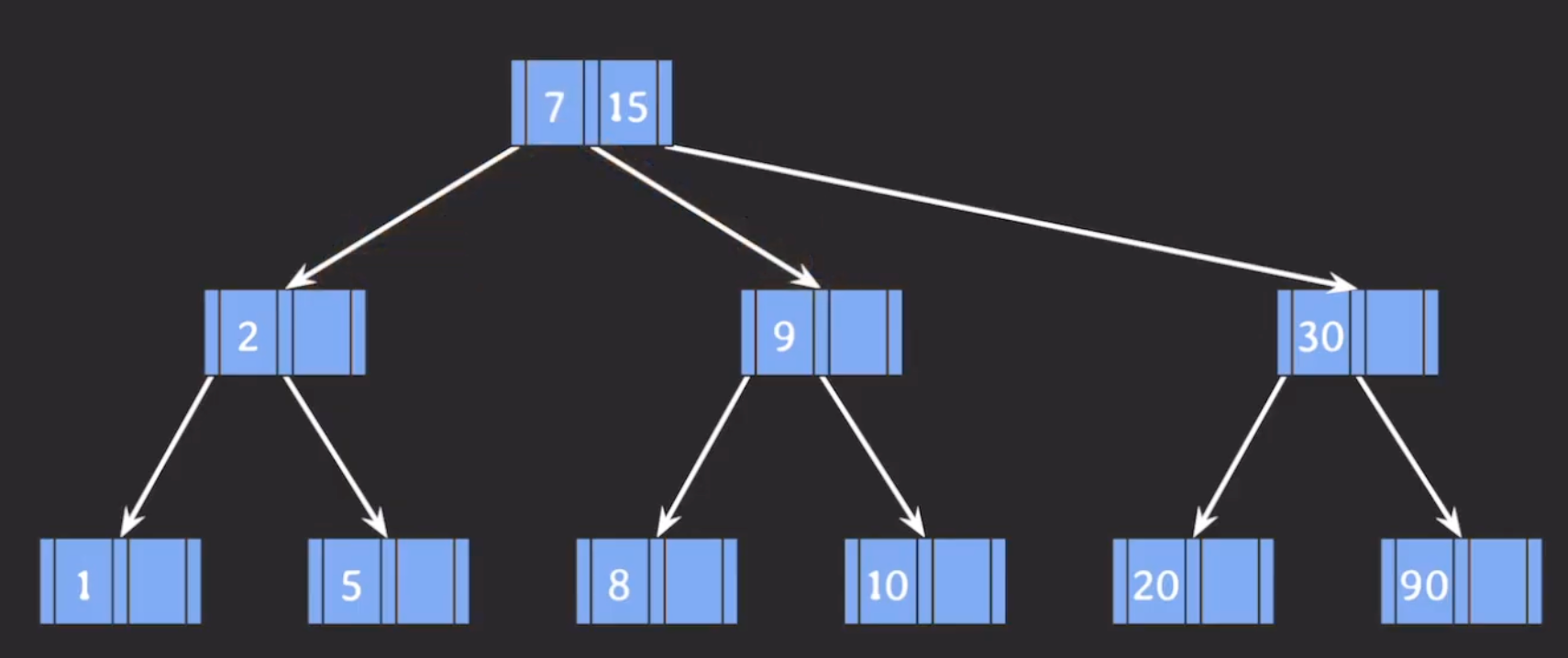
3-3. 삭제
(1) 리프노드에서 삭제 발생
-
데이터 삭제는 항상 리프노드에서 발생
-
삭제 후 최소 key 수보다 적어지면 재조정한다. → 최소 key 수 = ceil(M/2) -1 (루트노드 제외)
-
재조정
(1) key 수가 여유있는 형제의 지원 받는다.
-
먼저 동생(왼쪽 형제)부터 지원받는거 시도
-
형제에게 지원 받은 키를 부모 키 자리로 올리고 부모의 키를 현재 노드의 부족한 곳에 채운다
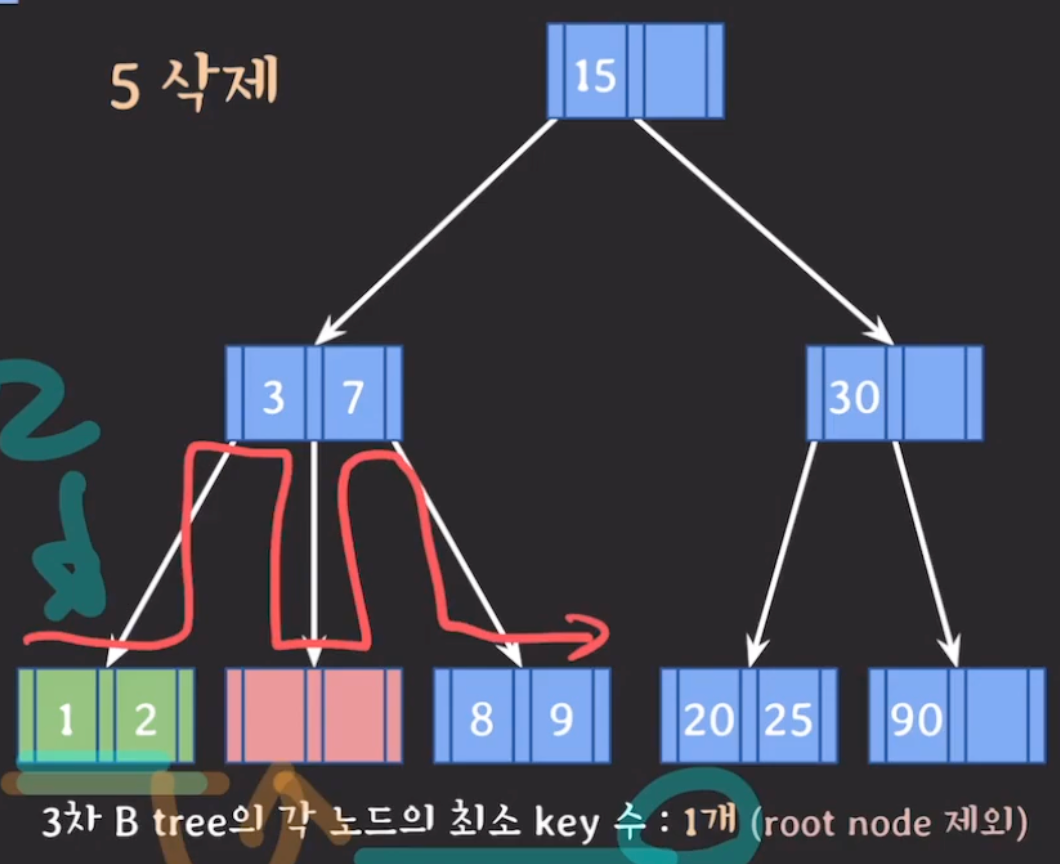
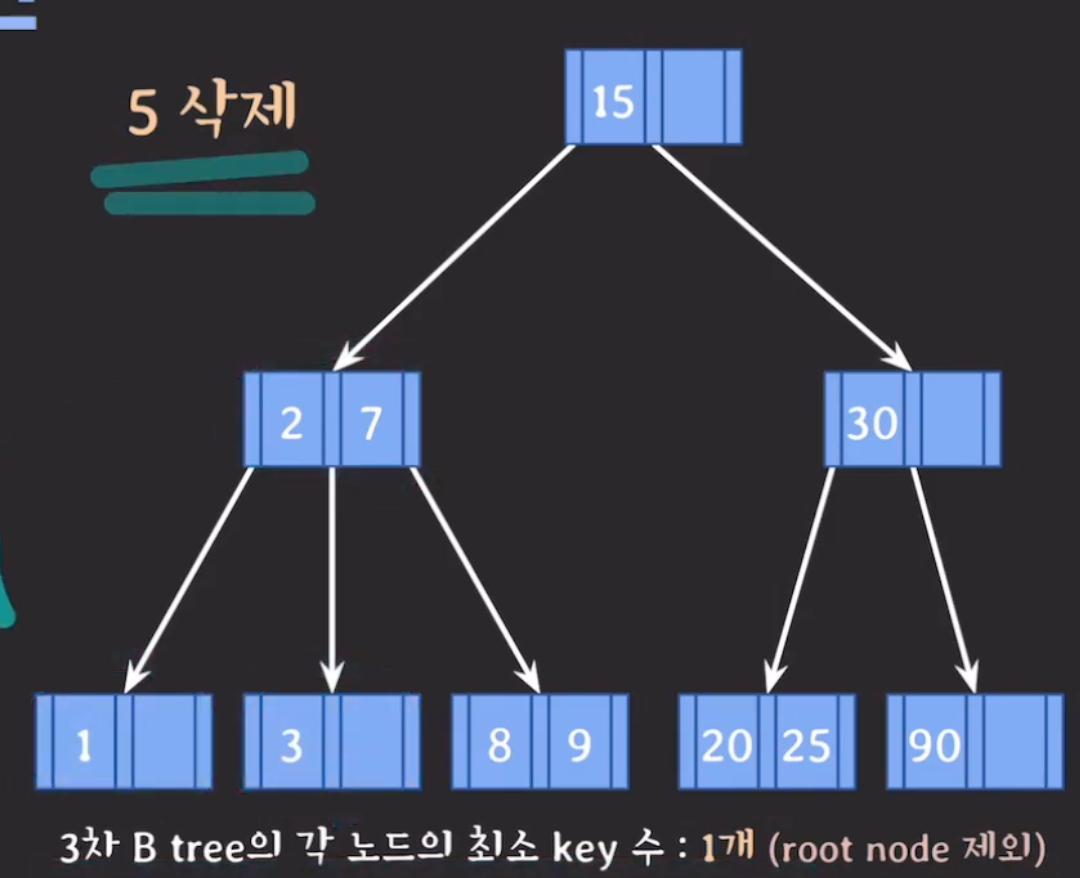

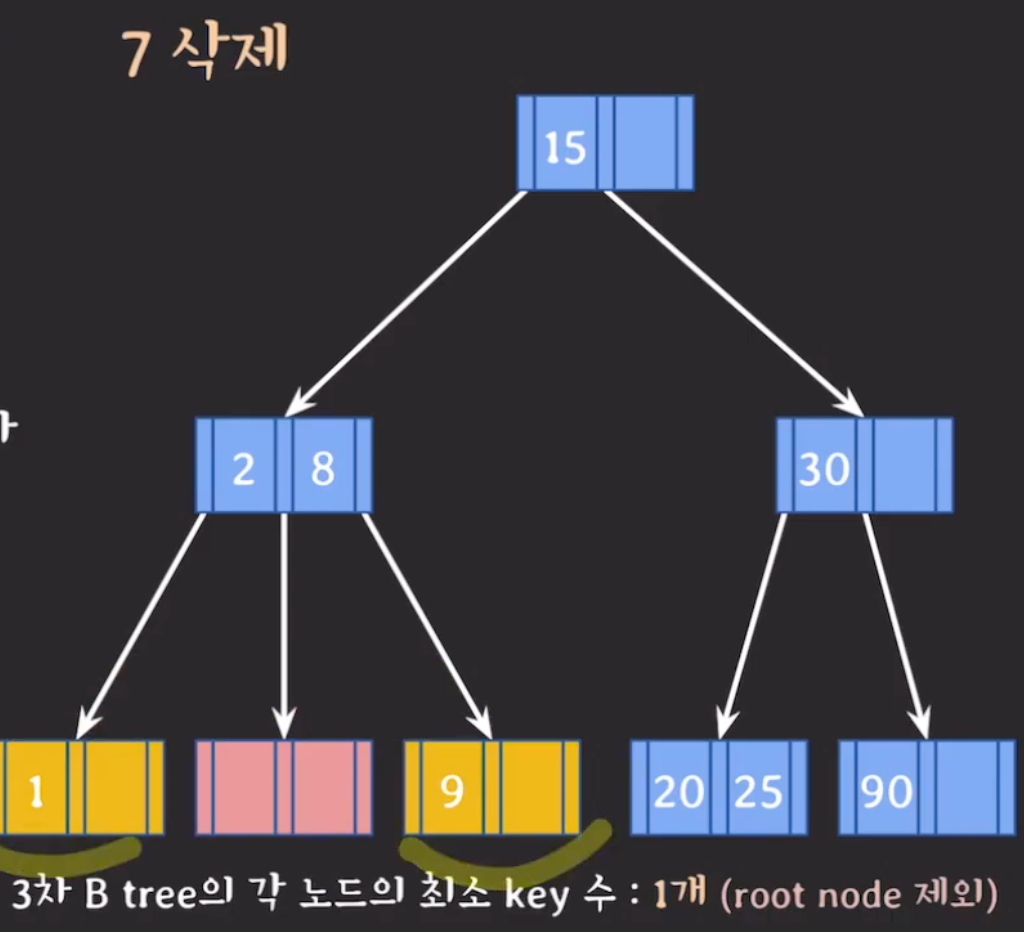
(2) (1)번이 불가능하면 부모의 지원을 받고 형제와 합친다.(합칠때 왼쪽으로 합치기) → 부모에게 지원받는 키는 형제노드와 삭제가 진행되는 노드의 포인터 중간에 있는 키임
-
먼저 동생(왼쪽 형제)부터 합치는거 시도
-
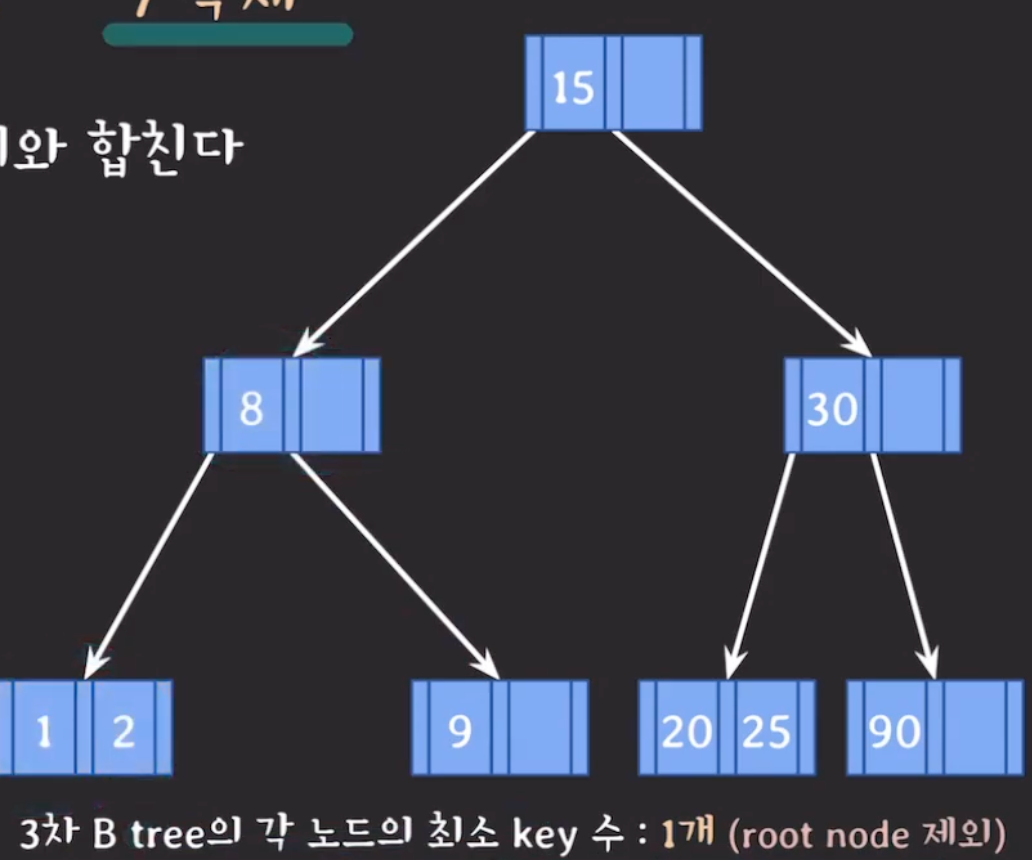
부모에게 지원받은 키를 왼쪽 동생에게 합치고 삭제가 진행된 현재 노드의 남은 내용도 왼쪽 동생에게 합친다.

(3) (2)번 후 부모에 문제가 생기면 거기서 다시 재조정한다.
-
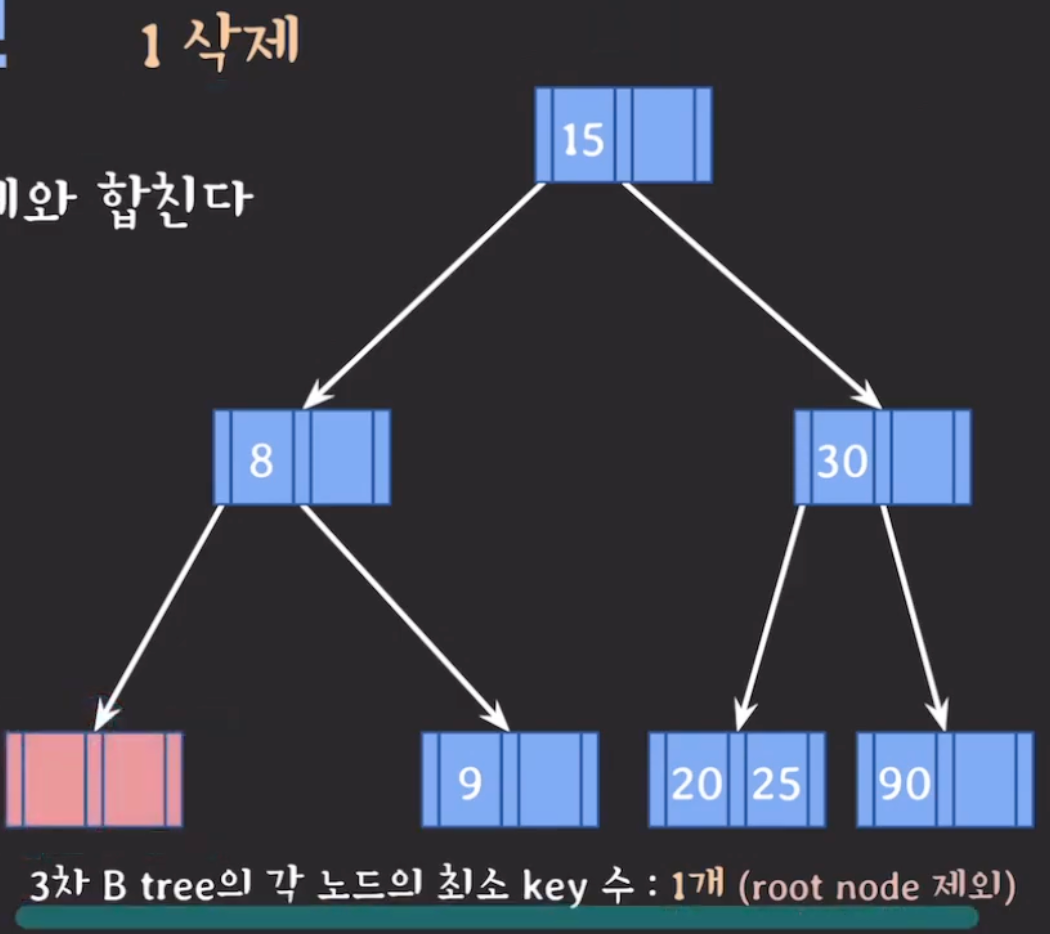
위 (1)(2)번 재조정을 부모 노드에서 다시 시작한다.
-
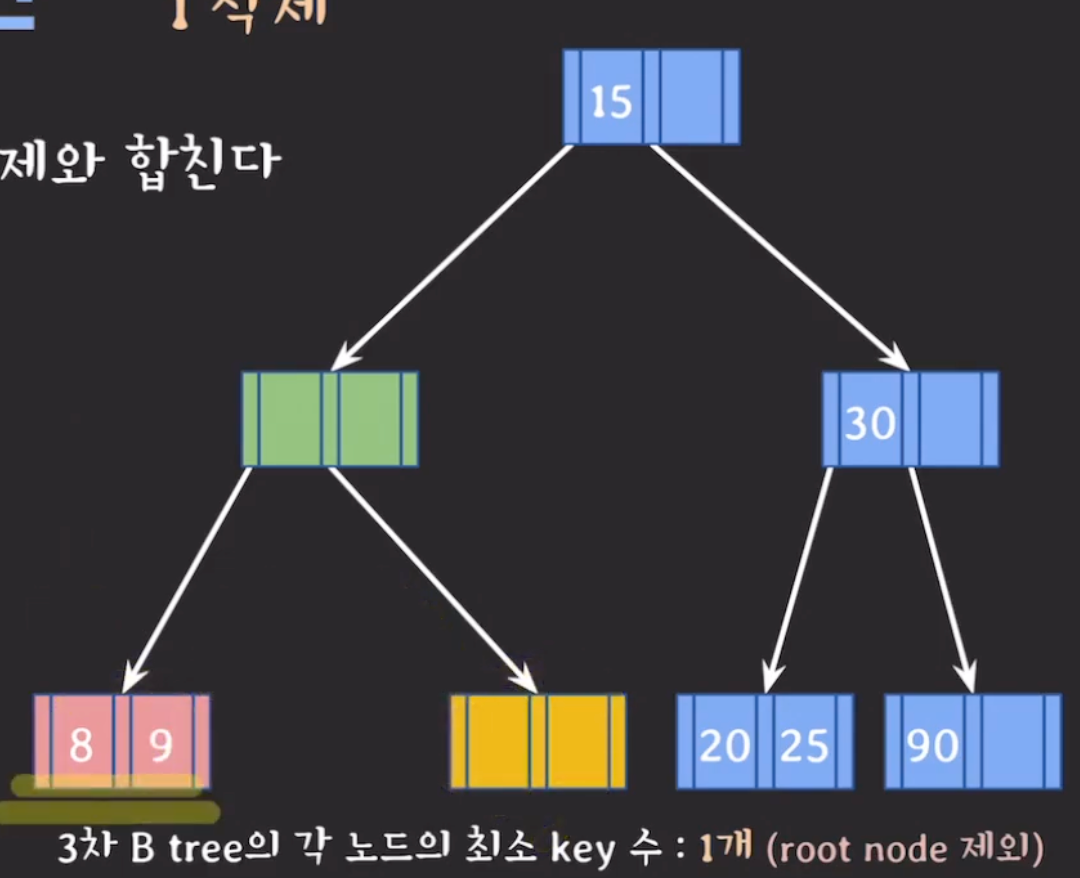
재조정 과정에서 root 노드가 비어있으면 삭제하고 직전에 합쳐진 노드가 root가 된다. → root 노드는 최소 key 수를 만족하지 않아도 괜찮음
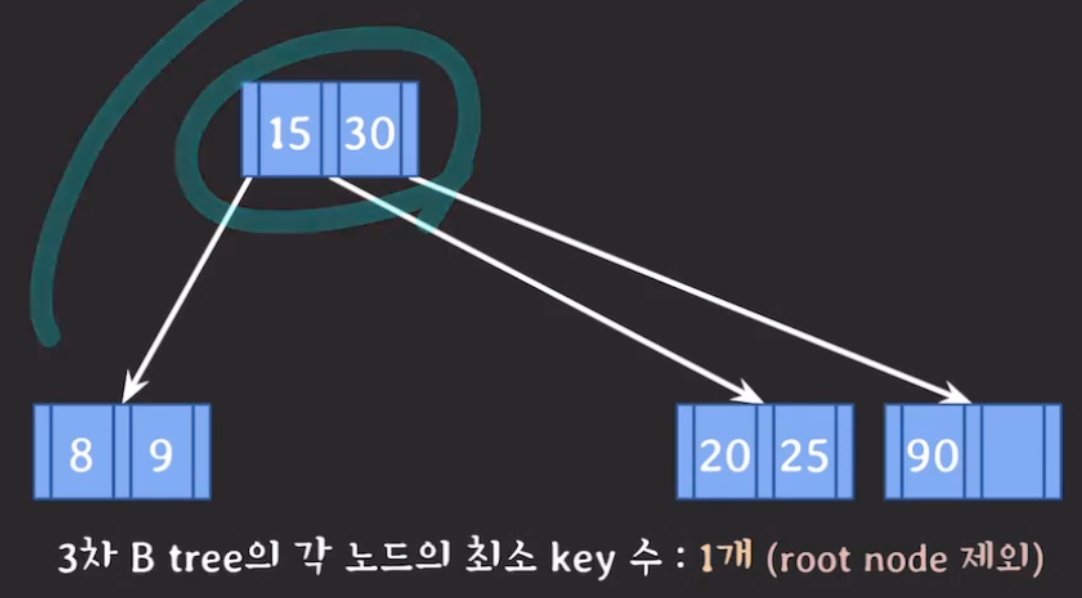
-
-
(2) 내부(internal) 노드에서 삭제 발생
- 리프 노드와 삭제되는 내부 노드 위치 교체
- 삭제할 데이터의 선임자나 후임자와 위치 교체
- 선임자 : predecessor 나보다 작은 데이터 중 가장 큰 값
- 후임자 : successor 나보다 큰 데이터 중 가장 작은 값
- 즉, 데이터 삭제는 항상 리프노드에서 발생
하지만 코드에서 구현할 때는 조금 다름
- 삭제할 키가 있는 노드가 리프노드일 때
- 현재 노드에서 바로 삭제
- 삭제할 키가 있는 노드가 리프노드가 아닐 때
- 선임자가 여유 키를 가진 경우 (> min_keys)
→ Predecessor로 교체 후, 왼쪽 서브트리에서 predecessor 재귀 삭제
→ 최종적으로 리프 노드에서 삭제됨 - 후임자가 여유 키를 가진 경우 (> min_keys)
→ Successor로 교체 후, 오른쪽 서브트리에서 successor 재귀 삭제
→ 최종적으로 리프 노드에서 삭제됨 - 선임자, 후임자 모두 최소 키만 가진 경우 (= min_keys)
→ 양쪽 자식과 삭제할 키를 병합(Merge)
→ 병합된 노드에서 삭제 (리프가 아닐 수도 있음)
- 예시``` [10, 20, 30] ← 20 삭제 / | | \ [5] [15] [25] [35] ↑ ↑ 양쪽 모두 키 1개 (= min_keys) Step 1: 병합 - [15] + 20 + [25] = [15, 20, 25] [10, 30] / | \ [5] [15,20,25] [35] ↑ 병합된 노드 (리프일 수도, 아닐 수도) Step 2: 병합된 노드에서 20 삭제 [10, 30] / | \ [5] [15,25] [35] ```
- 선임자가 여유 키를 가진 경우 (> min_keys)
- (항상 확인) 삭제 진행 후 현재 노드의 키가 최소보다 작을 때
- 형제에게 키 빌릴 수 있으면 빌리기
- 형제에게 못빌릴때 부모에게 빌리고 부모키 왼쪽 오른쪽 자식(현재 노드와 형제노드)끼리 병합
4. B-Tree 시간복잡도

- 시간복잡도 계산
- N: 전체 key(데이터)의 개수, m : B-Tree의 차수(최대 자식 개수), h : B-Tree 높이
- m^h ≥ N
- h ≤ logₘ N ⇒ h ≈ logₘ N
- 이때 탐색 시간은 트리 높이에 비례함. 즉, 시간복잡도는 logₘ N에 비례
- logₘ N에서 m은 상수로 1로 취급 logₘ N ⇒ log N
- 시간 복잡도 = log N
- 시간복잡도 평균 최악이 같은 이유
- B-Tree는 항상 균형을 유지하므로 모든 리프 노드가 같은 깊이
- 같은 깊이 = 같은 시간복잡도
5. 데이터베이스에서 사용되는 방식
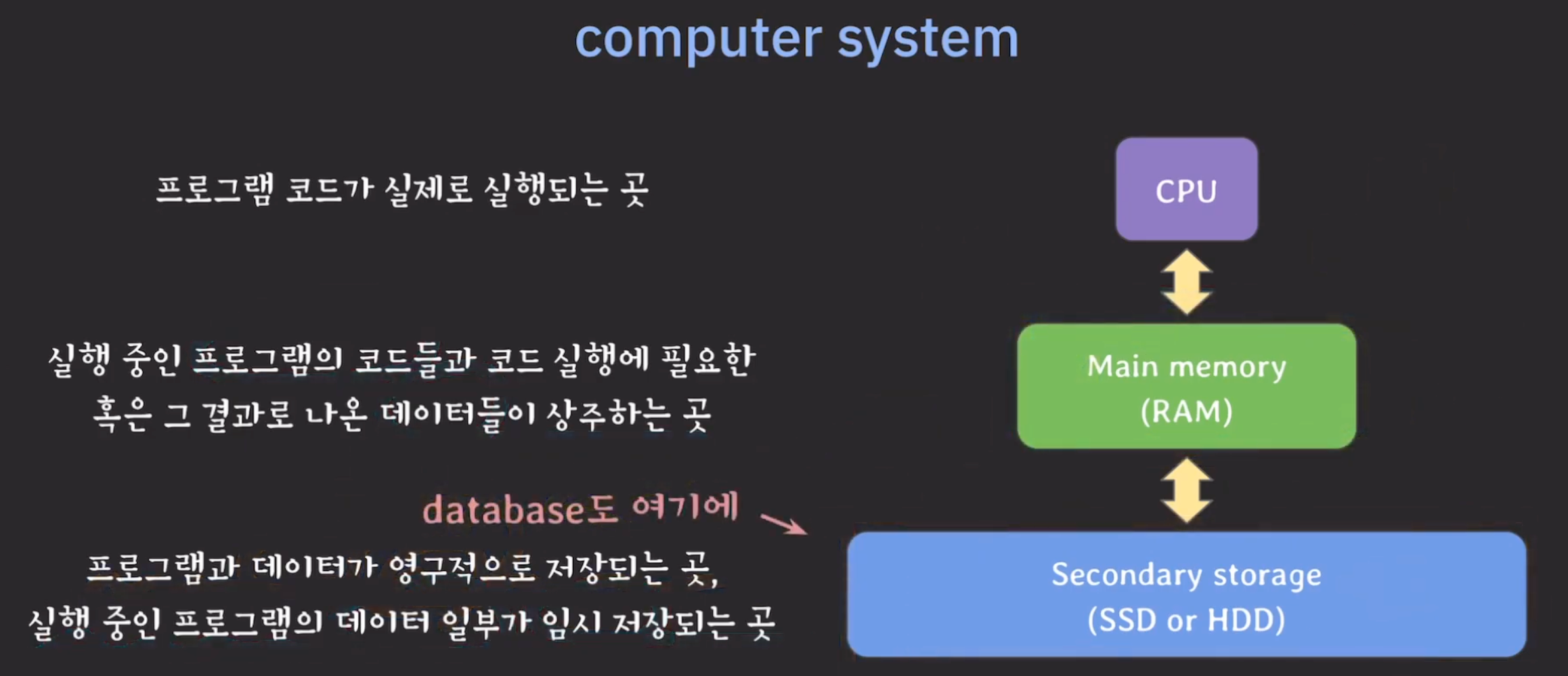
(1) 기본 데이터베이스 개념
- database는 보조저장장치에 위치함
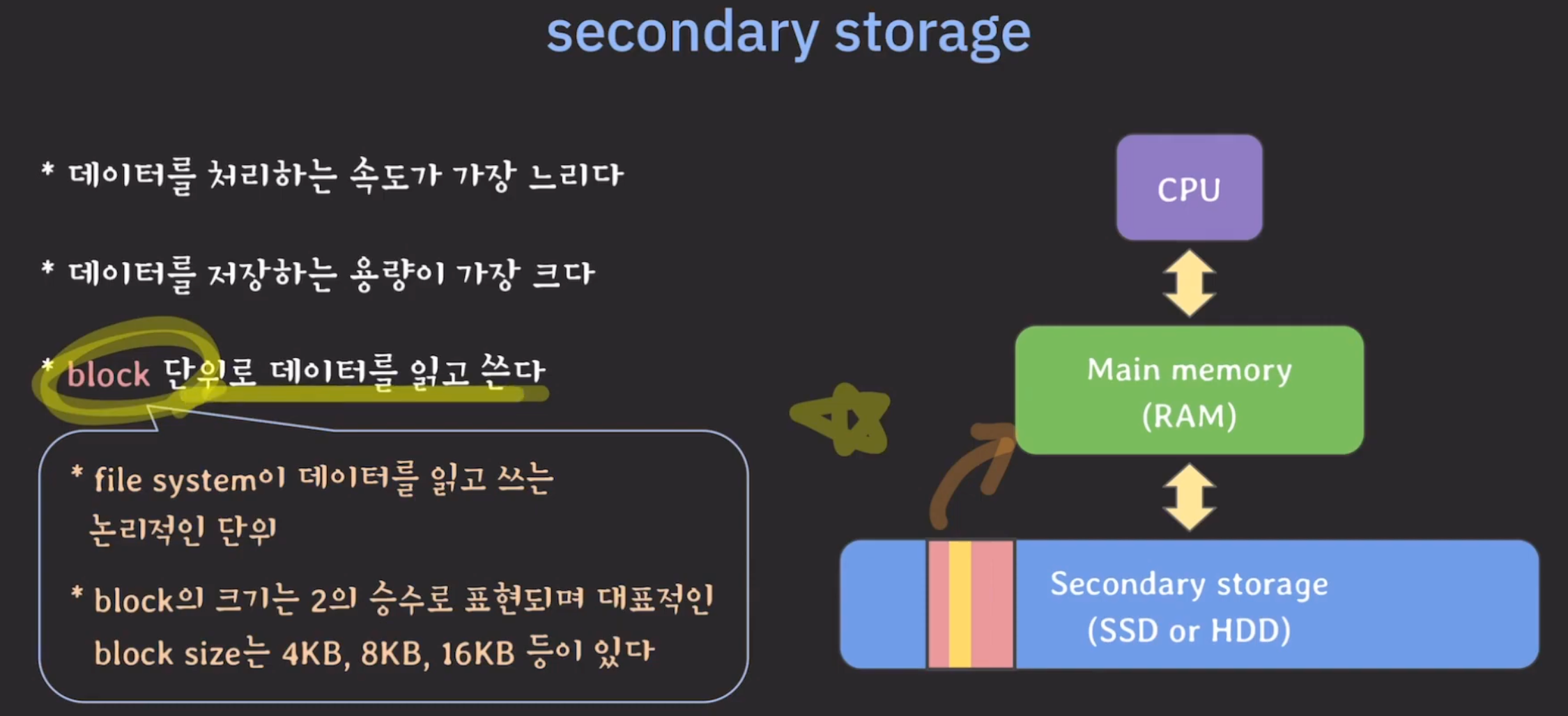
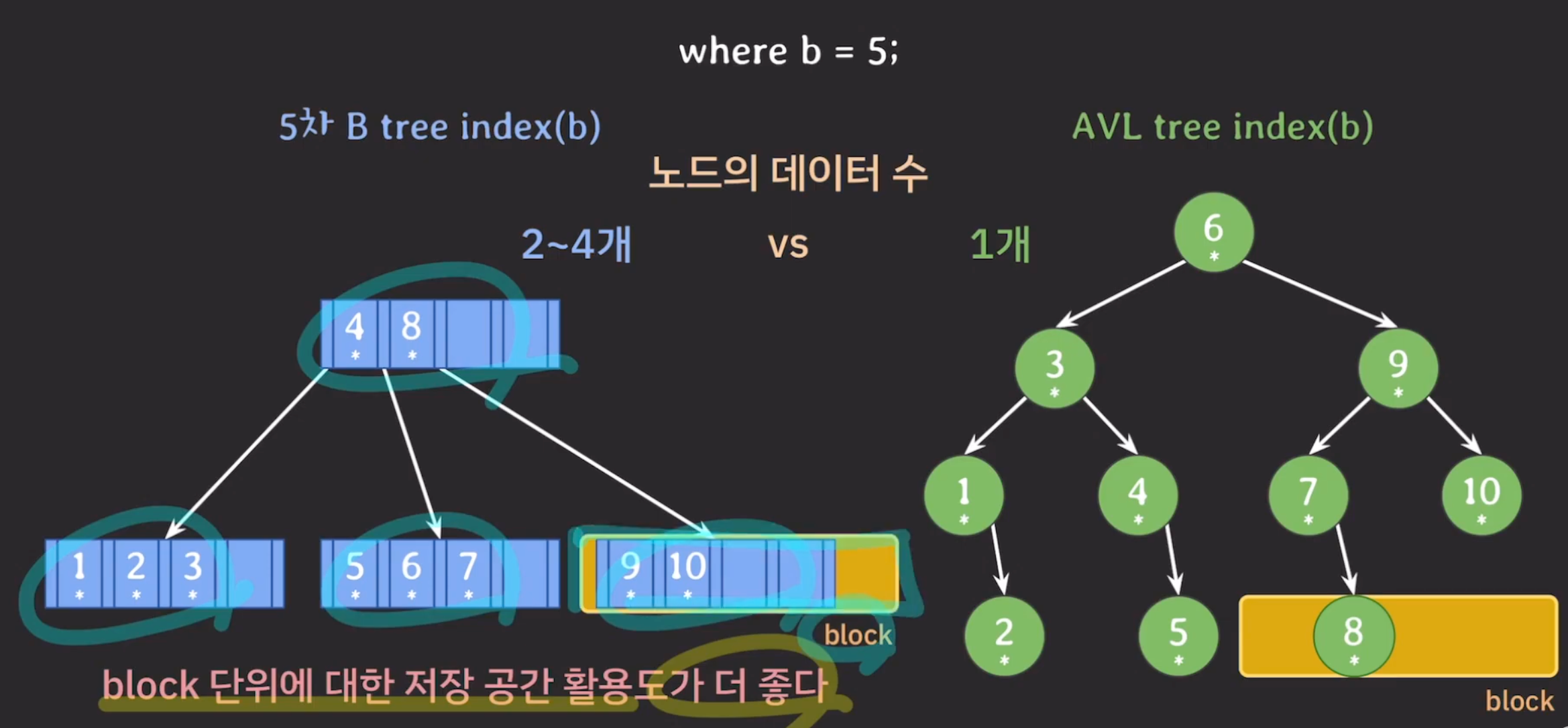
- 데이터를 읽고 쓸 때 원하는 부분만 가져오는 것이 아니라 block 단위로 가져다 씀
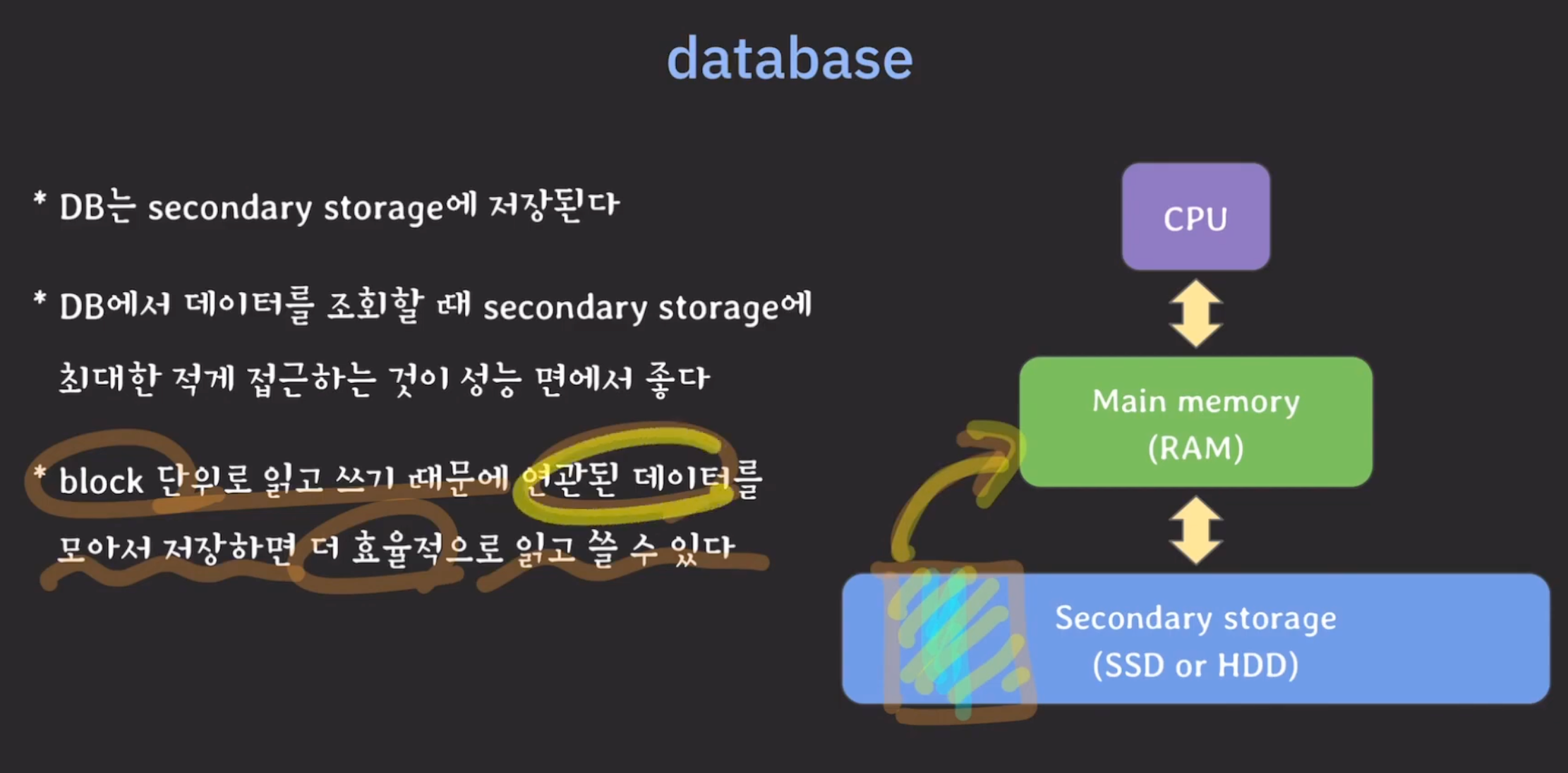
- 보조기억장치에 최대한 적게 접근하고 연관된 데이터가 가까이 모아서 저장되면 더 효율적임
(2) DB에 B Tree 계열을 사용하는 이유
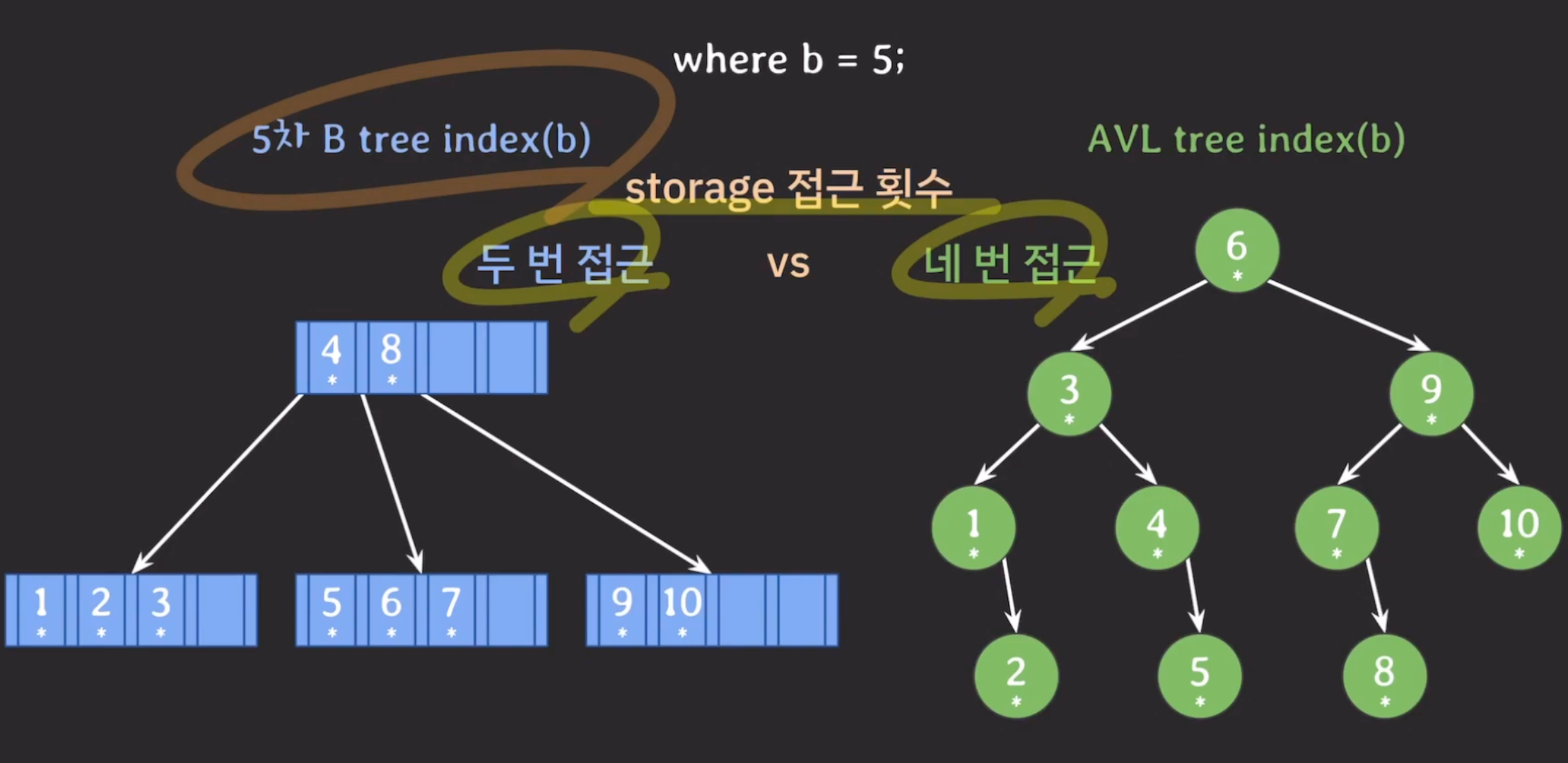
- 자녀 노드의 개수, 노드의 데이터 수를 많이 가질 수 있으므로 storage 접근 횟수가 줄어들고 Block 단위의 저장 공간을 알차게 사용할 수 있음 → 데이터를 찾을 때 탐색 범위를 빠르게 좁힐 수 있음
- DBMS에서는 ‘하나의 B-Tree 노드 = 하나의 디스크 블록’으로 설계되므로 같은 노드의 key들은 항상 같은 블록에 존재
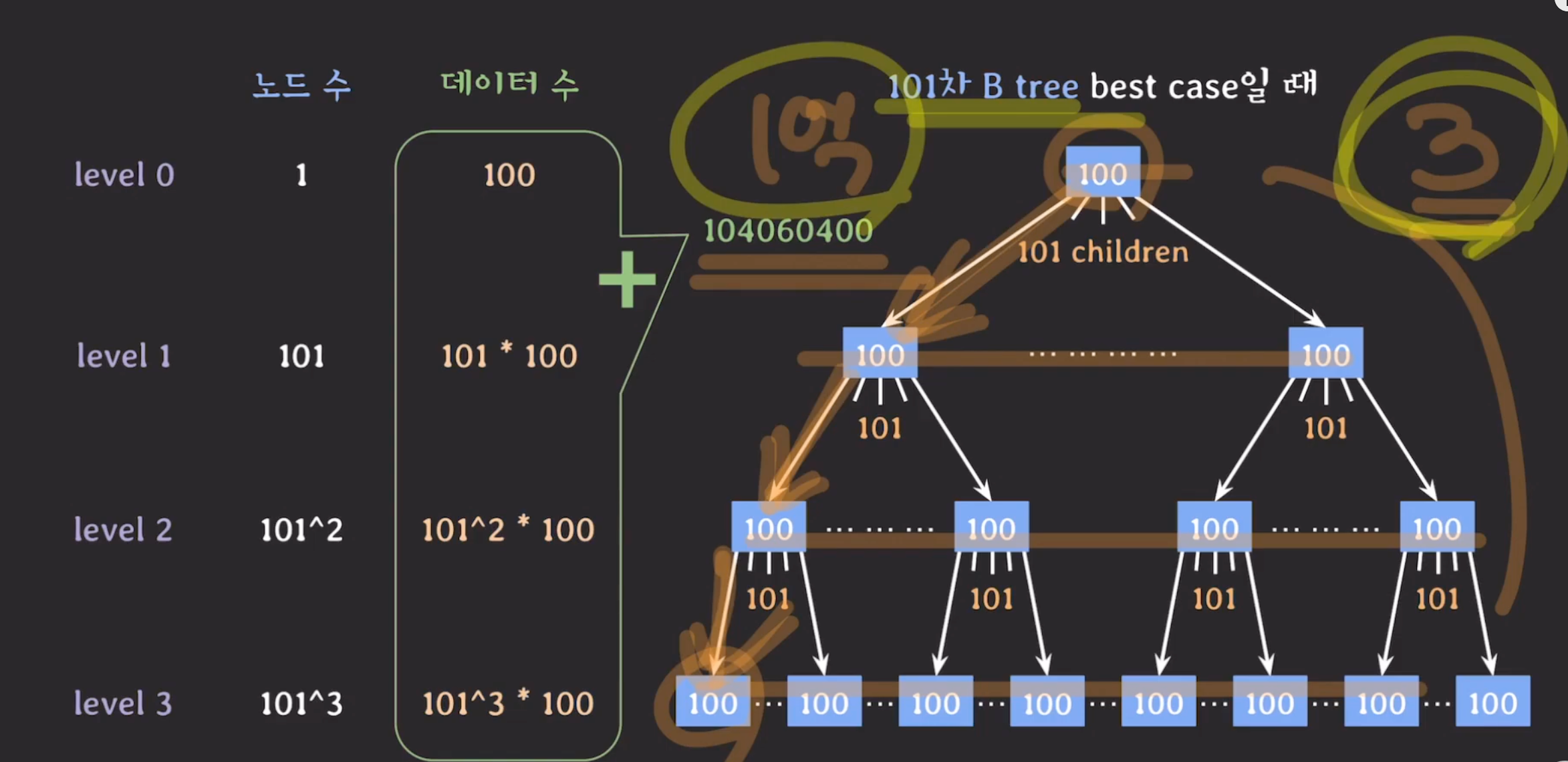
(3) B-Tree best case
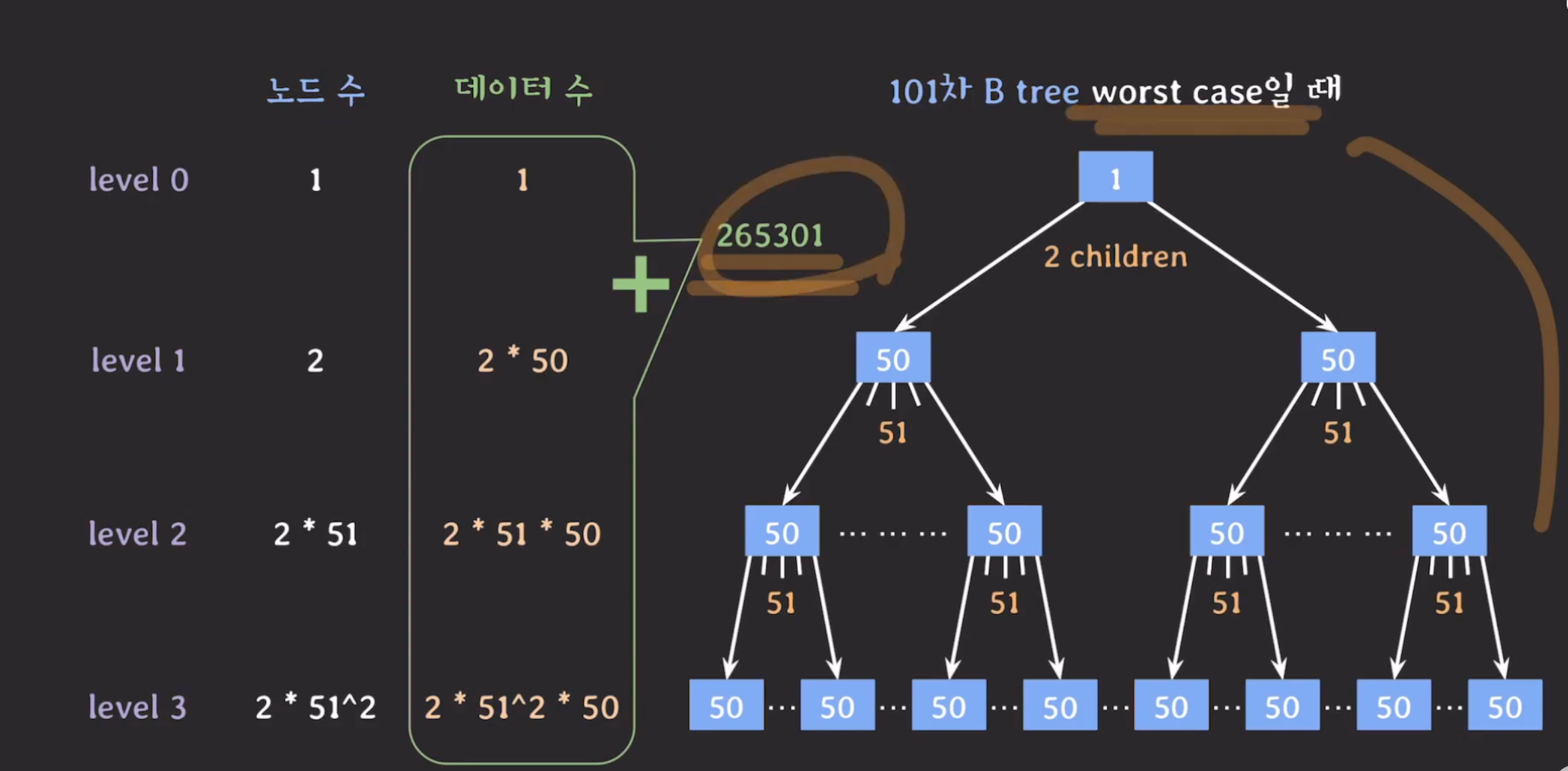
(4) B-Tree worst case
- 파라미터
- 최소 루트 노드 key 개수 : 1
- 최소 루트 자식 노드 개수 : 2
- 최소 노드 key 개수 : 50
- 최소 자식 노드 개수 : 51

6. 나오게 된 배경, 다른 B+Tree, B*Tree와의 차이점
- 창시자
- 루돌프 바이어(독일)가 새롭게 만듬
- 배경
- 디스크를 위한 트리를 위해 만들어진 것으로 디스크의 느린 I/O와 블록 단위의 데이터 읽기를 고려하고 만들어짐
- 차이점
- B-Tree는 데이터가 내부 노드에도 존재 가능 → 디스크 I/O 많이 발생
- B-Tree는 리프노드 연결X → 범위 검색 시 모든 노드 순회 필요
*그 외
*-1. 문자열은 단순 자료구조인지 복합 자료구조인지
- 내부적 구현 관점에서 보면 문자가 연속된 메모리 공간에 저장되어 복합적 구조이지만 일반 프로그래밍 언어에서 기본적으로 제공하는 데이터 타입이므로 논리적으로는 단순 자료구조임
*-2. 배열과 리스트 차이
배열, 동적배열, 리스트, 연결리스트
- 배열
- 선언 시 크기 고정, 연속된 메모리 공간
- 직접 접근 O(1) but, 중간 삽입삭제 느림 O(n)
- 동적 배열
- 크기 조절 가능한 배열 → 공간이 부족하면 더 큰 메모리를 새로 할당하고 기존 데이터 복사 (여전히 연속된 메모리 공간)
- 직접 접근 but, 중간 삽입삭제 느림
- 연결 리스트
- 각 노드가 데이터+포인터(다음 노드 주소) 저장, 비연속 메모리 공간
- 순차 접근 O(n) but, 중간 삽입삭제 빠름 O(1)
- 리스트 → 동적 배열 또는 연결 리스트
*-3. 힙 트리와 일반 트리 차이
(1) 완전 이진 트리
- 높이가 k인 트리에서 레벨 1부터 k-1까지 노드가 모두 채워져있고 마지막 레벨 k에서는 왼쪽부터 오른쪽으로 노드가 순서대로 채워져 있는 이진트리
(2) 힙
- 완전 이진 트리 형태를 가지며, 부모 자식 간의 값 크기 관계를 만족하는 트리
- 최대 힙 : 부모 노드 ≥ 자식 노드
- 최소 힙 : 부모노드 ≤ 자식 노드
- 왼쪽 노드가 오른쪽 노드보다 크거나 작아야 한다는 규칙 없음.
- 단, 삭제 연산 시 루트 노드 삭제 후 제일 말단 노드를 루트로 올려서 자식 노드 중 더 크거나 작은 노드와 교환해야함.
*-4. 알고리즘의 자세한 정의
- 문제를 해결하기 위한 명확하고 순서있는 절차
- 입력, 출력, 명확성, 유한성, 효율성
*-5. 멀티 레벨 인덱스
(1) 인덱스
- ‘검색키의 값’과 ‘그 값이 있는 레코드 주소(포인터)’를 묶어둔 자료구조
- https://jaehee1007.tistory.com/131
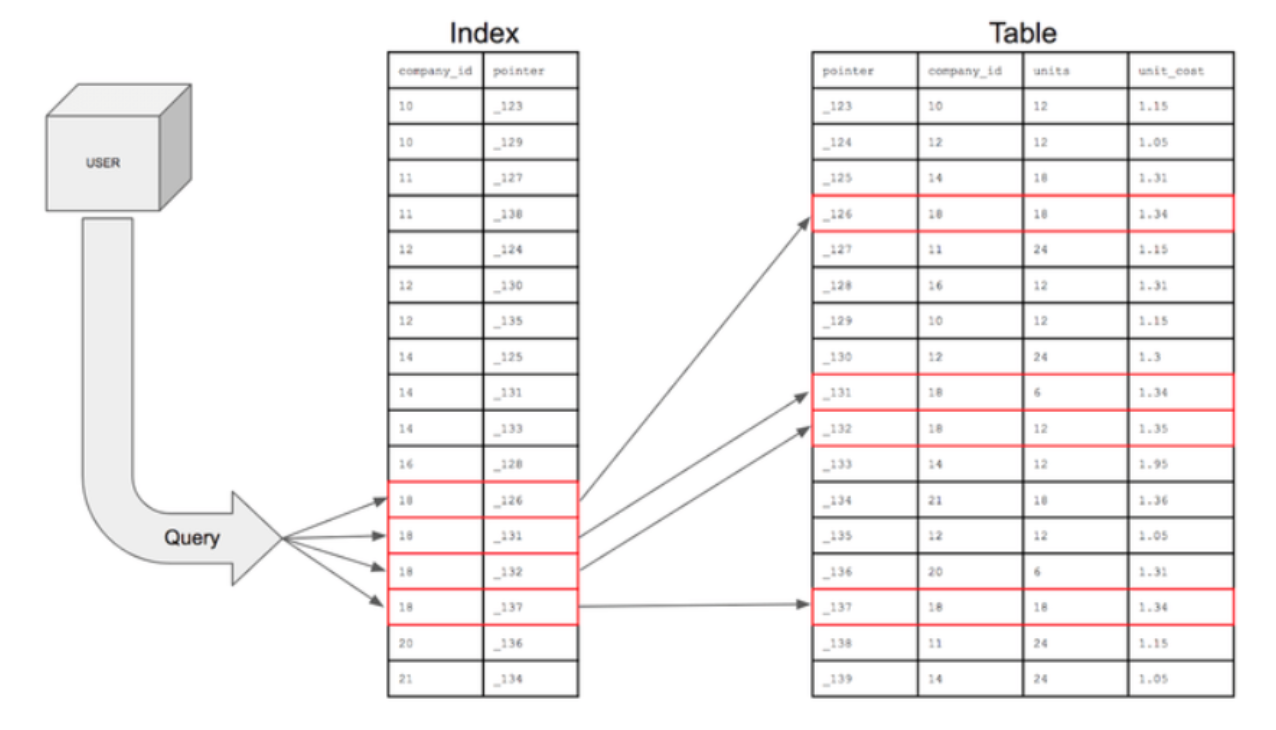
- 클러스터형 인덱스 : 데이터 행 순서대로 저장되는 인덱스, 각 테이블 당 하나
- 테이블 생성 시 기본키를 기준으로 하나의 클러스터형 인덱스 가짐
- 보조형 인덱스 : 기준이 되는 컬럼을 기준으로 별도의 순서로 저장되는 인덱스, 각 테이블 당 여러개 가능
- 테이블의 컬럼에 ‘유일값을 가지게 하는 UNIQUE’로 설정하면 그 컬럼 기준으로 하나의 보조형 인덱스 가짐
(2) 멀티 레벨 인덱스
- 인덱스를 위한 인덱스를 두는 계층적 구조

- 단일 인덱스와 비교해서 멀티 레벨 인덱스를 사용하면 인덱스 저장 파일 크기는 동일하지만 검색 속도가 빨라짐 (단일 O(n), 멀티레벨 O(log n))
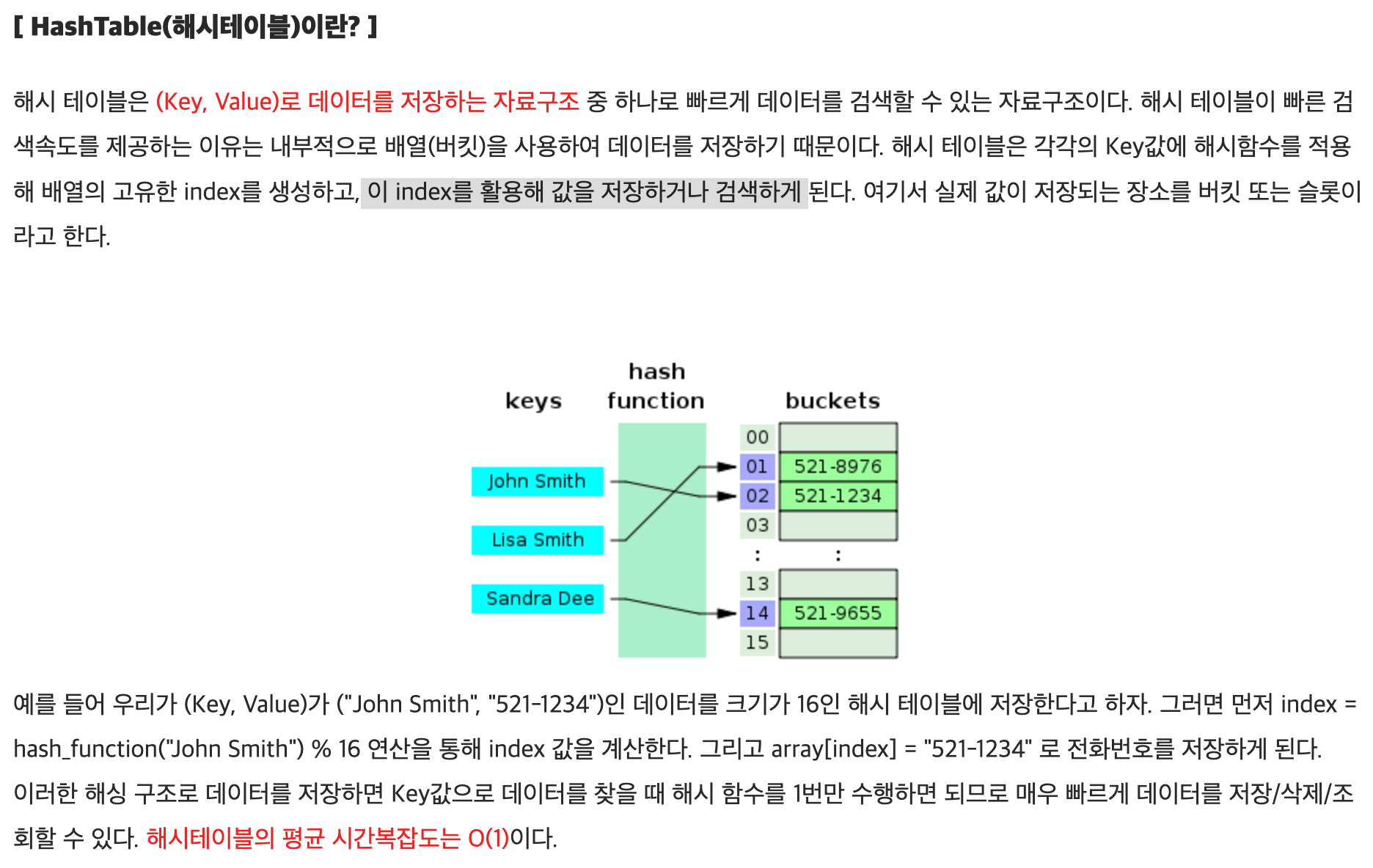
*-6. 해시 테이블
*-7. 파일 시스템
- 파일시스템 개념 : https://velog.io/@yuseogi0218/File-System-파일-시스템
- 파일시스템 종류 : https://wikidocs.net/232344
B-Tree를 사용하는 파일 시스템은 Btrfs(B-Tree File System)
(1) Btrfs

**용어
0. 검색키
인덱스가 기준으로 삼는 필드
0. 필드, 레코드
필드 = 컬럼 = 열
레코드 = 행
0. 실린더(Cylinder)
- 물리적인 하드디스크 저장 구조 단위
- 하드디스크에는 원판이 여러개 있고 각 원판에는 트랙이 있음
- 같은 위치의 트랙들을 위아래로 합친 것을 실린더라함
- 즉, 디스크에서 데이터를 연속적으로 읽을 수 있는 최소 단위
참고 자료
- https://code-lab1.tistory.com/217
- B-tree 개념, 데이터 삽입 영상 https://www.youtube.com/watch?v=bqkcoSm_rCs
- B-tree 삭제 방식 영상 https://www.youtube.com/watch?v=H_u28u0usjA
- B-tree 시간복잡도, secondary storage, DB index 영상 https://www.youtube.com/watch?v=liPSnc6Wzfk

하루살이