RCNN은 객체 분류(classification), 위치 특정(localization) 작업을 하는 대표적인 object detection model이자 2-stage-detector이다.
RCNN 모델의 부모모델이며 추후 RCNN의 속도를 보안한 Fast RCNN
anchor box 기법을 최초로 적용한 Faster RCNN 발표된다.
RCNN이란
RCNN이란 기존 CNN구조에 selective search 알고리즘을 통해 object로 판단되는 영역제안(region proposals)을 한 뒤 해당 RoI(region of interest)들을 연산하는 기법이다. 논문의 저자들은 PASCAL VOC 2007 데이터를 기준으로 기존의 방법들보다 mAP(mean average precision)이 30%이상 향상되었다고 한다.
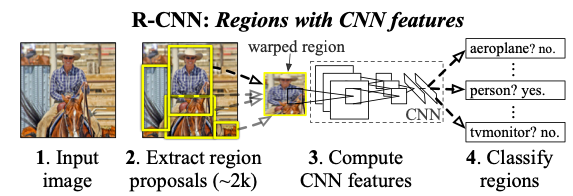
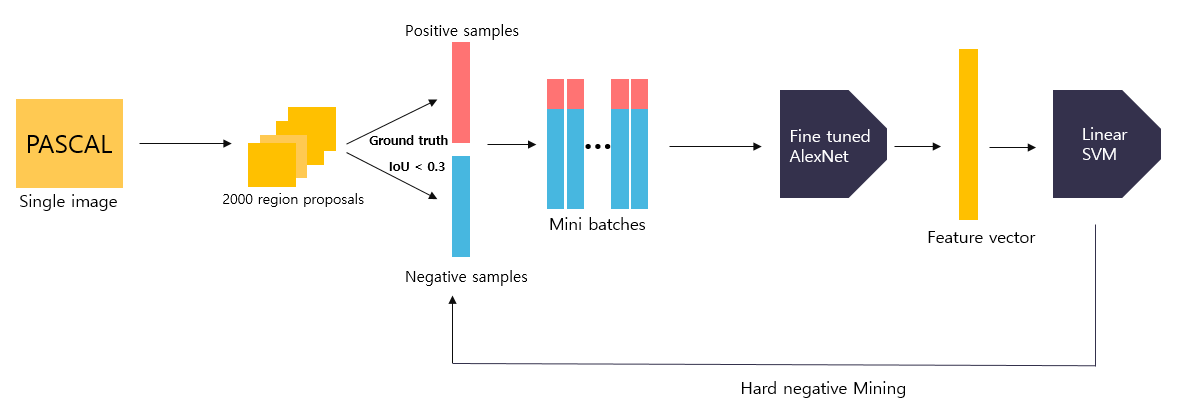
논문에서 RCNN의 pipe-line을 위의 사진으로 표현하고있다.
- 이미지를 입력받는다.
- 약 2천여개의 관심영역을 제안받는다
- 관심영역을 특정 크기로 warp시킨다
- warp된 feature들을 CNN연산시켜 feature vector를 추출한다
- 최종적으로 object의 class와 location을 계산한다
Cores of RCNN
- region proposlas
- CNN
- linear SVMs
- bounding box regressor
RCNN의 가장 핵심이 되는 3가지 기법이다. 하나씩 차근차근 알아보자
1. Region Proposals
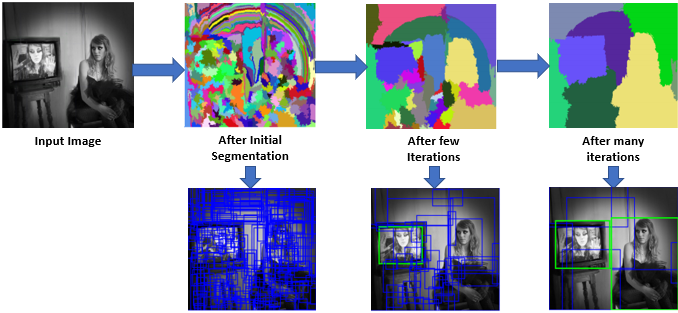
위는 region proposals의 pipe-line이다.
region proposals는 selective serach algorithm으로 super pixel기반의 selective search는 hierarchical grouping algorithm 방식을 사용하여 pixel간 유사도를 히스토그램으로 나타에어 연산하는 알고리즘이다. RCNN에서는 위 사진과 같은 방식으로 단일 이미지서 약 2천여개의 RoI를 추출한 뒤 227x227 사이즈로 warp(=resize)시켜 모델에 전달한다.
논문저자는 타이트한 original bonding box보다 16pixel씩 늘린 bonding box가 더 좋은 성능을 보인다고 설명한다
- bonding box란 object가 들어있거나 그렇다고 판단되는 임의의 사각형을 말한다 사진상에선 파란색, 초록색 박스가 모두 bonding box이다 나아가 초록색 박스는 ground truth box로 불리기도 한다.
2. CNN
RCNN에서도 고전적인 CNN기법을 사용하여 feature vector를 추출하며 RCNN은 backbone으로 ImageNet으로 pre-trained AlexNet을 사용하였다.
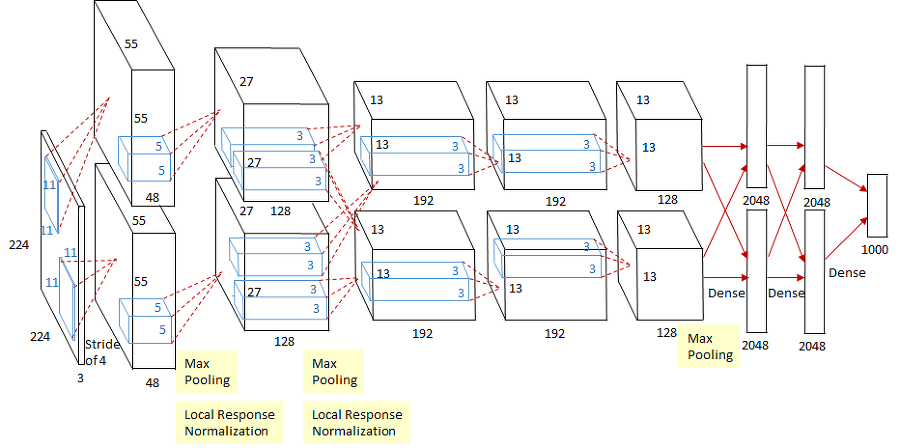
위 사진은 AlexNet의 architecture이다.
AlexNet은 연산속도를 높이기위해 2대의 GPU를 이용해 병렬연산을 진행하고 2번 convolution layer는 3번 convolution layer와 fully-connected되어있는 것이 특징이다
Domain-specific fine-tuning
보다 나은 성능을 위해 도메인에 맞게끔 fine-tuning을 해야한다고 논문에선 설명한다.
기존 ImageNet은 1000개의 class가 있지만 RCNN에서는 background까지 class에 추가하여 1001개의 class로 초기화한다. 논문에서 사용한 PASCAL VOC 2007는 총 20개의 클래스로 구성되어 있기때문에 21개의 class로 초기화한다고 설명하고있다.
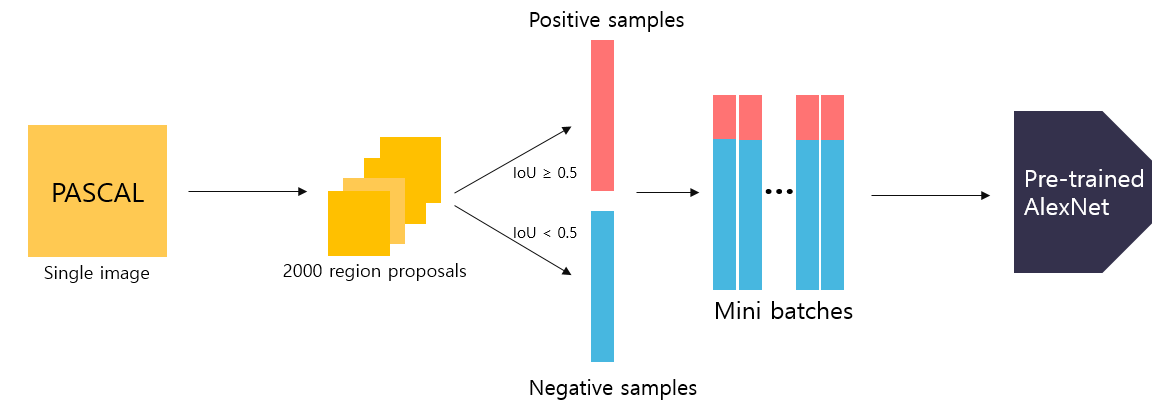
region proposals을 통해 입력받은 2000개의 feature들은 object를 포함할수도 아닐수도 있기때문에 연산을 통해 IoU가 0.5이상이면 positive samples 0.5미만이면 negative samples(background)로 구분하여
positive samples 32개 negative samples 96개로 구성된 mini-batch를 AlexNet으로 전달하여 fine-tuning한다.
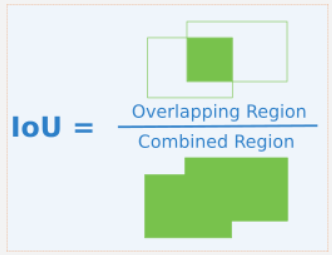
- IoU란 ground truth box와 predict bonding box 교집합의 넓이를 합집합의 넓이로 나눈 것을 말한다
- mini-batch는 SGD(stochastic gradient descent)기법을 사용할 때 train data를 임의의 크기로 나누어 모델에 전달할 때 쓰이는 용어이다.
- SGD를 사용하는 이유는 BGD(batch gradient descent)보다 훨씬 빠른 학습시간을 보여주기 때문이다.
- BGD는 train data를 한번에 모델에 전달하는 기법이다.
3. Linear SVMs
liner SVMs(support vector machine)모델은 2000(RoI의 수)x4096(각 RoI의 차원)의 feature vector를 입력받아 class와 각 class에 해당하는 confidence score를 반환한다.
print(output)
> (0, 1)
>> output[0] = lable map에 0의 ID를 가지는 class
>> output[1] = 존재 여부, 0 = False 1 = TrueSVMs모델의 특징은 해당 class의 여부만 판단하는 이진분류기(binary classifier)
이기 때문에 (N+1)개의 톡립적인 SVMs를 학습해야한다는 것이다.
SMVs모델의 학습 과정은 다음과 같다.
전반적인 pipe-line은 AlexNet을 fine-tunning할 때와 비슷하지만 몇가지 차이점이 있다.
- positive sample은 ground truth box만 사용하고 IoU가 0.3미만은 negative sample, 0.3이상은 무시한다.
- 한 번의 사이클이 끝난 후 hard negative mining기법으로 재학습한다.
여기서 궁금증이 든다.
- data분류의 기준이 AlexNet과 Linear SVMs이 다른이유
- 왜 softmax가 아닌 SVMs을 classifier로 채택하였나
- hard negative mining기법은 무엇인가.
먼저 1,2번의 궁금증은 논문의 Appendix B. Positive vs. negative samples and softmax에서 설명하고있다.
- 저자는 AlexNet을 fine-tuning할 때는 overfiting을 방지하기위해 많은 양의 data가 필요하다고 서술한다. IoU가 0.5이상인 feature-map을 positive sample로 분류한다면 ground truth box만을 positive sample로 분류했을 때 보다 30배 이상의 train data를 얻을 수 있다고 말한다.
- softmax를 사용했을 때, SVMs을 때 mAP가 각각 50.9%, 54.2%로 본인들이 고안한 "hard negative"기법을 이용한 SVMs classifier가 더 좋은 퍼포먼스를 보여줬기 때문이라고 설명한다.
3.1 Hard Negative Mining
hard negative mining이란 쉽게 말해 모델이 구별하기 힘든 sample들을 epoch마다 추가해 학습시키는 기법이다.
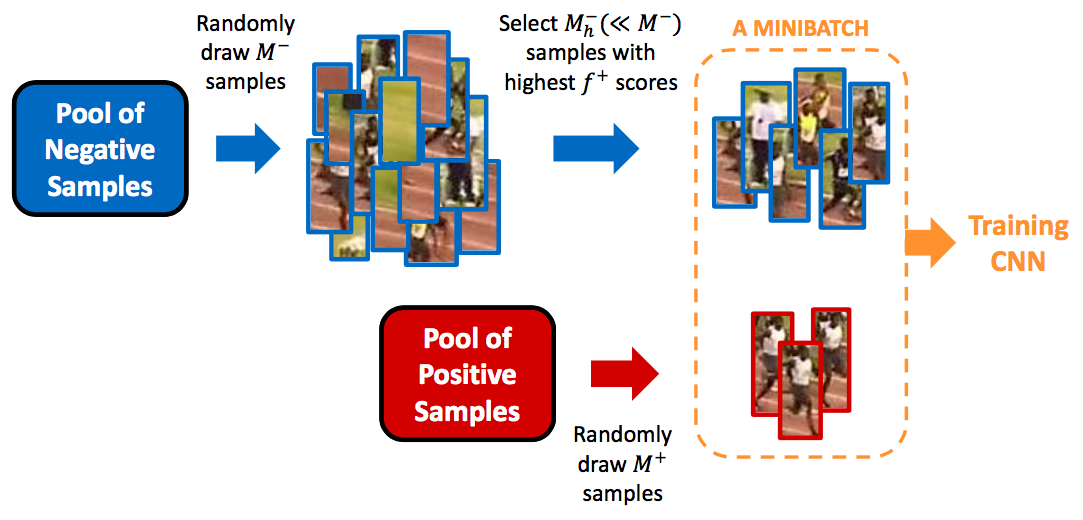
예를들어 위 사진처럼 사람을 detecting한다면 sample을 분류하는 기준은 다음과 같다.
사람을 사람으로 -> TP(true positive)
사람을 배경으로 -> FP(false positive)
배경을 배경으로 -> TN(true negative)
배경을 사람으로 -> FN(fasle negative)
object detection 과정에서 positive sample보다 negative sample이 압도적으로 많기 때문에 클레스 불균형(class imbalence) 문제로 모델들은 FP를 많이 검출하게 된다. 그렇기 때문에 논문의 저자들은 hard negative mining기법을 통해 FP sample들을 추가해 학습시켜 모델의 신뢰도를 높인다고 설명한다.
4. Bounding Box Regressor
selective search를 통해 얻어진 bounding box와 실제 bounding box에 오차가 존제할 수 있기 때문에 bounding box regressor 모델을 통해 오차를 보정해주는 작업을 한다.
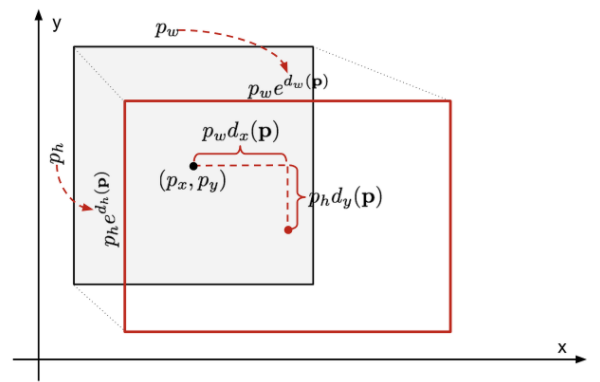
검은 태두리의 박스가 모델이 예측한 박스의 x,y 좌표와 w,h (width, height)이고 빨간 태두리의 박스가 bounding box regressor를 통해 오차를 보정한 박스의 좌표와 길이와 높이이다.
개의 bounding box에 대해 개의 짝을 가지며
prediction value (예측값),
ground truth value (실제값)이다.
다음은 bounding box regressor의 계산 공식이다.
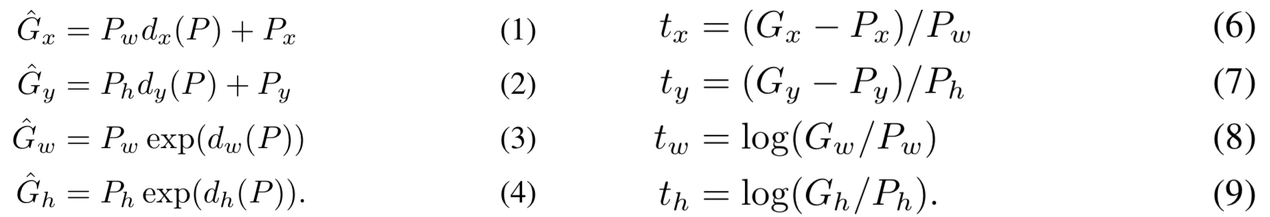
공식1
= 각각 bounding box regressor를 통과한 ground truth 예측값
= bounding box regressor 통과 전 예측한 값
= bounding box regressor의 학습대상(예측 오차)
= target(학습 목표, 실제 오차)
여기서 우리는 regressor 통과전 예측값을 알고 있기때문에 학습하여야 할 변수는
뿐이다.
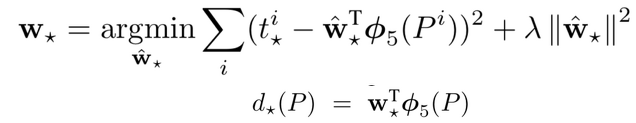
공식2
최종적으로 다음과 같은 식 loss function을 도출 할 수 있다.(ridge regressor)
= 최종적으로 업데이트 될 weight(가중치)
= 실제 오차
= = bounding box regressor의 학습대상(예측 오차)
(논문상)
LSM(Least Square Method, 최소제곱법)과 L2 norm * 로 제약을 준
loss function이다
None Max Suppression
직역한다면 비최대 억제로 앞서 RCNN은 2000여개의 bounding box를 연산한다 그 중 back ground로 판단한 bounding box 제외한 나머지들은 모두 confidence score와 class ID를 리턴받는다. 해당 bounding box를 모두 시각화한다면 output image는 매우 지저분할 것이다.


위에서부터 NMS를 적용 전, 후 모습을 나타낸 사진이고 아래 사진은 모델이 차로 예측한 confidence score를 시각화 한 사진이다.
과정은 다음과 같다.
- class별 score_threshold 이하의 confidence score를 가지는 bounding box는 제거한다.
- confidence score를 기준으로 내림차순으로 정렬한다.
- confidence score가 높은 순서대로 나머지 bounding box와 비교하여 IoU점수가 IoU_threshold보다 이상이면 제거한다
- 위 과정을 반복하여 최적의 bounding box를 도출한다.
RCNN의 의의와 한계
논문 리뷰를 하며 RCNN의 구조와 학습과정, 사용기법들을 알아보았다. object detection을 배우면 최초로 공부하게되는 RCNN이지만 pipe-line이 복잡하기 때문에 난이도가 상당이 높다. RCNN의 의의와 한계를 끝으로 리뷰를 마친다.
의의
- 최초로 neural network방식 즉 인공지능 방식으로 object detection을 구현한 모델이다
- RCNN의 단점을 보완하기위해 여러가지 기법들이 등장하였다.
단점
- 3단계의 process를 거치며 classfication과 localization 문제를 따로 처리하기 때문에 end-to-end학습이 불가능하다.
- region proposals의 selective search는 cpu 알고리즘이기 때문에 느리다.
References
한국IT교육원 2023년 2월 20일 ~ 2023년 2월 24일
Based on Andrew ng - DeepLearningAI
RCNN paper link
https://herbwood.tistory.com/5
https://velog.io/@skhim520/R-CNN-논문-리뷰
https://bigdata-analyst.tistory.com/269
