Fast RCNN
Fast RCNN은 RCNN의 고질적 문제인 속도와 end-to-end 학습이 불가능하다는 것을 보완한 모델로 논문에서는 GPU를 사용여도 VGG16기반의 RCNN은 test time에서 47초가 소요되던 것을 약 10~100배 단축, traing time을 3배 단축하였고 multi-task loss를 사용해 classification과 localization을 한번에 학습한다고 설명합니다.
RCNN에 대한 내용은 여기서 확인해 주세요.
Architecture
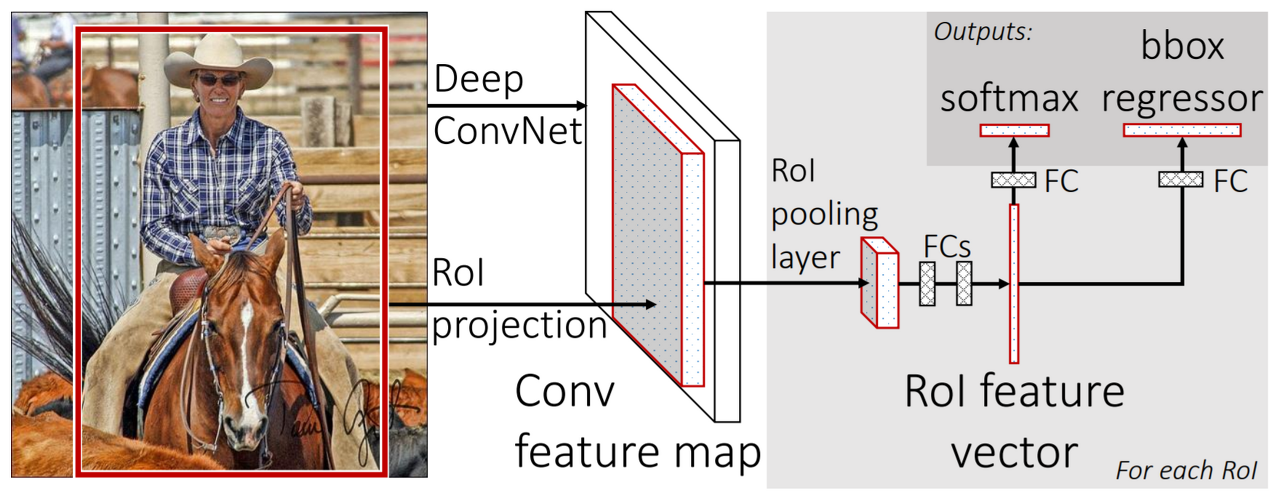
사진 1
가장 눈에 띄는 것은 warp된 RoI를 입력받는 것이 아닌 이미지 전체와 RoI 전체를 ConvNet에 입력받는 것이다. 또한 SVMs를 사용하지 않고 activation함수를 softmax 사용하여 end-to-end 학습이 가능하게 되었다.
그 다음 눈에 띄는 다른 것은 RoI pooling layer인데 아래단에서 알아보자.
- selective search를 통해 RoI 추출
- 추출한 RoI를 warp(crop,resizing)없이 모델에 전달
- RoI pooling layer를 통해 고정된 크기로 pooling
- softmax 함수에선 class를 bbox regressor에선 location을 연산
RoI Pooling Layer
간략히 요약하자면 RoI pooling layer는 입력받은 RoI를 고정된 크기의 feature map으로 max pooling하는 layer이다.
사진 2
RoI pooling의 과정이다 이 때 RoI는 (r,c,h,w)형태의 튜플값을 가지며 (x,y), (h,w)는 각각 좌상단 좌표(left top), (h,w)는 넓이(높이, 너비)이며 window의 크기는 H, W에 따라 달라지기 때문에 하이퍼파라미터에 해당한다.
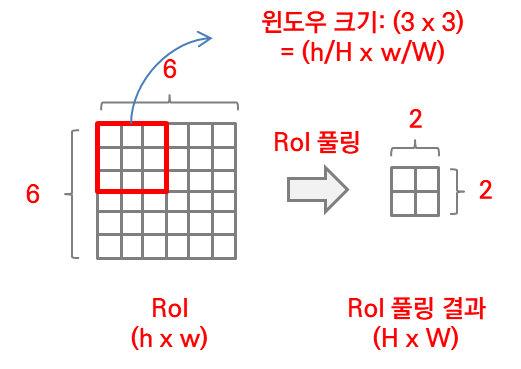
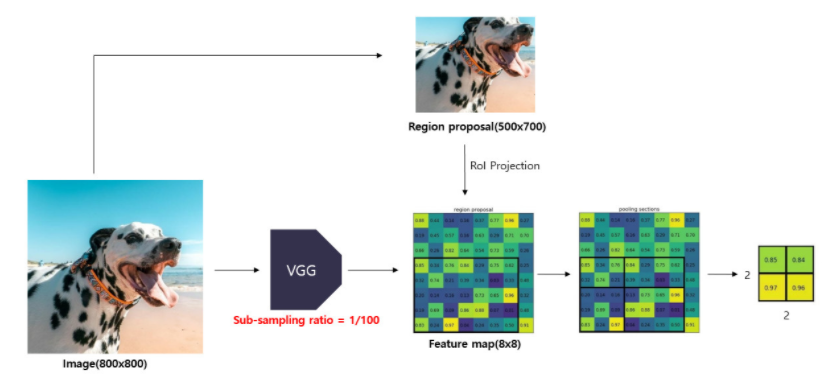
사진 3
위에서 설명하였듯 Fast RCNN은 이미지 전체와 RoI 전체를 입력받는다. 사진3과 같이 800x800사진을 1/100로 sub-sampling한다면 최종적으로 8x8의 feature map을 얻을 수 있다. 이 때 RoI가 500x700이라면 5x7의 feature map을 가지게 된다. 이제 원본 이미지를 pooling한 feature map에 RoI를 투영한 뒤 사진2와 같이 고정된 크기의 window에 맞추어 grid를 나눈뒤 max pooling을 진행한다.
Initializing from Pre-trained Networks
Fast RCNN은 back born으로 VGG16을 사용한다. 해당 모델은 classfication모델로 object detection을 수행하기 위해 몇가지 수정이 필요하다.
- 마지막 pooling layer를 RoI pooling layer로 변환
- output layer에 bbox regressor layer 추가
- 모델이 image와 RoI데이터(좌표)값을 받을 수 있게 한다
Fine-tuning for Detection
Fast RCNN의 가장 큰 특징 중 하나는 classification, localization을 한 번에 학습하는 것이다. SPPnet은 spartial pyramid layer 이전의 Conv layer는 학습하지 못한다. 각각의 RoI가 다른 이미지에서 올 때 비효율적이기 때문이다(노이즈가 많이 낌). 각 RoI가 굉장히 큰 receptive field를 갖기 때문이다. RoI가 input image에 많은 부분을 차지하기 때문이며 때로는 이미지 전체가 RoI이기 때문이다.
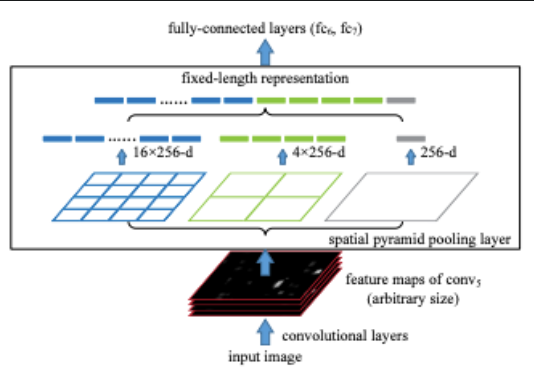
사진 4
SPPnet의 핵심이 되는 SPP layer의 architecture이다.
각각 의 고정된 크기로 pooling 해 1x256, 4x256, 16x256의 feature map들을 merge하여 FC layer로 전달한다.
논문의 저자들은 R-CNN 모델은 학습 시 region proposal이 서로 다른 이미지에서 추출되고 이로 인해 학습 시 연산을 공유할 수 없다는 단점을 보완하기 위해 hierarchical sampling 방법을 제시한다.
hierarchical sampling란 SGD mini-batch sapmle을 통해 N개의 이미지를 셈플링하고 각 이미지에서 R/N개의 RoI를 추출한다. 여기서 중요한 점은 동일한 이미지에서 추출한 RoI는 forward and backward passes에서 연산결과와 메모리를 공유한다는 점이다. 또한 N을 줄이면 mini-batch계산 속도가 빨라지며 예를 들어 N = 2 R = 128일 때 RCNN, SPPnet보다 64배 빠르다고 논문저자는 설명한다.
Multi-task Loss
Fast RCNN은 class와 bbox를 한 번에 학습하기 때문에 독자적인 loss function이 필요하다.
- 개의 class 예측값
- ground truth class score 실제값
- bbox 예측 좌표값
- ground truth bbox 좌표값
- classification loss(Log loss)
- balancing hyperparamter(논문에선 1)
- 가 1 이상일 때만(object) loss를 계산
- bbox regressor loss
Mini-batch sampling
논문에선 2개의 이미지에서 64개의 RoI를 추출하여 128개의 mini-batch를 생성하여 ground-truth bounding box와 IoU 0.5이상의 RoI를 25% 가져와 foreground object class(<=> background class)로 라벨링 한다. 즉 이 된다. 0.1~0.5 미만은 back ground로 이다. 또한 data agumentation을 위해 50% 확률로 좌우 대칭한다고 설명한다
마치며
Fast RCNN은 RCNN의 가장 고질적인 문제였던 end-to-end로 학습이 불가능한 점을 보완하여 학습 시간과 테스트 시간을 획기적으로 줄인 모델이다. 하지만 여전히 selective search를 사용하기 때문에 real-time object detection 모델로 사용하기엔 무리가 있다. 해당 약점을 보완하기 위해 Faster RCNN에서는 현재 OD의 기반이 되는 Anchor box의 개념이 처음 도입되었다.
Reference
한국IT교육원 2023년 2월 27일 ~ 2023년 3월 3일
based on Andrew Ng - DeepLearningAI
Fast R-CNN paper
Fast R-CNN 논문 리뷰
논문 리뷰 - Fast R-CNN 톺아보기
