기존 OD 모델들의 문제점은 background가 foreground 보다 압도적으로 많아 학습을 비효율적으로 진행한다. 2-stage 모델은 이를 해결하기 위해 region proposal을 통해 일반적으로 background : foreground를 1:3으로 sampling 하여 loss를 구한다. 이는 높은 정확도를 보여주지만 pre-processing 과정에서 많은 시간이 소요된다. 1-stage 모델은 pre-processing 과정을 생략하고 이미지 전체를 받아 각 feature map의 grid 마다 확률을 계산하여 detecting 시간은 짧지만 정확도는 낮게 나타난다.
이는 압도적은 class imbalance 때문에 발생한다.
RetinaNet은 이를 해결하기 위해 새로운 loss function을 제안한다.
Focal Loss
Focal loss는 1-stage detector가 가지는 class imbalance 현상을 해결하기 위해 고안된 loss function이다.
일반적으로 binary classification에서 사용되는 CE(cross entropy loss function)를 이용하였다.
ground truth class이면 1 background이면 -1
모델이 예측한 y=1일 확률
해당 loss function은 모든 sample에 똑같은 가중치를 적용한다. 1-stage detector는 이를 처리하기 위한 pre-processing이 없기 때문에 압도적인 수의 easy-nagative sample들이 non-trival한 loss를 유발하여 rare class를 압도한다.
- easy sample, hard sample 이란 직역하면 모델이 예측하기 쉬운 샘플, 어려운 샘플로 IoU나 probabilty가 threshold 보다 확연히 높거나 낮고 true positive, true negative 이면 easy sample이 되며 두 조건 중 하나라도 반대의 조건을 가지면 hard sample이다.
- rare class는 object를 뜻한다. 생성된 anchor들 중 object class는 non-object class보다 압도적으로 작기 때문에 rare class로 표현한 것 같다.
Balanced Cross Entropy
class imbalance 문제를 해결하기 위해 사용되는 일반적인 방법은 에 weighing facor 를 곱해주는 것이다. 는 inverse frequence cross validation으로 인해 결정된다. 즉 빈도수가 높으면 작게 낮으면 낮으면 크게 설정한다.
논문에선 해당 식을 balance라 칭하고 baseline으로 실험을 진행했다.
Focal Loss Definition
balance는 positive/negative sampling에선 중요한 역활을 하지만 easy/hard sampling에선 그렇지 않다. 때문에 easy sample에 대해선 down-weight를 적용해 hard sample에 중점적으로 학습 할 수 있도록 를 reshape 하였다.
논문의 저자는 를 moduling factor로 focusing parameter로 칭한다.
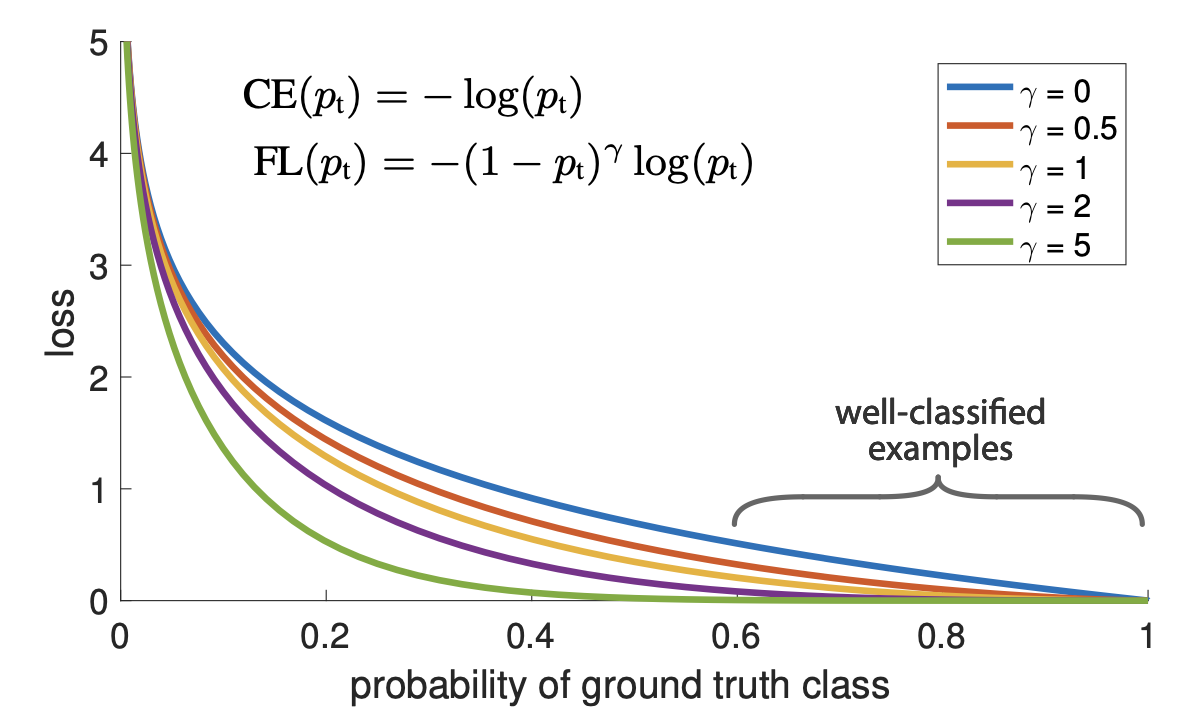
에 따른 그래프이며 파란선은 를 나타낸다.
이를 통해 Focal loss의 2가지 특성을 알 수 있다.
- example이 misclassified 되거나 가 0로 다가가면 moduling factor는 1에 근사하여 loss에 영향을 주지 않는다.
반대로 이 1에 다가가면 moduling factor는 0에 근사하며 well-classified example은 weight-down된다. - focusing factor 는 down-weighted의 정도를 조절한다.
논문의 저자는 가 가장 좋은 성능을 보인다고 설명한다.
일 때 Focal loss는 기존 CE보다 100배 작은 loss를, 이면 1000배 더 적은 loss를 가진다.
논문의 저자는 훈련에서 balance를 Focal loss에 적용하여 사용하였다고 설명한다.
Class Imbalance and Model Initialization
binary classification model은 기본적으로 -1또는 1의 동일한 확률을 출력하도록 초기화한다. 이러한 초기화 방식은 빈도수가 높은 class의 loss 때문에 total loss가 지배되며 초기 훈련에서 불안정하게 작동할 수 있다. 이러한 문제를 해결하기 위해 traning이 시작할 때 모델이 예측한 (foreground)의 값을 'prior' 컨셉을 적용한다. prior를 로 표기하고 모델의 예측값 가 작아지게 설정한다.(논문에선 0.01) 논문의 저자는 해당 initialization이 CE, FL에서 heavy class imbalance를 개선한다고 말한다.
RetinaNet Detector
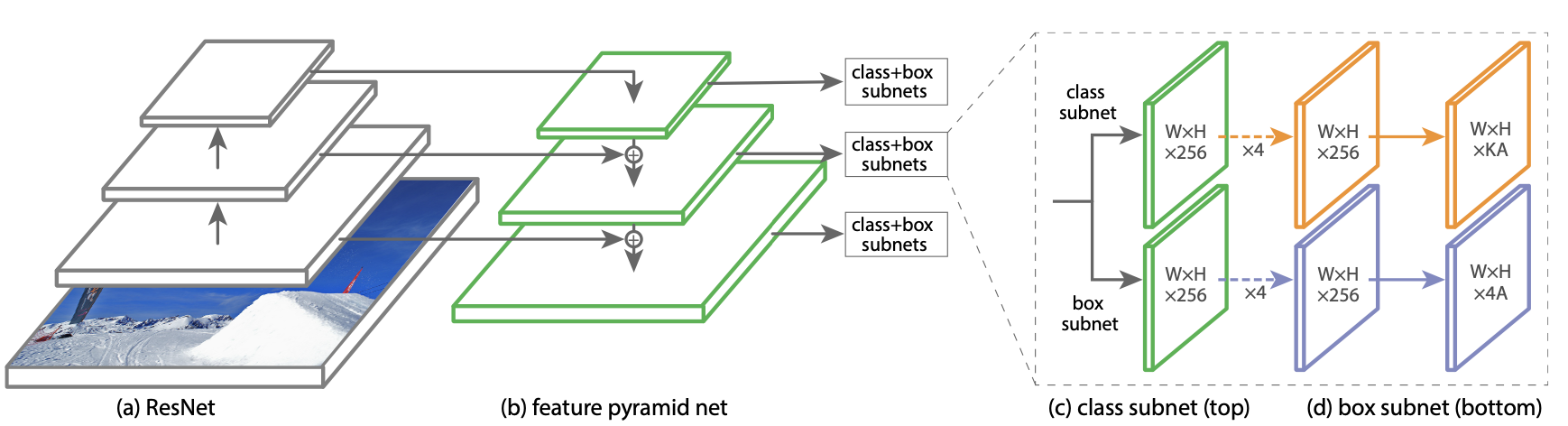
RetinaNet은 1개의 backbone network와 2개의 task-specific subnetwork가 통합된 하나의 network이다. backbone에선 convolutioal feature map을 추출하고 subnetwork는 classification과 box regression를 수행한다.
Feature Pyramid Network Backbone
RetinaNet은 FPN과 몇 가지 차지만 있을 뿐 거의 동일한 구조를 가진다. 먼저 RetinaNet은 level의 feature map을 사용하며 channel = 256으로 모든 level에서 동일하다. (pyramid level을 로 표시 할 때 input image에 비해 씩 작아진다)
Anchors
각각의 anchor는 에서 크기를 가진다. 이 때 기본적으로 3개의 aspect ratio {1:2, 1:1, 2:1} 가지고 논문 저자들은 의 aspect ratio 추가하여 각 pyramid level grid 마다 9개의 anchor box를 생성한다.
각 anchor는 target class의 길이만큼의 one-hot-vector와 4-vector of regresstion target가 할당된다 이 때 class의 길이는 로 나타낸다. GT와의 IoU가 0.5 이상이면 ground-truth로 사용하고 IoU가 0 ~ 0.4 background로 사용하고 0.4 이상 0.5 미만의 box는 무시된다. 각 anchor는 최대 하나의 object를 가지며 해당하는 class를 vector에서 1로 표시하고 나머지는 0으로 표시한다.
Classification Subnet and Box Regression Subnet
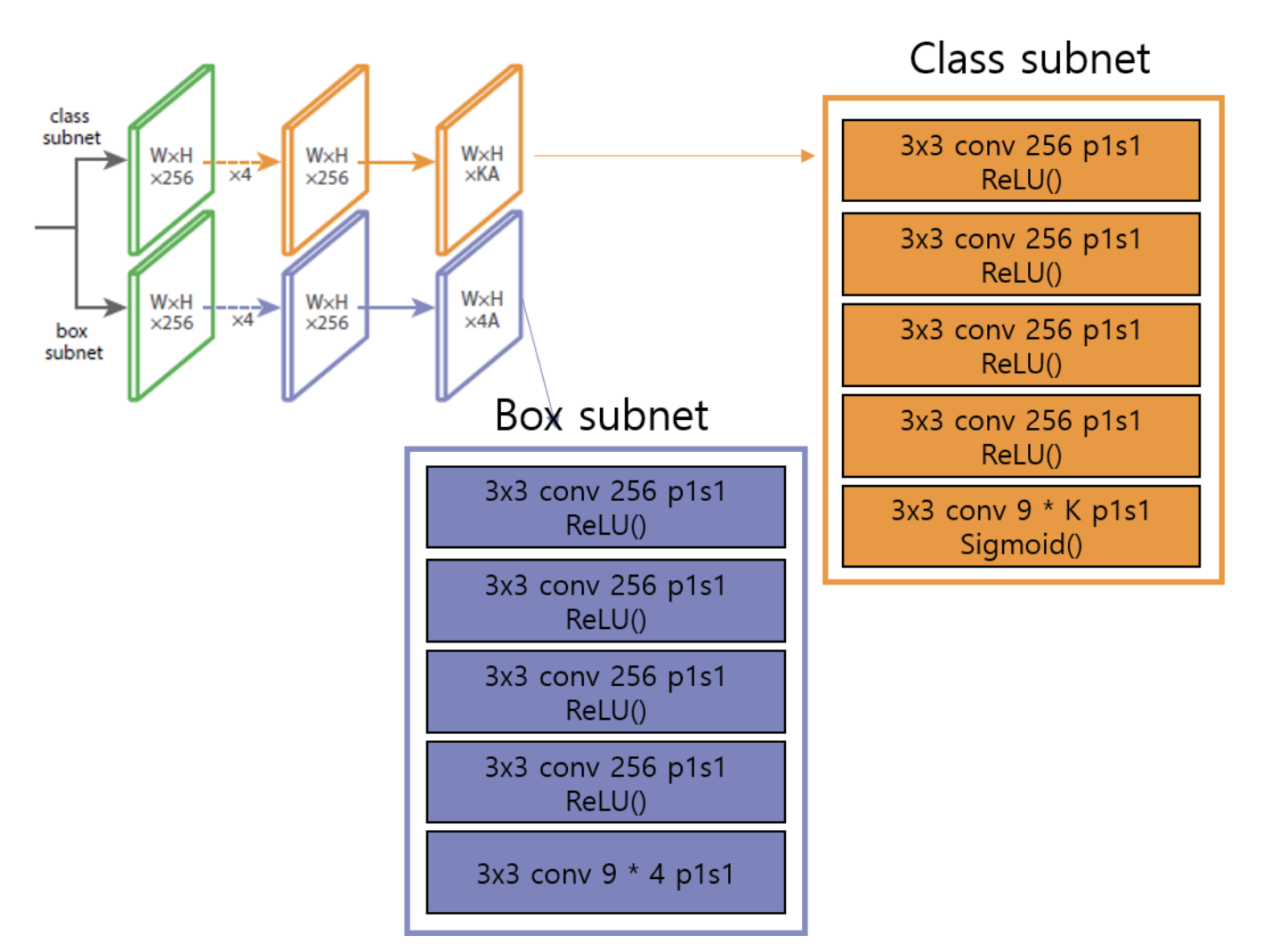
FPN을 거친 후 각 featrue map은 classification, box regression subnet으로 전달된다 각각의 subnet은
conv layer와 ReLU를 4번 반복하며 최종적으로 의 출력을 가진다. 이 때 각 subnet은 parameter를 공유하지 않는다.
Inference and Training
Inference
논문저자는 속도 향상을 위해 각 pyramid level에서 상위 1000개의 box만 decode하여 merge 후 NMS를 적용해 최종 결과를 도출한다. (threshold = 0.5)
Focal Loss
total Focal loss는 all ~ 100K 의 anchor box의 합해 ground truth box의 갯수로 normalization하여 구한다. 전체 anchor로 하지 않는 이유는 대부분의 easy sample들은 Focal loss에선 매우 작게 나타나기 때문이다. 마지막으로 실험을 통해 가 가장 좋은 성능을 보인다고 설명한다.
Initialization
backbone으로 ImageNet으로 pre-train된 ResNet-50-FPN과 ResNet-100-FPN 사용하며 RetinaNet subnet에 추가된 conv layer들은 마지막 layer를 제외하고 bias , weight 인 가우시안 분포로 초기화하며 classiffication subnet의 마지막 conv layer는 로 초기화한다. 여기서 학습 시작 시 의 confidence로 모든 anchor들은 foreground로 labeled된다. 실험에서 을 사용했다. 이러한 초기화 방법은 학습 초기 불안정을 방지한다.
Reference
한국 IT 교육원
based on Andrew Ng
Focal Loss for Dense Object Detection paper
RetinaNet 논문(Focal Loss for Dense Object Detection) 리뷰
RetinaNet 논문 리뷰
[Object Detection] RetinaNet (Focal Loss) 논문리뷰 및 코드구현(ICCV2017)

좋은 글이네요. 공유해주셔서 감사합니다.