기존 OD 모델들은 accuracy와 efficiency는 trade-off 관계를 유지하였고 state-of-the-art 모델들은 accuracy에 집중하여 크기가 매우 크다. 이러한 문제로 일반 사용자들이 사용하는 application에 적용하기엔 무리가 있었다. EfficientDet은 parameter 수를 줄이고 FPN 기법을 수정하여 accuracy와 efficiency를 모두 잡았다.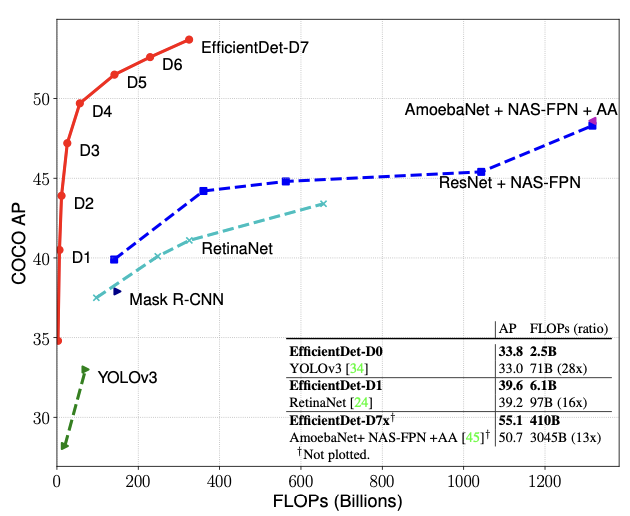
Challenges
1. Efficient Multi-scale Feature Fusion
PANet, NAS-FPN과 같이 FPN 구조를 사용하는 모델들은 multi scale feature fusion을 할 때 다른 resolusion의 feature map을 단순히 sum하였다. 이는 output에 악영향을 미치는 것을 확인하였다. 이를 위해 BiFPN(bi-direction FPN) 기법을 제안하며 이는 다른 resolusion의 feature map마다의 중요한 특성을 학습할 수 있다고 설명한다.
Model scaling
기존까지는 높은 accuracy를 위해 큰 backbone을 가지거나 높은 resolution image를 모델에 전달하였다. 하지만 accuracy와 efficiency를 고려한다면 매우 치명적으로 작용한다. 때문에 저자들의 이전 논문인 classiffication model인 EfficientNet에서 영감을 받아 composed scaling 기법을 detection model에도 적용하였다.
BiFPN
Problem Formulation
multi scale feature fusion은 feature를 aggregate하는 것에 집중한다.
공식으론 다음과 같이 나타낸다.
이 때 는 level에서의 input feature map을 나타낸다.
으로 나타내고자 할 때 가장 효과적으로 feature들을 aggregate하는 를 찾는것이 목표이다.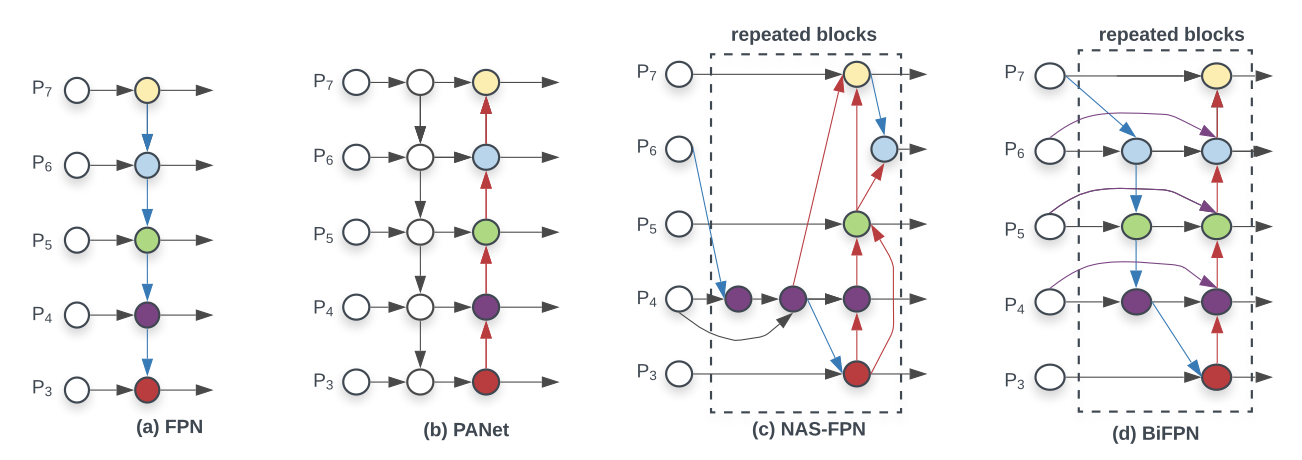
사진과 같이 BiFPN은 기존 NAS-FPN의 방식을 uniformly하게 배치한 구조를 가진다.
논문에선 level 3 ~ level 7 feature를 사용하고 각 level의 feature들은 FPN과 마찬가지로 만큼 downscaling된다. 각 feature들은 다음과 같이 표현한다.
는 resolusion에 맞추어 upscaling 혹은 downscaling 으로 mapping되며 는 보통 convolusion 과정이다.
Cross-Scale Connections
FPN은 본질적으로 feature의 정보들이 한 방향으로만 전달되는 한계가 있다. NAS-FPN은 이를 해결하기 위해 cross-scale feature network topology를 위해 neural architecture search 방식을 도입하였지만 이는 수 천 시간의 GPU hour와 FLOPS를 요구하고 이해하거나 수정하기 어렵다.
(a,b,c)를 연구하며 PANet이 NAS-FPN보다 더 좋은 accuracy를 보여주지만 더 많은 cost를 동반한다.
해당 논문에선 cross-scale connection을 최적화 하는 몇가지 방법을 제시한다.
- 1개의 input을 가지는 node는 삭제한다. 논문에선 feature network 상에서 기여하는 바가 작기 때문이라고 설명한다.
- 같은 level에 있는 merge된 output featue map에 original feature map을 더해준다.(사진상 왼쪽의 흰색 node를 오른쪽 node에 더해주는 것) 이는 cost를 많이 증가시키지 않는다고 설명한다.
- 해당 과정을 하나의 feature network layer로 생각하고 해당 과정을 여러번 반복한다.
Weighted Feature Fusion
기존의 scaling 방식은 모든 feature들을 똑같이 여기고 단순히 resolusion만 맞추어 더하거나 global self-attention upsampling을 하였다. 하지만 논문의 저자들은 다른 resolution의 다른 feature는 output에 똑같이 기여하지 않는 것을 연구로 알게되었다. 이를 해결하기 위해 각각의 input마다 가중치를 더해주었다.
Unbounded fusion
는 scala(per freature), vector(per channel), multi-dimensional tensor(per pixel)등이 될 수 있다. scala가 가장 작은 cost를 가지지만 무수히 많기 때문에 학습에 불안정성을 초례할 수 있다. 때문에 각 weight마다 유한한 범위로 normalization을 한다.
Softmax-based fusion
unbounded fusion의 문제를 해결하기 위해 를 softmax 함수에 대입하는 것이다. 그러면 0과 1사이의 확률값으로 normalization이 된다. 하지만 이러한 추가적인 softmax 활용은 GPU를 감속시킨다.
Fast normalized fusion
ReLU를 적용하여 하게 제한하고 numerical instability를 피하기 위해 로 아주 작은 값을 추가해 분모에 추가한다. 그러면 softmax를 적용한 것과 비슷하게 0과 1사이의 값으로 normalization되며 GPU에서 30% 빠르게 동작하기 때문에 보다 효율적이다.
최종적으로 level 6에서 bidirectional cross feature fusion과 fast normalization fusion을 적용한 식은 다음과 같다.
EfficientDet
EfficientDet Architecture
EfficientDet은 1-stage detector로 ImageNet으로 pre-train된 EfficientNet을 backbone으로 사용한다. feature network로 BiFPN을 사용하고 level 3~7의 feature를 사용하여 class/box prediction을 수행한다. 이 때 weights는 모든 feature level에서 공유한다.
Compound Scaling
이전의 모델들은 backbone의 크기를 키우거나 큰 input image를 사용 또는 FPN layer를 더 쌓는 방식으로 발전했다. 이러한 방식들은 scaling 크기를 제한하거나 단일화 된 크기로 하기 때문에 비효율적이다. EfficientDet은 EfficientNet와 같이 compound coefficient 를 추가해 width, depth, resolution을 모두 scale up 함으로써 성능을 높혔다.
BiFPN network
depth 은 BiFPN layer의 갯수로 정수값으로 나타내어야 한다. 은 BiFPN에 입력되는 channle로 각각 compound coefficient와 scaling factor를 사용하여 다음과 같이 scaling된다.
특히 scaling factor는 의 후보들이 있었지만 grid search를 통해 1.35가 최적의 scaling factor라고 설명한다.
Box/class prediction network
Box/class prediction network의 channel은 항상 BiFPN의 channel과 동일하게 고정하지만() depth는 linear하게 증가시킨다.
Input image resolution
BiFPN에서 feature level을 3-7로 설정했기 때문에 로 나눠지도록 input image resolution을 다음과 같이 scaling한다.
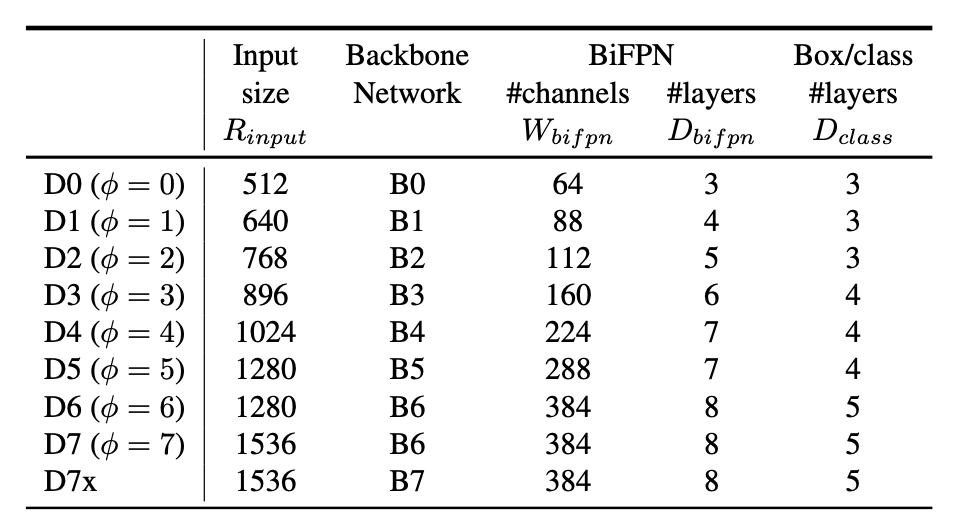
다음의 식들을 가지고 를 바꾸어가며 EfficientDet-D0 ~ D7까지 개발하였으며 최종적으로 다음과 같다.
Reference
한국 IT 교육원
based on Andrew Ng
BiFPN (Bi-directional Feature Pyramid Network) 구조와 코드
[논문 리뷰] EfficientDet: Scalable and Efficient Object Detection
EfficientDet 논문(EfficientDet: Scalable and Efficient Object Detection) 리뷰

공감하며 읽었습니다. 좋은 글 감사드립니다.