SDD
SDD는 Yolov1의 뒤를 잇는 1-stage detection 모델이다.
기존 Yolo는 Faster RCNN에 비해 6배 이상의 속도를 보여주었지만 bbox의 위치가 다소 부정확한 모습을 보여주었다. 이를 보완하기위해 Default box와 pooling layer마다 featrue map을 classifier에 전달하여 속도와 정확도를 높혔다.
Model
SSD의 기본적인 구조는 여느 모델들과 비슷하다. 고정된 크기의 bbox에 class의 존재여부를 점수화하고 최종적으로 NMS를 적용하여 최종 결과를 보여준다.
또한 base network(backbone -> VGG16)을 사용하여 conv연산을 진행 후에 본인들의 auxiliary structure를 network에 전달한다.
Multi-scale feature maps for detection
base network에 auxiliary structure를 추가하여 해당 structure를 통과한 각각의 feature map을 classifier에 전달한다. 이 때 각각의 classifier의 bbox는 서로다른 aspect ratio와 갯수를 가진다.
Convolutional predictors for detection
저자는 conv filter를 사용하여 고정된 크기의 detection prediction을 가지며 가장 포텐셜이 높은 것은 3x3xp(channels)이며 이를 통해 class score와 default box 좌표의 offset을 알 수 있다고 설명한다.
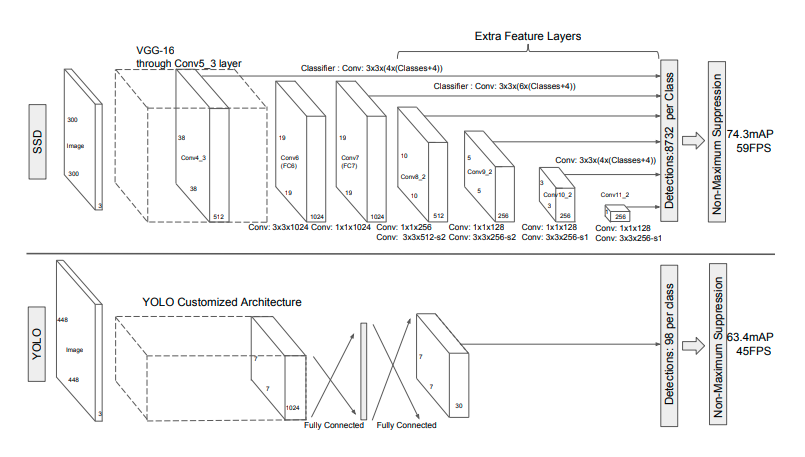
논문속 SSD와 Yolo를 비교한 사진이다.
SSD의 핵심 아이디어 한눈에 알아볼 수 있다. 먼저 일정 conv layer이 후 부터 feature map의 scale이 줄어 들 때 마다 detection을 진행한다. 이 때문에 다양한 크기의 object를 검출 할 수 있고 신뢰도를 높였다.
또 FC layer를 없애고 conv layer로 대체하여 연산속도를 높였다.
- Conv5_3: VGG16 5번째 conv block에 3번째 layer이며 사용한 이유는
단순히 가장 좋은 결과를 보여주기 때문이다.- Conv 에서 은 defualt box의 수.
- Conv6와 Conv7은 하나의 conv block이며 뒷 부분에는 생략되어 있다.
- Conv8부터 1x1 conv 연산으로 채널수를 줄였다 늘렸다를 반복한다.
- s1, s1은 stride를 뜻하며 s2는 stride = 2, s1은 stride = 1이다.
Traning
Matching strategy
dafault box는 다양한 aspect ratio, scale, location을 가지기 때문에 어떤 default box가 ground truth에 매칭되는지를 찾는 방식으로 학습된다.
최종적으론 최상의 Jaccard( IoU)를 찾는 것을 목표로 하지만. 학습 문제를 단순화 하기위해 IoU가 가장 높은 bbox를 찾는 것이 아닌 우선 IoU가 0.5이상인 bbox를 모두 선택한다.
Training objective
SSD의 학습 목표는 Multibox에 영감을 받았지만 여러 category를 처리하기위해 조금 확장하였다.
Overall loss function

SSD의 전체 loss function이다.
location loss와 confidence loss의 합으로 정의하였으며 location loss는 이고 confidence loss는 softmax를 사용하였다.
= 매칭된 default box의 수()
= balancing hyperparameter이며 기본적으로 1.
Localization loss function
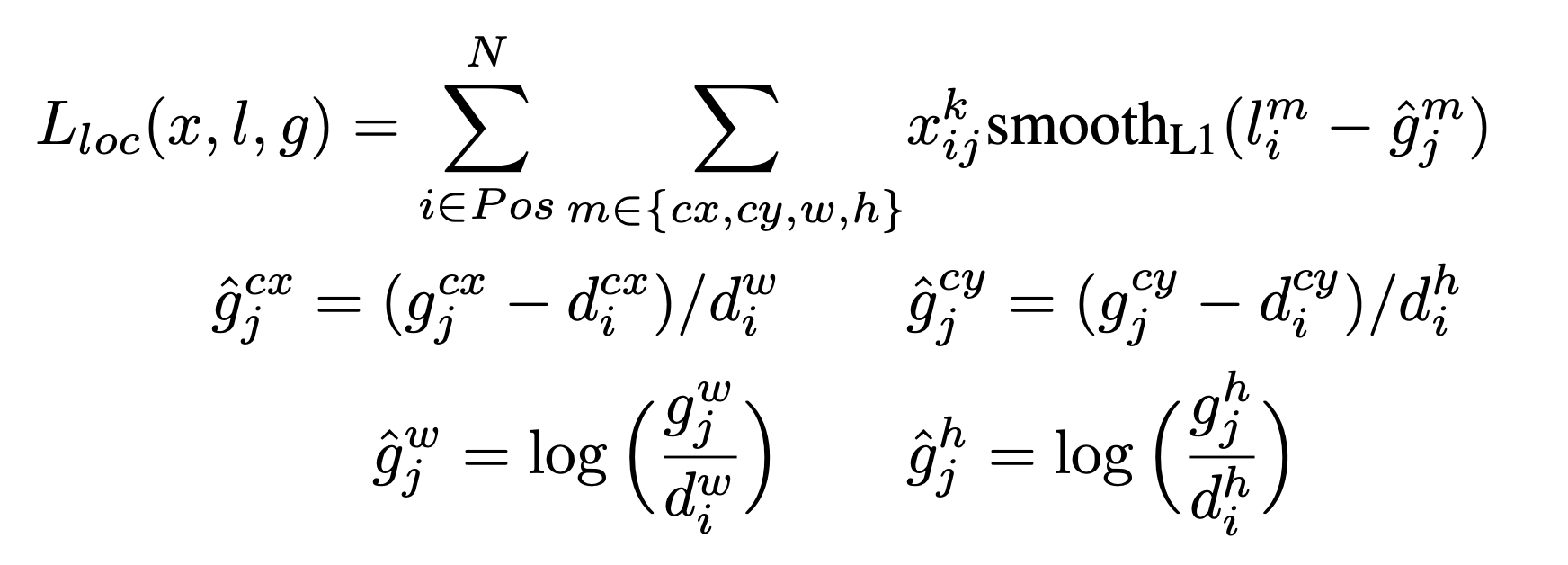
= class 의 ground truth가 번 째 default box에 매칭 여부(1 or 0)
= predicted box
= ground truth
= target
= default box
Confidence loss function
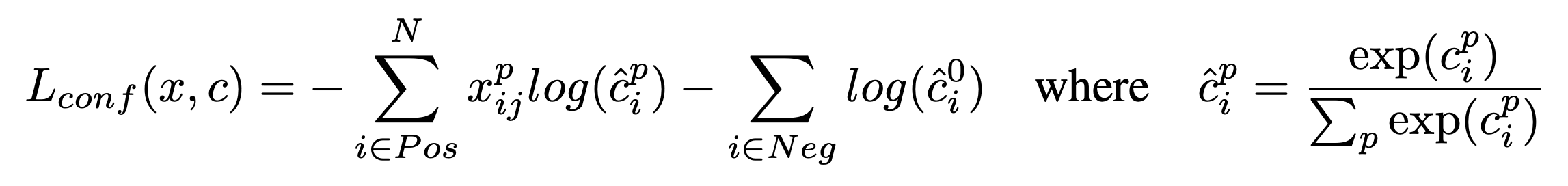
confidence loss function은 모든 class에 대한 loss를 softmax함수를 이용하여 구함.
= 배경이라 판단한 box의 학습을 위함
Choosing scales and aspect ratios for default boxes
scale이 다른 object들을 detection하기 위해 이미지 사이즈를 줄이거나 늘리는 전처리 혹은 후처리 과정이 필요하였지만 SSD는 여러 다른 conv layer의 feature map을 사용하여 비슷한 효과를 볼 수 있었다. lower layer는 이미지의 세부정보를 잘 나타내기 때문이다.
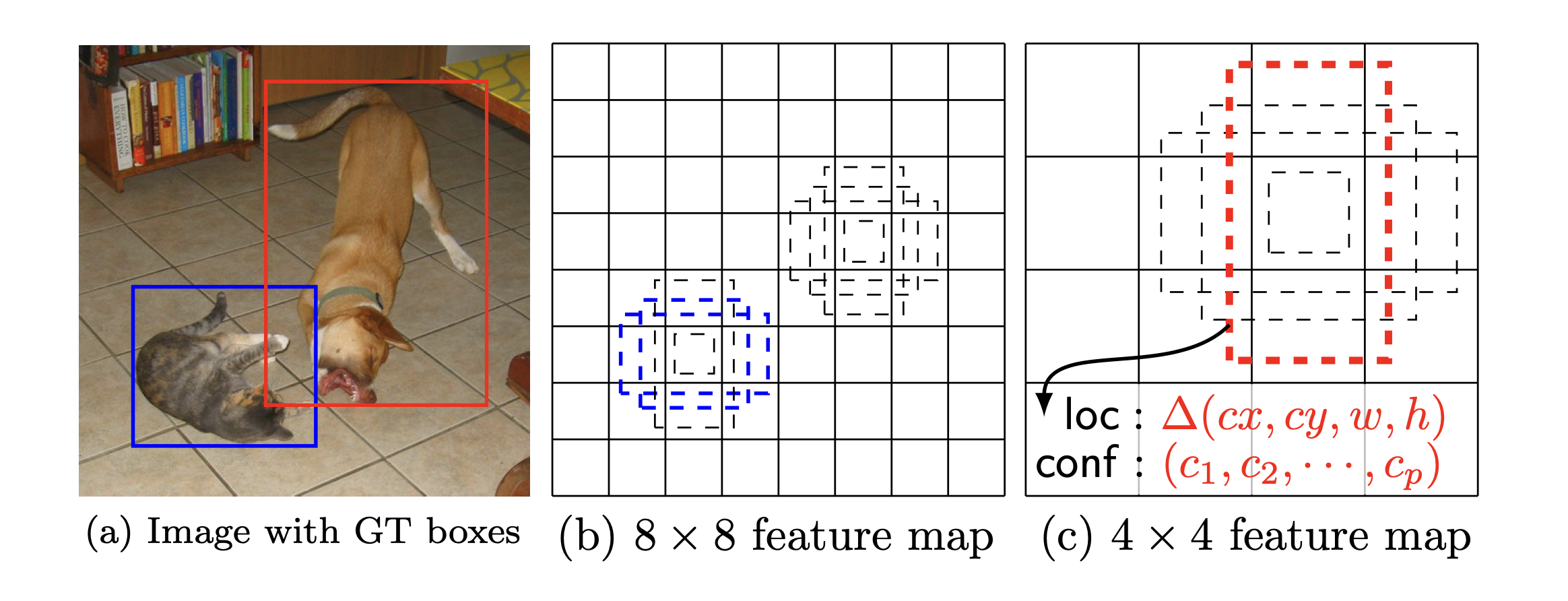
크기가 다른 feature map은 각기 다른 receptive filed(object를 품을 수 있는 영역 혹은 넓이)를 가지기 때문에 사진과 같이 8x8 feature map은 상대적으로 작은 고양이를 detecting하고 4x4 feature map은 상대적으로 큰 개를 detecting한다.

feature map scale에 따른 defualt box를 위한 공식이다.
= aspect ratio
= 사용할 최소 상대크기(논문상 0.2)
= 사용할 최대 상대크기(논문상 0.9)
= feature map의 index
= 사용할 feature map의 수(논문상 6)
= aspect ratio
= default box의 상대너비
= default box의 상대높이
= default box의 중심좌표
또 aspect ratio가 1:1이면 크기의 default box를 추가한다.
Hard negative mining
SSD 또한 OD 모델의 고질적인 문제인 negative sample이 postive sample보다 압도적으로 많은 것이다. 때문에 default box마다 negative confidence score loss를 내림차순으로 정렬하여 가장 높은 것을 골라 negative:positive = 3:1로 설정하였고 이 방법이 학습속도가 가장 빨랐다고 말한다.
Reference
한국 IT교육원 3/13 ~ 3/17
based on Andrew Ng
SSD: Single Shot MultiBox Detector
SSD 논문(SSD: Single Shot MultiBox Detector) 리뷰
[논문] SSD: Single Shot Multibox Detector 분석
[Object Detection] SSD 논문리뷰 및 코드구현 (ECCV2016)
