앞선 RCNN모델들은 대표적인 2-stage model이였다면 Yolov1은 1-stage model의 대표 모델이라 할 수 있다.
1-stage vs 2-stage
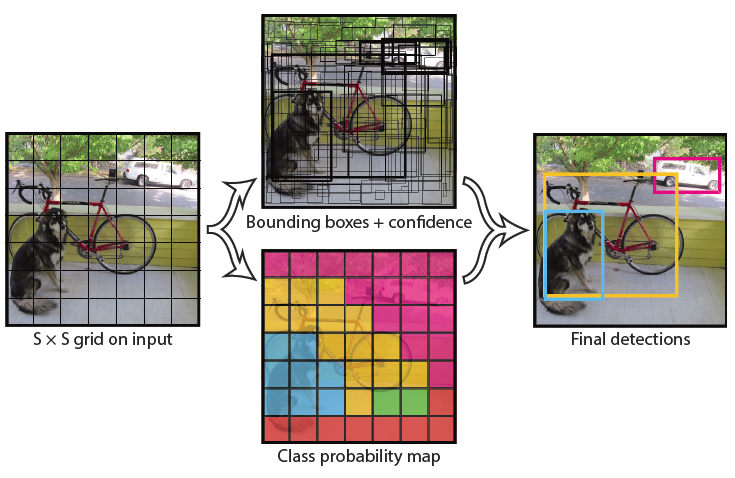
1-stage와 2-stage의 대표적인 차이점은 localization을 따로 계산하느냐 한 번에 계산하느냐이다. 1-stage model은 region proposal단계를 삭제하고 이미지를 grid로 나누어 각 grid마다 object의 확률을 계산하고 bbox regression을 수행하여 single task로 학습을 진행한다.
Yolo
1. Unified Detection
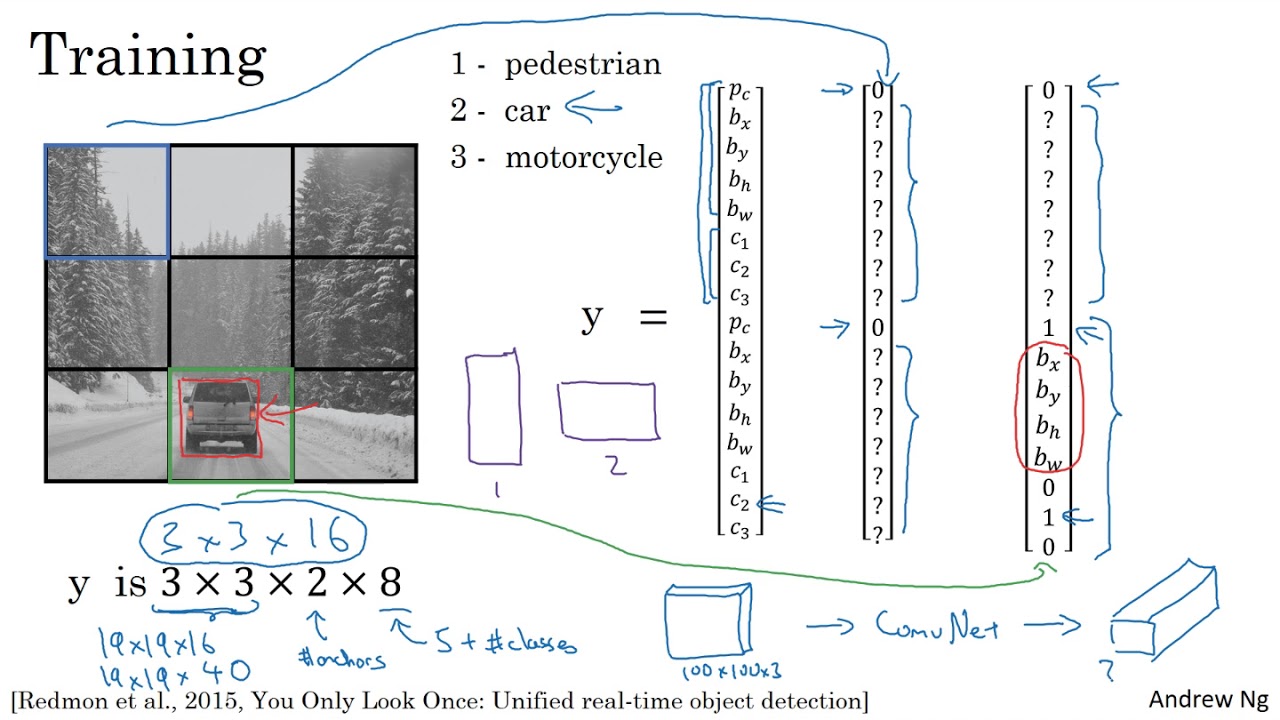
Yolo는 input image를 의 grid로 나누어 어떤 object가 grid cell의 중심에 있다면 해당 grid cell은 해당 object를 감지하고 각 grid cell은 B개의 bbox와 confidence score를 예측한다. confidence score는 bbox 안에 object의 존재 여부와 bbox의 위치가 얼마나 정확한지를 수치로 나타낸 것이다.
논문에서 confidence score는 다음처럼 나타내며 만약 bbox에 object가 없다고 판단하면 이며 object가 확실히 있다고 판단하면 이다 때문에 가 가장 이상적이라고 설명한다.
각 bbox는 5개의 예측값을 가진다(x,y,w,h,c) 이 때 (x,y)는 grid cell을 중심으로 하는 좌표, (w,h)는 bbox의 넓이 c는 confidence score이다. 이 때 (x,y,w,h)는 모두 grid cell안에서의 상대값이기 때문에 0 ~ 1 사이 값을 가지지만 (w,h)는 grid cell 보다 클 수 있기 때문에 1 보다 클 수 있다.
각 grid cell마다 (conditional class probabilities)를 예측하며 식은 다음과 같다.
해당 식은 grid cell이 포함하고 있는 object의 조건부 확률이다. 앞서 각 grid cell은 B개의 bbox를 예측한다고 하였지만 bbox의 갯수와 무관하게 단 하나의 class를 예측한다.
테스트에선 와 individual box confidence predictions를 곱해주어 각 bbox마다의 class-specific confidence scores를 구하고 식은 다음과 같다.
해당 점수는 object가 bbox에 얼마나 잘 맞는지, 잘 나타나는지를 나타낸다.
하나의 input-image를 SxS로 나누었을 때 B개의 bbox를 예측하고 해당 bbox는 5개의 값을 가지기 때문에 다음과 같은 식으로 나타낼 수 있다.위 사진과 같이 3x3으로 이미지를 나누고 논문과 같이 PASCAL VOC dataset을 사용한다면 이미지당 다음과 같은 feature map을 가진다.
2.1 Network Design
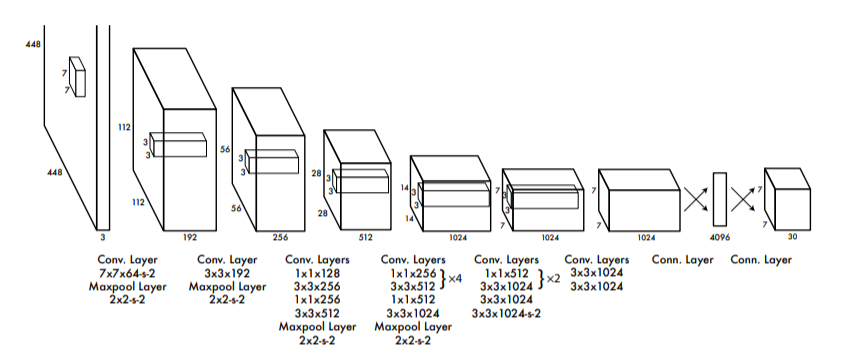
Yolo는 PASCAL VOC dataset에서 학습하였다. 앞의 conv layer에서는 이미지로부터 feature map을 추출하고 뒤의 FC layer에서는 좌표와 확률을 예측한다.
architecture는 classification에 사용되는 GoogLeNet의 영감을 받았으며 24개의 convolusion layer와 2개의 fully connected layer로 이루져 있고 GoogLeNet에서 사용하는 inception module 대신 1x1 conv layer와 3x3 conv layer를 사용하여 심플하게 inception module을 대체하였다고 설명한다.
최종적으로 7x7x30(SxSxBx(5+classes))의 아웃풋을 갖는다.
2.2 Traning
논문의 해당 파트에선 위에서 설명한 것들을 추가적으로 서술하고 있는데 네트워크 구성과 backbone을 어떻게 튜닝하였는지, 이미지를 어떻게 프로세싱하였는지 설명한다.
- 학습은 ImageNet을 사용하였다.
- 24개의 conv layer 중 20개만 학습하였다.
- ImageNet 2012에서 top-5 accuracy가 88%이다.
(상위 5개 confidence socor중 정답일 확률) - Darknet이라는 독자적인 framework를 사용하였다.
- 기존 classification model을 object detection model로 변환하기 위해 4개의 conv layer와 2개의 fully connected layer를 추가하였다.
- detection에선 종종 fine-grained를 요구하기 때문에 224x224 -> 448x448로 resize시켰다.
- bbox의 width, height를 이미지 width, height에 대한 상대크기로 나타내어 0과 1사이 값을 가진다.
- bbox의 중심좌표 또한 grid cell에 대한 상대위치로 나타내어 0과 1사이 값으로 나타낸다
- 마지막 layer는 linear activation function을, 나머지는 leakey ReLU 사용한다.
Loss Function
기존 RCNN의 모델들은 multi-task loss를 사용하여 classification, localization에 사용하는 loss function이 서로 달랐다. 하지만 Yolo에서는 SSE(sum of squared error) 하나만 사용하여 localization loss + confidence loss + classification loss의 합으로 나타낸다.
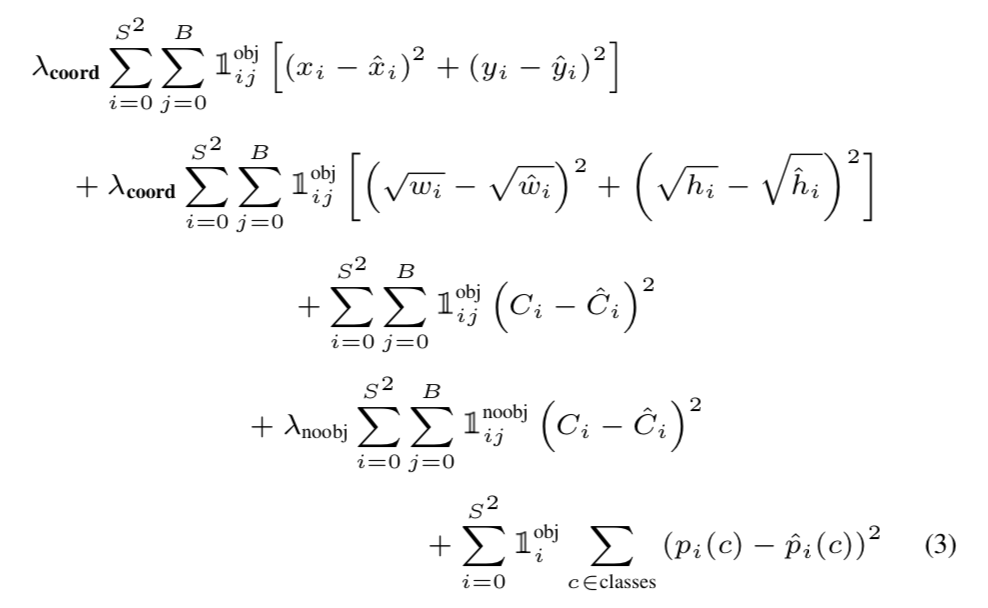
Localization Loss
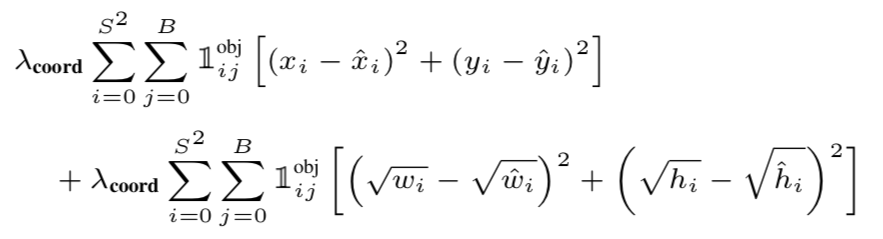
- = 대부분의 이미지에 경우 background가 foreground 보다 압도적으로 많기 때문에 사용하는 balancing hyperparameter이다.( = 5)
- = 번째 grid에 번째 bbox가 object를 포함하고 있으면 1 아니면 0.
(ground truth bbox와 IoU가 가장 높은 하나) - = 각각 ground truth value, prediction value
width, height 부분만 를 사용한 이유는 크기가 큰 object에 비해 작은 크기의 object는 작은 움직임에도 box가 많이 벗어나기 때문이라고 논문에서 설명한다.
Confidence Loss
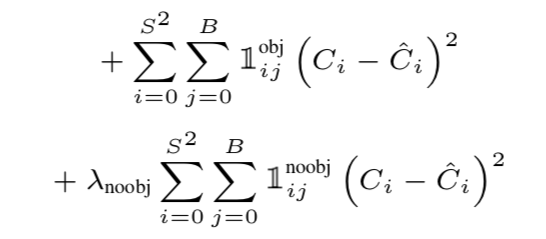
- = 마찬가지로 background가 foreground보다 압도적으로 많기 때문에 background의 영향역을 줄이기위한 balancing hyperparameter( = 0.5)
- = 번째 grid에 번째 bbox가 object를 포함하고 있으면 0 아니면 1.
- = 각각 ground truth confidence score(1 or 0), prediction confidence score(0 ~ 1)
Classification Loss
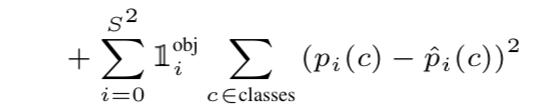
= 각각 ground truth probabilities, prediction probabilities
Reference
한국 IT 교육원 3/10 ~ 3/15
based on Andrew Ng
You Only Look Once: Unified, Real-Time Object Detection
YOLO v1 논문(You Only Look Once:Unified, Real-Time Object Detection) 리뷰
[논문 리뷰] YOLO v1 (2016) 리뷰

유익한 글이었습니다.