- iris 실습
#1.iris를 import 하기
from sklearn.datasets import load_iris
iris = load_iris()
#2. iris의 키값
iris.keys()
#결과출력
dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module'])
#3.sklearn.에서 데이터를 가져오면 대부분 DESCR이 포함되어 있다.
print(iris['DESCR'])
#출력
:Number of Instances: 150 (50 in each of three classes)
:Number of Attributes: 4 numeric, predictive attributes and the class
:Attribute Information:
- sepal length in cm
- sepal width in cm
- petal length in cm
- petal width in cm
- class:
- Iris-Setosa
- Iris-Versicolour
- Iris-Virginica
...
4. setosa, vesicolor, virginica 갯수확인
len(iris['target']) # setosa, versicolor, virginica 각각50개가 포함되어있다. (총150개)
4-2 target 출력
print(iris['target'])
# 0번 setosa, 1번 versicolor, 2번 virginica (각각 50개)
5. 컬럼에 사용할 feature_names
print(iris['feature_names'])
#출력
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
6. iris 데이타 확인
iris.data
([[5.1, 3.5, 1.4, 0.2], # setosa 첫번째 데이터
[4.9, 3. , 1.4, 0.2], #stosa의 두번째 데이터
[4.7, 3.2, 1.3, 0.2],
[4.6, 3.1, 1.5, 0.2],
...
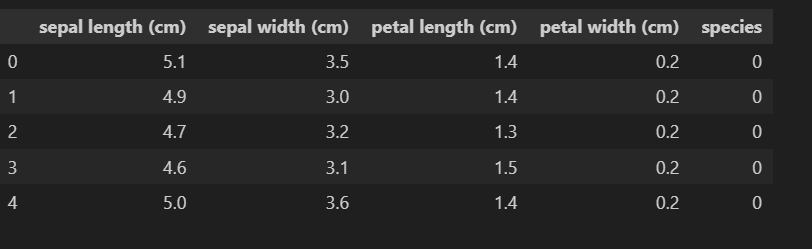
7.iris_pd['species'] = iris.target # 3개의 꽃종료 0,1,2 넣어주기
iris_pd.head()
- iris 시각화
Decision Tree(의사 결정 트리)
Decision Tree는 나무 구조로 타나낼 수 있는 모델이며 데이터의 특성(feature)을 토대로 순차적인 의사 결정을 통해 데이터를 분류하거나 값을 예측한다.
1. 노드: 의사 결정 트리는 노드로 구성된다. 데이터를 분할하거나 결정하는 데 사용된다.
- 루트 노드(root node):트리의 시작점으로 모든 데이터가 이곳에서 시작한다.
- 내부 노드(internal node): 데이터를 분할하는 역할을 한다.
- 리프 노드(leaf node):최종 예측값 또는 분류 결과를 가지고 있는 노드
- 분할(Splitting)
- 내부 노드는 특정 특성(feature)의 값을 기준으로 데이터 분할
ex) 꽃잎 길이가 5cm이상인가
- 결정 기준(Decision Criteria)
- 엔트로피(entroy), 지니 계수(Gini Impurity), 분산감소(Variance Reduction) 등 지표를 사용하여 정보 이득을 최대화하거나 불순도를 최소화하는 방식으로 결정
- 가지치기
- 모델의 복잡성을 줄이며 과적합(Overfitting)을 방지하고 일반화 성능을 향상시킨다.
- 장점
- 해석력이 좋고 시각화하기 쉽다.
- 범주형(categorical)특성을 다루기 쉽다.
- Feature의 스케일링이나 정규화가 필요하지 않다.
- 단점
- 과적합(Overfitting)되기 쉽다.
- 데이터를 사각형 모양의 경계로만 분할
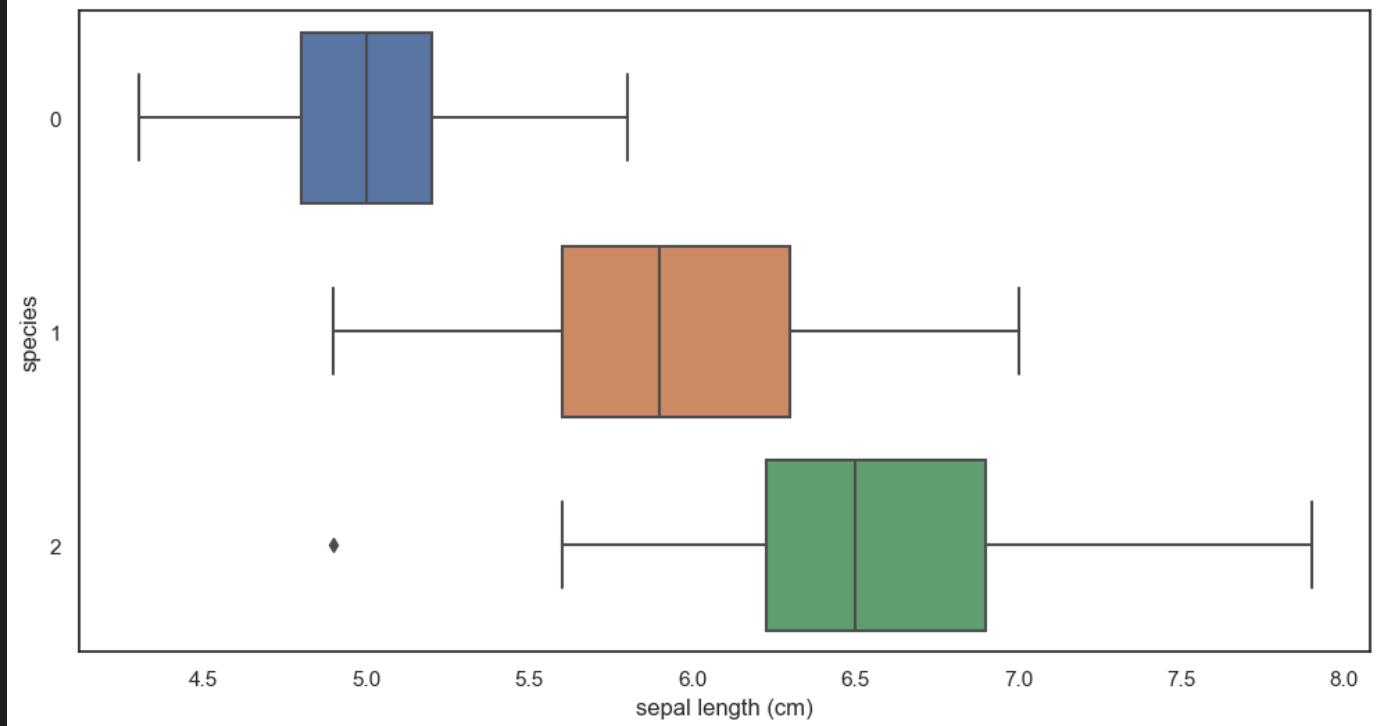
#슬라이싱 0제외 출력하기 즉 setosa 제외
iris_12 = iris_pd[iris_pd['species']!=0]
plt.figure(figsize= (12, 6))
sns.scatterplot(x= "petal length (cm)", y="petal width (cm)",
data=iris_12, hue = 'species', palette = "Set2")
엔트로피
- 열역학의 용어로 물질의 열적 상태를 나타내는 물리 량의 단위 중 하나. 무질서의 정도를 나타낸다.
- 엔트로피 개념에서 힌트를 얻어 확률 분포의 무질서도나 불확실성 혹은 정보 부담 정도를 나타내는 정보 엔트로피 개념을 클로드 섀넌이 고안함
- entropy: 얼마만큼의 정보를 담고 있는가? 또한, 무질서도(disorder)를 의미, 불확실성(uncertainty)를 나타내기도한다.
- -p*np.log2(p)
- p는 해당 데이터가 해당 클래스에 속할 확률이고 위 식을 그려보면 다음과 같다.
- 어떤 확률 분포로 일어나는 사건을 표현하는 데 필요한 정보의 양이며 이 값이 커질수록 확률 분포의 불확실성이 커지며 결과에 대한 예측이 어려워짐
- 파이썬에서 수학공식을 표기하는것을 latex라고 한다.
- 정보의 무질서 또는 불확실성의 정도를 나타내는 척도
- 엔트로피가 높을수록 정보의 무질서도가 높아진다(예측이 어려워진다.).
- H(X) = -Σ(p(x) * log2(p(x)))
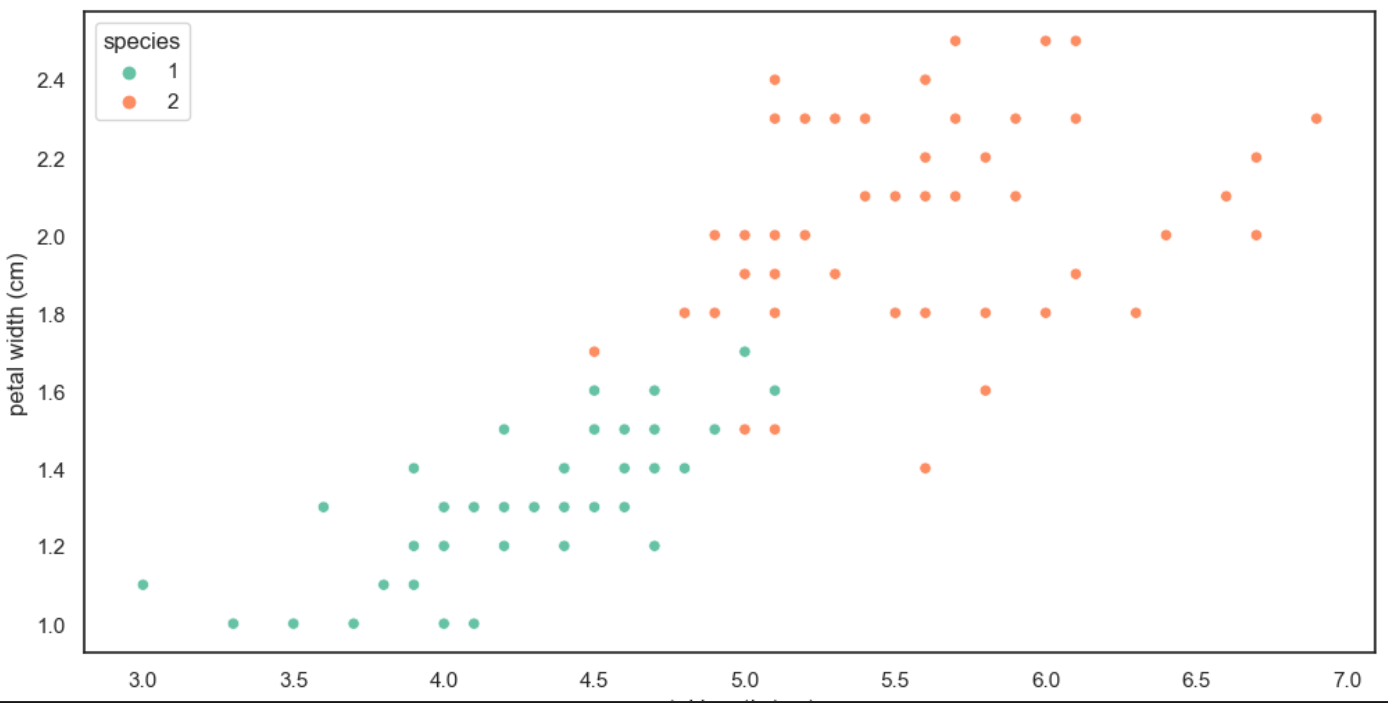
엔트로피 시각화
import numpy as np
p = np.arange(0.001, 1, 0.001) #0.001은 확률 (0을 줄수 없다.)
#넘파이의 arange 함수이다. 0.001부터 1까지 0.001간격으로 숫자 생성
plt.grid()
plt.title("$-p \log_{2}{p}$")
plt.plot(p, -p*np.log2(p)); #p 배열 x축 -p*np.log2(p)를 y축
지니계수
1.Gini 계수 정의
- Gini index 혹은 불순도율
- 엔트로피의 계산량이 많아서 비슷한 개념이면서 보다 계산량이 적은 지니계수를 사용하는 경우가 많다.
- 값 범위는 0에서 0.5(0~50%)사이
- Gini(X) = 1 - Σ(p_i^2)
- Gini(X): 지니 계수를 나타내는 기호로, 데이터 집합 X의 불순도를 측정
- Σ: 시그마(Σ) 기호는 합산을 나타냅니다. 즉, 집합 X 내의 모든 클래스에 대해 합산한다는 의미입니다.
- p_i: 클래스 i의 비율을 나타냅니다. 즉, 데이터 집합 X에서 클래스 i에 속하는 샘플의 비율입니다.
--- Scikit learn
#1. 결정 트리(Decision Tree) 분류 모델을 만들기 위한 시작 단계
from sklearn.tree import DecisionTreeClassifier
iris_tree = DecisionTreeClassifier()
#2.
#fit 학습실행 명령어 정답지를 주고 데이터 넣어주기
iris_tree.fit(iris.data[:, 2:], iris.target) #데이터를 준다. data[:,2:]그리고 (정답지를 알려준다. iris.target)
#ex) petal width가 1.4 length가 0.2 --> setosa구나
#3. Accuracy 성능확인
from sklearn.metrics import accuracy_score
y_pred_tr = iris_tree. predict(iris.data[:, 2:]) #이번엔 정답지를 표시하지 않고 데이터만 가져와서 예측을한것이다.
y_pred_tr
#array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
#0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
#0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
#1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
#1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
#2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
#2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])
#결론: 원본 iris.target과 달리 오답이 1개 존재한다.
#4. 일치확인
accuracy_score(iris.target, y_pred_tr) #정답확인하기 정답지(iris.target) 예측값(y_pred_tr)
#출력결과 99.33% 정확도가 나왔다.
# 출력결과 0.9933333333333333
Dscision Tree를 이용한iris -과적합
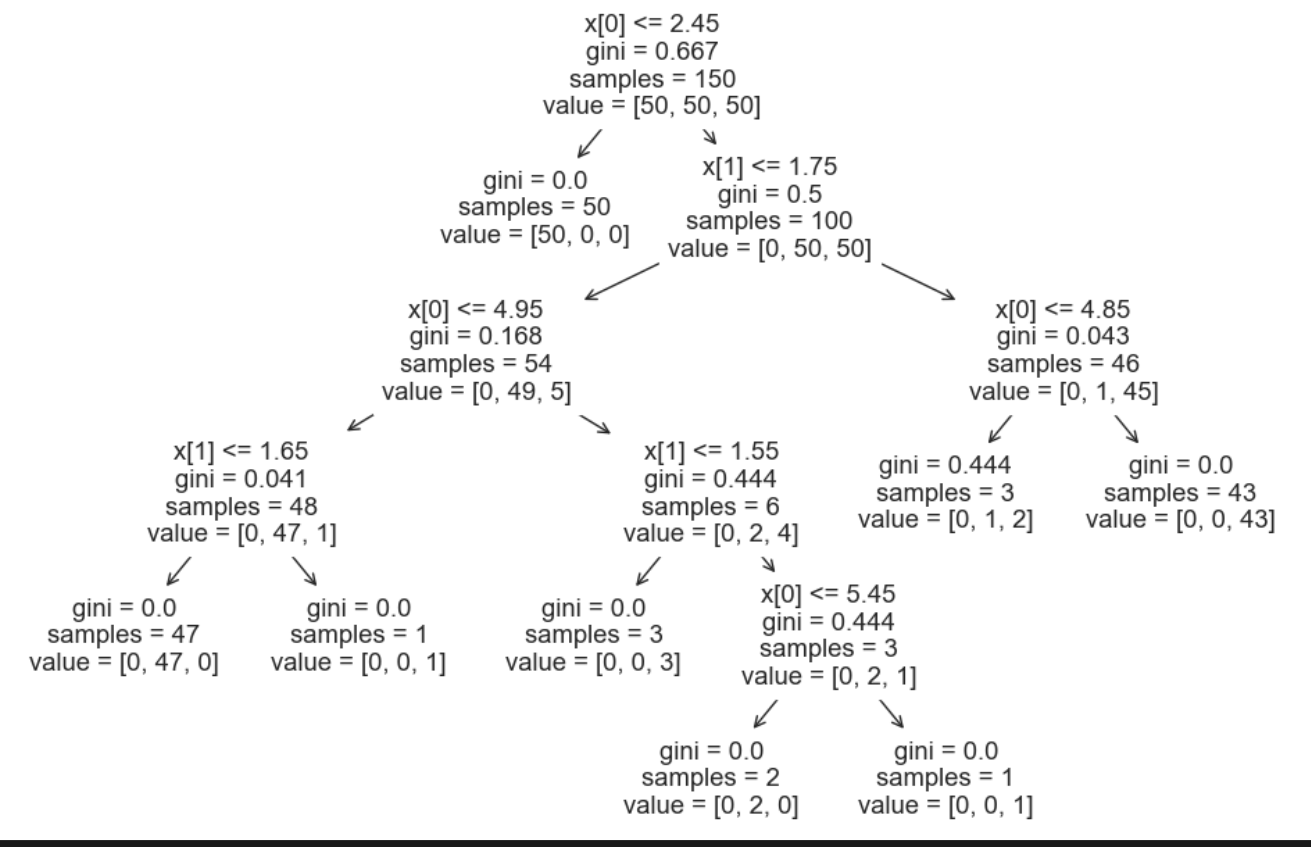
- Decision Tree의 모양을 확인하기
#plot_tree는 결정 트리(Decision Tree)의 모양을 보여준다.
from sklearn.tree import plot_tree
plt.figure(figsize=(12,8))
plot_tree(iris_tree);
- setosa의 경우 100% 분류가 되어 도출이 바로 끝났지만
나머지는 도출되지 않아 계속 도출이 이어진다.
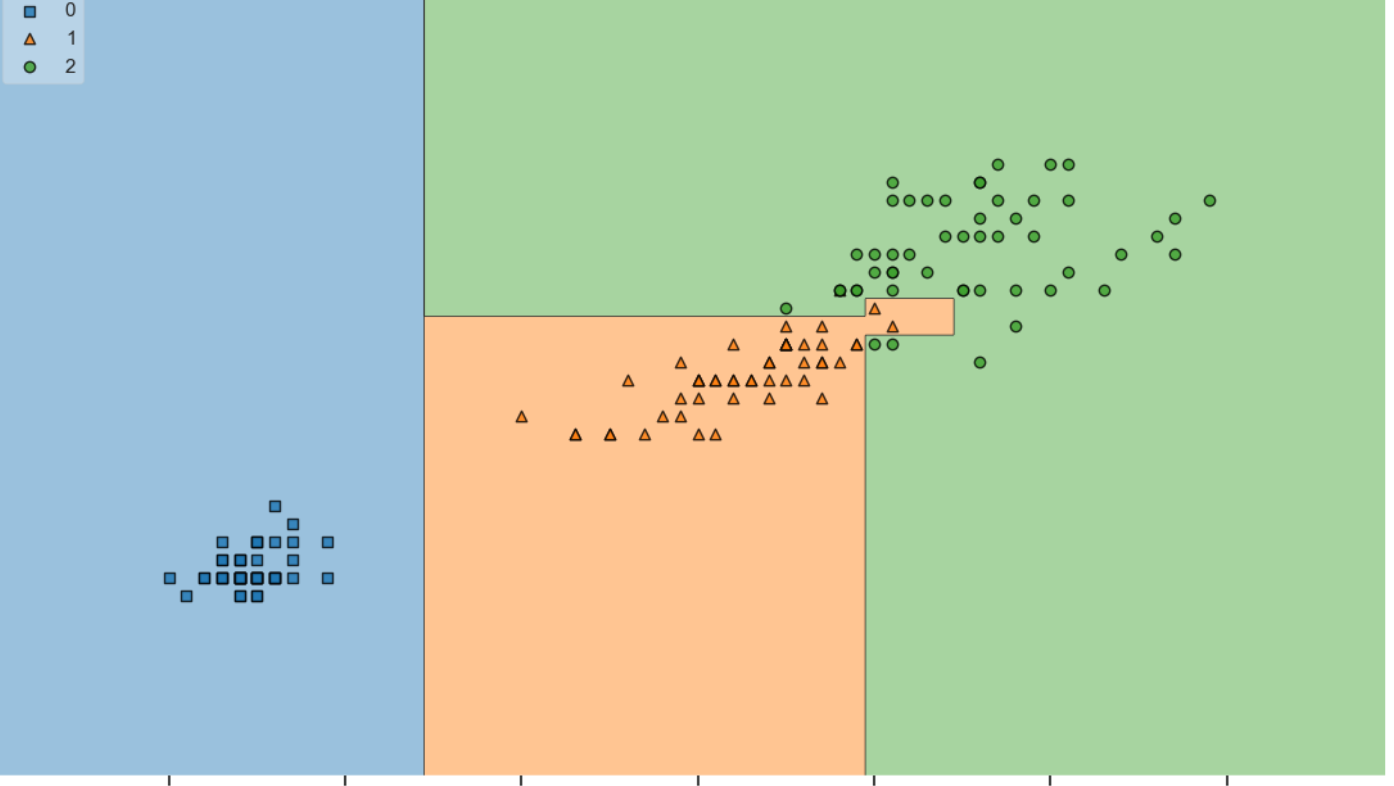
- 결정 트리가 Iris 데이터를 분류했는지 확인하기
#iris의 품종을 분류하는 결정나무 모델이 어떻게 데이터를 분류했는지 확인해보자
from mlxtend.plotting import plot_decision_regions
plt.figure(figsize=(14,8))
plot_decision_regions(X=iris.data[:, 2:], y= iris.target, clf = iris_tree, legend= 2)
#학습에 사용할 데이터 iris.data[:, 2:]
#정답지 iris.target
#학습모델 iris_tree
plt.show()- 과적합
과적합(Overfitting): 기계학습에서 발생하는 일반화의 문제를 가리킨다
모델이 훈련 데이터에 너무 맞추어져 있어서 이전에 보지 못한 데이터에 대한 성능이 나빠지는 현상을 의미
1. 결정 나무트리의 시각화 데이터가 위와 같이 나왔고 정확도가 99.3%라고 측정을 해주었지만 이것이 정말 99%의 정답을 가리키는게 아닐수도 있다.
이것은 과적합 때문이다.
