Machine Learning
1.machine learning1 (iris실습)
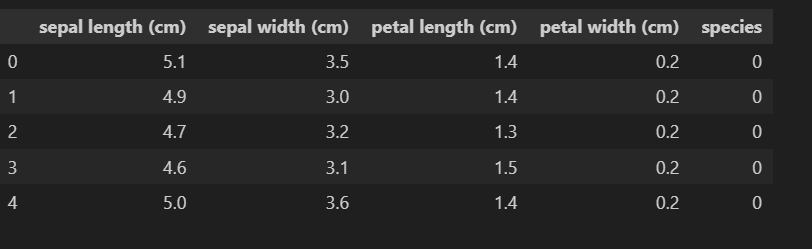
iris 실습iris 시각화Decision Tree는 나무 구조로 타나낼 수 있는 모델이며 데이터의 특성(feature)을 토대로 순차적인 의사 결정을 통해 데이터를 분류하거나 값을 예측한다.1\. 노드: 의사 결정 트리는 노드로 구성된다. 데이터를 분할하거나 결정하는
2.ML (label, min-max, standard, robust)
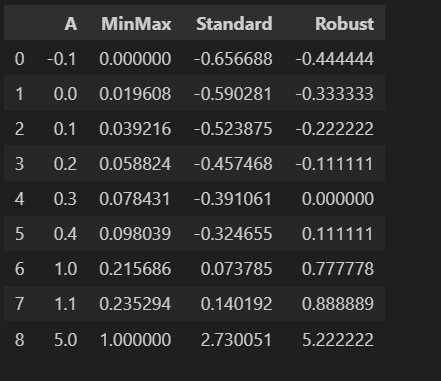
라벨 인코더: 머신러닝과 데이터 전처리 작업에서 주로 사용된다.범주형 데이터를 수치형(숫자) 데이터로 변환라벨인코딩: ex) 치킨, 피자, 햄버거가 있는데 치킨는 1피자는2 햄버거는3과 같이 할당할 수 있다.Min-max: 데이터를 특정 범위로 변환하는 데이터 스케일링
3.ML(모델 평가의 개념)
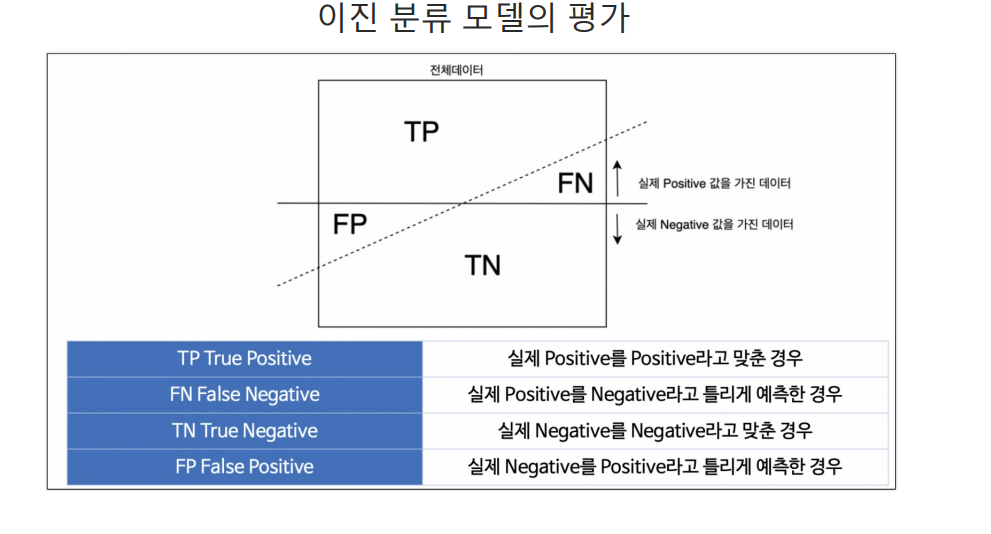
이진 분류 모델: 모델의 예측 결과와 실제 레이블 간 비교를 통해 계산1\. 정확도(Accuracy)전체 예측 중 올바르게 예측한 비율정밀도(Precision)정밀도는 양성(Positive)클래스로 예측한 샘플 중 실제 양성 클래스인 샘플의 비율을 나타낸다. (양성을
4.ML (다항함수,지수함수)
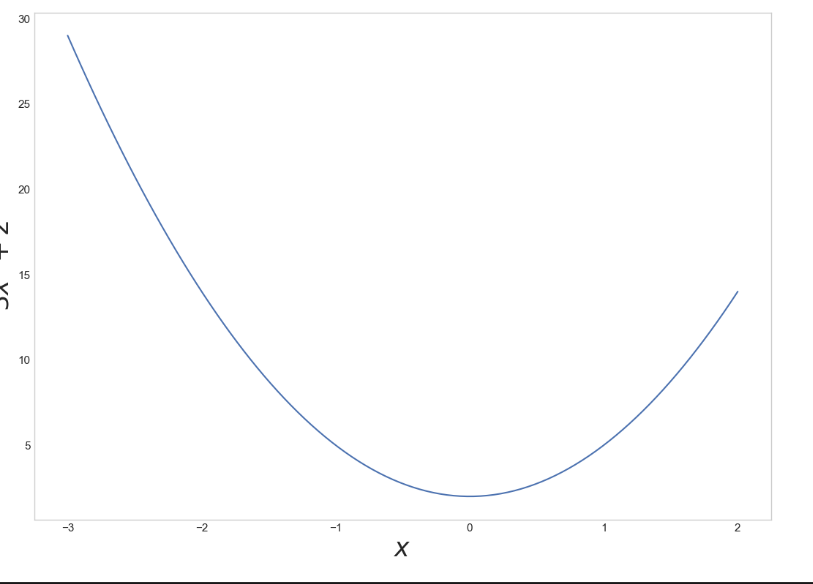
시그모이드(Sigmoid) 그래프는 S 모양의 곡선 형태를 가지는 함수 그래프이다.주로 로지스틱 함수(Logistic function)라고 불리며 실수 입력을 받아0과 1사이의 출력 값 반환한다.1\. S 모양 곡선 시그모이드 함수의 그래프는 S 모양의 곡선으로, 입력
5.ML (Basic of Regression- 회귀)

지도학습 > 지도학습(Supervised Learning):입력 데이터와 해당 데이터에 대한 정답 또는 레이블(label)이 주어진 상태에서 모델을 학습시키는 방법 ex)스팸메일 종류 회귀(Reggression): 연속형 출력 변수 예측한다. 군집화(Clustering
6.ML(Cost Fucntion)
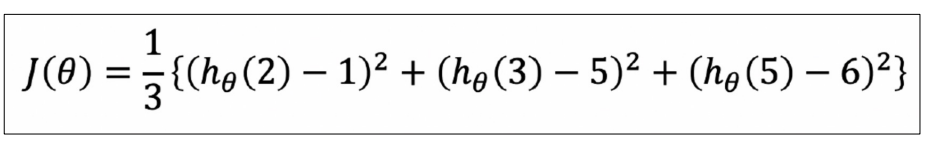
Cost funtion, Loss function(손실함수) : 머신 러닝, 통계 모델에서 모델의 성능을 측정하고 모델을 최적화하는 데 사용 이 함수는 모델의 예측값과 실제 관측값 간의 차이를 측정하고, 이 차이를 최소화하는 방향으로 모델의 매개 변수(가중치 및 편향)
7.ML (보스턴)

가격기준 히스토그램상관관계히트맵 (sns.heatmap(data=corr_mat, annot=True, cmap='bwr'))선형회귀
8.ML (Logistic Regression) 1
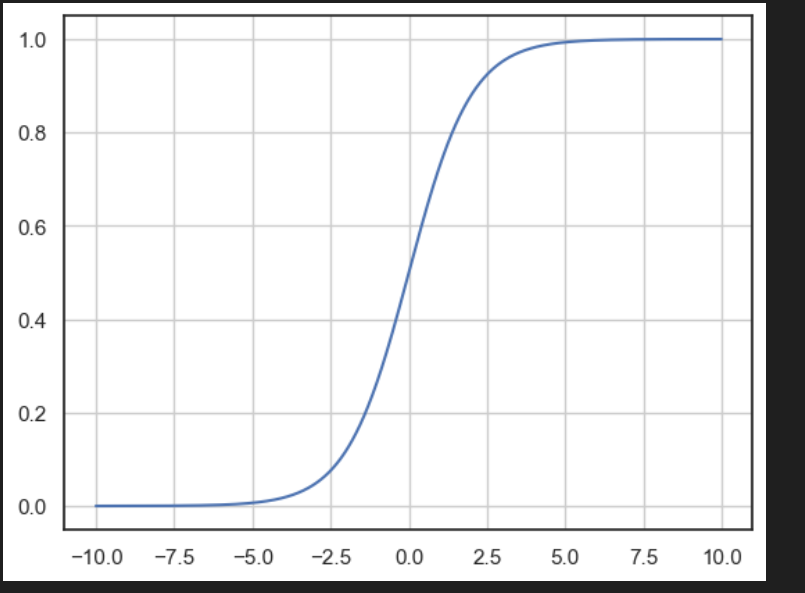
로지스틱(Logistic Regression) 분류(Classification) 문제를 다루기 위한 통계적 기계 학습 알고리즘이며 분류(classification)알고리즘이다.주로 이진 분류(Binary Classification)문제를 다루며, 샘플을 구 개의 클래
9.ML (Logistic Regression 정밀도와 재현율 트레이드 오프)
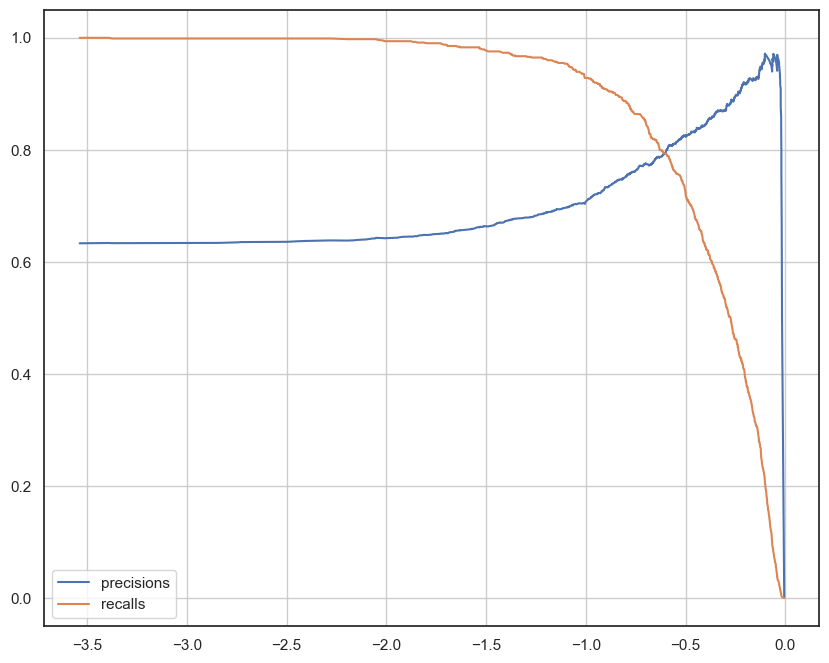
정밀도(Precision): 모델이 양성 클래스로 예측한 샘플 중 실제로 양성 클래스에 속한 샘플의 비율을 나타낸다.재현율(Recall): 재현율은 실제로 양성 클래스에 속한 샘플 중 모델이 양성 클래스로 올바르게 예측한 샘플의 비율을 나타낸다.트레이드 오프: 정밀도와
10.ML (앙상블 기법)

앙상블(Ensemble): 다양한 학습 알고리즘을 결합 하여 더 강력하고 안정적인 모델을 만드는 방법. 앙상블은 단일 모델보다 더 좋은 예측 성능을 달성하고 모델의 과적합을 줄인다. 분류(Classfication) 및 회귀(Regression)문제에서 사용된다.설명
11.ML (Boosting Algorithm)
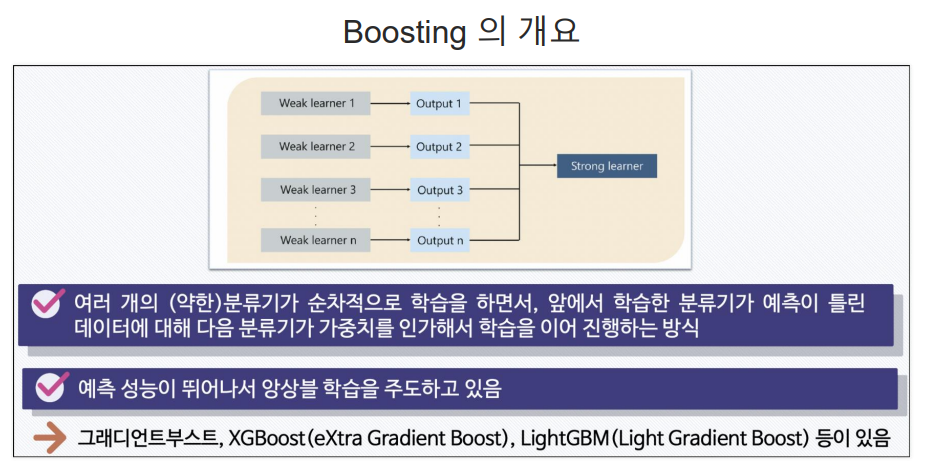
앙상블 기법Voging,Bagging,Boosting, voting과 bagging은 여러개의 분류기가 투표를 통해 최종 예측 결과를 결정하는 방식보팅과 배깅의 차이점은 보팅은 각각 다른 분류기, 배깅은 같은 분류기를 사용대표적인 배깅 방식이 랜덤 포레스트배킹과 부스팅
12.ML (NLP 자연어)

NLP은 언어를 이해하고 처리하는 컴퓨터 프로그램을 개발하는 인공지능 분야개념텍스트 데이터 처리: NLP는 텍스트 데이터를 기본 단위로 취급토큰화(Tokenization): 텍스트 데이터를 분할하여 처리하는 과정텍스트 분류(Text Classification): NLP