논문 출처 Reinventing RNNs for the Transformer Era: RWKV
OverView
- RNN에 대한 간단 설명
- RNN과 Transformer의 장단점을 융합하는 RWKV
=> RNN : 순차(재귀) 상태로 문맥을 기억하지만, 학습 시 시간축 비병렬성과 기울기 소실/폭발 문제
=> Transformer : 병렬 학습과 강한 콘텐츠 선택성(어텐션)이 장점이지만, 긴 문맥에서 계산·메모리 비용이 큰 문제- RWKV는 어텐션의 “정규화 가중 평균”을 WKV로 재구성해 재귀 갱신(RNN형)으로 계산하여, 효율성과 선택성을 함께 잡음
- RWKV는 “훈련은 트랜스포머처럼, 추론은 RNN처럼” 동작하는 하이브리드로 좋은 성능을 보임
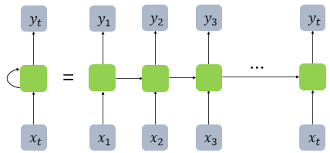
우리는 지금까지 NN 하나에 이미지 하나가 들어가 flatten 정보벡터가 input 노드에 입력되는 형식으로 이해했다. 하지만, 지금부터는 다르게 바라보아야 한다.
RNN은 순서데이터를 위주로 다룬다. 즉, 맥락이 중요한 문장이나 주식 데이터가 들어가게 된다. 그렇다면, NN 하나에 단어 하나, 한시점의 데이터 하나가 들어간다고 보면되고, 이 단어를 고유벡터화시키는게 임베딩과정이라고 한다.
RNN의 가장 큰 특징을 한글자로 말하지면 "기억"이다. 이 신경망은 과거의 정보를 현재의 입력과 함께 기억을 하는 형식이라, 아까 말한 순서데이터, 문장데이터 등에 효과적이다.
Recurrent의 필요성
우리가 평소에 알고 있는 NN은 Feedforward Neural Network로 아래 그림과 같은 형태이다.
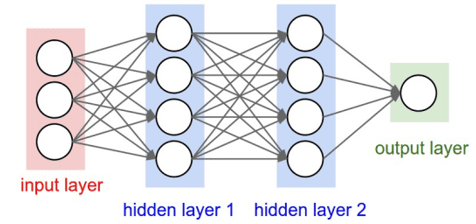
전반적으로 RNN도 동일한 형태의 Network를 가지고 있다. 단, Recurrent(순환)가 hidden layer에 존재할 뿐이다.
문장데이터를 예시로 들어보자. (지금부터 말하는 것은 학습이 아닌 추론단계)
"나는 벨로그에 글을 쓴다." 라는 문장이 있다. 그리고, 위와 같은 NN형식의 네트워크가 있다고 하자. 아까 말했듯이 한번에 한시점, 하나의 단어가 들어가므로 첫번째 데이터는 "나는"일 것이다. "나는"이 임베딩을 통해 고유 벡터화가 진행된다. 그렇게 생긴 벡터를 input layer에 넣게 된다.
이제 평소에 알고있듯이, NN은 데이터의 feature 특징을 추출하게 된다. 특징을 추출함으로써 기계적으로 그 단어를 이해하게 된다. 그리고 각 추출된 특징의 값을 통해 마지막 output layer에서 분류를 하든 예측을 하든 하게 된다.
자, 다음 단어인 "벨로그에"가 동일한 NN에 입력되게 된다. 똑같은 과정을 거쳐서 input에 입력되고, hidden layer에 지나 똑같이 "벨로그에"에 대한 결과값을 내놓게 된다.
하지만, 우리의 목적 input data는 "나는"이나 "벨로그에"가 아니라, "나는 벨로그에 글을 쓴다."이다. 그럼, 사실 첫번째, 두번째 단어의 결과는 중요하지 않다. 우리는 결과적으로 이 문장의 결과값이 필요한 것이다. 하지만, 만약 위와 같이 동일하게 진행이 된다면, 마지막 결과값은 "나는 벨로그에 글을 쓴다."의 결과값이 아닌, "쓴다."의 결과값일 것이다
. 즉, 이전 단계의 정보가 축적되어 전달이 되어야 한다. 여기서 Recurrent(순환)의 필요성이 생긴다.
RNN
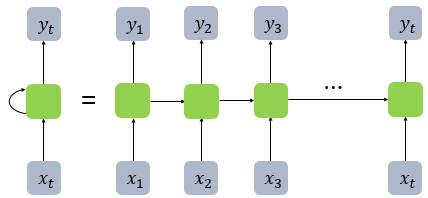
위 그림과 같이 RNN은 이전 단계의 정보를 hidden layer에서 가져오는 Recurrent가 존재한다. 각 블럭이 layer, 초록색 블럭이 하나의 hidden layer라고 생각해주길 바란다.
각 은닉층엔 은닉 상태가 있을 것이고, 다음 은닉층에 전달할 때마다, 가중치에 의해 가중합되어 전달이 될 것이다.
아래의 그림과 같이 단어의 벡터 차원에 따른 크기의 가중치와 t-1시점의 은닉 상태가 있을때, 그 이전 시점(t-1)의 은닉층과 현재 시점(t)의 입력값이 가중합(활성화함수도 거친다)되어, 현재 시점(t)의 은닉 상태를 결정하게 된다.

이런 구조로 이전 시점들의 정보를 포함하면서 연산을 하게 되고, 이는 nlp나 시계열에서 맥락을 파악한 결과값을 반환할 수 있게 된다.
문제점: 이전 시점의 정보를 가져간다는 점에서 단순한 문장은 맥락파악에 충분하지만, 만약 문장이나 데이터 길이가 매우 길어진다면, 초기 시점의 정보를 잊어버리는 기울기 소실 문제가 발생한다.
Reinventing RNNs for the Transformer Era: RWKV
이후 RNN은 수많은 발전을 거쳐, Transformer나 Mamba같은 여러 다른 모델의 기초가 되었다. 이때, 이 이러한 발전을 위해서 하나의 연결고리를 한 논문을 보고 넘어가고자 한다.
Reinventing RNNs for the Transformer Era: RWKV
Introduction
연속 시퀀스 데이터에서 사용되는 RNN과 Transformer에 대한 장단점에 대해 언급한다.
RNN
장점: 긴 시퀀스 처리에서 메모리 요구량이 적다.
단점: 기울기 소실 문제, 시간 축에서의 비병렬성에 의한 확장성 제약
Transformer
장점: 국소 및 장거리 의존성을 잘다룸, 병렬화된 학습 지원
단점: 셀프 어텐션의 제곱 복잡도에 의한 계산과 메모리 부담
이 논문은 위의 RNN과 Transformer의 강점을 결합하여 한계를 극복하는 RWKV를 제시한다.
Background
논문의 배경이 되는 RNN 아키텍처와 Transformer 아키텍처를 설명한다.
RNN
두개의 선형블록(W, U)로 분해가 가능하지만, 이전 시점에 대한 데이터 의존성에 의해 시간 축 병렬화가 불가능하다.
Transformer
순차적 처리가 아닌 어텐션 메커니즘을 통해 입출력 토큰 간 관계를 포착하는 Transformer
쿼리의 키값의 행렬곱으로 진행되지만, AFT에서는 이 행렬곱 보다 간단하게 Q,K 내적대신 W (위치 가중치)을 활용해서 간단한 덧셈 형태로 변경을 진행했다.
위의 두가지를 아키텍처를 잘 융합해서 RNN의 병렬처리 한계와 어텐션 매커니즘의 연산량 문제를 동시에 해결하고자 한다.
위와 같이 w를 시간이 흐를수록 감소되는 가중치로서 활용해, RNN으로 변환 가능한 가중치로 적용한다.
RWKV
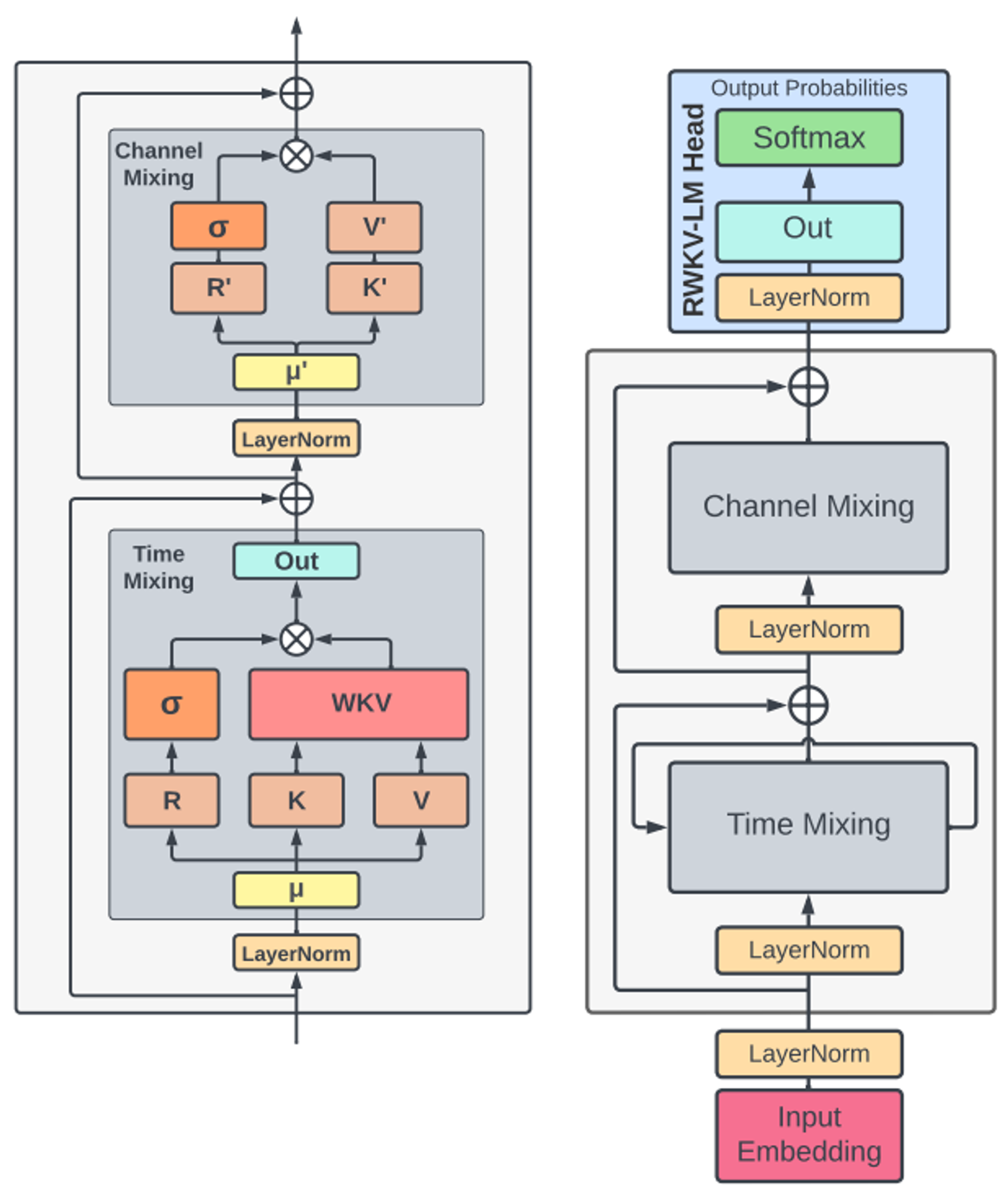
우선 RWKV은 time-mixing 블록과 channel-mixing 블록으로 구성되어 있고,
그 블록은 다음 4개의 기본 요소로 구성되어 있다.
- R: Receptance 벡터 — 과거 정보를 수신하는 역할
- W: Weight — 위치 가중 감쇠(positional weight decay) 벡터로, 모델 내에서 학습 가능한 파라미터
- K, V: Key, Value 벡터 — 전통적 어텐션의 K, V와 유사한 역할을 수행
이 요소들을 각 시점(t)마다 곱셈적으로 상호작용한다.
아키텍처
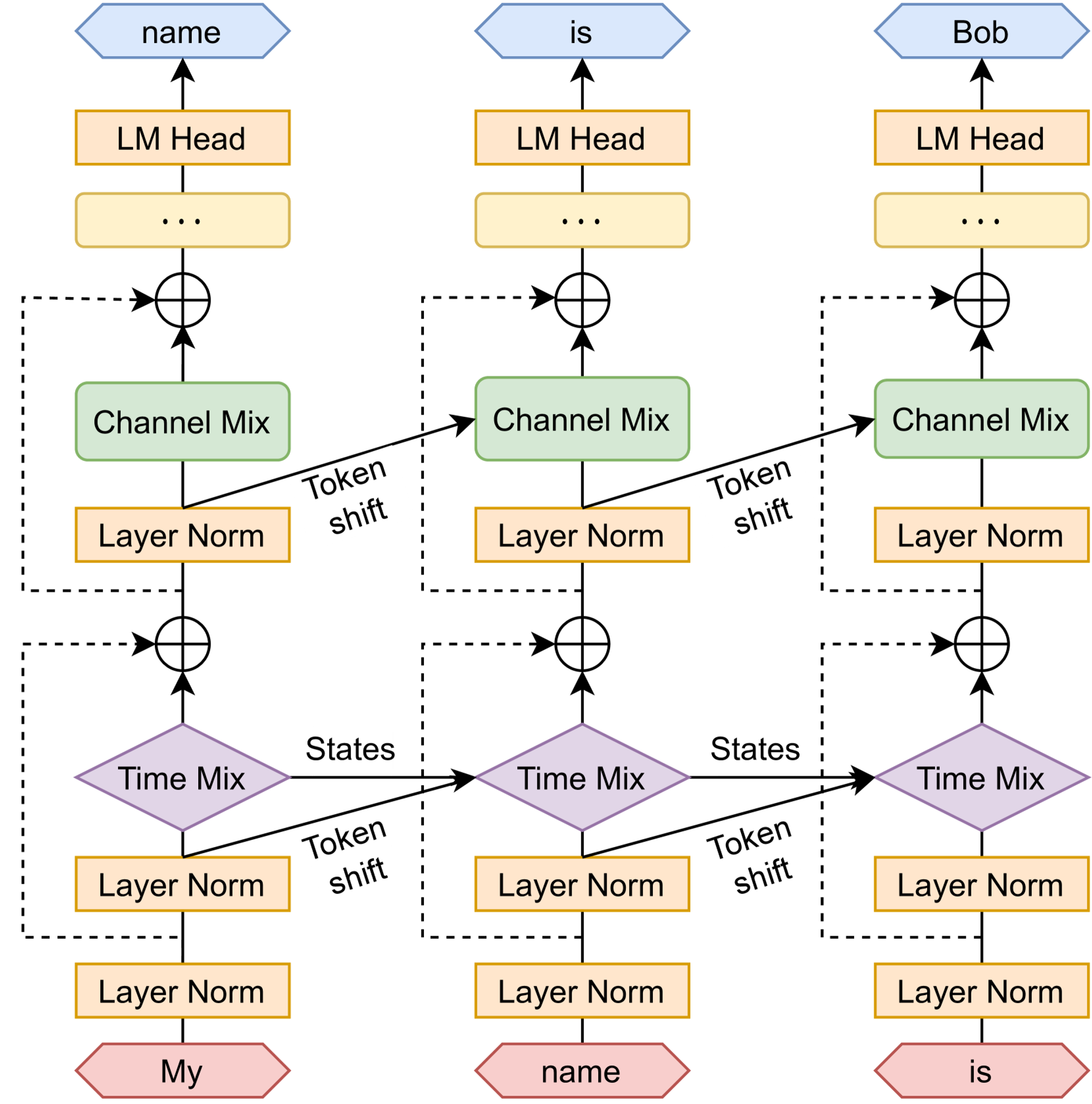
RWKV는 위의 그림을 보면 알 수 있듯이 순환구조를 가지고 있다. Attention과 유사한 점수 갱신 과정을 사용하며, 기울기(가중치 갱신)는 가장 관련성(출력에 대한 영향력)가 높은 방향으로 전파가 이루어진다. 또한, 잔차(Residual)와 Layer Norm을 통해 안정성을 유지해 기울기 소실 및 폭발 문제를 해결한다.
토큰 변환
위의 그림에서 μ파트에서 R,K,V를 생성하는데, 이를 위해서 이뤄지는 기법으로 토큰 변환은 train과정 중 병렬화를 위해, 각 블록 내부에서 현재 입력과 이전 입력을 섞는다.
즉, 원래 RNN은 토큰을 하나씩 거치며 시간이라는 요소를 학습했다면, RWKV는 과거 정보의 영향력이 거리에 따라 자연스럽게 감소하는 '시간 감쇠' 메커니즘을 모델 내에 구현하여, 위치 정보를 별도로 주입하지 않고도 시간의 흐름을 학습한다.
Time-mixing의 R,K,V와 Channel-mixing의 R',K'은 현재와 과거 time step간의 선형 보간으로 생성
WKV 연산자
Time-mixing 내부를 보면 K와 V가 WKV 연산자를 지나친다.
W(가중치)+KV(키+값)으로서 어텐션처럼 중요한 과거를 RNN처럼 효율적으로 고르게 하는 파트라고 볼 수 있다.
위의 식은 AFT와 매우 흡사하지만 우선 각 시점 거리 쌍(t,i)마다 고유한 가중치를 두어 각각의 시간과 시차에 직접 의존하는 pairwise가 아닌 channel-wise 벡터이므로 각 특징 채널마다 감쇠율 w를 두어 특징마다 고유의 패턴을 가지게되고, 이는 가중치가 오직 시차(t-i)만 고려하므로(=쌍별 매개변수X), RNN처럼 재귀적 갱신이 가능하다.
출력 게이팅(Output Gating)
Time-Mixing과 Channel-Mixing에서 출력될때, 출력 게이팅을 지나친다. 지금 K와 V는 WKV연산자를 지나고 R (receptance)는 시그모이드 σ(r)활성화 함수를 통과하여 출력이 된다. 그리고 이 두 값을 합성곱하고 가중치를 곱해 gating하게 된다.
.
Transformer-유사학습
RWKV는 Transformer와 RNN의 구조를 결합한다고 했다. 여기서 Transformer 구조는 학습에서 사용된다.
RWKV엔 time-parallel 모드를 사용해 효율적인 병렬화가 가능하다.
하나의 블록엔 모든 시점 t를 한번에 처리가능한 완전 병렬 가능 연산이 있고, WKV 갱신처럼 이전 결과가 필요한 직렬 연산이 있다.
그래서 완전 병렬 가능 연산은 배치, 시간 축에서 한번에 처리를 하고, 직렬 연산인 WKV만 스캔으로 처리해서 훈련은 빠르게 병렬, 결합은 RNN처럼 선형시간으로 처리하게된다.
RNN-유사추론
RNN은 t시점의 출력을 t+1시점의 input으로 사용하면서 "recurrent"를 하게된다.
RWKV를 이에 착안해 만든 time-sequential 모드를 사용해 긴 시퀀스에 대한 효율적인 추론이 가능하다.
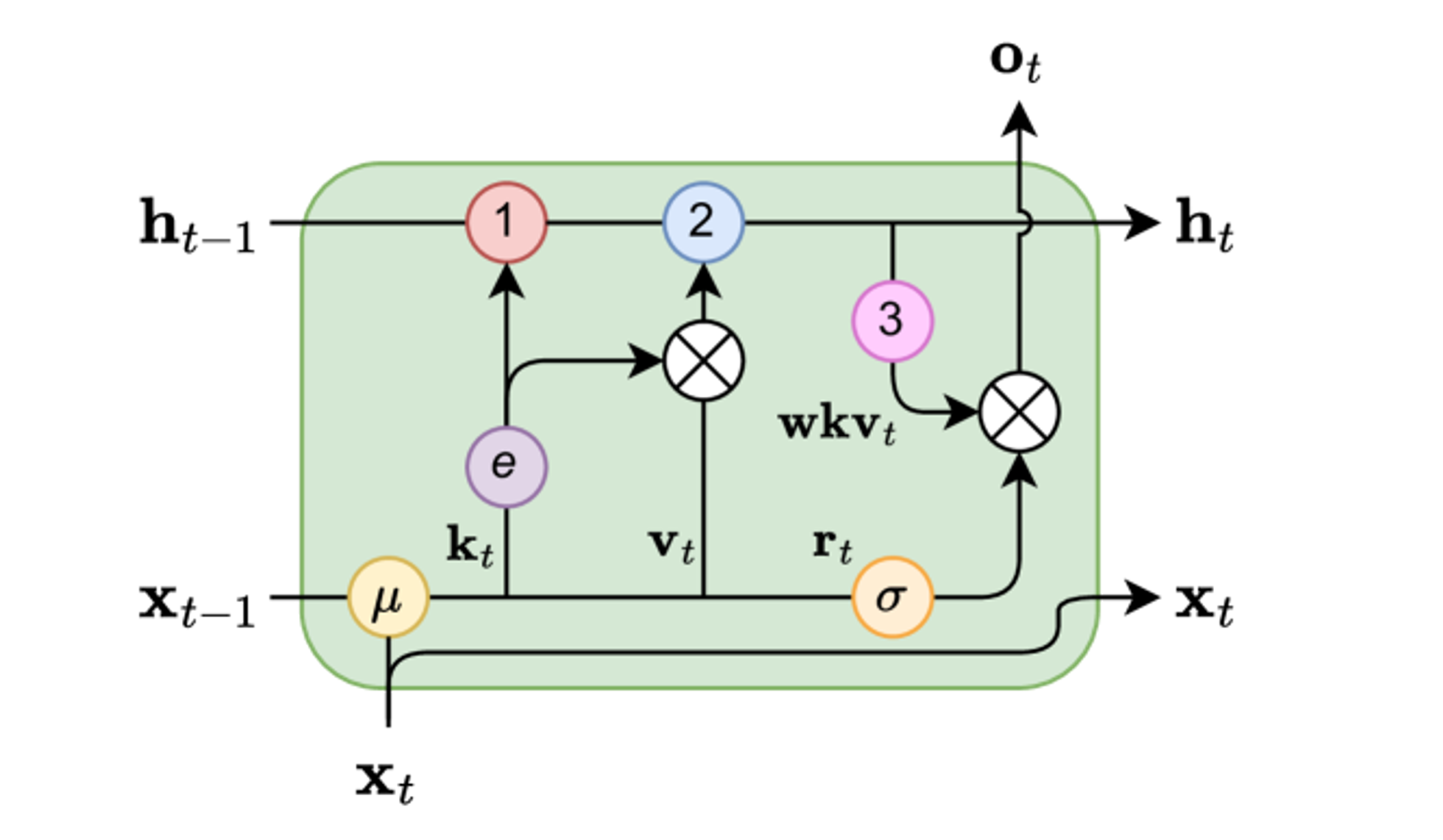
본래 RNN은 위와 같은 형태로 이전 상태를 현재상태로 넘긴다.
RWKV에서도 Layer마다 상태가 존재하고, 이 상태는 WKV의 누적치를 의미한다.
- ,는 실질적 채널별 히든 상태
- ,는 입력 에 대한 key, value
- 는 채널별 감쇠율
- 현재 토큰 가중치를 보정하는 상수 벡터
다시말해, 는 과거의 중요한 요약인 A, B와 현재의 값인 k, v를 적절히 섞어 정규화된 평균이다.
자기 회귀 디코딩
- 입력 준비: 직전 출력 토큰을 임베딩해 얻기
- Token shift 보간: 과 혼합해 ,,에 들어갈 입력 구성
- 입력 토큰 R/K/V로 사영
- WKV 상태 갱신(재귀)
- 출력 게이팅
- LayerNorm -> 선형 -> softmax로 다음 토큰 결정
- , 에 상태 저장 후 t+1으로
결과적으로
RWKV는 RNN의 재귀상태, 상수 메모리, 온라인성을 그대로 살린다.
또한 Attention의 정규화된 가중 평균을 상태 갱신에 첨가하는 형태.
그래서 훈련은 Transformer처럼, 추론은 RNN처럼 하는 하이브리드 형태라고 보면된다.
RWKV과 RNN
RNN을 이해하는데 RWKV를 활용한 것이므로 조금은 정리가 필요할 것 같다.
처음에 말했듯이 RNN은 Recurrent를 통해 과거의 정보를 포함시켜 그 맥락을 파악한 결과를 반환하는데 매우 큰 도움을 준다고 했다.
결국 RNN은 선형 시간에 강하며, 메모리 효율이 좋다는 강점이 있었지만, 시간축에서 비병렬성으로 훈련이 느리고, 기울기 소실및 폭발이 일어나며, 과거의 정보에 대해 어떤 정보가 중요한지를 못고르는 문제점이 있었다.
그래서 RWKV는 어텐션을 활용한 가중평균을 RNN 형태의 업데이트인 재귀 갱신 형태로 구현한다는 핵심 아이디어를 활용한다.
WKV 연산자, 채널별 감쇠율, 토큰 변환, 게이팅, 안정성 보강(LayerNorm + 잔차)를 통해 훈련은 transformer처럼 병렬화 가능하게 했고, 추론에선 WKV값을 RNN처럼 재귀 상태로 계산하여, RNN처럼 메모리 효율을 가져갔다.
즉, 다음과 같은 느낌으로 RNN을 발전시킨 것이다.
Transformer: 회의에서 모든 사람 말을 전부 듣고(쌍별 상호작용) 판단 → 정확하지만 비용 큼.
전통 RNN: 직전 메모 요약만 들으며 진행 → 싸지만 뭘 들어야 할지 약함.
RWKV: “직전까지의 요약을 지수감쇠로 관리하면서도, 키(콘텐츠) 로 정작 중요한 말에 더 귀를 기울이는” 회의 진행 방식.
RWKV에서 찾을 수 있는 RNN의 성질은 다음과 같다.
1. 순차적(재귀) 상태 갱신
2. 상수 메모리 및 선형 시간(추론 과정)
3. 인과성 유지
4. 자기회귀 디쾽
5. BPTT(역전파) 친화구조 (순차구조)
comment
위의 논문을 본 이유는 딥러닝을 차례로 정리하던 중 RNN의 성질이 transformer, Mamba 등으로 넘어가는 것의 구조 변화를 이해하는데 좋을 것이라 생각했다. RNN과 transformer의 장단점을 확실히 이해하고, 딥러닝의 기본인 RNN의 구조와 그 이유를 이해할 수 있고, 추가로 RWKV를 통해 모델 간 구조 융합까지 살펴볼 수 있는 좋은 논문이라고 생각한다.
