[CoinWhale] 2. "초당 9,100건이 쏟아진다면?" - Kafka 18개 토픽 설계와 Python 비동기 수집기
암호화폐 실시간 데이터 파이프라인 & 퀀트 구축기
시리즈: 암호화폐 실시간 데이터 파이프라인 & 퀀트 자동매매 구축기
파이프라인 시리즈 2편 — Kafka 18개 토픽 설계와 Python Collector 구현
🏗️ 1. 왜 하필 18개 토픽인가?
데이터 파이프라인을 처음 기획할 때는 아주 단순하게 생각했습니다.
"비트코인(BTCUSDT) 체결 데이터 하나만 받아서 분석하면 되지 않나?"
하지만 1편에서 언급했듯, 시장의 맥락을 제대로 읽어내려면 단순한 체결 내역 그 이상이 필요합니다.
가격이 움직일 때 거래량은 얼마나 동반되는가?
현재 롱과 숏 중 어느 쪽의 매수세가 더 공격적인가?
청산이 터졌을 때 반대 방향으로 연쇄 작용(캐스케이드)이 일어나는가?
펀딩비가 극단적으로 치솟으면 포지션이 어떻게 풀리는가?
💡 리마인드: 알아두면 좋은 기본 용어
롱 / 숏*: 가격 상승을 예상하면 롱(매수), 하락을 예상하면 숏(매도) 포지션을 취합니다.
청산: 손실이 커져 증거금을 모두 잃었을 때, 거래소가 강제로 포지션을 정리하는 현상.
펀딩비: 영구 선물 시장에서 시장 가격을 현물 가격에 맞추기 위해 8시간마다 주고받는 수수료. 시장의 과열 여부를 보여주는 핵심 지표입니다.
이 질문들에 실시간으로 답하기 위해서는 각각 다른 Binance 데이터 스트림을 조합해야만 했습니다. 핵심 지표들을 커버하기 위해 도출된 결론이 바로 선물 13개 + 현물 5개 = 총 18개의 Kafka 토픽입니다.
이번 글에서는 이 18개의 토픽이 어떤 기준으로 나뉘었고, Python을 활용한 비동기(Async) Collector가 여러 심볼(코인)을 어떻게 안정적으로 수집해 내는지 파헤쳐보겠습니다.
📊 2. 토픽 구조 한눈에 보기
2-1. 선물(Futures) 13개 토픽
| 토픽 | Binance 스트림 | 용도 | 수집 방식 |
|---|---|---|---|
| binance-trade | aggTrade | 체결 데이터 (CVD 계산) | WS (실시간) |
| binance-depth | depth@100ms | 호가창 스냅샷 | WS (실시간) |
| binance-kline | kline_1m | 1분봉 | WS (실시간) |
| binance-bookticker | bookTicker | 최우선 매수/매도 호가 | WS (실시간) |
| binance-liquidation | forceOrder | 강제 청산 내역 | WS (실시간) |
| binance-markprice | markPrice@1s | 마크 가격 + 펀딩비 | WS (실시간) |
| binance-ticker | miniTicker, ticker | 24h 시장 요약 | WS (실시간) |
| binance-composite-index | compositeIndex | BTC 복합 지수 | WS (실시간) |
| binance-openinterest | openInterest | 미결제약정(OI) | REST (10초 주기) |
| binance-ls-ratio | globalLongShortAccountRatio | 전체 롱숏 비율 | REST (5분 주기) |
| binance-top-ls-account | topLongShortAccountRatio | 상위 트레이더 계정 기준 | REST (5분 주기) |
| binance-top-ls-position | topLongShortPositionRatio | 상위 트레이더 포지션 기준 | REST (5분 주기) |
| binance-taker-ls-ratio | takerlongshortRatio | 테이커 매수/매도 비율 | REST (5분 주기) |
2-2. 현물(Spot) 5개 토픽
| 토픽 | Binance 스트림 | 용도 | 수집 방식 |
|---|---|---|---|
| spot-trade | aggTrade | 현물 체결 데이터 | WS |
| spot-bookticker | bookTicker | 현물 최우선 호가 | WS |
| spot-kline | kline_1m | 현물 1분봉 | WS |
| spot-depth | depth@100ms | 현물 호가창 스냅샷 | WS |
| spot-ticker | miniTicker, ticker | 현물 시장 요약 | WS |
🤔 왜 이렇게 쪼갰는가? (설계 원칙)
📌 원칙 1: 원시(Raw) 데이터와 파생 집계 데이터의 분리
aggTrade(체결 데이터)는 초당 수백 건씩 쏟아지는 원시 데이터지만, L/S Ratio나 OI는 거래소가 주기적으로 계산해 주는 파생 데이터입니다. 성격이 다른 두 데이터를 섞으면 후속 파이프라인(Spark) 처리가 꼬입니다. 폭주하는 데이터는 WebSocket으로 받고, 집계값은 REST API로 폴링하도록 아키텍처를 분리했습니다.
📌 원칙 2: 선물과 현물 데이터의 엄격한 격리
선물과 현물은 가격도 다르며 가격 형성 메커니즘 자체가 다릅니다. CVD 같은 핵심 시그널을 계산할 때 두 체결 데이터를 한 토픽에 섞으면 최악의 노이즈가 됩니다. 따라서 binance-(선물)와 spot- prefix(현물)를 두어 원천 차단했습니다.
📌 원칙 3: Burst 패턴 분산 (L/S Ratio 토픽 분리)
Binance가 제공하는 4종의 Long/Short Ratio 데이터는 5분마다 한꺼번에 쏟아지는 Burst 패턴을 보입니다. 평소 4분 59초 동안은 단 1건의 데이터도 없다가, 00초 정각이 되는 순간 4개의 비율 데이터가 0.1초 만에 쾅 하고 쏟아지는 현상입니다.
"어차피 5분마다 한 번씩 오는 건데 그냥 토픽 1개에 넣으면 안 되나?"라고 생각할 수 있습니다. 하지만 카프카 토픽 1개에 4종류를 다 밀어 넣으면, 뒤단의 Spark가 데이터를 꺼낼 때마다
if type == 'global'
...
else if type == 'top'
...하며 매번 박스를 까보고 분류해야 합니다.
반면 수집 단계에서 이를 4개의 개별 토픽으로 나누어놓으면, Spark 컨슈머 워커 4개는 각자 자기 토픽에 파이프만 꽂고 "여기 있는 건 전부 Global 데이터야!" 하며 묻지도 따지지도 않고 병렬로 계산만 하면 됩니다. 순간적인 렉(Lag)을 없애는 핵심 설계입니다.
🔀 3. 토픽 매핑: 코드로 보는 라우팅 구조
파이프라인 중앙에서 라우팅 역할을 담당하는 common/config.py의 핵심 매핑 로직입니다.
선물 토픽 매핑
TOPIC_MAP = {
"bookTicker": "binance-bookticker",
"depth": "binance-depth",
"trade": "binance-trade",
"aggTrade": "binance-trade", # trade와 통합 처리
"kline": "binance-kline",
"forceOrder": "binance-liquidation",
"markPrice": "binance-markprice",
#... (생략)
"miniTicker": "binance-ticker", # ticker와 통합 처리
"ticker": "binance-ticker",
}주목할 점은 trade와 aggTrade를 같은 binance-trade 토픽으로 묶었다는 것입니다. 거래소 측에선 별개의 스트림이지만, 파이프라인 관점에서는 모두 동일한 '체결 데이터'이므로 통합 처리하는 것이 효율적입니다.
@classmethod
def get_topic(cls, stream_name: str, market_type: str = "futures") -> str:
"""스트림 이름으로 매핑된 Kafka 토픽명 반환"""
topic_map = cls.SPOT_TOPIC_MAP if market_type == "spot" else cls.TOPIC_MAP
for key, topic in topic_map.items():
if key in stream_name:
return topic
return "binance-other" # Fallback 방어 로직이 get_topic 함수는 '자동 분류기'입니다. WebSocket으로 btcusdt@aggTrade 같은 동적인 스트림 문자열이 무작위로 쏟아져 들어올 때, 이 코드가 재빠르게 딕셔너리를 스캔하여 binance-trade라는 알맞은 카프카 토픽 상자로 데이터로 던져주는 역할을 합니다. 앞서 말한 'Spark의 if문 생략'이 바로 여기서 완성됩니다..
⚙️ 4. Collector 아키텍처: 5개 WS + 2개 REST
I/O 바운드(네트워크 대기) 작업이 주를 이루는 코인 데이터 수집기 특성상, 일반적인 멀티스레딩 대신 Python asyncio 기반의 비동기 아키텍처를 채택했습니다.
💡 멀티스레딩 vs Asyncio(비동기)의 차이?
멀티스레딩이 여러 명의 일꾼을 고용해 번갈아 일하게 하는 것이라면, 비동기는 단 한 명의 일꾼이 50명과 동시에 체스를 두는 고수와 같습니다. 상대방(거래소)이 수를 생각하는 시간(네트워크 응답 대기 시간) 동안 다른 체스판의 말을 움직이기 때문에, 일꾼이 자리를 바꾸는 체력 소모(Context Switching)가 전혀 없어 가볍고 빠릅니다.
4-1. 클래스 구조 (장애 격리 및 공통 뼈대)
BaseBinanceCollector (ABC) # 공통 뼈대 (연결, 에러처리, Kafka 전송 로직 등)
├─ DepthKlineAggTradeCollector # 1. 선물 핵심 (depth, kline, aggTrade)
├─ FuturesInsightCollector # 2. 선물 추가 (liquidation, markPrice, bookTicker)
├─ MarketMetricsCollector # 3. 선물 요약 (miniTicker, ticker, compositeIndex)
├─ SpotCollector # 4. 현물 핵심 (aggTrade, bookTicker, kline, depth)
└─ SpotTickerCollector # 5. 현물 요약 (miniTicker, ticker)
OpenInterestPoller (REST) # 6. OI 10초 주기 폴링
LongShortRatioPoller (REST) # 7. L/S Ratio 5분 주기 폴링BaseBinanceCollector를 추상 기반 클래스로 두어 소켓 연결, 재연결, Kafka 전송 등 똑같이 반복되는 메인 로직을 부모 클래스에 템플릿화했습니다.
여기서 가장 중요한 질문이 나옵니다.
"수집해야 할 토픽이 18개인데, 왜 WebSocket 수집기는 5개밖에 없나요?"
바이낸스 WebSocket은 연결할 때 /stream?streams=trade/depth/kline 처럼 여러 스트림을 한 번에 묶어서 요청할 수 있습니다. 그렇다면 다음과 같은 딜레마가 생깁니다.
왜 18개(각각 1개씩)로 안 쪼갰나?: 18개 토픽에 맞춰 소켓을 열면 코인 3개 기준 총 54개의 소켓이 열립니다. 거래소 방화벽에서 디도스(DDoS)로 간주하고 IP 밴(Ban)을 먹일 확률이 높고, Python 서버의 관리 오버헤드도 커집니다.
왜 1개의 커넥션(최대 200개 구독 가능)에 다 몰아넣지 않았나?: 장애 격리 때문입니다. 뒤에서 보시겠지만 전체 트래픽의 80%는 호가창(bookTicker)에서 나옵니다. 만약 호가창 데이터가 폭주해서 1개뿐인 소켓 버퍼가 터지면, 가장 중요한 체결 데이터까지 통째로 끊어지는 대참사가 발생합니다.
따라서 "동시에 죽어도 타격이 적은, 성격이 비슷한 데이터끼리" 5개의 논리적인 그룹으로 묶어 5대의 수집기에 나눠 싣게 된 것입니다. 네트워크 효율성과 안정성 사이의 타협점입니다.
4-2. 재연결 전략: 지수 백오프 (Exponential Backoff)
서버 점검, 네트워크 불안정 등 WebSocket은 무조건 한 번은 끊어집니다. (바이낸스는 정책상 24시간마다 한 번씩 강제로 커넥션을 날려버립니다.)
이때 while True 루프로 즉시 재연결을 시도하면 거래소 측 방화벽에서 악성 디도스 공격으로 간주해 IP를 밴해버립니다. 고장 난 엘리베이터의 닫힘 버튼을 미친 듯이 연타한다고 문이 빨리 고쳐지지 않는 것과 같습니다.
reconnect_delay = 3 # 첫 재연결 대기
max_delay = 60 # 최대 60초 캡
while self.running:
try:
async with websockets.connect(self.url) as ws:
reconnect_delay = 3 # 연결 성공 시 초기화
while self.running:
msg = await asyncio.wait_for(ws.recv(), timeout=1.0)
# ... 처리 로직 ...
except websockets.exceptions.ConnectionClosed:
pass
# 지수 백오프: 3초 -> 6초 -> 12초 -> 24초 -> 48초 -> 60초
await asyncio.sleep(reconnect_delay)
reconnect_delay = min(reconnect_delay * 2, max_delay)4-3. 멀티 심볼 확장 (asyncio.gather)
현재 시스템은 단일 코인을 넘어 BTC, ETH, SOL 3개의 심볼을 동시에 수집합니다.
async def main():
symbols = Config.COLLECT_SYMBOLS # ["BTCUSDT", "ETHUSDT", "SOLUSDT"]
tasks = []
for symbol in symbols:
ws_collectors, rest_pollers = create_collectors_for_symbol(symbol)
tasks.extend([c.run() for c in ws_collectors + rest_pollers])
# 심볼 3개 × (WS 5개 + REST 2개) = 총 21개 비동기 코루틴 동시 실행
await asyncio.gather(*tasks)
여기서 일반적인 for 반복문 안에 await를 걸지 않고 asyncio.gather를 사용한 분명한 이유가 있습니다.
for문 안에서 await를 걸면 비트코인(BTC) 5개 소켓을 다 연결하고 나서야 이더리움(ETH) 연결을 시도하는 직렬 처리가 됩니다. 하지만 gather를 사용하면 21개의 거대한 수집 태스크가 1개의 이벤트 루프 위에서 동시에 출발(병렬성 확보)하여 무서운 속도로 데이터를 빨아들이게 됩니다.
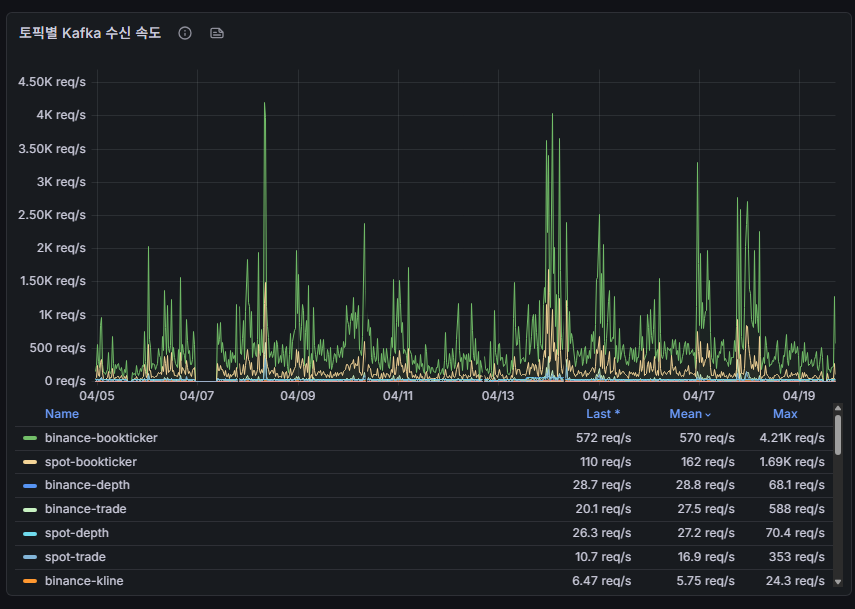
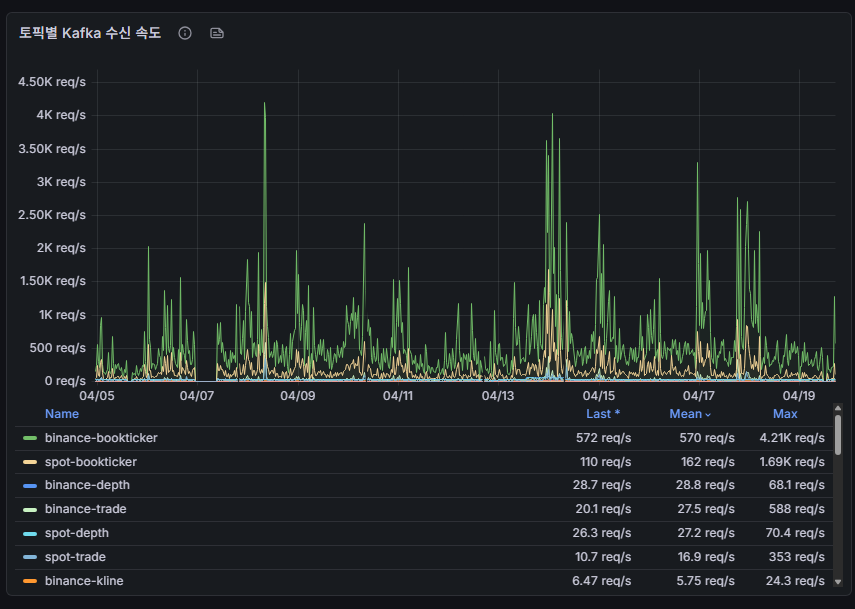
📈 5. 멀티 심볼 TPS 실측 데이터 분석 (평균 830, 최대 9,100)
데이터 파이프라인의 내구성은 잔잔한 횡보장이 아니라 극단적인 변동성 장세에서 증명됩니다.
현재 코인웨일 시스템의 Kafka 수신 트래픽은 시장 상황에 따라 고무줄처럼 변합니다. 플래시 크래시(Flash Crash)나 대규모 롱스퀴즈가 터지는 역대급 폭락/폭등장에서는 주문과 체결 데이터가 폭우처럼 쏟아지며 순간 최대 9,100 TPS (Peak)까지 트래픽이 수직 상승했습니다. 반면 최근과 같은 잔잔한 장세에서는 평균 약 800대, 최대 4~5,000 수준의 안정적인 트래픽을 보여줍니다.
5-1. 토픽별 트래픽 수신 속도 (최근 실무 Grafana 데이터)
아래는 최근 24시간 기준 Kafka로 인입되는 주요 바이낸스 토픽들의 실측 속도(req/s)입니다. 전부 합산 시 평균 약 780 TPS를 쉴 새 없이 처리하고 있습니다.
| Topic Name | Mean (평균) | Max (최대) | 비고 |
|---|---|---|---|
| binance-bookticker | 572 req/s | 4.21K req/s | 최우선 호가 (선물) |
| spot-bookticker | 110 req/s | 1.69K req/s | 최우선 호가 (현물) |
| binance-depth | 28.7 req/s | 68.1 req/s | 호가창 스냅샷 |
| spot-depth | 26.3 req/s | 70.4 req/s | 현물 호가창 스냅샷 |
| binance-trade | 20.1 req/s | 588 req/s | 선물 체결 내역 |
| spot-trade | 10.7 req/s | 353 req/s | 현물 체결 내역 |
| binance-kline | 6.47 req/s | 24.3 req/s | 1분봉 |
| spot-ticker | 5.51 req/s | 13.9 req/s | 현물 24h 요약 |
| binance-markprice | 3.00 req/s | 6.22 req/s | 마크 가격 |
| binance-ticker | 2.96 req/s | 6.74 req/s | 선물 24h 요약 |
5-2. 스트림별 트래픽 기여도 (과대평가 주의보)
위 표를 보면 아주 충격적인 사실을 알 수 있습니다. 파이프라인에서 가장 많은 트래픽 비중을 차지하는 것은 흔히 생각하는 체결(trade) 데이터가 아니라, 최우선 호가를 나타내는 bookTicker입니다. 수신량 1, 2위를 다투며 전체의 80% 이상을 점유합니다. (특히 이더리움 데이터가 가장 많습니다)
거래소의 bookTicker는 거래 체결량에 비례하여 발생하는 것이 아니라, '호가창이 아주 미세하게라도 변동될 때마다 즉각 브로드캐스트' 되기 때문입니다. 특히 시장 변동성이 극에 달하는 순간, 무수한 알고리즘 봇들의 1ms 단위 호가 정정 요청이 쏟아지며 이 수치가 미친 듯이 튀어 오르게 됩니다.
📦 6. Kafka Producer & Topic 최적화 세팅
순간적으로 9,100 TPS의 트래픽 쓰나미가 밀려오든, 잔잔한 장세에서 5,000 TPS가 들어오든 수집기가 터지지 않고 버티려면 이 데이터를 Kafka가 지연 없이 꽉 잡아줘야 합니다.
KafkaProducer(
batch_size=32768, # 32KB
linger_ms=10, # 10ms 대기
compression_type='gzip', # 텍스트 압축률 70~80% 극대화
acks='all', # 모든 ISR 동기화 (무결성 보장)
retries=3,
)이 설정들은 물류 센터의 '택배 배송 원리'와 같습니다. 매번 편지가 올 때마다 오토바이를 출발시키면 비효율적이니, 택배 박스(batch_size=32KB)에 편지를 모아서 출발시키는 것입니다.
linger_ms=1(0.01초): 박스가 다 안 찼더라도 0.01초가 지나면 무조건 출발하라는 뜻입니다.
트래픽 폭주 시나리오: 초당 9,100건이 쏟아지면 0.01초가 지나기도 전에 이미 32KB 박스가 꽉 차버립니다. 그러면 기다리지 않고 즉각 꽉 찬 박스를 출발시킵니다. (배치 사이즈를 1MB로 너무 크게 잡으면 트래픽이 적을 때 실시간성이 떨어지므로 32KB가 최적의 타협점입니다.
compression_type='gzip': 32KB 박스가 꽉 차면 출발 직전에 압축(gzip)해서 6~8KB로 만듭니다. 덕분에 네트워크 대역폭 병목을 완전히 돌파할 수 있습니다.
데이터 유실을 막는 장치: acks & retries
acks='all'은 카프카 내부의 원본(Leader) 서버뿐만 아니라 백업(Follower) 서버들까지 하드디스크에 데이터를 완벽하게 저장했을 때만 "잘 받았어!"라는 영수증(ACK)을 파이썬에 보내주는 가장 강력한 무결성 옵션입니다.
여기에 네트워크 지연으로 영수증이 안 올 경우 자동으로 3번 다시 쏴주는 retries=3 옵션을 결합했습니다.
💡 DLQ (Dead Letter Queue)는 블랙박스다
완벽한 세팅에도 불구하고 최종 전송에 실패한 메시지를 공중분해 시키면 악몽이 시작됩니다. 코드 내에 on_failure 콜백을 구현해 실패한 메시지와 에러 로그를 그 즉시 dlq-producer 토픽(반송함)으로 던져 넣었습니다. 파이프라인을 짤 때 DLQ는 0순위 필수 세팅입니다.
🛠️ 7. 실무 운영에서 맞아가며 얻은 교훈
개발 환경과 실서버는 다릅니다. 이 파이프라인을 직접 부딪혀보며 배운 점들입니다.
로그 노이즈를 얕보지 말자 (PM2 최적화)
여러 프로세스가 매초 TPS 로그를 찍어냅니다. 초당 수천 건이 들어오는 상황에서는 로그 자체가 서버 디스크 I/O를 갉아먹는 주범이 됩니다. sys.stdout.isatty()를 활용해 백그라운드 환경에서는 불필요한 콘솔 출력을 완전히 스킵하고, 모니터링은 온전히 Prometheus/Grafana에게 위임했습니다.
API 갱신 주기(Period)를 맹신하지 말자
L/S Ratio 데이터를 최신으로 받겠다고 1분마다 폴링(Polling)해봤자, 거래소 내부 서버 업데이트 주기가 5분이면 똑같은 데이터만 중복으로 쌓입니다. 소스 시스템의 진짜 갱신 주기를 파악해야 합니다.
Key 파티셔닝의 양날의 검 (Hot Partition) (핵심!! ⭐)
코인 심볼(BTCUSDT 등)을 파티션 Key로 사용하여 메시지 순서를 보장했습니다. 하지만 변동성 장세에서 특정 코인(ex. ETH)에 트래픽이 쏠리면 특정 파티션만 죽어라 일하는 병목 현상이 발생합니다. 향후 확장 시 {symbol}-{random_int} 형태로 강제 분산시키고, 순서 정렬은 뒤쪽의 Spark Watermark 기능에 맡기는 방식으로 개선할 예정입니다.(즉, 라운드 로빈으로 데이터를 골고루 받고 스파크에서 순서 기반으로 처리하기)
⏭️ 8. 다음 글 예고
지금까지 상황에 따라 순간 최대 9,100 TPS까지 치솟는 폭발적인 트래픽을 견뎌내며 매일 수천만 건의 원시 데이터를 쏟아붓는 카프카 파이프라인을 건설했습니다.
하지만 이 원시 데이터 자체만으로는 "비트코인 숏스퀴즈 터졌나요?"라는 질문에 대답할 수 없습니다.
다음 편에서는 이 거대한 트래픽을 Apache Spark Structured Streaming이 실시간으로 집어삼켜, 10초 단위의 정제된 Silver 테이블(특히 고래의 매수/매도 압력을 보여주는 핵심 지표, CVD)로 어떻게 변환해 내는지 그 정교한 아키텍처와 코드를 파헤쳐보겠습니다.
[다음 편] 파이프라인 3편: Spark Structured Streaming과 CVD 실시간 집계 로직🔥
본 시리즈는 개인적인 학습과 실무 적용 과정을 기록한 것으로, 완벽한 정답이 아닐 수 있습니다.
글을 읽으시며 발견하신 오류나 더 나은 개선 방향이 있다면 댓글로 자유롭게 의견을 남겨주시면 감사하겠습니다. 함께 성장해 나가는 기록이 되었으면 좋겠습니다!
