[CoinWhale] 3. "고래의 숨겨진 매수세를 10초 만에 포착하는 법" - Spark 실시간 집계와 메달리온 아키텍처(Silver)
암호화폐 실시간 데이터 파이프라인 & 퀀트 구축기
시리즈: 암호화폐 실시간 데이터 파이프라인 & 퀀트 자동매매 구축기
파이프라인 시리즈 3편 — Spark Structured Streaming + 7개 Silver 집계
이 글은 초기 안정 운영 버전(v1)을 기준으로 정리했습니다.
당시 기준(26.3월)은 토픽당 기본 3파티션, key=symbol 기반 파티셔닝, 10초 집계였습니다.
이후에 들어간 처리 구조 개선은 의도적으로 빼고, "원래 Silver 레이어를 어떻게 설계했는가"에만 집중합니다.
1. 들어가며: Raw 데이터를 지표로 바꾸는 레이어
이전 글에서는 Python Collector가 Binance WebSocket과 REST API 데이터를 받아 Kafka의 18개 토픽에 밀어 넣는 구조를 살펴봤습니다.
브론즈 단계의 데이터는 아직 원본(Raw Data)에 가깝습니다.
JSON 문자열이 그대로 들어오며, 같은 코인 심볼이라도 토픽별로 의미가 다릅니다.
대시보드나 AI 시그널 엔진, 자동매매(퀀트, 멀티 에이전트)가 바로 가져다 쓰기엔 데이터가 너무 방대하고 정제가 되어있지 않습니다. 그래서 중간에 데이터를 한 번 더 깔끔하게 정리해 주는 레이어가 필요했습니다. 그것이 바로 Spark Structured Streaming 기반의 Silver 레이어입니다.
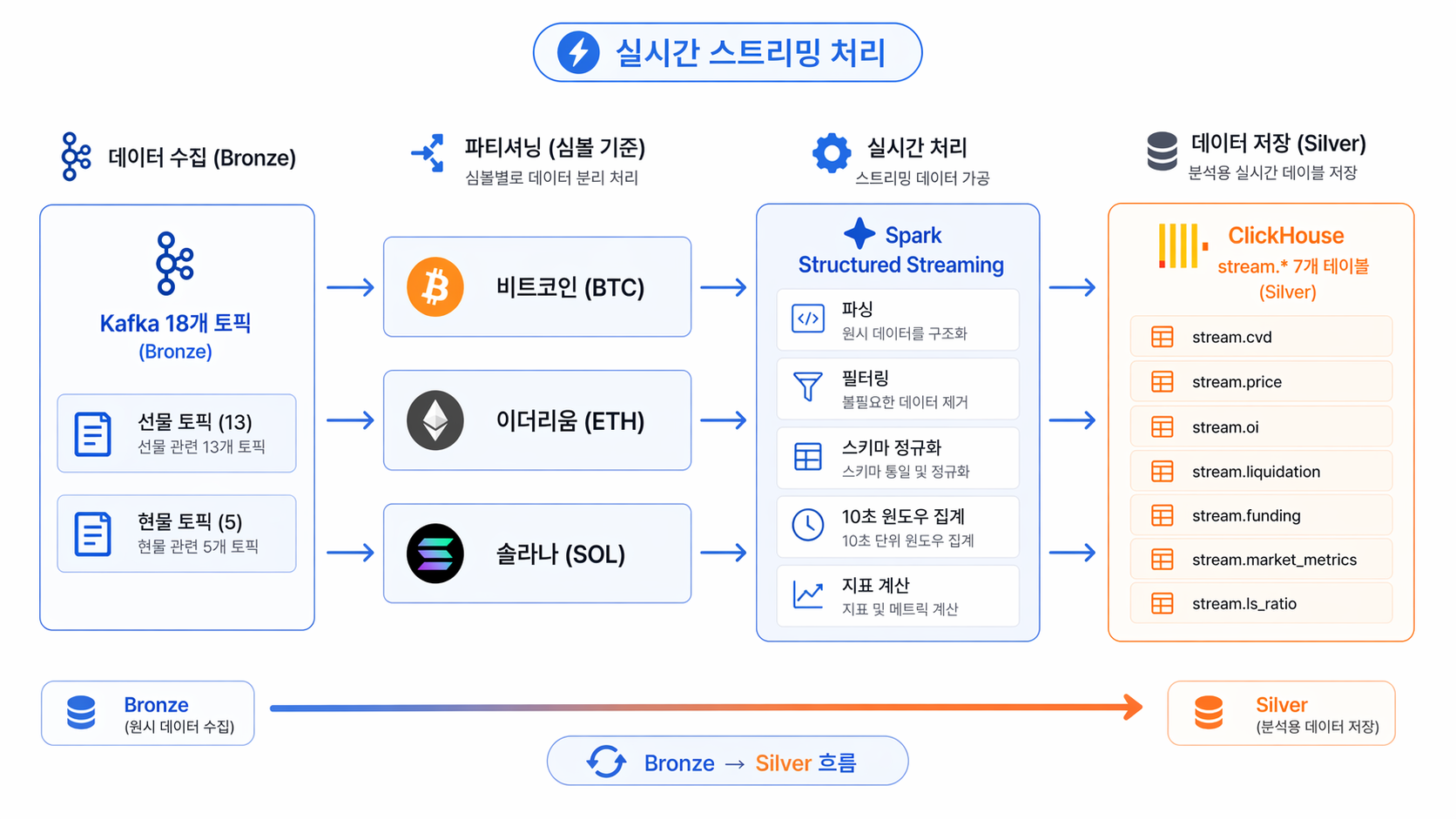
📊 다이어그램 설명
위 다이어그램은 원시 데이터(Bronze)가 정제된 지표(Silver)로 변환되는 전체 흐름을 보여줍니다.
데이터 수집 (Bronze): Kafka 18개 토픽에 선물/현물 원시 데이터가 쌓입니다.
파티셔닝: 심볼(BTC, ETH, SOL) 기준으로 트래픽을 나누어 병렬 처리의 기반을 다집니다.
실시간 처리 (Spark): 스트리밍 데이터를 파싱 및 필터링하고, 10초 윈도우로 묶어 핵심 지표를 계산합니다.
데이터 저장 (Silver): 최종 계산된 7개의 지표가 ClickHouse의 stream.* 테이블로 실시간 적재됩니다.
💡 용어를 간단하게 정리해 볼까요?
Structured Streaming: 정해진 주기마다 데이터를 끊어서 처리하는 Spark의 실시간 스트리밍 처리 기술입니다.
윈도우(Window): 데이터를 묶는 시간 구간입니다. (예: 10초 단위로 묶기)
Watermark (워터마크): 네트워크 지연 등으로 너무 늦게 도착한 지각생 데이터를 '어디까지(몇 초까지) 허용하고 계산에 포함할지' 정하는 기준선입니다.
Checkpoint (체크포인트): Spark가 장애로 꺼졌을 때를 대비해 "나 여기까지 읽고 처리했어"라고 디스크에 저장해 두는 복구 지점입니다.
2. 🐼 실시간 데이터 처리에 Pandas 대신 Spark를 선택한 이유
데이터 정제 레이어를 설계할 때, 파이썬에 익숙한 분들이라면 자연스럽게 Pandas를 먼저 떠올리실 수 있습니다. "Kafka에서 데이터를 빼와서 Pandas DataFrame으로 만들고 10초마다 묶어서 계산하면 되지 않나?"라는 생각이 드는 것도 무리가 아닙니다.
하지만 데이터를 메모리에 한 번에 올리는(Batch) Pandas와 끊임없이 흐르는 물줄기를 처리하는(Streaming) Spark는 철학부터가 완전히 다릅니다. 구체적으로 아래와 같은 핵심적인 차이점들이 있습니다.
1) 데이터 적재 방식: 전체 메모리 vs 마이크로 배치
Pandas: 데이터프레임을 생성할 때 모든 데이터를 RAM에 한 번에 몽땅 올려야 합니다. 데이터에 끝이 있다면 훌륭하지만, 24시간 끊임없이 들어오는 암호화폐 데이터를 판다스로 받다가는 금방 메모리가 터져버립니다(OOM).
Spark: 스트리밍 모드에서는 한 번에 데이터를 다 품는 게 아니라, 정해진 시간(예: 10초) 단위로 데이터를 퍼내서(Micro-batch) 처리하고 결과를 넘긴 뒤 메모리를 비웁니다.
2) 실행 방식: 즉시 실행(Eager) vs 지연 평가(Lazy Evaluation)
Pandas: 코드를 한 줄 칠 때마다 즉시 연산을 수행합니다.
Spark: select, filter, groupBy 같은 코드를 짜도 당장 실행하지 않습니다. 대신 '어떻게 계산할지' 계획(DAG)만 미리 짜두고, 마지막에 결과를 출력하라는 명령이 떨어지면 그제서야 가장 최적화된 경로로 한 번에 연산을 밀어버립니다.
3) 연산 구조: 단일 노드 vs 분산 처리 (수평 확장)
Pandas: 기본적으로 컴퓨터 한 대(싱글 코어)에서 돌아갑니다. 트래픽이 2배가 되면 서버 사양을 높이는 것(Scale-up) 외엔 답이 없습니다.
Spark: 처음부터 여러 대의 컴퓨터(Worker)가 일을 나눠서 하도록 설계된 분산 엔진입니다. 데이터가 폭주하면 단순하게 워커 컨테이너를 늘리는 것(Scale-out)만으로 대응이 가능합니다.
4) 내결함성(Fault Tolerance): 죽었을 때의 복구 능력
Pandas: 서버가 꺼지면 메모리 안의 데이터는 증발합니다. 어디까지 처리했는지 알 길이 없습니다.
Spark: 데이터를 처리할 때마다 Checkpoint에 "어디까지 읽었는지(Offset)"를 기록합니다. 중간에 서버가 죽었다 살아나도 정확히 멈춘 곳부터 다시 데이터를 빨아들여 유실 없는 처리를 보장합니다.
이러한 이유로, 대규모 실시간 파이프라인의 심장 역할은 Pandas가 아닌 Spark에게 맡길 수밖에 없었습니다.
3. 당시 운영 기준: 3파티션 + symbol key + 10초 집계
파이프라인을 처음 구축하던 초창기 버전(v1)에서는 복잡한 튜닝보다는 가장 직관적이고 이해하기 쉬운 구조를 택했습니다.
우선 Kafka 토픽은 기본이 되는 3개의 파티션으로 구성했고, 데이터를 집어넣을 때는 헷갈리지 않게 코인 종류(BTC, ETH 등)를 뜻하는 key=symbol을 기준으로 가지런히 나누어 담았습니다. 그리고 이 데이터를 처리하는 Spark 역시 대부분 '10초 단위 윈도우'와 '10초 트리거'라는 단순한 규칙을 적용했죠.
이러한 운영 기준이 실제 코드에서는 어떻게 설정되어 있는지 핵심 옵션 세 가지만 잠깐 살펴볼까요?
WINDOW_DURATION = "10 seconds"
TRIGGER_INTERVAL = "10 seconds"
WATERMARK_DELAY = "30 seconds"이 세 가지 옵션이 의미하는 바는 다음과 같습니다.
WINDOW_DURATION (10초): "들어온 데이터를 10초 단위의 시간 박스에 담아서 집계하겠다"는 뜻입니다. (예: 12:00:00 ~ 12:00:10 묶음)
TRIGGER_INTERVAL (10초): "실제로 계산 작업(배치)을 10초에 한 번씩 실행하겠다"는 뜻입니다.
WATERMARK_DELAY (30초): 스트리밍 처리에서 아주 중요한 개념입니다. 네트워크 지연 등으로 10초 윈도우를 놓친 '지각생 데이터'도 "30초 전 데이터까지는 다시 계산에 포함시켜 줄게"라는 뜻입니다. 만약 30초를 넘겨서 너무 늦게 도착한 데이터는 스파크 메모리 보호를 위해 과감하게 버려집니다(Drop).
💡 FAQ 1: 워터마크를 30초로 잡으면 차트에 고래 마커, 표시 등도 30초 늦게 업데이트되나요?
절대 아닙니다! 스파크는 10초(TRIGGER_INTERVAL)가 지나면 워터마크를 기다려주지 않고 일단 지금까지 계산된 결과를 즉각 ClickHouse DB로 쏴버립니다. 대시보드와 자동매매 시그널은 단 1초의 지연도 없이 10초마다 즉시 발동됩니다.
그렇다면 워터마크 30초는 왜 필요할까요? 바로 "수정본을 받아주는 애프터서비스(A/S) 기간"입니다.
트래픽이 폭주해서 세력의 거대한 매수 체결 데이터가 11초 만에 늦게 도착했다고 가정해 봅시다. 스파크는 이 데이터를 버리지 않고, 아까 DB에 보냈던 10초 치 결과를 다시 수정 계산해서 DB로 잽싸게 수정본을 다시 쏴줍니다. 워터마크는 출력을 지연시키는 게 아니라, 지각한 핵심 데이터가 영영 날아가는 것을 막아주는 든든한 방어막입니다.
💡 FAQ 2: 왜 하필 '30초'인가요? 30초를 넘겨서 버려진 데이터는 어떻게 복구하나요?
"안전하게 워터마크를 5분으로 넉넉하게 잡으면 안 되나요?"라는 질문이 생길 수 있습니다. 하지만 워터마크를 무작정 길게 잡으면 스파크가 메모리에 품고 있어야 하는 데이터가 기하급수적으로 커져 OOM(메모리 부족) 에러의 주범이 됩니다.
1) 30초의 근거 (Kafka Lateness Audit)
무작정 시간을 정한 것이 아닙니다. 거래소 이벤트 발생 시점부터 파이프라인의 입구인 Kafka에 도착하기까지의 지연 시간을 실시간으로 추적했습니다. 분석 결과, 트래픽이 몰리는 주요 토픽들의 상위 1%(p99) 지연 시간이 최대 약 13.97초로 측정되었습니다. 즉, 99% 이상의 데이터가 14초 안에 카프카에 도착하므로 30초면 매우 안전한 방어선입니다.
2) 30초를 넘겨서 버려진 데이터의 복구 (Airflow 결손 보정)
그럼에도 네트워크 대장애가 발생해 30초를 넘겨 스파크에서 버려진(Drop) 데이터는 어떻게 할까요? 워터마크를 늘려 스파크를 무겁게 만드는 대신, Airflow를 활용한 '결손 구간 보정(Gap Correction)' 방식을 진행 중입니다.
Airflow가 5분마다 ClickHouse 결과 테이블에 비어있는 시간대(Gap)가 있는지 검사합니다.
만약 누락된 구간이 발견되면, 결손이 발생한 특정 구간만 원본 Raw 데이터에서 다시 긁어와 재집계(Backfill)하여 넣습니다.
이 구조 덕분에 실시간 스트리밍의 '가벼움'과 배치(Batch) 처리의 '완벽한 정합성'을 동시에 달성할 수 있었습니다. 최근 검증에서도 이 방식이 완벽하게 동작하며 현재 설정된 30초 워터마크만으로도 데이터 결손 없이 파이프라인이 안정적으로 유지됨을 확인했습니다.
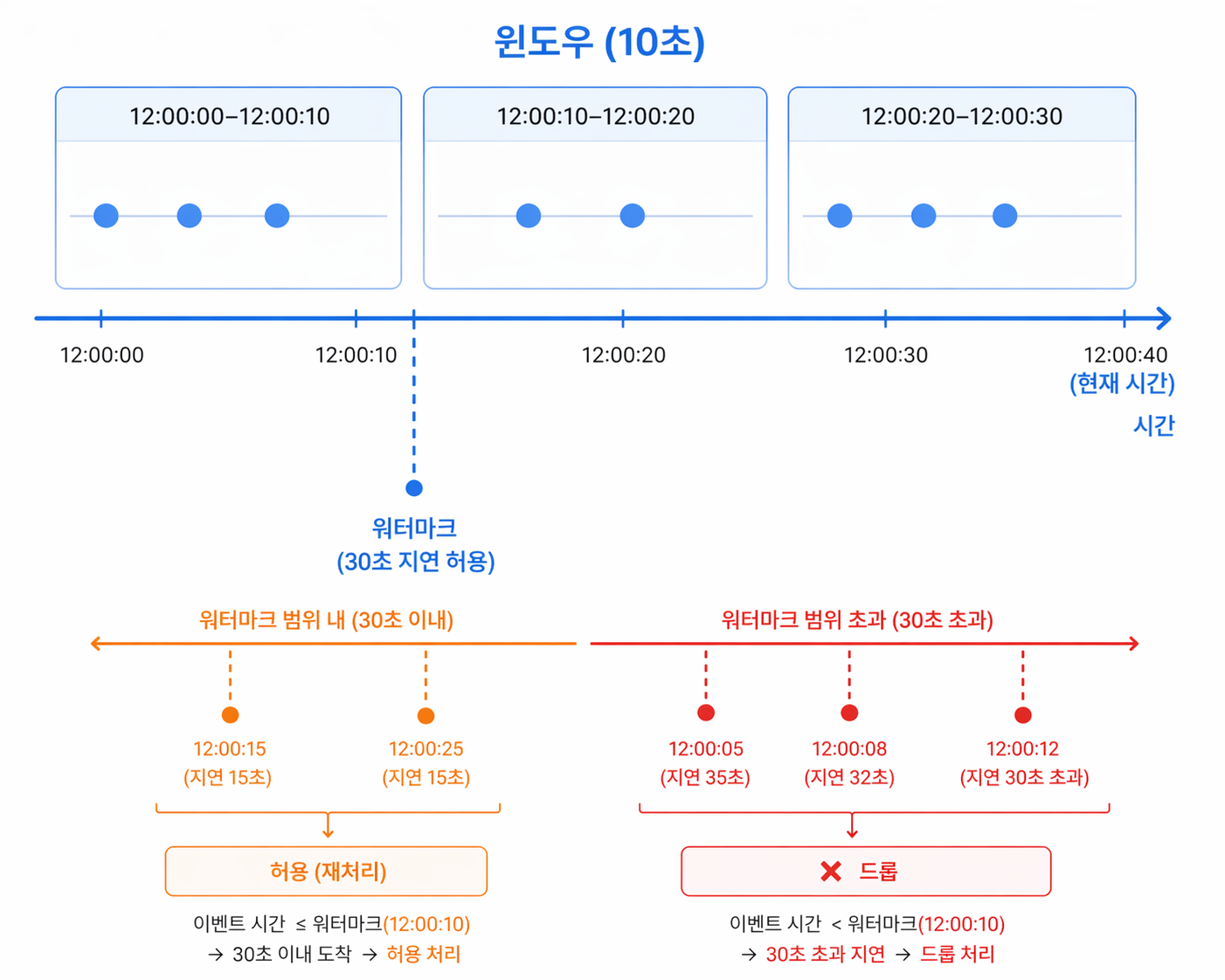
📊 다이어그램 설명
위 그림을 보면 10초 단위의 윈도우(파란색 박스)로 데이터가 묶여서 처리되는 과정을 볼 수 있습니다.
여기서 핵심은 아래쪽의 지각생 데이터(Late Data) 처리입니다. 현재 시간을 기준으로 뒤로 30초의 워터마크(주황색 점선)가 설정되어 있습니다.
주황색 점: 10초 윈도우는 이미 지났지만 아직 워터마크 30초 유예 기간 안에 도착했기 때문에, 스파크가 정상적으로 받아주고 재계산에 포함시킵니다.
빨간색 X: 네트워크 지연이 너무 심해서 워터마크 30초조차 넘겨버린 데이터입니다. 스파크의 메모리 과부하를 막기 위해 이 데이터들은 가차 없이 버려지는 것을 확인할 수 있습니다.
4. 전체 구조: OCP 원칙을 적용한 Plugin 자동 탐색 아키텍처
우리가 ClickHouse(Silver 레이어)에 저장해야 할 지표는 CVD, Price, OI, Funding 등 총 7가지입니다.
4-1. 왜 파이썬 파일 하나에 다 넣지 않았을까요?
처음에는 silver_aggregator.py라는 메인 파일 하나에 7개 로직을 다 넣을까도 생각했습니다. 하지만 금방 문제가 발생합니다.
새로운 지표를 하나 추가할 때마다 잘 돌아가고 있는 메인 파일을 건드려야 하며, 코드가 길어져서 어디서 에러가 났는지 찾기 힘듭니다.
그래서 도입한 것이 객체지향의 핵심 원칙인 개방-폐쇄 원칙(OCP, Open-Closed Principle)을 활용한 자동 탐색 플러그인 구조입니다.
4-2. SilverBase가 만들어주는 자동화
아래처럼 공통 뼈대(SilverBase)를 만들어 둡니다.
class SilverBase(ABC):
# 공통 설정 (토픽명, 테이블명, 윈도우 주기 등)
# 반드시 구현해야 하는 3가지 함수 규칙
@abstractmethod
def parse(self, raw_df): ... # 1. 원본 파싱
@abstractmethod
def aggregate(self, parsed_df): ... # 2. 집계
@abstractmethod
def select_output(self, agg_df): ...# 3. DB 전송그리고 메인 프로그램은 특정 폴더(spark_jobs/silver/)를 지켜보다가, 이 뼈대를 상속받은 파일이 발견되면 메인 코드 수정 없이 알아서 로딩하여 실행합니다.
즉, "기존 코드는 건드리지 않고(Closed), 새로운 기능 추가는 폴더에 파일만 넣으면 되도록(Open)" 구성한 것입니다.
4-3. 1개의 메인 파일, 7개의 독립 쿼리
앞서 4장 도입부에서 우리가 ClickHouse에 저장해야 할 지표가 CVD, Price 등 총 7가지라고 말씀드렸습니다. 그렇다면 플러그인 로더가 이 7개의 설정 파일을 모두 읽어 들이면, 스파크 엔진 내부에서는 어떤 일이 벌어질까요?
결론부터 말씀드리면, 하나의 메인 실행 파일(silver_aggregator.py) 안에서 '7개의 독립적인 스트리밍 쿼리(작업)'가 동시에 돌아가게 됩니다.
어렵게 생각할 것 없이, 하나의 거대한 스파크 공장 안에서 7개의 컨베이어 벨트가 각자의 지표(CVD, OI 등)를 조립해서 쉼 없이 ClickHouse 창고로 보내고 있다고 이해하시면 됩니다.
5. CVD 집계: 선물과 현물을 한 번에 묶는 법
가장 중요한 지표인 CVD (Cumulative Volume Delta)는 공격적 매수 체결량과 매도 체결량의 차이를 보여줍니다.
이 지표의 까다로운 점은 '선물(Futures)' 체결 데이터와 '현물(Spot)' 체결 데이터를 동시에 읽어서 합쳐야 한다는 것입니다.
5-1. 왜 다른 데이터를 굳이 하나로 합치나요?
"선물과 현물은 시장도 다르고 가격도 다른데 왜 하나로 합치나요?"라고 생각하실 수 있습니다.
맞습니다. 시장은 다릅니다. 하지만 바이낸스가 제공하는 체결 데이터(aggTrade)의 형식(스키마)은 완전히 똑같습니다. 만약 이걸 따로따로 처리하면 완전히 똑같은 계산 코드를 두 번 작성해야 합니다.
그래서 스파크의 unionByName 함수를 써서 거대한 하나의 표로 일단 합쳐버립니다. 단, 이때 헷갈리지 않도록 source라는 카테고리 꼬리표를 달아줍니다.
꼬리표 달고 하나의 표로 합치기!
futures_parsed = _kr.parse_trade_data(futures_raw).withColumn("source", lit("futures")) spot_parsed = _kr.parse_spot_trade_data(spot_raw).withColumn("source", lit("spot")) unified = futures_parsed.unionByName(spot_parsed)
5-2. 하나의 수식으로 깔끔하게 분리 출력하기
하나의 표로 합쳐서 똑같은 연산 컨베이어 벨트를 태우지만, 안에서는 우리가 달아둔 source 꼬리표를 보고 결과를 분리합니다.
enriched = (
parsed_df
# 50만 불(약 6.5억 원) 이상 긁으면 고래(Whale)!
.withColumn("is_whale", (col("price") * col("quantity")) >= lit(500_000))
# 꼬리표가 'futures(선물)'이면서 시장가 매수면 '선물 매수량' 컬럼에 담기!
.withColumn(
"futures_taker_buy_qty",
when((col("source") == "futures") & (~col("is_buyer_maker")), col("quantity")).otherwise(0.0),
)
# ... 매도 및 현물 로직 생략
)즉, 연산 로직은 하나지만 꼬리표를 기준으로 컬럼을 나누었기 때문에,
최종 결과물은 "[코인: BTCUSDT | 선물 매수량: 100 | 현물 매수량: 50]" 처럼 한 줄 안에 2개의 데이터가 분리된 상태로 깔끔하게 저장됩니다.
6. Price 집계: 무거운 Spark Join 대신 딕셔너리(Dict) 메모장 쓰기
가격(Price) 집계는 겉보기보다 까다롭습니다. 마크 가격(Mark Price), 선물 호가창(bookTicker), 현물 호가창(bookTicker) 이 3개의 서로 다른 스트림 데이터를 하나로 합쳐서 봐야 하기 때문입니다.
6-1. 무거운 Spark Join이 아니라, 단순한 Dict 메모장을 썼습니다
보통 두 스트림 데이터를 합칠 때는 스파크에 내장된 Join 기능을 떠올립니다. 하지만 스트리밍 Join은 굉장히 무겁습니다. 스파크가 "12시 01분에 들어온 마크 가격과 12시 01분에 들어온 호가를 merge해줘!"라는 명령을 수행하기 위해 양쪽 데이터를 계속 메모리에 들고 매칭을 시도하기 때문입니다.
그래서 아예 스파크 워커 내부에서 파이썬의 기본 기능인 딕셔너리를 단순한 메모장처럼 활용하는 실용적인 방법을 택했습니다.
class PriceInsight(SilverBase):
def __init__(self) -> None:
self._futures_bid: dict[str, float] = {} # 선물 매수 1호가 메모장마크 가격과 달리 호가창 데이터는 매초 수백 번씩 무섭게 들어옵니다. 이때 복잡한 연산을 하는 게 아니라, 그냥 위에서 만든 딕셔너리에 최신 호가 값을 계속 덮어씌우기만 합니다. 그리고 마크 가격 배치가 돌 때, 복잡하게 조인할 필요 없이 그저 "지금 딕셔너리에 적힌 최신 가격이 얼마야?" 하고 쓱 읽어오기만 하면 됩니다. 연산 비용이 0에 가깝게 줄어듭니다.
6-2. 호가창 히스토리를 저장하지 않은 이유? (Trade-off)
이 대목에서 이런 의문이 드실 수 있습니다. "호가창의 과거 내역을 다 저장하면 세력들의 허위 매물 벽(Spoofing) 같은 패턴도 탐지할 수 있지 않나요? 왜 가장 마지막 최신 데이터만 남기는 거죠?"
정확한 지적입니다. 하지만 여기엔 명확한 Trade-off가 존재합니다.
호가창의 모든 변동 틱을 다 저장하고 분석하려면 파이프라인의 부하가 지금의 10배 이상으로 치솟게 됩니다. 현재 Silver 레이어의 Price 테이블 목적은 세력의 호가 조작 탐지가 아니라, 현재 시점의 선물과 현물 사이의 가격 괴리율과 스프레드를 빠르게 알아내는 것입니다. 따라서 무거운 과거 내역은 과감하게 포기하고 시스템의 안정성과 속도를 취하는 전략을 선택했습니다.
7. 나머지 지표들 (OI, Liquidation, Funding 등)
OI (미결제약정): 미결제약정은 절대적인 수치보다 '직전 대비 얼마나 늘었나(변화율)'가 중요합니다. 이 역시 앞서 설명한 딕셔너리 메모장에 '이전 10초의 값'을 임시 저장해 두고, 현재 값과 비교해 증감률(%)을 계산합니다.
Liquidation(청산), Funding(펀딩비), Market Metrics(시장 요약), L/S Ratio(롱숏 비율): 이 4가지는 복잡한 변환 없이, 10초(또는 5분) 동안 카프카로 들어온 데이터를 깔끔하게 파싱하고 정리해서 ClickHouse에 저장하는 역할을 담당합니다.
즉, 7개 지표의 성격은 조금씩 다르지만, "Raw 데이터를 읽기 쉽게 변형해서 10초 단위 윈도우로 정리해 ClickHouse로 넘긴다"는 본질적인 역할은 모두 동일합니다.
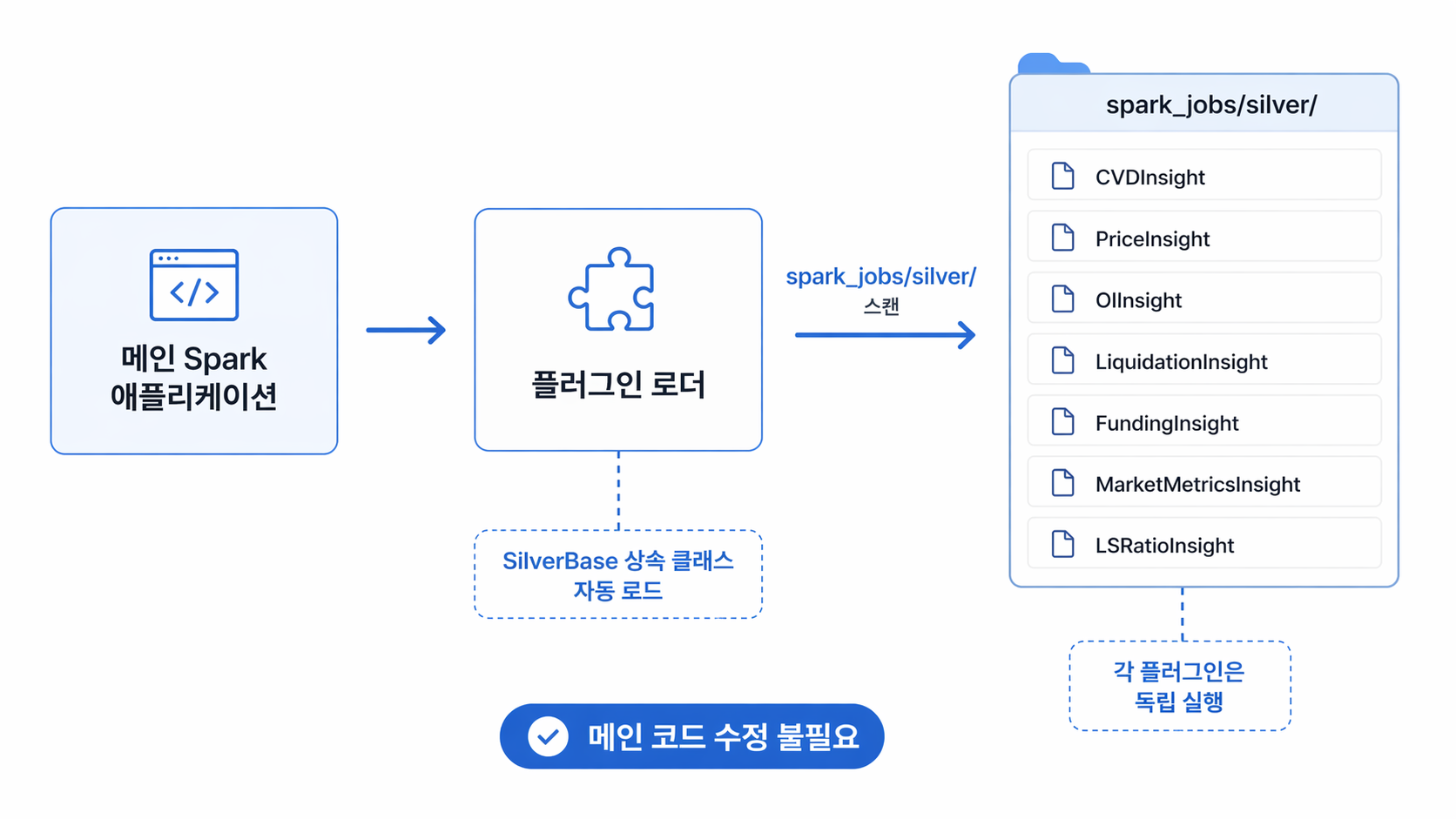
📊 다이어그램 설명
위 그림은 앞서 4장에서 설명했던 자동 탐색 플러그인(Plugin) 구조가 이 7가지 지표들을 어떻게 처리하는지 한눈에 보여줍니다.
메인 Spark 코드는 전혀 수정할 필요 없이(OCP 원칙 적용), 플러그인 로더가 spark_jobs/silver/ 폴더를 스캔하여 7개의 지표(CVD, Price, OI 등)를 각각 독립된 실행 환경에 태웁니다. 이렇게 각자의 라인을 타고 10초마다 다듬어진 데이터들이 최종적으로 ClickHouse의 7개 테이블에 쏙쏙 안착하게 되는 구조입니다.
8. ClickHouse 적재: 덮어쓰기와 실패 방어선
스파크가 10초 단위로 압축해 준 데이터를 최종적으로 ClickHouse DB에 넣습니다. 이 과정에는 두 가지 핵심 장치가 숨어 있습니다.
8-1. 실시간 수정본 데이터는 어떻게 덮어씌울까? (ReplacingMergeTree)
앞서 3번 섹션에서, 지각생 데이터가 오면 스파크가 다시 계산해서 '수정본'을 DB에 다시 쏴준다고 말씀드렸습니다. 일반적인 RDBMS(MySQL 등)라면, 기존 데이터를 찾아내어 지우고 덮어씌우는 무거운 UPDATE 연산을 해야 합니다. 트래픽이 폭주할 때 이런 짓을 하면 DB가 그대로 뻗어버립니다.
하지만 ClickHouse는 "일단 덮어쓰지 않고 무조건 맨 밑에 추가(INSERT)만 하고, 중복된 건 나중에 알아서 청소(Merge)하는"방식을 사용합니다.
스파크가 첫 결과인 "[12:00:10, BTC, 매수 100]"을 보냅니다. (DB 맨 밑에 INSERT)
5초 뒤 지각생 데이터가 반영된 "[12:00:10, BTC, 매수 150]" 수정본을 보냅니다. (기존 걸 수정하지 않고 또 DB 맨 밑에 INSERT)
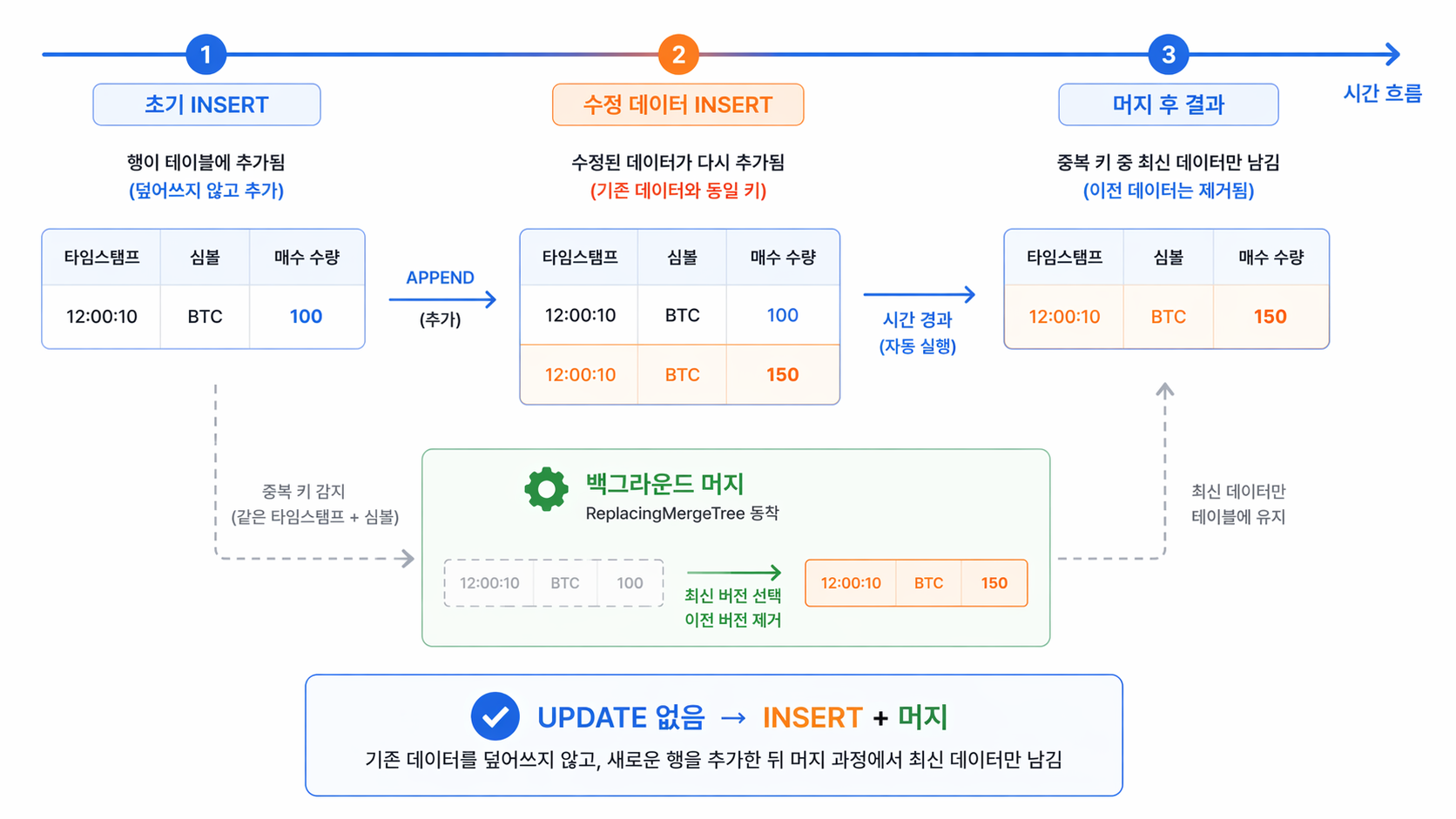
📊 다이어그램 설명
수정 데이터(150)가 오더라도 기존 데이터(100)를 UPDATE로 덮어쓰는 것이 아니라, 단순히 맨 밑에 새로운 행(Row)으로 APPEND(추가)하는 것을 볼 수 있습니다. 이후 ClickHouse의 ReplacingMergeTree 엔진이 백그라운드에서 한가할 때 스윽 돌아가며, 동일한 타임스탬프와 심볼(Key)을 가진 중복 데이터를 찾아 구버전을 지우고 가장 최신 데이터만 깔끔하게 유지(Merge)합니다.
바로 이 아키텍처 덕분에 쏟아지는 트래픽 속에서도 DB가 뻗지 않고 빛의 속도로 쓰기를 감당할 수 있습니다.
결과적으로 스파크 입장에서는 수정을 요청하지만, ClickHouse 입장에서는 오직 쓰기만 하므로 실시간 데이터가 쏟아지는 상황에서도 DB가 전혀 느려지지 않는 환상적인 아키텍처가 완성됩니다!
(자세한 내막은 4편에서 다룹니다)
8-2. 실패 방어선 (Dead Letter Queue)
DB가 잠깐 응답하지 않거나, 알 수 없는 에러로 데이터 입력(INSERT)이 실패한다면 그 10초 치 데이터는 영영 날아가 버리게 됩니다.
except Exception as e:
dlq_dir = os.getenv("DLQ_DIR", "/opt/spark/work-dir/dlq")
# 메타데이터 JSON + 실패 데이터 JSONL 형태로 로컬에 저장이를 방지하기 위해, 저장에 실패한 배치는 무조건 에러 원인과 함께 파일 형태로 DLQ(Dead Letter Queue, 실패 보관소) 폴더에 남기도록 했습니다. 운영을 해보시면 아시겠지만, 이 실패 보관소가 없으면 파이프라인은 금세 원인을 알 수 없는 '블랙박스'가 되어버립니다.
9. 실무 운영 요약과 의미
초기 운영 로그를 보면 이 구조가 어떻게 동작하는지 직관적으로 알 수 있습니다.
[CVDInsight] Batch 142 window=12:00:00..12:00:10
[CH] batch 142 -> stream.cvd: 3 rows (BTC, ETH, SOL)수많은 원본 데이터가 스파크를 거치며 정확히 10초마다 심볼당 딱 1개의 행(Row)으로 번역되어 DB에 안착합니다.
이 Silver 레이어 덕분에 뒷단의 작업은 눈부시게 쉬워졌습니다. 대시보드 서버나 퀀트 AI 모델은 복잡한 카프카 원본 데이터를 들여다볼 필요 없이, 정리된 표만 조회하면 됩니다. 그리고 우리가 궁극적으로 목표로 하는 최종 시그널인 Gold VIEW는 바로 이 ClickHouse 안에 저장된 Silver 테이블들끼리 JOIN 하여 완성하게 됩니다.
10. 다음 글 예고와 스포일러 (v2를 향하여)
이번 글에서 만든 7개 Silver 테이블은 아직 조각일 뿐입니다. 다음 편에서는 이 조각들을 ClickHouse 내부에서 엮어 최종 인사이트 뷰(gold.market_insights)로 완성하는 메달리온 아키텍처의 끝을 다룰 예정입니다.
사실 여기서 미리 밝혀둘 비하인드 스토리가 하나 있습니다.
지금까지 설명해 드린 초기 구조(v1)는 기능적으로 우리가 원하는 결과를 정확히 내주었지만, 실무 운영 관점에서는 언제 시스템이 뻗을지 모르는 시한폭탄과도 같았습니다.
원래는 이런 식으로 3개의 파티션과 스파크를 연결해 진행했지만, 변동성이 심한 장에서는 특정 코인(예: 이더리움)에 트래픽이 기형적으로 몰리면서 매번 Spark OOM(Out of Memory) 에러가 터졌습니다. 힙(Heap) 메모리가 꽉 차서 스파크가 죽으면, 자동화 도구(PM2)로 강제 재시작을 시키며 억지로 심폐소생술을 하는 식으로 버티고 있었습니다. 절대 완벽한 해결책이 아니었습니다.
그러던 중, Crypto Trading 플랫폼 Mubite의 CEO이신 Peter Andreas님께서 카프카의 '핫 파티션(Hot Partition)' 문제를 분산시키는 훌륭한 아키텍처 해결 방법을 공유해 주셨습니다. 그 조언을 바탕으로 스파크의 처리 구조와 파티션 분배 방식을 대대적으로 뜯어고친 결과, 현재는 OOM이나 강제 재시작이 거의 발생하지 않는 매우 안정적인 시스템(v2)으로 진화했습니다.
현재 이 연재 글은 파이프라인을 구축해 나가던 초창기 버전(v1)의 고민을 공유하고 있습니다. 다음 ClickHouse 편이 마무리되면, 그동안 저를 괴롭혔던 핫 파티션 문제와 스파크 병렬 처리 최적화를 어떻게 이뤄냈는지 그 치열했던 트러블슈팅의 과정(v2)도 상세히 공유해 드리겠습니다!
[다음 편] 파이프라인 4편 — ClickHouse 메달리온 아키텍처 + Gold VIEW 🔥
