[CoinWhale] 4. "DB가 뻗지 않는 실시간 뷰" - ClickHouse 메달리온 아키텍처와 Gold VIEW
암호화폐 실시간 데이터 파이프라인 & 퀀트 구축기
시리즈: 암호화폐 실시간 데이터 파이프라인 & 퀀트 자동매매 구축기
💡참고!
이 글은 ClickHouse 모델링을 처음 성립시킨 시점의 고민과 판단을 기준으로 정리하였습니다. 운영을 거치며 Gold VIEW의 조인 방식과 5초/10초 분리 전략은 더 정교해졌지만, 이번 편에서는 "왜 데이터베이스 레이어를 이런 모양으로 잡았는가"부터 "운영하면서 어떤 지점이 바뀌어야 했는가"까지를 한 흐름으로 연결해 봅니다. (※ Spark OOM, Kafka 백로그, 자동매매 재설계 등은 후속 운영 편에서 다룹니다!)
1. 들어가며: Spark 다음에는 결국 DB 모델링이 남는다
이전 3편에서는 Kafka로 쏟아지는 원시(Raw) 데이터를 Spark Structured Streaming이 10초 단위로 깔끔하게 가공해 주는(Silver) 구조를 살펴봤습니다.
문제는 그다음이었습니다.
Spark가 10초마다 지표를 만들어주긴 하는데, 그 결과를 어떤 데이터베이스 구조에 어떻게 쌓을지 정하지 않으면 서비스는 완성되지 않습니다.
당시 (2026.03) 시스템은 서로 성격이 완전히 다른 3가지 조회 패턴을 동시에 만족해야 했습니다.
- 대시보드 & API (실시간): "Spark가 10초마다 가공한 데이터를 바탕으로 시장의 의미를 뽑아내고, 실시간 매수/매도 시그널까지 즉각 화면에 띄우기!"
- 시그널 엔진 (복합 조회): "단일 지표로는 매매 판정을 내릴 수 없으니 CVD, OI, 펀딩비, 가격을 10초 단위로 한 번에 다 묶어서 확인하기"
- 백테스트 (과거 이력): "실시간에서는 사용하지 않지만, 자동매매 전략을 검증하고 설계하기 위해 과거의 정제된 데이터를 원활하게 조회할 수 있어야 해."
즉, 오래된 실시간 데이터는 서버 비용을 갉아먹지 않게 알아서 정리되어야 하고, 백테스트용 데이터는 영구 보존되어야 합니다. 이걸 전부 하나의 DB 테이블군에 밀어 넣으면 어떻게 될까요? 운영이 금방 꼬이게 됩니다.
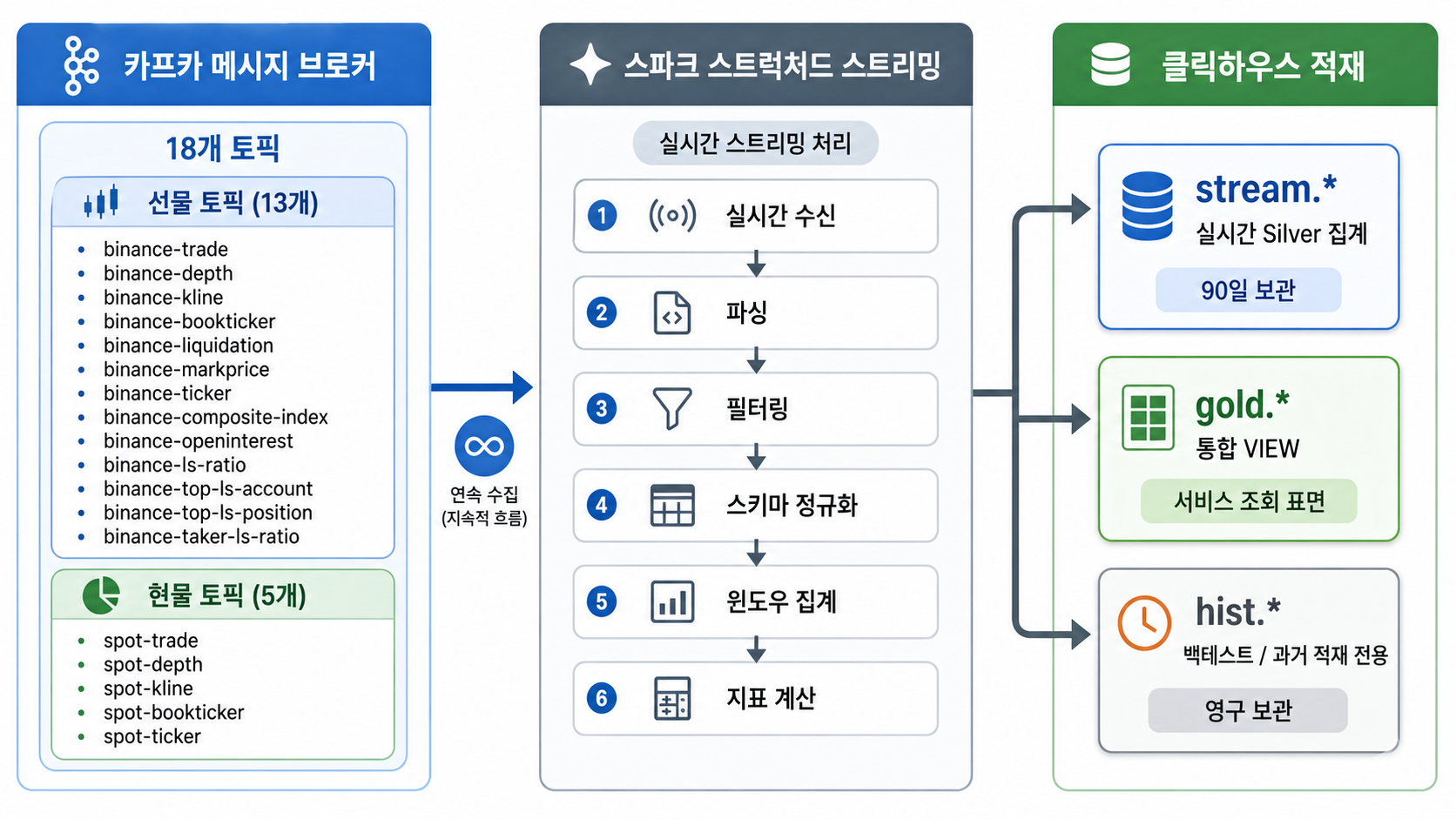
그래서 완성한 전체 아키텍처 흐름은 다음과 같습니다.
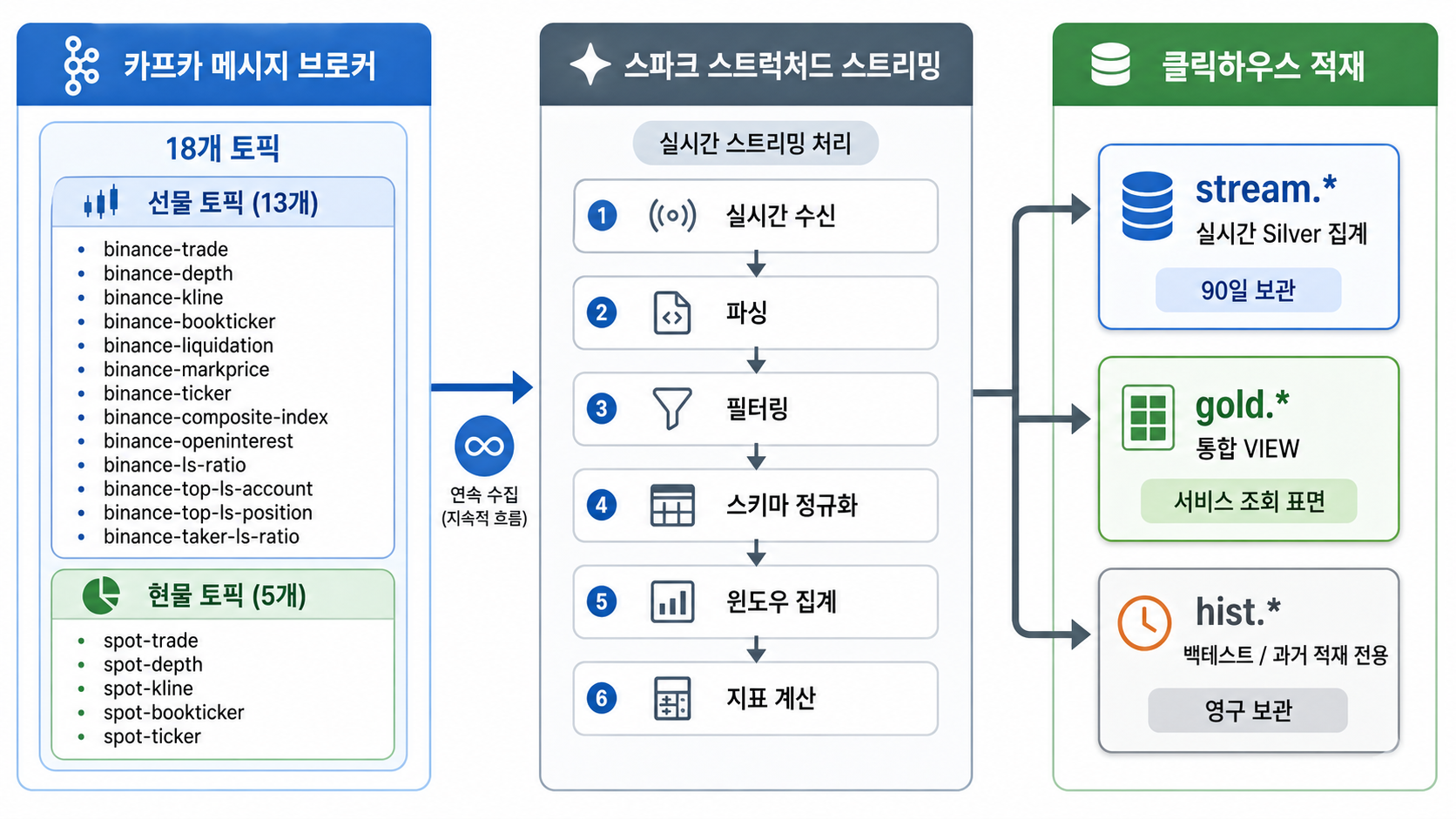
우리가 흔히 아는 메달리온 아키텍처(Bronze → Silver → Gold)에 hist.*라는 병렬 히스토리 레이어를 하나 더 추가한 형태입니다.
Spark 편이 "원시 이벤트를 어떻게 지표로 바꿨는가"에 대한 답이었다면, 이번 이야기는 "그 지표를 어떤 '표준 인터페이스'로 제공할 것인가"에 대한 소개입니다.
Spark의 고민: "이 이벤트를 어떤 윈도우와 지표로 집계할까?"
ClickHouse의 고민: "이 지표를 신뢰할 수 있게 만드려면 어떤 조회 규격(인터페이스)을 제공해야 할까?"
코드보다는 엔진, 정렬 키, TTL, VIEW 같은 선택들이 톱니바퀴처럼 어떻게 맞물려 돌아가는지를 봐야 합니다.
2. 왜 PostgreSQL이 아니라 ClickHouse였나?
⚡ ClickHouse란? 그리고 장단점
ClickHouse(클릭하우스)는 대용량 시계열/분석 쿼리에 특화된 오픈소스 컬럼형 데이터베이스(OLAP)입니다.
장점: 압도적인 INSERT 속도(초당 수백만 건 가능), 컬럼 단위 저장 및 벡터 연산으로 인한 집계(SUM, AVG 등) 속도, 뛰어난 데이터 압축률.
단점: 빈번한 UPDATE/DELETE에 매우 취약함, 완벽한 트랜잭션(ACID) 지원 부족, 일반 RDBMS 대비 무거운 JOIN 연산.
개발 초기에는 "그냥 PostgreSQL(RDBMS)를 써아햐나?"라는 고민을 가장 많이 했습니다. 하지만 당시 요구사항을 비교해 보면 ClickHouse의 압승이었습니다.
| 요구사항 | ClickHouse의 무기 | PostgreSQL의 한계 |
|---|---|---|
| 10초마다 쏟아지는 INSERT | 배치 INSERT와 Append에 특화됨 | 잦은 행(Row) 단위 쓰기 시 부하가 큼 |
| 대규모 시계열 집계 SELECT | 컬럼형 스토리지 + 벡터 연산으로 압도적 속도 | 행 단위 스캔으로 집계 쿼리 속도 저하 |
| 오래된 데이터 자동 삭제 (TTL) | 파티션 단위로 가볍게 날려버림 (Drop) | 행 단위 DELETE로 무거운 Lock 및 부하 발생 |
핵심은 최신 기술이라서가 아니라 패턴의 적합성이었습니다. CoinWhale 프로젝트의 DB는 짧은 주기 INSERT + 특정 시간 범위 대량 SELECT + 오래된 데이터 자동 정리를 동시에 감당해야 했고, 이 워크로드에서 ClickHouse가 적합했습니다.
3. 구조 해부: stream / hist / gold 세 레이어의 역할 분리
🥈 3-1. stream.*: 실시간 Silver 집계 레이어!
실시간으로 쌓이는 Silver 테이블은 stream 데이터베이스 아래에 모았습니다. (총 7개)
대표적인 DDL 스키마 패턴은 이렇습니다.
CREATE TABLE IF NOT EXISTS stream.cvd (
ts DateTime,
symbol String,
futures_taker_buy_vol Float64,
futures_cvd_delta Float64,
-- ... (생략)
) ENGINE = ReplacingMergeTree()
PARTITION BY toYYYYMM(ts)
ORDER BY (symbol, ts)
TTL ts + INTERVAL 90 DAY;표면적으로는 단순해 보이지만, 이 4줄의 설정에 실시간 운영의 핵심 원칙이 모두 담겨있습니다.
ENGINE = ReplacingMergeTree(): 지각생(Late data)이나 중복 INSERT 가능성을 전제로 한 방어적 엔진.
PARTITION BY toYYYYMM(ts): 데이터를 월(Month) 단위로 관리합니다. 실제로 서버의 로컬 저장소를 열어보면 202603..., 202604... 같은 폴더들로 데이터가 물리적으로 분리되어 저장되어 있습니다.
ORDER BY (symbol, ts): 대시보드의 대표 조회 패턴인 "특정 코인의 시간대별 조회"에 맞춘 정렬 키.
TTL ts + INTERVAL 90 DAY: 실시간 서비스에 필요 없는 90일 지난 데이터는 자동으로 소멸시킴.
(완전히 삭제하기 전 S3 같은 데이터 레이크로 백업하는 것을 권장합니다.)
💡 왜 주 단위나 일 단위 파티션을 안 썼나요?
파티션을 너무 잘게 쪼개면 ClickHouse 내부에 폴더와 파일이 기하급수적으로 늘어나 성능이 급감하는 'Too many parts' 에러가 발생합니다. 90일 보관 정책을 고려했을 때 '월 단위'가 가장 타협점이었습니다.)
여기서 중요한 점은, Silver가 단순히 "가공된 데이터"가 아니라 서비스가 바로 읽을 수 있는 최소 단위 지표 테이블이라는 것입니다.
| ClickHouse 테이블 | 주 입력 소스 | 집계 성격 | Gold 포함 방식 |
|---|---|---|---|
| stream.cvd | 선물/현물 aggTrade | 10초 합산 | Gold 뷰의 기준 시간축 |
| stream.liquidation | forceOrder (청산) | 10초 합산 | CVD와 같은 ts로 직접 조인 |
| stream.price | 선물/현물 호가, markPrice | 최신 스냅샷 | ASOF JOIN으로 최근값 보정 |
| stream.oi | OI (미결제약정) REST | 최신값 + 변화율 | ASOF JOIN으로 최근값 보정 |
| stream.market_metrics | 24h ticker | 최신 스냅샷 | ASOF JOIN으로 최근값 보정 |
| stream.funding | 펀딩비, 프리미엄 | 최신 스냅샷 | ASOF JOIN으로 최근값 보정 |
| stream.ls_ratio | 롱숏 비율 4종 REST | 5분 주기 스냅샷 | (주기가 달라 메인 Gold 뷰에선 분리) |
📚 3-2. hist.*: 실시간과 분리된 백테스트 저장소
hist.*는 정석적인 메달리온 구조에는 없지만, 실시간 운영과 충돌하지 않게 만든 장기 보관용 병렬 히스토리 레이어입니다.
과거 수년 치 데이터를 무겁게 뒤져야 하는 백테스트 쿼리가, 초당 수십 건씩 응답해야 하는 실시간 대시보드 테이블의 성능을 갉아먹지 않도록 별도의 저장소를 구축한 것입니다.
🥇 3-3. gold.*: 여러 Silver를 묶는 단 하나의 서비스 뷰(VIEW)
시그널 엔진이 매매 판정을 내릴 때마다 6~7개의 Silver 테이블을 일일이 조인해야 한다면 코드가 엉망이 될 것입니다. 그래서 gold.market_insights_10s 라는 통합 뷰(VIEW)를 만들었습니다.
stream.cvd ┐
stream.liquidation │
stream.price ├─ JOIN & 재집계 ─→ gold.market_insights_10s
stream.oi │
stream.funding ┘서비스(백엔드, 봇)는 "CVD는 합치고, 가격은 최신값을 가져온다"는 복잡한 조립 규칙을 알 필요 없이 뷰만 바라보면 됩니다.
🕵️ 3-4. Gold VIEW를 실제로 누가 읽었나?
첫 번째 소비자: 시그널 엔진
시그널 엔진은 '현재 이 순간'이 중요합니다. 방금 만들어진 최근 10초 구간의 시장 상황 스냅샷을 찍어 즉각적인 시그널을 생성합니다.
def fetch_combined_10s(client, symbol: str) -> Optional[dict]:
# 쿼리 생략: 최근 10초 윈도우 스냅샷 단일 쿼리엔진은 이 데이터를 통해 "고래 매수세가 들어왔는데 레버리지(OI)까지 터졌다 -> 롱(Long) 시그널 발동!" 같은 로직을 수행합니다.
두 번째 소비자: 자동매매 (Paper Trading) 계층
Quant 봇: PAPER_MARKET_VIEW=gold.market_insights_5s (초단타, 5초 루프)
Hybrid 봇: PAPER_MARKET_VIEW=gold.market_insights_10s (10초 루프 + LLM 승인)
4. 설계의 이유: 엔진, 파티션, 뷰는 한 세트다
🔄 4-1. ReplacingMergeTree: 스트리밍의 중복을 DB에서 흡수한다
스트리밍 환경에서는 파이프라인 재시작이나 네트워크 지연으로 인해 동일한 데이터가 두 번 이상 들어오는 중복 적재가 필연적으로 발생합니다.
일반적인 DB라면 UNIQUE KEY를 걸고 중복 시 에러를 내거나, UPSERT 연산으로 기존 데이터를 무겁게 찾아 덮어써야 합니다. 하지만 트래픽이 초당 수천 건씩 쏟아지는 상황에서 이런 방식은 DB에 엄청난 부하를 줍니다.
여기서 ReplacingMergeTree 엔진이 빛을 발합니다.
이 엔진은 데이터가 들어올 때 중복 검사를 하느라 시간을 끌지 않고, 일단 맨 밑에 빠르게 추가(Append)만 합니다. 그리고 백그라운드에서 DB가 한가할 때(Merge 시점), ORDER BY (symbol, ts) 키를 기준으로 중복된 구버전 데이터를 조용히 지우고 가장 최신의 데이터만 남겨줍니다.
즉, ReplacingMergeTree는 "스트리밍에서는 중복이 생길 수밖에 없으니 일단 다 받아주고, 정리는 내가 나중에 알아서 할게"라는 현실을 인정한 아주 똑똑하고 방어적인 선택입니다.
🤔 4-2. 왜 Materialized View가 아니라 일반 VIEW였나?
"미리 계산해 두는 Materialized View(MV)가 더 빠르지 않나요?" 맞습니다. 하지만 초기 파이프라인에서는 조인 규칙이 쉴 새 없이 변했습니다. MV로 결과를 물리적으로 굳혀버리면 과거 데이터를 모두 재생성해야 했기에, 유연하게 조회 규격을 고칠 수 있는 일반 VIEW가 훨씬 안전한 선택이었습니다.
5. 운영의 쓴맛: 이론은 완벽했으나, 현실은 달랐다
🛠️ 트러블슈팅 1: 중복이 바로 안 지워진다? (FINAL)
ReplacingMergeTree는 백그라운드에서 한가할 때 중복을 지웁니다. 방금 들어온 데이터를 조회하면 중복 데이터가 두세 줄 보일 수 있습니다.
👉 해결책 (FINAL):
조회 쿼리에 FINAL을 붙였습니다. FINAL을 붙이면 쿼리를 실행하는 바로 그 시점(On-the-fly)에 DB 엔진이 메모리상에서 강제로 병합 및 중복을 제거하여 완벽하게 1건으로 정리된 결과를 반환합니다.
🛠️ 트러블슈팅 2: 정확히 일치하는 시간 조인의 환상 (ASOF JOIN)
10초에 거래량이 터졌는데, OI 데이터는 폴링이라 9초에 머물러 있을 수 있습니다. 시간이 안 맞아서 값이 NULL로 비는 구간이 속출했습니다.
👉 해결책 (LEFT ASOF JOIN + 보정 가드):
일반 JOIN이 정확히 일치하는 시간을 찾는다면, ASOF JOIN은 시계열에 특화되어 "정확히 일치하는 시간이 없으면, 기준 시점보다 과거에 있었던 가장 가까운 최신 값(As Of)을 자동으로 찾아서 매핑"해 줍니다. 단, 수집기가 죽었을 때 아주 오래된 과거 값을 가져오는 것을 막기 위해 dateDiff로 유효기간(임계값)을 걸었습니다.
🛠️ 트러블슈팅 3: 10초 뷰 하나로는 모두를 만족시킬 수 없다
결국 가장 민첩한 5초 뷰를 베이스로 두고, 이를 다시 10초 단위로 묶어서 서빙하는 2단계 구조로 진화했습니다.
✅ 5-1. 데이터 규모와 Airflow: 검증 기준이 있어야 VIEW를 믿을 수 있다
현재 파이프라인에서 수집 및 가공되고 있는 데이터의 규모는 다음과 같습니다. (2026.03 ~ 04월 말)
전체 데이터 (주요 DB 합산): 7,351,287건
핵심 스트림 7개 테이블 합: 6,155,839건
(cvd: 1.2M, price: 1.2M, market_metrics: 1.2M, funding: 1.18M, oi: 1.1M, ls_ratio: 120K, liquidation: 61K)이처럼 방대한 데이터 속에서
"중복 데이터가 없는가?",
"시간 정렬(5초 단위)이 어긋나지 않았는가?",
"가격이나 OI가 비어있는 빈 구간(Gap)은 없는가?"
를 사람이 일일이 감시하는 것은 불가능합니다.
시그널 엔진이 이 뷰를 믿고 실제 매매 주문을 던지기 위해서는 견고한 데이터 품질 점검과 운영 자동화가 필수적이었습니다. 이를 위해 Apache Airflow를 오케스트레이터로 도입했습니다.
Airflow의 주요 역할 (배치 및 운영 자동화)
이 프로젝트에서 Airflow는 실시간 스트리밍(1초 단위) 처리가 아닌, 다음 세 가지 후속 운영을 책임집니다.
- 데이터 품질 점검 (data_quality_audit):
stream. 최신 시점 검사, null 비율, 10분 내 데이터 급감 탐지. (문제가 감지되면 알림 및 조치)
- 자동 백필 (stream_gap_scan):
운영 중 5분마다 빈 구간(Gap)을 탐지하여 자동으로 복구
- LLM 일일 리포트 (daily_report_v2):
24시간마다 누적된 Gold VIEW 데이터를 기반으로 LLM이 시장 분석 리포트를 정기적으로 생성.
Airflow가 배치성 품질 점검과 백필을 든든하게 받쳐주었기 때문에, 실시간으로 돌아가는 Gold VIEW를 비로소 "신뢰할 수 있는 인터페이스"로 사용할 수 있었습니다.
6. 마치며: ClickHouse는 저장소가 아니라 '통합 조회 창구'였다
이번 글에서 핵심은 단순히 "ClickHouse라는 DB를 도입했다"가 아닌 stream(실시간 운영), hist(백테스팅), gold(서비스 조회)로 역할을 명확히 쪼개둔 덕분에,
Spark는 지표를 계산하는 역할에만 집중하고,
ClickHouse는 시간축 보관 정책(TTL/파티션)을 맡고,
FastAPI와 시그널 엔진은 Gold VIEW라는 공통 표면만 편하게 읽을 수 있었습니다.
현재 운영 중인 시스템에서 gold.* 레이어는 단순한 뷰를 넘어, 시그널 로직 결과값, AI 리포트(daily_reports), 자동매매 가상 포지션 기록까지 품어내는 든든한 서비스 통합 데이터 허브로 확장되었습니다.
결국 이 파이프라인에서 ClickHouse는 데이터를 막 저장하는 창고가 아니라, 파이프라인과 서비스 사이의 튼튼한 표준 인터페이스(Interface Layer)였습니다.
하지만, 진정한 시련은 이제부터 시작이었습니다...
파이프라인 설계는 완벽해 보였지만, 이렇게 공들여 만든 데이터를 바탕으로 야심 차게 시작한 자동매매는 뼈아픈 실패를 맞이하게 됩니다.🥲
다음 편에서는 이 데이터를 활용해 진행해 본 '간단한 퀀트 투자 실패기'를 다루어 보겠습니다! 🔥
[다음 편] 퀀트 1편 — 완벽한 데이터, 그러나 처참했던 퀀트 실패 기록
