You Only Look Once: Unified, Real-Time Object Detection
- 2 Stage Object Detection : 위치 → 분류
- 1 Stage Object Detection : 위치 + 분류 → Confidence = acc. + IoU ⇒ confidence 50% 이상인 경우에만 물체가 있을 확률이 높다고 판단, 50% 이하의 경우 무시
Abstract
- 속도가 매우 빠름, 45 frame/second (cf. Faster-RCNN 0.5 sec/frame)
- YOLO가 당시 SOTA detection model에 비하여 localization error가 더 있지만 background에 대한 false-positive가 더 적음 : 있는데 없다고 하는 경우는 더 적음
Introduction

- 기존 DPM(Deformable parts models)는 이미지 전체를 sliding window 방식
- 제안된 bounding box에 classifier를 적용하여 분류(classification) → 후처리 (bounding box를 조정, 중복 제고, box 재산정) ⇒ 느리고 최적화가 어려움
- YOLO : box cordinate와 class probailitie를 하나의 회귀 문제로 규정을 함
- 하나의 convolutional network가 여러 bbox와 그 bbox의 클래스 확률을 동시에 계산
- 이미지 전체를 확습해서 곧바로 검출 성능 최적화
- 장점
- 빠름
- background error에 강함 : Fast R-CNN은 배경의 노이즈나 반점이 있으면 객체로 인식함(Sliding window나 Region proposal 방식 사용)
- 검출 정화도가 높음
- 단점
- 정확도가 떨어짐 : 속도와 정확도는 trade-off 관계
Unified Detection

- 입력 이미지(input images)를 S x S grid로 나눔
- 각각의 grid cell은 B개의 bounding box와 그 bounding box에 대한 confidence score를 예측
Network Design
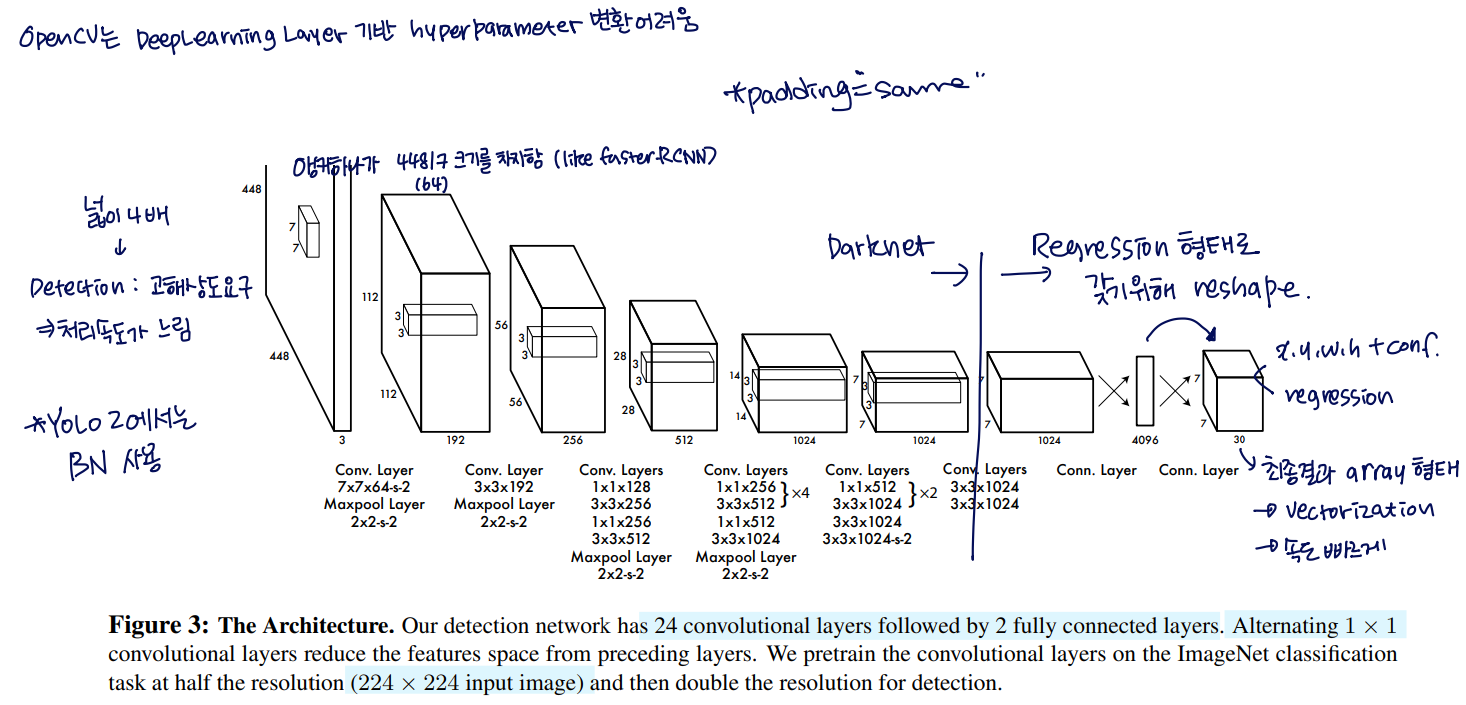
- Object Detection을 위해서 이미지 정보의 해상도가 높아야 하기 때문에 224x224를 448x448로 증가시킴
- 최종 예측값 : class probabilities와 bbox 위치정보
- bbox 위치 정보에는 bbox의 중심좌표(x, y)를 하고 너비와 높이를 상대 좌표로 변환 → 정규화 ⇒ 처리 속도를 빠르게 함
- Leaky ReLU를 사용
- ReLU가 복잡해지면 Dying ReLU 현상이 발생 → 0이 안 되게 0.01x로 대칭시킨 것이 Leaky ReLU
- 이 논문에서는 0.1x로 변경시킴
- 문제점
- loss를 SSE(sum-squared error) 기반으로 함 : 최적이 편하기 때문에
- SSE는 localization loss와 classification loss의 가중치를 동일하게 두고 학습을 시키는데, 이는 좋은 방법이 아님
- 작은 bbox가 큰 bbox 보다 위치 변화에 더 민감
- 해결책
- localization loss와 classification loss 중 localization loss의 가중치를 증가
- bounding box의 너비(widht)와 높이(hegith)에 square root를 취해준 값을 loss function으로 사용
- 이미지 내 대부분의 grid cell에는 객체가 없음 (배경 영역이 obect 영역보다 더 큼) → confidence score=0 이 되버림 → 모델의 불균형 초래
- 해결책
- 객체가 없는 그리드 셀의 confidence loss보다 객체가 존재하는 그리드 셀의 confidence loss의 가중치를 증가
- 해결책
- loss를 SSE(sum-squared error) 기반으로 함 : 최적이 편하기 때문에
- 과적합(overfitting)을 막기 위해 드롭아웃(dropout)과 data augmentation을 적용
- YOLO v2에서는 BN 사용

매일 성장하고 있습니다