Blind Face Restoration via Deep Multi-scale Component Dictionaries 논문으로 얼굴 사진의 해상도를 높이는 Super Resolution 기술 중에서 Reference FSR 방식을 가지고 있는 DFDNet을 소개한 논문입니다.
원문 깃허브
감사하게도 깃허브에 코드까지 공유가 되어있습니다.
3줄 요약
- 복원하려는 사진과 같은 사람의 고화질 이미지를 찾기 힘든 경우 실제 활용 사례에서 많기 때문에, 이를 해결하기 위해 다른 사람의 고화질 얼굴 이미지를 눈, 코, 입 등으로 나누어 저장한 사전(dictionary)을 K-means로 만들었다.
- 그 후 저화질 사진과 가장 비슷한 눈, 코, 입 등을 선택하고 AdaIN 레이어로 밝기 등을 제거하여 합쳐서 복원에 성공하였다.
- 실험을 해보니 다른 모델들에 비하여 높은 성능을 보여주며, 저화질 사진의 사람과 같은 사람의 고화질 이미지가 있어도 높은 정확도로 복원할 수 있었다.
Introduction
본래 슈퍼 레졸루션의 문제 중 하나는, 저화질의 사진에는 많은 정보들을 잃어버리는 문제이다. 특히 어떤 방식으로 저화질이 되었는지 모르는 blind restoration 상황에서는 잃어버린 정보가 무엇인지 저화질 사진만 가지고는 전혀 모른다. 이런 문제를 해결하기 위하여, 저화질의 사람과 똑같은 사람의 다른 고화질의 사진을 Reference 이미지로 활용하여 성능을 크게 향상시키는 Reference FSR 방식이 등장했다.
하지만, 이 방법에도 두 가지 제약이 있다. 첫째로, 고화질의 이미지가 저화질 이미지인 사람과 반드시 같아야 한다는 것이다. 둘째로, reference 이미지와 저화질의 이미지의 포즈와 표정 등이 다를 수 있다. 이러한 제약을 모두 만족하는 상황은 실제로 이루어지기 매우 어렵다.
이를 해결하기 위해서 DFDNet에서는 얼굴의 네 부분(왼쪽/오른쪽 눈, 코, 입)을 담은 사전(Dictionary)를 만든다. 사람의 얼굴 각각의 부분은 닮은 경우가 많기 때문에, 저화질 이미지의 눈, 코, 입과 닮은 부분을 사전에서 꺼내서 사용한다. 이 과정을 통해서 동일한 사람의 고화질 이미지 없이도 높은 성능을 달성할 수 있다.
DFDNet은 다음과 같은 과정을 거친다.
1. 다량의 고화질 얼굴 이미지 데이터셋에서 pre-trained된 VggFace로 얼굴의 특성을 여러 크기로 뽑는다.
2. RoIAlign으로 facial landmark를 이용해 각 얼굴 부분을 자른다.
3. K-means를 적용해 클러스터링을 수행하여 비슷한 얼굴 부분끼리 묶는다. 4. CAdaIN(component adaptive instance normalization)으로 얼굴 스타일에 따른 영향을 삭제한다. (피부색이나 조명 등)
5. 저화질 사진에 가장 비슷한 부분들을 찾아서 슈퍼레졸루션을 진행한다.
Proposed Methods
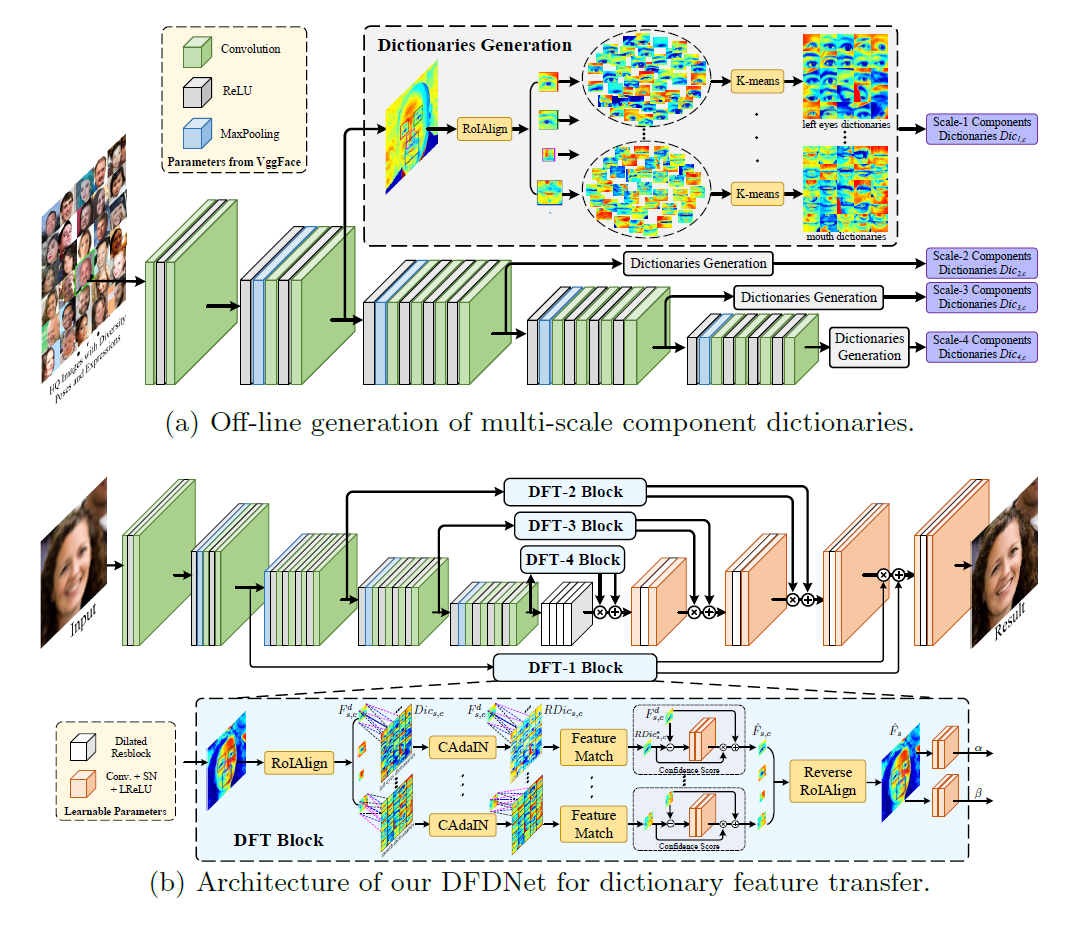
1. Component 사전 제작
높은 품질의 사전을 제작하기 위하여 FFHQ 데이터셋을 사용했다. DeepPose와 Face++를 활용하여 각 사진의 나이, 인종, 포즈, 표정 등을 파악했다. 이렇게 파악한 특성을 활용해, 7만장의 FFHQ중 밸런스있는 특성으로 1만장을 선별하여 사전을 만드는 데 사용했다.
이 사진들을 pre-trained 된 VggFace에 넣어 여러 크기에서 feature를 도출했다. 그 후, 이 feature에서 dlib으로 facial landmark를 찾고, RoIAlign으로 정해진 크기로 왼쪽/오른쪽 눈, 코, 입을 잘랐다. 그 후 K-means를 적용하여 개로 클러스터링하여 Component 사전을 제작했다.
사진은 1배, 2배, 3배, 4배로 작아지며 feataure를 뽑아냈다. 또, 눈, 코, 입의 크기는 256x256 이미지의 경우 40, 25, 55이다.
2. DFDNet
제안된 DFDNet의 구조를 공식화하면 다음과 같다.
와 는 (인풋 이미지)의 facial landmark와 component dictionray를 가르킨다. 또, 는 DFDNet의 학습시킬 수 있는 파라미터이다.
와 의 크기를 똑같이 하기 위해서, DFDNet의 인코더로는 pre-trained VggFace를 사용하며, 이것은 Dictionary 제작에 사용한 것과 동일하다. 그냥 단순히 이 VggFace를 사용하면 Dictionary와는 다른 값들을 DFDNet에 넣게 될 것이다. 이를 막기 위해서 DFT block을 이용한다. DFT block은 RoIAlign, CAdaIN, Feature Match, Confidence Score, Reverse RoIAlign; 이렇게 5 단계로 이루어져 있다.
인풋 이미지 에서 왼쪽/오른쪽 눈, 코, 입을 RoIAlign을 이용해 때어낸다. 그 후, CAdaIN을 통해 dictionary의 각 클러스터를 인풋 이미지의 스타일에 맞게 조정한다. 그리고 Feature Match로 비슷한 클러스터를 찾아낸다. 여기서 실제로 비슷한지 알아내기 위하여 confidence score를 사용한다. 마지막으로 reverse RoIAlign을 적용하여 각 위치에 복원된 부위들을 붙여넣는다. decoder에서의 더 좋은 성능을 내기 위해서 UNet을 변형해 사용했으며 SFT를 제안한다. 아래는 각 과정에 대한 더 자세한 설명이다.
CAdaIN
피부 색깔이나 다른 조명 상황 등의 차이점을 제거하기 위하여 CAdaIN을 이용한다. 이를 통하여 각 사진 마다의 차이점을 제거하여 더 비슷한 부위를 Dictionary에서 찾아낼 수 있도록 한다.
AdaIN을 이용하면 구조적인 생김새는 그대로 유지하면서 피부 색깔 등의 스타일은 바꿀 수 있다. CAdaIN은 다음과 같다.
위에서 와 는 크기에서 인풋 이미지 와 component dictionary의 번째 클러스터의 번째 부분을 의미한다. 또한, 는 평균이며 는 표준 편차이다. 위와 같은 수식을 통하여 입력되는 부분인 는 와 유사한 분포를 가지게 되어 스타일이 똑같아지며, feature match를 더 정확하게 할 수 있다.
Feature Match
입력된 이미지의 각 부분 feature인 와 CAdaIN을 이용해 재조정한 Dictionary 의 모든 클러스터간의 유사도를 측정하기 위하여 내적을 수행한다. 사전의 번째 클러스터에서 유사성은 다음과 같이 정의할 수 있다.
이러한 내적 연산을 모든 클러스터와 실행하여 유사도를 비교하여야 하는데, 이는 0의 가중치와 bias를 가진 convolutional 레이어 연산으로 수행할 수 있다. 이를 통해 빠르게 얼마나 유사한지 측정하고 사전에서 가장 유사한 클러스터를 찾아낸다. 이를 라 하겠다. 이제 이 부분을 이용하여 사진을 복원할 수 있다.
Confidence Score
DFDNet의 인풋은 크기가 계속 달라지며, 그것에 상응하는 사전의 크기도 마찬가지이다. 다른 크기에서 DFDNet을 평준화하기 위해서 와 를 직접 비교하여 confidence score를 구한다. 그 score는 빠졌던 고퀄리티의 디테일을 에서 가져오도록 한다. 수식은 다음과 같다.
는 Confidence Score 수식 의 학습 가능한 파라미터이다.
다시 말해, 원본의 이미지와 Dictionary에서 가장 유사하다고 분류된 각 부분의 사진을 결합하여 각 부분의 SR 이미지를 생성해 낼 수 있다.
Reverse RoIAlign
confidence score를 통해서 SR을 진행한 각 부분의 이미지 를 Reverse RoIAlign을 통해서 역으로 원본 사진에 붙여 넣는다. 이 과정은 SFT를 활용하여 이루어진다.
3. 모델 loss
Reconstruction Loss
원본 사진 와 SR 결과인 의 차이를 측정하는 loss이다. 이를 위해 MSE를 적용했다. 수식은 다음과 같다.
첫 항의 수식만을 이용하면 (단순히 원본과 SR 결과만을 비교한 경우) blurry한 결과를 생성한다. 그렇기에 두번째 항을 이용한다. 두번째 항은 perceptual loss로써, 는 VggFace 모델의 번째 컨볼루션 레이어를 가리킨다. 이 loss를 통해서 SR 결과의 퀄리티를 향상시킬 수 있으며, 이는 Computer Vision 분야에서 흔히 사용하는 방법이다.
Adversarial Loss
이 loss는 이미지를 진짜처럼 복원하기 위해서 사용된다. 여러 크기에 대해서 적용할 수 있는 형태로 설계되었다. 특히, 실제 고화질 원본 사진과 SR 사진을 더 잘 구별하는 Discriminator를 안정적으로 훈련하기 위하여 각 컨볼루션 레이어에 SNGAN을 적용하였다. Discriminator의 목적 함수 수식은 다음과 같다.
은 이미지의 크기를 줄이는 다운샘플링을 의미하며, 은 몇 배 크기를 조정하는지이다. 비슷하게, generator 는 다음과 같다.
은 각 크기에 따라서 바뀌는 trade-off 파라미터이다.
최종적으로, DFDNet을 훈련시키는 데에 사용하는 최종적인 목적 함수는 다음과 같이 reconstruction loss와 adversarial loss의 합으로 이루어진다.
p.s.
이 부분이 갑자기 수식 폭탄이라 이해하기 어려울 수 있는데, 모두 GAN loss에 기초한 내용이라 논문에는 많은 부분이 생략되어 있다. 이 논문을 참고하면 좋을 것 같다.
실험
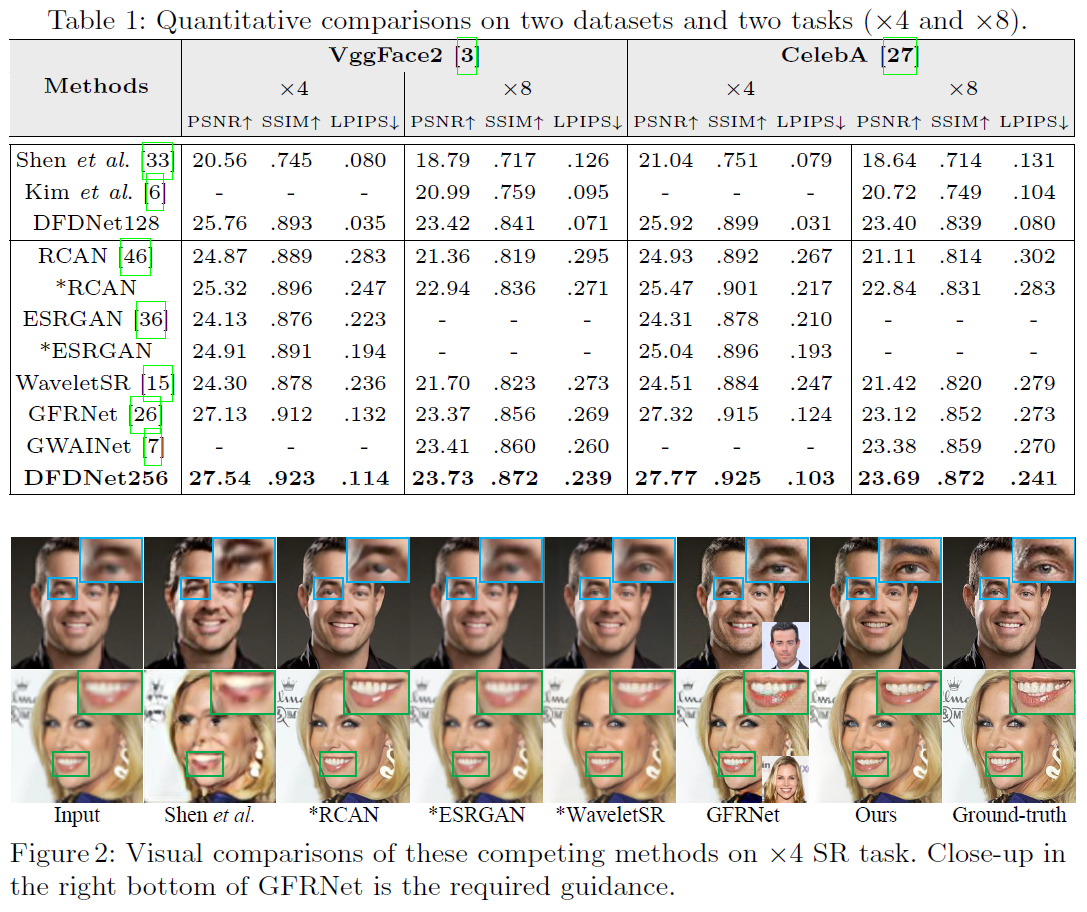
먼저 Dictionary는 FFHQ 데이터셋의 10000장을 활용해 훈련했다. 또한, 테스트 데이터셋으로는 VggFace2의 2000장과 CelebA 데이터셋의 2천장을 활용했다. 저화질로 낮추는 방법은 GFRNet에서 제안한 방법을 사용하였다.
결과
질적 평가
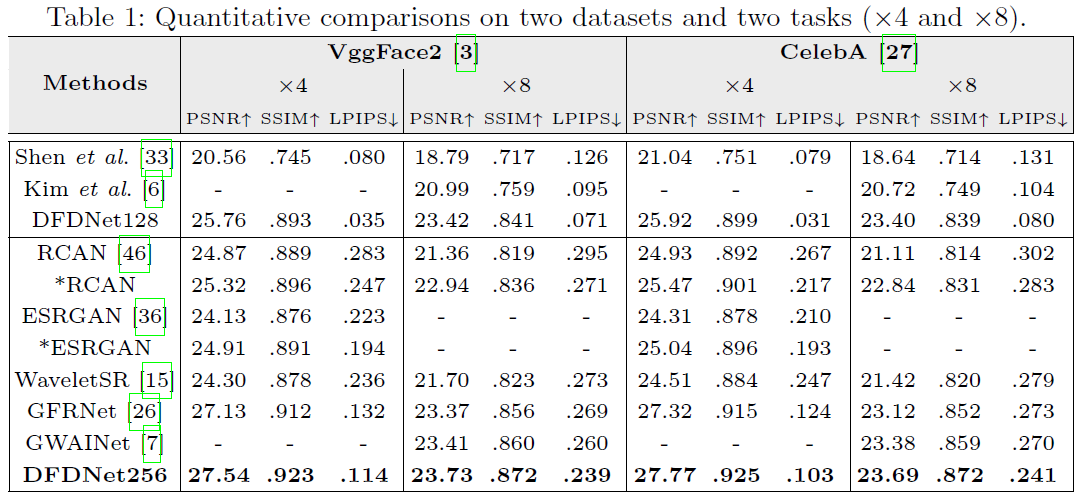
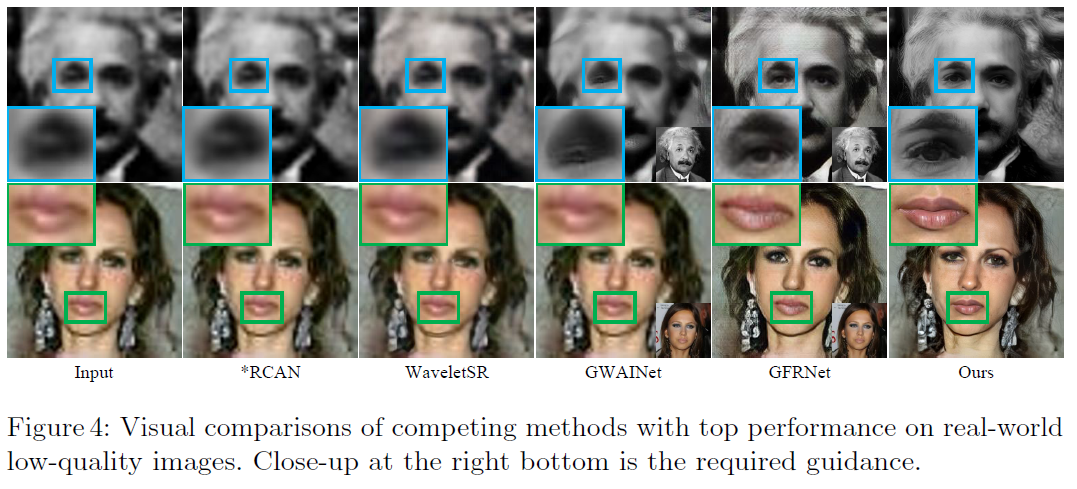
사진 비교


확대한 각 부위를 보면 알 수 있듯이, DFDNet은 기존의 고화질 눈,코,입을 활용하기 때문에 눈, 코, 입의 재현이 매우 정확하고 디테일하다는 것을 알 수 있다.
실제 사진 복원 예시