글머리
Super Resolution은 저화질의 사진을 고화질의 사진으로 화질을 향상시키는 기술이다. 이러한 Super Resolution의 여러 분야 중에서, 한 종류에 특화되어있는 domain-specific한 분야들이 있는데 그 중 가장 활발하게 연구되고 있는 Face Super Resolution (이하 FSR)에 대해 살펴보고자 한다.
원본 논문은 이곳에서 바로 볼 수 있다.
Background
문제 정의
FSR은 기존 SR(Super Resolution)의 문제 정의와 크게 다를 바 없다. 결국 LR (Low Resolution, 저화질) 이미지를 HR (High Resolution, 고화질)로 바꾸는 것이다.
이 과정에서 원래 HR 이미지를 LR로 바꾸는 과정이 필요하다. 그러한 LR 과정은 blurring kernel을 추가하거나, downsample하는 과정이나 random한 노이즈를 추가하는 거으로 달성할 수 있다.
그렇게 HR을 강제로 LR 이미지로 변환한 후, LR 이미지를 SR 모델을 통해 다시 HR로 변환하여 원래 HR 이미지와 비교하는 방식으로 SR 모델을 평가하고 훈련할 수 있다. 그러면 어떻게 평가할 수 있을까?
평가 지표
1. PSNR (Peak Signal-to-Noise Ratio)
단순하게 SR과 원본 HR 이미지의 픽셀이 얼마나 다른가를 픽셀 by 픽셀로 계산하는 방법이다. 각각의 픽셀마다 각 채널의 값의 오차를 계산하여 전체 MSE 값을 계산하는 것이 핵심이다. 계산한 값은 다음과 같은 수식으로 PSNR로 변환된다.
여기서 M은 픽셀 하나가 가질 수 있는 가장 큰 값이다. (8-bit 이미지라면 255)
오차의 역수를 나타내기 때문에 PSNR이 클수록 더 정확한 SR 이미지라는 뜻이다.
2. SSIM (Structural Similarity Index)
이미지의 밝기, 대조, structure 차이를 모두 곱한 값이다. 이 값 하나로는 각 이미지들을 공평하게 비교할 수 없기 때문에, 각 사진을 여러개의 window로 잘라 SSIM을 계산하고 합산하는 MS-SSIM을 주로 사용한다. 두 이미지가 비슷할수록 SSIM은 높다.
3. NIQE (Natural Image Quality Evaluator)
원본 HR 이미지 없이도 SR 이미지를 평가할 수 있는 평가 지표이다. multivariate 가우시안 모델을 사용한다고 하며, 값이 작을수록 복원이 잘 된 이미지라는 뜻이다.
이 외에도 FID, LPIPS 등이 있다.
Loss Function
1. Pixel-wise Loss
PSNR 계산에 사용한 MSE (L2 loss) 혹은 MAE (L1 loss)를 의미한다. 이 loss를 사용하면 항상 PSNR이 향상하는 방향으로 훈련되지만 과하게 smooth해지고 디테일이 떨어진다는 단점이 있다.
2. SSIM Loss
은 SSIM 결과를 뜻한다. 즉, 평가 지표로 쓰이는 SSIM을 위와 같이 변형한 결과가 loss로 쓰인다.
3. Perceptual Loss
위의 두 개의 loss에 비하여 실제 사람이 지각하는 품질을 향상시키기 위하여 등장한 loss로, 훈련하는 모델 안의 각 feature간 거리를 계산하는 방식으로 구한다. 이 loss를 사용하면 Pixel-wise Loss를 사용한 모델보다 PSNR은 안 좋지만 실제 보여지는 품질은 더 높다.
이 외에 GAN 모델에서 사용하는 Adversarial Loss, cycle GAN 모델에서 사용하는 Cycle Consistency Loss 등이 있다.
얼굴 이미지의 특징
FSR은 domain-specific한 이미지이기 때문에, 얼굴의 특징을 모델에 반영할 수 있다. 그렇기에 얼굴의 특징을 알고 활용할 수 있는 것은 FSR에 중요한 측면 중 하나이다.
1. Prior Information
Facial Landmark, heatmap, parsing map 등이 있다. 사람들의 얼굴 표정에서 각 지점을 landmark나 기타 각각의 방법으로 표시하는 것이다.

2. 특성 정보
성별, 머리 색, 안경 유무와 같은 얼굴의 특성을 뽑는 것이다. FSR에서는 SR 과정에서 LR의 특성과 다른 경우가 생길 수 있는데, LR에서 이러한 특성 정보를 뽑아 제공해주면 그러한 경우를 방지할 수 있다.
예를 들어, LR에서 안경을 쓰고 있던 이미지가 SR 모델을 돌렸더니 안경이 사라졌다면, 안경이 있다는 특성 정보를 모델에 알려줘서 SR을 더 정확하게 복원할 수 있다.
3. 개인 식별 정보
이 사람이 이 사람이 맞는지 식별할 수 있는 정보이다. 쉽게 얼굴 인식 잠금 해제를 생각하면 된다. 알다시피 사람의 얼굴은 모두 unique하기 때문에, SR 이미지와 LR 이미지가 다른 사람으로 인식되면 안된다.
4. FSR을 위한 데이터셋
가장 중요한 특징은 얼굴 데이터셋이어야 한다는 것과, HR 이미지를 반드시 특정 방식으로 LR로 바꾸어서 사용해야 한다는 것이다. 본 논문에서 소개하는 데이터셋에는 CACD200, VGGFace2, UMDFaces, CASIA-WebFace 등이 있다.
FSR 종류
General한 FSR 종류
1. 기초적인 CNN 기반 방법
최초의 General SR 논문을 (원문,리뷰) 시작으로 등장한 방법이다. 이 전통적인 방법은 FSR에서도 활발하게 연구되었으며 그 종류를 크게 세 가지로 나눌 수 있는데, 다음과 같다.
1-1. Global Methods
얼굴 이미지 전체를 사용하여 전체를 복원시키는 방법이다. 얼굴 이미지만의 특성을 크게 사용하지 않고 마치 General 이미지마냥 사용하는 방법이다. 그렇기에 General SR 방법과 CNN의 발전에 따라 성장해 왔으며 현재는 CNN의 기조와 비슷하게 attention 기반의 모델도 제안되고 있다.
이러한 SR 기법을 이용한 결과물은 상대적으로 smooth한 SR 결과물을 제공하며 높은 수준의 디테일까지는 구현할 수 없다. 이러한 문제점을 해결하고자 WaSRNet와 같은 연구에서 wavelet coefficient를 사용하여 디테일을 개선하고 지나치게 smooth한 결과물을 피하도록 했다.
1-2. Local Methods
Global Methods에서 얼굴의 디테일한 부분을 해결하기 위하여 얼굴의 각 부분을 다르게 복원하는 방식이다. SRDSI 연구에서는 전형적인 얼굴 모양과 구체적인 얼굴 모양을 PCA를 이용하여 한 사진에서 나누어서 각각 VDSR (매우 깊은 CNN)을 이용해 구체적인 모양과 전반적인 모양을 SR 하는 데에 성공했다. 또한, 얼굴의 각 부분을 나누어서 각기 SR 한 후 붙이는 방법들이 제안되었다.
1-3. Mixed Methods
위의 Global과 Local Methods들을 합쳐서 사용하는 방법이다. 이 방법으로 두 방법의 장점을 모두 잡으려는 연구들이다. 순차적으로 각 방법을 사용하는 global-local network 방법이나, 동시에 두 성질을 모두 잡는 DPDFN과 같은 연구가 진행되었다.
2. GAN 기반 방법
GAN을 이용한 방법으로, smooth한 결과를 내놓은 CNN 기반 방법과는 다르게 더 디테일한 모습을 보여주는 이미지를 생성할 수 있다. 최근에는 이미 pretrained 되어있는 GAN 모델을 FSR에 맞게 변형하는 방식이 주목을 받고 있다.
2-1. 일반적인 GAN 기반 방법
최초로 FSR에 GAN을 제안한 논문은 URDGN으로써 SR 이미지를 생성하는 generator와 진짜 HR 이미지와 생성된 SR 이미지를 구별하는 discriminator로 이루어져 있다. 이 URDGN을 기반으로 성능을 향상시킨 여러 연구가 진행되었으며, PCA를 이용해 discriminator가 더 잘 학습하도록 하는 연구(PCA-SRGAN)나 pixel-wise adversarial loss를 사용해 discriminator의 성능을 향상시킨 연구(SPGAN) 등이 있다.
위의 연구들은 임의로 생성한 LR 이미지를 사용하는 한계가 있었으며, 이를 해결하기 위하여 RWSR과 같은 연구에서 blur, 노이즈, 압축과 같은 실제 LR 이미지의 특성에 관해 연구하였다. 이러한 맥락으로 LRGAN은 SR 전 LR로의 degradation을 먼저 학습하는 방법을 사용했다. HR에서 LR로 가는 GAN을 학습하고 LR에서 HR로 가는 pair GAN 모델을 학습하는 방식을 이용한 것이다.
이러한 방식은 CycleGAN을 사용하며 더욱 발전되었다.
2-2. Generative prior-based methods
StyleGAN이나 ProGAN, StarGAN 등 많은 얼굴 합성 GAN 모델들이 등장하면서, FSR에 이러한 pre-trained 모델을 사용하는 연구가 늘어나고 있다. 이러한 prior-based 방법은 더 얼굴과 유사한 이미지와 더 다양한 사진들을 복원할 수 있다.
PULSE는 이러한 방법을 제시한 방식이다. 간단하게 정리하자면, SR 이미지를 생성한 후 그 이미지를 다시 LR로 낮추었을 때, 원래 LR과 비슷하게 만드는 방식으로 훈련하는 방법이다. 다시 LR로 낮추었을 때 input LR과 같아야 똑같은 사람이라고 생각할 수 있으며, 여기에서는 StyleGAN을 이용했다.
이 때 PULSE에서는 랜덤으로 샘플된 input을 StyleGAN에 넣는데, 이를 개선하기 위해 GLEAN, CFP-GAN, GPEN 등이 개발되었다.
3. 나머지 방법들
강화 학습을 이용한 방법, GAN과 CNN 및 RNN 베이스의 모델을 두 개 이상 Ensemble하는 Ensemble 방법 등이 있다.
Prior-guided FSR
일반적인 FSR 방법과는 다르게, facial landmark나 parsing map 등 얼굴만의 특징적인 정보를 이용하여 FSR을 수행하는 방식이다. 그러한 특징적인 정보를 뽑아내는 위치에 따라서 4가지로 나눌 수 있다.
1. Pre-prior Methods
이 방식은 FSR 모델 전에 특징적인 정보를 추출하여, 그 정보와 같이 FSR 모델을 훈련시키는 방식이다. 즉, LR 이미지에서 특징적인 정보를 추출하고 해당 정보를 FSR 모델의 subnetwork 등에 투입하여 훈련하는 방식이다.
LCGE와 MNCEFH에서는 LR 이미지에서 랜드마크를 잡아 얼굴을 여러 부분으로 나누어 훈련하는 방식을 사용하였는데, LR 이미지에서 랜드마크의 정확성이 낮아 parsing maps를 활용한 PSFR-GAN, SeRNET, CAFGace와 같은 연구가 진행되었다.
2. Parallel-prior Methods
pre-prior methods는 특징 정보 추출과 FSR 모델의 성능이 서로 영향을 미치는 상관관계를 완전히 무시한다. 이러한 이유로, 서로 성능에 영향을 미치기 때문에 FSR 모델과 얼굴 특징 정보 추출을 동시에 진행하는 Parallel-prior methods가 제안되었다.
그 중에 가장 유명한 것은 JASRNet으로, 동시에 SR을 위한 feature와 얼굴 특징 정보를 추출하는 shared encoder를 사용한다.
3. In-prior Methods
위의 두 가지 방법은 LR 이미지에서 곧바로 특징 정보를 추출한다. 하지만 LR 이미지는 품질이 좋지 않기 때문에, 특징 정보 추출에 어려움을 겪을 수 있다. 이러한 점을 개선하기 위하여 연구진들은 먼저 LR 이미지를 복원하고 특징 정보를 추출한 후, 복원한 이미지를 개선하는 방식을 사용하였다.
FSRNet, FSRGFCH, HCFR에서는 먼저 LR 이미지를 고화질로 복원하여 중간 결과를 만들고, 그 중간 결과에서 특징 정보를 뽑아낸 후, 중간 결과를 최종 결과로 복원하는 데에 특징 정보를 사용하였다.
4. Post-prior Methods
앞의 방법과는 달리 post-prior methods에서는 LR 이미지 대신 SR 이미지에서 특징 정보를 추출한다. 먼저 LR 이미지로 SR을 수행하고 SR과 HR 이미지에서 face heatmap을 뽑아내기 위한 모델을 개선한다. 이를 이용해 heatmap을 구하고 최종 SR을 구한다.
In-prior과 다른 점은 특징적인 정보를 SR 모델의 도우미로만 사용한다는 것이다. Super-FAN, PFSRNet, Super-FAN, PFSRNet 연구를 참고해세요.
Attribute-constrained FSR
이미지의 특성(attribute)을 이용하여 FSR을 수행하는 방식이다. Prior-guided FSR과 다른 점은 특징이 아니라 특성이라는 것이다.... 무슨 차이인가 하면, 특징은 facial landmark, parsing maps 등 얼굴 이미지에서 기계적으로 측정 가능한 것이라면, 특성은 안경을 끼었는가, 립스틱을 발랐는가 등을 이야기하는 것이다. 즉, 굉장히 다양한 특성이 있을 수 있고 이를 수학적이고 기계적인 수치로 표현하기에는 살짝 힘든 것들이다.
또한, prior과 attribute가 다른 점은 prior은 LR 이미지를 무조건 알아야 하지만, attribute는 LR 이미지 없이 알 수 있다. 예를 들어, 범죄자의 이미지를 재구성할 때 찍힌 사진은 없지만 목격자의 증언에 따라 몽타주를 만들 수 있는 것처럼 말이다. 즉, LR 이미지 없이 attribute 만으로 SR을 하는 과정은 몽타주를 만드는 과정과 동일하다고 생각하면 좋겠다.
1. Given Attribute Methods
주어진 attribute를 SR 모델에 어떻게 적용하는가가 Attribute-constrained FSR에서 가장 중요한 숙제이다. 이를 위해 AGCycle-GAN 등의 관련 연구에서는 attribute 정보와 LR 이미지를 직접적으로 합치는 방식을 이용한다. 이러한 연구에서 Discriminator에 attribute-based loss function을 사용하여 attribute가 비슷한 SR 이미지를 만들기 위하여 사용한다.
반면에, AACNN과 같은 연구에서는 attribute에서 feature를 뽑아네어 FSR 모델을 향상시키는 데 사용한다.
2. Estimated Attribute Methods
위의 방식에서는 주어진 attribute만 사용하기 때문에, 없는 attribute가 있을 경우 급격하게 성능이 감소한다. 이를 개선하기 위하여 attribute를 예측하는 방법을 연구하였다. 이러한 연구에서는 attribute-based loss function을 이용하여 모델에서 attribute 정보를 올바르게 예측하도록 한다.
Identity-preserving FSR
LR 이미지와 SR 이미지의 사람이 아예 다른 사람처럼 생겼다면 SR의 성능이 아무리 좋다고 해도 좋은 FSR 모델이라고 부를 수 없을 것이다. 이러한 문제를 해결하기 위해 Identity-preserving FSR이 개발되었다. 아래 그림은 Identity-preserving FSR의 발전도이다.
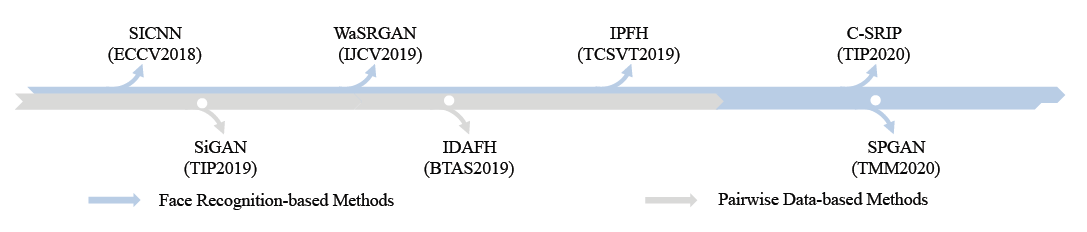
1. Face Recognition-based Methods
얼굴 인식을 통하여 Identity loss function을 사용해 서로 같은 사람처럼 보이는 SR 모델을 만들어가는 방법이다. SICNN, FH-GAN, WaSRGAN, IPFH, C-SRIP 및 ATSENet의 방법이 제안되었다.
이러한 연구들은 SR 모델과 미리 훈련된 얼굴 인식 모델, 그리고 추가적인 Discriminator로 이루어진다. SR 모델로 SR 이미지를 내놓는 동시에, LR 이미지와 SR 이미지의 Identity를 비교하여 Identity loss를 구해 훈련하는 방식을 사용한다.
SPGAN에서는 identity 특징을 더 강조하기 위하여 먼저 pretrained 얼굴 인식 모델을 통하여 identity 특징을 구하고 그것을 이용해 attention 기반의 identity loss로 훈련시킨다.
2. Pairwise Data-based Methods
위의 방법은 잘 레이블링 된 데이터셋을 필요로 한다. 누가 어떤 사람들이 알 수 있는 데이터가 필요하기 때문이다. 하지만 그러한 데이터셋은 아주 큰 비용을 필요로 한다. 그래서 잘 레이블링 되지 않은 데이터셋을 활용할 수 있어야 하는데, 이를 SiGAN이 해냈다. SiGAN은 두 LR 이미지가 동시에 들어갈 수 있는 GAN 모델 2개를 사용한다. 이 두 개의 모델에 다른 사람의 이미지를 넣으면 SR 이미지도 다르고, 같은 사람의 이미지를 넣으면 SR 이미지가 비슷해야 한다는 것을 모티브로 contrastive loss를 계산한다. 그러한 방식으로 같은 사람의 이미지는 최대한 같게, 다른 사람의 이미지는 다르게 복원하도록 훈련시킨다.
IADFH는 2개의 GAN 모델을 사용하는 대신 Discriminator에 pair 데이터를 동시에 투입하는 것으로 문제를 해결하였다.
Reference FSR
위의 방식들을 오직 한 장의 LR 사진만을 input으로 사용하였다. 하지만 같은 사람의 HR 이미지를 여러 장 가지고 있는 상황이 있을 수 있다. 이러한 상황에서는 HR 이미지에서 해당 사람의 Identity를 제공해 줄 수 있다. 이러한 Reference 이미지가 있는 상황에서는 더 높은 퀄리티의 SR 사진을 얻을 수 있을 것이다. 아래 사진은 Reference FSR의 발전도이다.
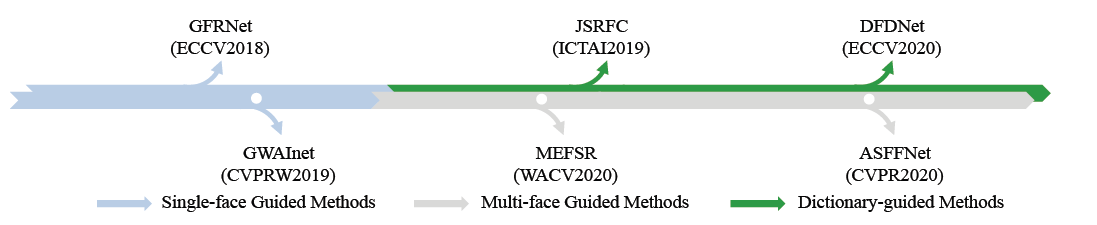
1. Single-face Guided Methods
한 장의 HR reference 이미지를 사용하는 방법이다. 그 이미지는 LR 이미지와 얼굴의 포즈와 방향이 다를 수 있으므로, LR 이미지의 얼굴과 포즈와 같게 HR reference 이미지의 포즈와 방향을 변경한다. 이후, LR 이미지와 변경한 reference 이미지를 GAN 네트워크에 넣는다. 이러한 연구에는 GFRNet과 GWAInet이 있다.
2. multi-face Guided Methods
실제로 한 사람의 고화질 이미지 다수가 존재할 수 있고, 이를 사용하기 위해 여러장의 reference 이미지를 사용하는 방법이다. 이러한 방식을 사용한 것은 ASFFNet가 최초이다. 여러 장의 사진중에 LR 사진과 가장 비슷한 포즈와 얼굴 표현을 하고 있는 reference 이미지를 찾아 그 사진을 사용하는 방법이다. 하지만 그 사진 역시 밝기 등의 차이가 분명히 있다는 문제가 존재한다. 이러한 문제를 해결하기 위하여 attention 기반의 adaptive feature fusion block을 사용하여 여러개의 reference 이미지의 정보를 뽑아내어 FSR에 적용하는 방법을 연구했다.
3. Dictionary-guided Methods
다른 사람이지만 얼굴의 특정 부분은 비슷할 수 있다. 예를 들어 아주 다르게 생긴 사람도 눈은 비슷할 수 있는 것처럼 말이다. 이러한 점을 사용하는 것이 해당 방법으로, JSRFC 및 DFDNet에서 제안되었다. 해당 방법은 얼굴 각 부위들을 사전처럼 가지고 있다가, LR 이미지와 닮은 부분들을 이용하여 FSR을 수행한다.
마무리
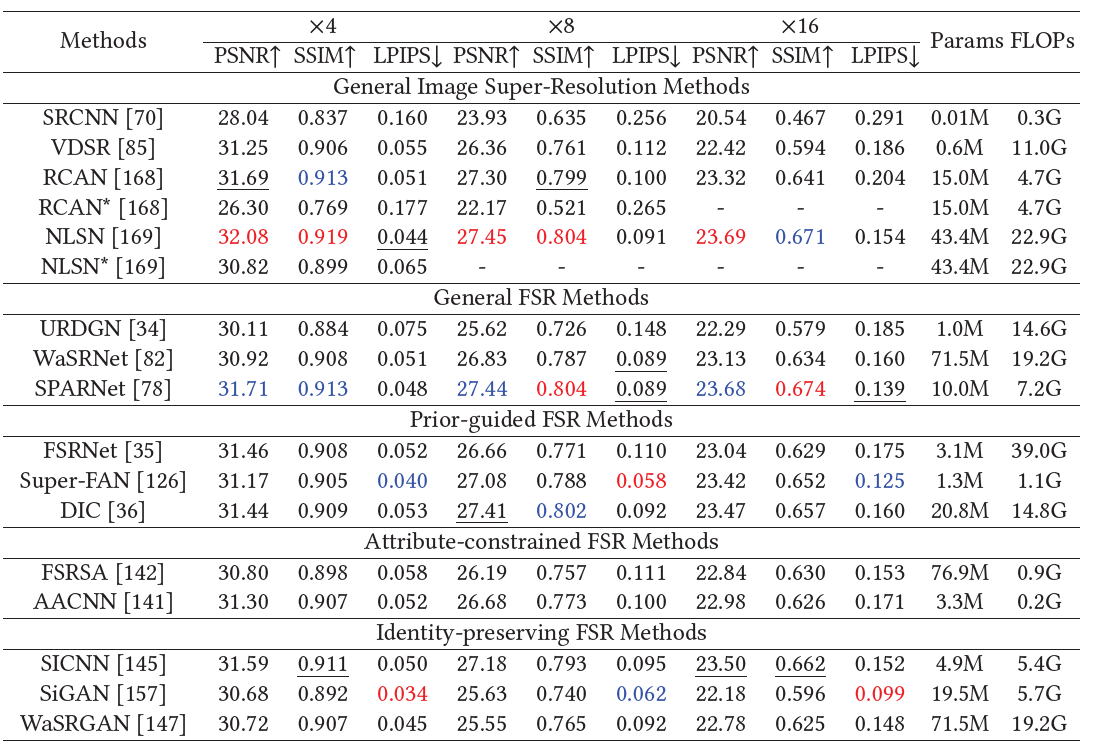
여러 벤치마크 결과는 다음과 같으며, 이보다 더 자세한 내용은 원본 논문 참고 부탁드립니다.
긴 글 읽어주셔서 감사합니다.
