[제 2 장] 기본 지식
성능 튜닝을 할 때는 애플리케이션 전체를 조사하고 수정해야 한다. 따라서 효과적인 성능 튜닝을 위해서는 하드웨어부터 3d 렌더링, Unity의 구조에 이르기까지 폭넓은 지식이 필요하다. 이 장에서는 성능 튜닝을 수행하기 위해 필요한 기초 지식에 대해 정리한다.
[2.1 하드웨어]
컴퓨터의 하드웨어는 크게 입력장치, 출력장치, 저장장치, 연산장치, 제어장치의 5가지 장치로 구성된다. 이를 컴퓨터의 5대 장치라고 한다. 이 절에서는 이러한 하드웨어 중 성능 튜닝에 있어 중요한 기초 지식을 정리한다.
[2.1.1] SoC
컴퓨터는 다양한 장치로 구성되어 있다. 대표적으로 제어와 연산을 위한 CPU, 그래픽 연산을 위한 GPU, 음성 및 영상 디지털 데이터를 처리하는 DSP 등이 있다. 대부분의 PC에선 이러한 장치가 별도의 집적회로로 독립되어 있고, 이를 조합하여 컴퓨터를 구성한다. 이에 반해 스마트폰에서는 소형화, 저전력화를 위해 이 장치들이 하나의 칩에 구현되어 있다. 이를 System on a chip, 즉 SoC 라고 부른다.
[2.1.2] 아이폰, 안드로이드와 SoC
스마트폰은 기종에 따라 탑재되는 SoC가 다르다.
예를 들어, 아이폰에는 애플이 설계한 A 시리즈라는 SoC가 사용된다. 이 시리즈는 A15와 같이 'A'라는 글자와 숫자의 조합으로 명명되며, 버전이 올라갈수록 숫자가 커진다.
이에 반해 많은 안드로이드에는 Snapdragon 이라는 SoC가 사용되고 있다. 이는 Qualcomm 이라는 회사가 제조하는 SoC 로, Snapdragon 8 Gen 1 이나 Snapdragon 888과 같이 명명된다.
또한, 아이폰이 애플사에서 제조하는 반면, 안드로이드는 다양한 제조사들이 제조하고 있다. 따라서 안드로이드에는 Snapdragon 외에도 다양한 SoC가 존재한다. 안드로이드에서 기종에 따른 결함이 발생하기 쉬운 것은 바로 이 때문이다.
- 삼성은 Exynos 라는 SoC를 사용한다고 나와있는데, S24 Ultra는 Sanpdragon 8 Gen 3 for Galaxy를 사용한다.
[2.1.3 CPU]
CPU(Central Processing Unit)는 컴퓨터의 두뇌라고 할 수 있는 존재로, 프로그램 실행은 물론이고 컴퓨터를 구성하는 다양한 하드웨어와의 연계를 담당하고 있다. 실제로 성능 튜닝을 할 때 CPU 안에서 어떤 처리가 이루어지고 어떤 특성이 있는지를 알면 도움이 된다.
<CPU의 기본>
프로그램의 실행 속도를 결정하는 것은 단순한 연산 능력뿐만 아니라 복잡한 프로그램 단계를 얼마나 빠르게 실행할 수 있느냐에 따라 겨정된다. 예를 들어 프로그램 중에는 사칙연산도 있지만, 분기 처리도 있다. CPU로서는 다음에 어떤 명령어가 호출될지 프로그램을 실행하기 전까지는 알 수 없다. 그래서 CPU는 다양한 명령어를 고속으로 연속적으로 처리할 수 있도록 설계되어 있다.
CPU내부에서 명령어가 처리되는 흐름을 파이프라인이라고 하며, 파이프라인 안에서 다음 명령어를 예측하면서 처리되고 있다. 만약 다음 명령어가 예측되지 않으면 파이프라인 스톨이라고 불리는 일시정지가 발생하여 한 번 리셋된다. 스톨을 일으키는 대부분의 원인은 분기 처리이다. 분기 자체도 어느 정도 결과를 예측하고 있지만, 그래도 실수할 수 있다. 내부 구조를 몰라도 성능 튜닝은 가능하지만 이런 것을 알아두는 것만으로도 코드를 작성할 때 루프 내에서 분기 피하기 등을 의식할 수 있게 된다.
<CPU의 연산 능력>
CPU의 연산 능력은 클럭 주파수 (단위는 Hz) 와 코어 수로 결정된다. 클럭 주파수는 1 초당 CPU가 몇 번이나 동작할 수 있는지를 나타낸다. 따라서 클럭 주파수가 높을수록 프로그램 실행 속도가 빠르다.
한편 코어 수는 CPU의 병렬 연산 능력에 기여한다. 코어는 CPU가 동작하는 기본 단위이며, 코어가 여러 개일 경우 멀티코어라고 한다. 원래는 싱글 코어만 있었으나, 싱글 코어의 경우 여러 프로그램을 실행시키기 위해 번갈아 가며 실행할 프로그램을 전환하고 있다. 이를 컨텍스트 스위치라고 하는데, 그 비용이 매우 높다. 그래서 최적의 처리 능력을 제공하기 위해 여러 개의 코어를 탑재한 멀티코어가 대세가 되었다. 스마트폰의 경우 2022년을 기준으로 현재 2~8코어가 주류를 이루고 있다.
- S24 Ultra에 탑재된 Sanpdragon 8 Gen 3 for Galaxy는 옥타코어(8개)이다.
최근 멀티코어는 비대칭 코어(big.LITTLE)를 탑재한 CPU가 주류를 이루고 있다. 비대칭 코어란 고성능 코어와 저전력 코어를 함께 탑재한 CPU를 말한다. 비대칭 코어의 장점은 평소에는 저전력 코어만 구동해 배터리 소모를 줄이고, 게임 등 성능을 내야 할 때 코어를 전환해 사용할 수 있다는 점이다. 단, 절전 코어만큼 병렬 성능의 최대치가 떨어지므로 코어 수만으로는 판단할 수 없다는 점에 유의해야한다.
또한 프로그램이 여러개의 코어를 사용할 수 있는지 여부는 프로그램의 병렬 처리 설명에 따라 달라진다. 예를 들어 게임 엔진 측에서 물리엔진을 별도의 스레드에서 구동하는 등 효율을 높은 경우와 Unity의 JobSystem등을 통해 병렬처리를 활용하는 경우도 있지만, 게임의 메인 루프 자체의 동작은 병렬화할 수 없기 때문에 멀티코어라도 코어 자체의 성능이 높은 것이 유리하다.
<CPU의 캐시 메모리>
CPU와 메인 메모리는 물리적으로 멀리 떨어져 있으며, 접근하는데 약간의 시간(Latency)이 필요하다. 따라서 프로그램 실행 시 메인 메모리에 저장된 데이터에 접근하려고 할 때, 이 거리가 성능에 큰 병목현상이 발생한다. 그래서 이 Latency 문제를 해결하기 위해 CPU 내부에는 캐시 메모리가 탑재되어 있다. 캐시 메모리는 주로 메인 메모리에 저장된 데이터의 일부를 저장하여 프로그램이 필요로 하는 데이터에 빠르게 접근 할 수 있도록 한다. 캐시 메모리에는 L1, L2, L3 캐시가 있는데, 숫자가 작을수록 속도가 빠르지만 용량이 작다. 얼마나 작은 용량인가 하면, L3캐시도 2~4MB 수준이다. 따라서 CPU 캐시에는 모든 데이터를 저장할 수 없고, 가장 최근에 처리한 데이터만 캐시된다.
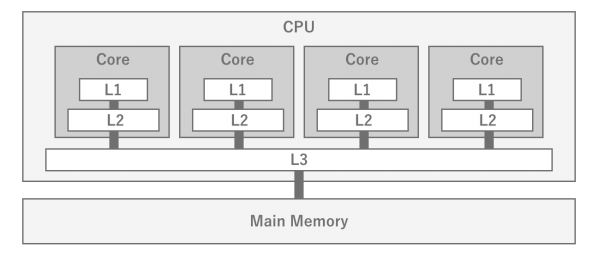
따라서 프로그램의 성능을 높이기 위해서는 데이터를 얼마나 효율적으로 캐시에 담을 수 있느냐가 관건인데, 프로그램 측에서 캐시를 자유롭게 제어할 수 없기 때문에 데이터의 국소성이 중요해진다. 게임 엔진에서는 데이터의 국소성을 고려한 메모리 관리가 어렵지만 유니티의 JobSystem 등 일부 구조에서는 데이터의 국소성을 높인 메모리 배치를 구현할 수 있다.
[2.1.4 GPU]
CPU가 프로그램 실행에 특화되어 있는 반면, GPU(Graphics Processing Unit)는 이미지 처리나 그래픽을 그리는 데 특화된 하드웨어이다.
<GPU의 기본>
GPU는 그래픽 처리에 특화되어 있기 때문에 CPU와 구조가 크게 다르며, 간단한 계산을 대량으로 병렬로 처리 할 수 있도록 설계되어 있다. 예를 들어 한 장의 이미지를 흑백으로 만들고 싶을 때, CPU로 계산할 경우 어떤 좌표의 RGB 값을 메모리에서 읽어와서 그레이 스케일로 변환하여 다시 메모리에 넣는 과정을 픽셀 단위로 수행해야한다. 이러한 처리는 분기도 없고, 각 픽셀의 계산은 다른 픽셀의 결과에 의존하지 않기 때문에 각 픽셀의 계산을 병렬로 수행하기 쉽다.
따라서 GPU에서는 대량의 데이터에 대해 동일한 연산을 적용하는 병렬처리를 빠르게 수행할 수 있고, 그 결과 그래픽 처리도 빠르게 수행할 수 있다. 특히 그래픽 계열에서는 부동소수점 연산이 많이 필요하기 때문에 GPU는 부동소수점 연산을 잘하도록 설계된다. 그래서 1초에 몇 번이나 부동소수점 연산을 할 수 있는지 나타내는 FLOPS라는 성능 지표가 일반적으로 사용된다. 또한, 연산 능력만으로는 알기 어렵기 때문에 1초당 몇 개의 픽셀을 그릴 수 있는지를 나타내는 필레이트(Fill Rate)라는 지표도 사용된다.
<GPU의 연산 능력>
GPU의 하드웨어 특징은 정수 및 부동소수점 연산 단위를 포함하는 코어가 대량(수십~수천 개)으로 배치되어 있다는 점이다. 코어를 많이 배치하기 위해 CPU에서 필요했던 복잡한 프로그램을 실행하는 데 필요한 단위는 필요 없으므로 생략되어 있다. 또한 CPU와 마찬가지로 동작하는 클럭 주파수가 높을수록 초당 많은 연산을 할 수 있다.
<GPU의 메모리>
GPU도 당연히 데이터를 처리하기 위해 일시적으로 저장할 수 있는 메모리 영역이 필요하다. 보통 이 영역은 메인 메모리와 달리 GPU 전용 메모리가 된다. 따라서 어떤 처리를 하기 위해서는 메인 메모리에서 GPU의 메모리로 데이터를 전송해야 한다. 처리 후에는 역순으로 메인 메모리로 되돌려 놓는다. 예를 들어 여러 해상도의 큰 텍스처를 전송하는 등 전송량이 많을 경우, 전송에 시간이 걸려 처리의 병목현상이 발생할 수 있으므로 주의해야한다.
그러나 모바일에서는 GPU 전용 메모리를 탑재하지 않고 CPU와 GPU가 메인 메모리를 공유하는 아키텍처가 일반적이다. 이는 GPU의 메모리 용량을 동적으로 변경할 수 있다는 장점이 있는 반면, 전송 대역을 CPU와 GPU가 공유한다는 단점이있다. 또한 이 경우에도 CPU와 GPU의 메모리 영역 간 데이터 전송이 필요하다.
<GPGPU>
CPU가 취약했던 대용량 데이터에 대한 병렬 연산을 GPU에서 고속으로 수행할 수 있기 때문에 최근에는 GPu를 그래픽 처리 이외의 목적으로도 적용하는 사례가 있다. GPGPU(General Purpose GPU)라고 불리고 있다. 특히 AI 등의 머신러닝이나 블록체인 등의 계산 처리에 적용되는 사례가 많아지면서 GPU의 수요가 급증하고, 가격 상승 등의 영향도 나타나고 있다. 유니티에서도 컴퓨트 셰이더라는 기능을 통해 GPGPU를 활용할 수 있다.
-> GPGPU의 가장 유명한 사례는 비트코인 채굴이다.
[2.1.5 메모리]
CPU는 그 순간 계산에 필요한 데이터만 가지고 있기 때문에 기본적으로 모든 데이터는 메인 메모리에 저장된다. 물리적인 용량 이상의 메모리를 사용할 수 없기 때문에 너무 많이 사용하면 메모리를 확보할 수 없게 되고, 프로세스가 OS에 의해 강제 종료된다.
일반적으로 이를 OOM(Out Of Memory)로 Kill 되었다고 표현한다. 2022년 기준으로 스마트폰에서는 4~8GB의 메모리 용량을 갖춘 단말기가 대세지만 그래도 메모리를 너무 많이 사용하지 않도록 주의하자.
또한 앞서 언급했듯이 메모리가 CPU와 떨어져 있기 때문에 메모리를 의식한 구현을 하느냐 마느냐에 따라 성능 자체도 달라진다. 이 절에서는 성능을 고려한 구현을 할 수 있도록 프로그램과 메모리의 관계에 대해 설명한다.
<메모리 하드웨어>
메인 메모리가 SoC 안에 있는 것이 물리적인 거리상 유리하지만, 메모리는 SoC에 포함되지 않는다. 왜냐하면 SoC 안에 포함되면 메모리 탑재량을 단말기마다 다르게 할 수 없기 때문이다. 하지만 메인 메모리가 느리면 프로그램 실행 속도에 큰 영향을 미치기 때문에 상대적으로 빠른 버스로 SoC와 메모리를 연결한다. 이 메모리와 버스의 규격으로 스마트폰에서 일반적으로 사용되는 것이 바로 LPDDR 이라는 규격이다. LPDDR에도 여러 세대가 있는데, 이론적으로 수 Gbps정도의 전송 속도이다. 물론 항상 이론상의 성능을 끌어낼 수는 없지만 게임 개발에서 이 부분 때문에 병목현상이 되는 경우는 거의 없기 때문에 크게 의식할 필요는 없다.
<메모리와 OS>
OS 안에는 많은 프로세스가 동시에 실행되고 있는데, 크게 시스템 프로세스와 사용자 프로세스가 있다. 시스템계는 OS를 구동하기 위해 중요한 역할을 하는 프로세스가 많고, 서비스로 상주하며 대부분 사용자의 의지와는 무관하게 계속 움직인다. 반면 사용자계는 사용자의 의지로 실행되는 프로세스로, OS를 구동하기 위해 필수적인 프로세스는 아니다.
스마트폰에선 앱의 표시 상태로 포그라운드(전면)와 백그라운드(숨김) 상태가 있는데, 일반적으로 특정 앱을 포그라운드로 설정하면 다른 앱은 백그라운드가 된다. 앱이 백그라운드에 있는 동안에도 복귀 처리를 원활하게 하기 위해 프로세스는 일시정지 상태로 존재하며, 메모리도 그대로 유지된다. 그런데 전체적으로 사용 중인 메모리가 부족해지면 OS에서 정한 우선순위에 따라 프로세스를 Kill 한다. 이 때 Kill 되기 쉬운 것이 메모리를 많이 사용하는 백그라운드 상태의 사용자계 앱(대부분 게임)이다. 즉, 메모리를 많이 사용하는 게임은 백그라운드로 이동했을 때 Kill 될 가능성이 높아지며, 이로 인해 게임으로 돌아와도 다시 처음부터 시작해야 하기 때문에 사용자 체감도가 떨어지게 된다.
만약 메모리를 확보하려고 할 때 다른 Kill 할 수 있는 프로세스가 없다면 자신이 Kill 의 대상이 된다. 또한 iOS와 같이 하나의 프로세스가 물리 용량의 일정 비율 이상의 메모리를 사용할 수 없도록 제어하는 경우도 있다. 따라서 애초에 메모리를 확보할 수 있는 한계라는 것이 존재한다. 예를 들어 RAM 이 3GB인 iOS 단말기의 경우 1.3~1.4GB 정도가 한계이기 때문에 게임을 만드는 데 있어서는 이 정도가 한계라고 생각하면 된다.
<메모리 스왑>
현실에는 다양한 하드웨어의 단말기가 있고, 탑재된 메모리의 물리적 용량이 매우 작은 단말기도 있다. OS는 그런 단말에서도 최대한 많은 프로세스를 구동하기 위해 다양한 방법으로 가상의 메모리 용량을 확보하려고 한다. 그것이 바로 메모리 스왑이다.
메모리 스왑에서 사용되는 한 가지 방법이 메모리 압축이다. 한동안 접근하지 않는 메모리를 중심으로 압축하여 메모리 상에 저장함으로써 물리적인 용량을 절약한다. 다만 압축과 전개 비용이 발생하기 때문에 이용이 활발한 영역이 아닌, 예를 들어 백그라운드에 있는 앱에 대해서만 수행된다.
또 다른 방법은 사용하지 않는 메모리의 저장소 퇴출이다. PC와 같이 스토리지가 넉넉한 하드웨어에서는 프로세스를 종료하여 메모리를 확보하는 것이 아니라 덜 사용되는 메모리를 스토리지로 대피시켜 물리 메모리의 여유 공간을 확보하려는 경우가 있다. 이는 메모리 압축보다 대용량의 메모리를 확보할 수 있다는 장점이 있지만, 스토리지는 메모리보다 속도가 느리기 때문에 성능상의 제약이 심하고 애초에 스토리지의 크기가 작은 스마트폰에서는 그다지 현실적이지 않기 때문에 채택되지 않고 있다.
<스택과 힙>
스택은 프로그램의 동작과 깊은 관련이 있는 전용 고정 영역이다. 함수가 호출되는 타이밍에 인수나 지역변수등의 분량이 확보되고, 원래의 함수로 돌아갈 때 확보한 분량을 해제하고 반환값을 쌓아 올린다. 즉, 함수 안에서 다음 함수를 호출할 때 현재 함수의 정보를 그대로 유지한 채 다음 함수를 메모리에 쌓아간다. 이렇게 함으로써 함수 호출의 구조를 구현하고 있다. 스택 메모리는 아키텍처에 따라 다르지만 1MB로 용량 자체가 매우 적기 때문에 한정된 데이터만 저장한다.
반면 힙은 프로그램 내부에서 자유롭게 사용할 수 있는 메모리 영역이다. 프로그램이 필요하면 언제든지 메모리 확보 명령어 (C 에서는 malloc) 를 내어 대용량의 데이터를 확보하여 사용할 수 있다. 물론 다 쓰고 나면 해제 처리 (free) 가 필요하다. C#에서는 메모리 확보와 해제 처리가 런타임에 자동으로 이루어지기 때문에 구현자가 명시적으로 할 필요가 없다.
OS측에서는 언제 얼마나 많은 메모리 용량이 필요할지 모르기 때문에 필요한 타이밍에 메모리의 여유 공간에서 확보하여 전달한다. 메모리를 확보하려고 할 때 연속적으로 그 크기를 확보하지 못하면 메모리 부족이 발생하게 된다. 이 연속이라는 키워드가 중요하다. 일반적으로 메모리 확보와 해제를 반복하면 메모리 조각화가 발생한다. 메모리가 조각화되면 전체 합계로는 여유 공간이 충분해도 연속적으로 비어있는 공간이 없는 경우를 생각할 수 있다. 이런 경우, OS는 우선적으로 힙 확장을 해야한다.
즉, 프로세스에 할당할 메모리를 새로 할당하여 연속적인 영역을 확보한다. 하지만 시스템 전체의 메모리는 유한하기 때문에 새로 할당할 메모리가 없어지면 OS에서 프로세스를 Kill 하게 된다.
스택과 힙을 비교할 때 메모리 확보 성능에 현저한 차이가 발생한다. 이는 함수에 필요한 스택의 메모리 양은 컴파일 시점에 확정되기 때문에 메모리 영역이 이미 확보된 반면, 힙은 실행할 때까지 필요한 메모리 양을 알 수 없기 때문에 매번 빈 공간을 찾아 확보해야 하기 때문이다. 이것이 힙이 느리고 스택이 빠른 이유이다.
<Stack Overflow 에러>
Stack overflow 에러는 함수의 재귀 호출 등으로 스택 메모리를 다 써버렸을 때 발생하는 에러이다. iOS/Android의 기본 스택 크기는 1MB 이므로 재귀 호출로 인한 탐색 규모가 커지면 발생하기 쉽다. 일반적으로 재귀 호출을 하지 않거나, 재귀 호출이 깊지 않은 알고리즘으로 변경하는 등의 대책이 필요하다.
[2.1.6 스토리지]
실제로 튜닝을 진행하다 보면 파일을 불러오는 장면에서 시간이 오래 걸리는 경우가 많다는 것을 알 수 있다. 파일을 불러온다는 것은 파일이 저장되어 있는 스토리지에서 데이터를 읽어들여 프로그램에서 처리할 수 있도록 메모리에 기록하는 것이다. 그래서 실제로 어떤 일이 일어나는지 알아두면 튜닝할 때 도움이 될 수 있다.
먼저 일반적인 하드웨어 아키텍처의 경우, 데이터를 영속화하기 위해 전용 스토리지를 가지고 있다. 스토리지는 대용량이면서 전원 없이 데이터를 영속화(비휘발성) 할 수 있다. 이 특징을 활용하여 방대한 자산은 물론, 앱 자체의 프로그램 등도 스토리지에 저장되며, 실행 시점에 스토리지에서 불러와 실행하게 된다.
<RAM과 ROM>
특히 국내에서는 스마트폰의 메모리를 RAM, 스토리지를 ROM으로 표기하는 것이 일반적이지만, 사실 ROM은 읽기 전용 메모리(Read Only Memory) 를 뜻한다. 이름에서 알 수 있듯이 읽기 전용이고 쓰기가 불가능해야 하는데도 이 용어가 쓰이는 것은 일본의 관습이 강한 것 같다.
그런데 이 스토리지에 대한 읽기/쓰기 처리를 몇 가지 측면에서 프로그램 실행 주기에 비해 매우 느린 편이다.
- CPU와의 물리적 거리가 메모리에 비해 멀기 때문에 레이턴시가 크고 읽기/쓰기 속도가 느리다.
- 명령된 데이터와 그 주변을 포함하여 블록 단위로 읽어들이기 때문에 낭비가 많다.
- 순차적 읽기/쓰기는 빠른 반면, 임의적 읽기/쓰기는 느리다.
특히 이 무작위 읽기/쓰기가 느리다는 것은 중요한 포인트이다. 애초에 어떤 상황에서 순차적이 되고 어떤 상황에서 랜덤이 되는가 하면, 하나의 파일을 처음부터 순서대로 읽거나 쓰는 경우는 순차적이 되지만 하나의 파일에서 여러 군데를 건너뛰며 읽거나 쓰는 경우, 또는 여러 개의 작은 파일을 읽거나 쓰는 경우에는 랜덤이 된다. 주의할 점은 같은 디렉토리에 있는 여러 개의 파일을 읽고 쓰는 경우에도 물리적으로 연속적으로 배치되어 있는 것은 아니기 때문에 물리적으로 떨어져 있는 경우 랜덤이 된다.
<스토리지에서 읽기 처리>
스토리지에서 파일을 읽어올 때, 대략 아래와 같은 흐름으로 처리된다.
1. 프로그램이 스토리지에서 읽으려는 파일의 영역을 스토리지 컨트롤러에 명령
2. 스토리지 컨트롤러가 명령을 받아 데이터가 있는 물리적으로 읽을 영역을 계산
3. 데이터를 읽음
4. 데이터를 메모리에 쓰기
5. 프로그램이 메모리를 통해 데이터에 접근함
하드웨어나 아키텍처에 따라 컨트롤러 등의 레이어가 더 추가되기도 한다. 정확히 기억할 필요는 없지만, 메모리에서 읽어오는 것에 비해 하드웨어의 처리 과정이 많다는 것을 인지하고 있어야 한다.
또한 일반적인 스토리지는 하나의 파일을 4KB와 같은 블록 단위로 기록하여 성능과 공간 효율성을 달성하고 있다. 이 블록은 하나의 파일이라고 해도 물리적으로 연속적으로 배치되어 있는 것은 아니다. 파일이 물리적으로 분산되어 있는 상태를 조각화(프로그멘테이션) 라고 부르며, 조각화를 해소하는 작업을 조각화 제거라고 한다. PC의 주류를 이루던 HDD에서는 조각화가 문제가 되는 경우가 많았지만, 플래시 스토리지로 인해 그 영향은 거의 사라졌다. 스마트폰에서는 파일 조각화를 의식할 필요가 없지만, PC를 고려한다면 주의해야 한다.
<PC와 스마트폰의 스토리지 종류>
PC의 세계에서는 HDD와 SSD가 주류인데, HDD는 CD처럼 원반 모양으로 기록되는 미디어로, 디스크 위에 헤드가 움직여 자기를 읽어내는 방식이다. 그래서 구조적으로도 크고, 물리적인 움직임이 발생하기 때문에 지연이 큰 장치였다. 최근에는 SSD가 보급되었는데, 이는 HDD와 달리 물리적인 움직임이 발생하지 않기 때문에 빠른 성능을 발휘하는 반면, 읽기/쓰기 횟수의 한계(수명)가 있어 자주 읽거나 쓰면 사용할 수 없게 되는 특징이 있다. 스마트폰은 SSD와 달리 NAND라는 플래시 메모리가 사용된다.
마지막으로 실제 스마트폰에서 스토리지가 어느 정도의 읽기/쓰기 속도를 가지고 있느냐는 것인데, 2022년 기준으로는 읽기가 100MB/s 정도이다. 예를 들어 10MB의 파일을 읽으려는 경우, 이상적인 상황에서도 파일 전체를 읽는 데 100ms가 필요하다는 것이다. 더군다나 여러 개의 작은 파일을 읽어들이는 경우 랜덤 액세스가 발생하기 때문에 점점 더 많은 시간이 소요된다. 이처럼 의외로 파일 로딩에 시간이 오래 걸린다는 것을 항상 염두에 두는 것이 좋다.
정리하자면, 파일 읽기/쓰기가 발생하는 경우 다음과 같은 관점을 의식하는 것이 좋다.
- 스토리지의 읽기/쓰기 속도는 의외로 느리고, 메모리와 동등한 속도를 기대하지 않는다.
- 동시에 읽고쓰는 파일 수를 최대한 줄인다. (타이밍을 분산시키거나, 하나의 파일로 묶는 등)
[2.2 렌더링]
게임에서 렌더링의 처리량은 종종 성능에 부정적인 영향을 미친다. 따라서 렌더링에 대한 지식은 성능 튜닝에 필수 적인 요소라고 할 수 있다. 따라서 이 절에서는 렌더링에 대한 기본 지식을 정리한다.
[2.2.1 렌더링 파이프라인]
컴퓨터 그래픽스에서는 3D모델의 버텍스 좌표, 라이트와 좌표와 색상 등의 데이터에 대해 일련의 처리를 거쳐 최종적으로 화면의 각 픽셀에 출력할 색을 출력한다. 이 처리 과정을 렌더링 파이프라인 이라고 한다.
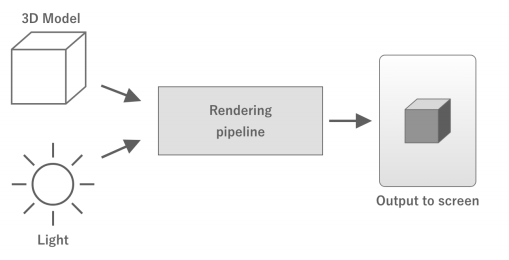
렌더링 파이프라인은 CPU에서 GPU로 필요한 데이터를 보내는 것으로 시작된다. 렌더링할 3D모델의 버텍스 좌표와 라이트 좌표를 비롯해 오브젝트의 재질 정보, 카메라 정보 등 다양한 데이터가 전송된다.
이때 전송되는 것은 3D모델의 버텍스 좌표와 카메라의 좌표, 방향, 화각 등 각각 개별적인 데이터이다. GPU는 이 정보들을 종합해 '해당 카메라로 해당 물체를 비췄을 때 화면의 어느 위치에 물체가 표시되는지'를 계산해 구한다. 이 과정을 좌표 변환이라고 한다.
객체가 화면의 어느 위치에 표시될지 결정되면, 다음으로 객체의 색을 구해야 한다. 이때 GPU는 '그 빛으로 그 재질의 모델을 비췄을 때, 화면의 각 픽셀에 해당하는 부분은 어떤 색이 될 것인가'를 계산해 구한다.
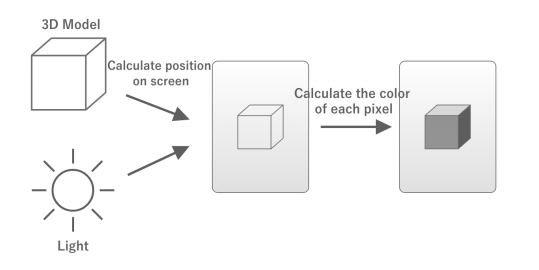
위의 처리 중 '화면의 어느 위치에 오브젝트가 표시될 것인가' 는 버텍스 셰이더 라는 프로그램에 의해 계산되며, '화면의 각 픽셀에 해당하는 부분은 어떤 색이 될 것인가' 는 프래그먼트 셰이더 라는 프로그램에 의해 계산된다.
그리고 이들 셰이더는 자유롭게 작성할 수 있습니다. 따라서 버텍스 셰이더나 프래그먼트 셰이더에 무거운 처리를 쓰면 처리 부하가 증가한다.
또한 버텍스 셰이더의 처리는 3D 모델의 버텍스수만큼 처리되기 때문에 버텍스 수가 많으면 많을수록 처리 부하가 커집니다. 프래그먼트 셰이더는 렌더링 대상 픽셀 수가 많을수록 처리 부하가 커진다.
<실제 렌더링 파이프라인>
실제 렌더링 파이프라인에는 버텍스 셰이더와 프래그먼트 셰이더 외에도 많은 프로세스가 존재하지만, 본 문서에서는 성능 튜닝에 필요한 개념의 이해를 목적으로 하므로 간략하게만 설명한다.
[2.2.2 반투명 렌더링과 오버드로우]
렌더링을 할 때 대상 오브젝트의 투명도는 중요한 문제이다. 예를 들어, 지금 카메라에서 봤을 때 일부가 겹치는 두 개의 오브젝트를 생각해보자.
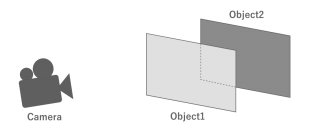
먼저 두 오브젝트가 모두 불투명한 경우를 생각해보자. 이 경우, 카메라에서 봤을 때 앞쪽에 있는 객체부터 순차적으로 그리기 처리를 한다. 이렇게 하면 뒤쪽의 오브젝트를 그릴 때 앞쪽의 오브젝트와 겹쳐서 보이지 않는 부분은 처리할 필요가 없다. 즉, 이 부분은 프래그먼트 셰이더의 연산을 생략할 수 있어 처리 부하를 최적화할 수 있다.
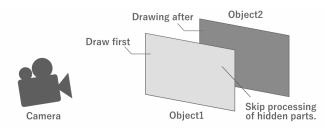
반면, 두 오브젝트가 모두 반투명인 경우, 앞의 오브젝트에 겹쳐진 부분이라도 뒤쪽의 오브젝트가 투명하게 보이지 않으면 부자연스럽다. 이 경우에는 카메라에서 볼 때 안쪽에 있는 오브젝트부터 순차적으로 드로잉 처리를 하고, 겹치는 부분의 색은 이미 드로잉된 색과 블렌딩한다.
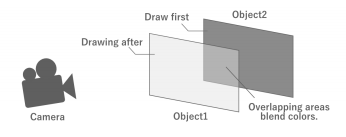
이처럼 반투명 드로잉은 불투명 드로잉과 달리 오브젝트끼리 겹치는 부분에 대해서도 드로잉 처리를 해야 한다. 만약 화면 전체에 그려지는 반투명 오브젝트가 두 개 존재한다면, 화면 전체에 대한 처리가 두 번 이루어지게 된다. 이렇게 반투명 오브젝트를 겹쳐서 그리는 것을 "오버드로우" 라고 한다. 오버드로우가 너무 많으면 GPU에 큰 처리 부하가 발생하여 성능 저하로 이어지기 때문에, 반투명 그리기를 할 때는 적절한 규제가 필요하다.
<포워드 렌더링 가정>
렌더링 파이프라인에는 여러 가지 구현 방법이 있다. 이 글에서는 포워드 렌더링을 가정하여 설명한다. 디퍼드 렌더링 등 다른 렌더링 기법에는 부분적으로 적용되지 않는 부분도 있다.
[2.2.3 드로우콜, 세트 패스 콜과 배칭]
렌더링은 GPU뿐만 아니라 CPU에도 많은 처리 부하가 발생한다.
위에서 언급했듯이, 오브젝트를 렌더링할 때 CPU에서 GPU에 그리기 위한 명령을 내린다. 이를 "드로우 콜" 이라고 하며, 렌더링할 오브젝트 수만큼 실행된다. 이 때 텍스처 등의 정보가 이전 드로우콜에서 그린 오브젝트의 텍스처와 다를 경우, 이를 GPU에 설정하는 과정을 거친다. 이는 "세트 패스 콜" 이라고 불리며, 비교적 무거운 작업이다. 이 과정은 CPU의 렌더 스레드에서 이루어지기 때문에 CPU의 처리 부하를 유발하고, 너무 많으면 성능에 영향을 미친다.
유니티에는 드로우 콜을 줄이기 위해 "드로우 콜 배칭" 이라는 메커니즘이 구현되어 있다. 이는 동일한 텍스처 등의 정보, 즉 동일한 머티리얼을 가진 오브젝트의 메시를 CPU측에서 미리 결합하여 한 번의 드로우 콜로 그리는 방식이다. "런타임에 배치하기", "다이나믹 배칭", "미리 결합된 메시를 생성해 두는 정적 배칭" 이 존재한다.
또한 Scriptable Render Pipeline 에는 SRP Batcher 라는 메커니즘이 구현되어 있다. 이를 사용하면 셰이더 변형이 동일하다면, 메시나 머티리얼이 다르더라도 세트 패스 호출을 한 번으로 묶을 수 있다. 드로우 콜은 줄어들지 않지만, 처리 부하가 큰 것은 세트 패스 코이기 때문에 이를 줄이기 위한 구조이다.
<GPU 인스턴싱>
배치와 비슷한 효과를 얻을 수 있는 기능으로 GPU 인스턴싱이 있다. 이는 GPU의 기능을 이용해서 동일한 메시를 가진 오브젝트를 한 번의 드로우 콜, 세트 패스 콜로 그릴 수 있는 기능이다.
[2.3 데이터 표현 방법]
게임에는 이미지, 3D 모델, 음성, 애니메이션 등 다양한 데이터가 사용된다. 이러한 데이터가 어떻게 디지털 데이터로 표현되는지 아는 것은 메모리와 스토리지 용량을 계산하고, 압축 등의 설정을 적절히 하는 데 있어 중요하다. 이 절에서는 기본적인 데이터 표현 방법에 대해 정리한다.
[2.3.1 비트와 바이트]
컴퓨터가 표현할 수 있는 가장 작은 단위는 비트이다. 1비트는 2진수 1자리로 표현할 수 있는 범위, 즉 0과 1의 두 가지 조합을 표현할 수 있다. 예를 들어 스위치의 ON/OFF와 같은 간단한 정보만 표현할 수 있다.
여기서 2비트를 사용하면 2진수 2자리로 표현할 수 있는 범위, 즉 4종류의 조합을 표현할 수 있다. 예를 들어 상하좌우 같은 정보를 표현할 수 있다.
마찬가지로 8비트가 되면 2진수 8자리로 표현할 수 있는 범위, 즉 2^8=256종류를 표현할 수 있다. 여기까지 오면 다양한 정보를 표현할 수 있다. 이러한 8비트는 1바이트라고 표현한다. 즉 1바이트는 256가지의 정보량을 표현할 수 있는 단위인 것이다.
또한 더 큰 숫자를 나타내는 단위로 1000 바이트를 나타내는 1킬로바이트 (KB)나 1000킬로바이트를 나타내는 1메가바이트(MB) 등이 존재한다.
<킬로바이트와 키비바이트>
위에서는 1KB를 1000바이트라고 썼지만, 문맥에 따라 1KB를 1024바이트로 표기하는 경우도 있다. 명시적으로 구분하는 경우에는 1000바이트를 1킬로바이트(KB)라고 부르고, 1024바이트를 1키비바이트(KiB)라고 부른다. 메가바이트도 마찬가지이다.
[2.3.2 이미지]
이미지 데이터는 픽셀의 집합으로 표현된다. 예를 들어 8*8 픽셀의 이미지라면 총 64개의 픽셀로 구성되어 있다.
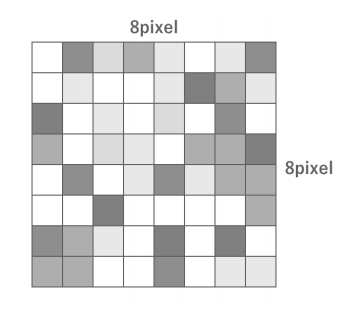
이때 각 픽셀은 각각 색상 데이터를 가지고 있다. 그렇다면 색은 디지털 데이터에서 어떻게 표현될까?
우선 색은 빨강, 초록, 파랑, 투명도의 4가지 요소를 조합하여 만들어진다. 이를 채널이라고 부르며, 각 채널의 머리글자를 따서 RGBA라고 표현한다.
흔히 사용되는 True Color 라는 색상 표현 방식에서는 RGBA의 각 값을 각각 256 단계로 표현한다. 앞 절에서 설명했듯이 256 단계는 8비트이다. 즉 True Color는 4채널 * 8비트 = 32비트의 정보량으로 표현 할 수 있다.
따라서 88 픽셀의 True Color 이미지라면, 그 정보량은 8픽셀 8픽셀 4채널 8비트 = 2048비트 = 256 바이트가 된다. 1024 1024 픽셀의 True Color 이미지의 정보량은 1024픽셀 1024픽셀 4채널 8비트 = 33,554,432비트 = 4,194,304바이트 = 4,096킬로바이트 = 4메가바이트가 된다.
[2.3.3 이미지 압축]
실제로 이미지는 대부분 압축된 데이터로 사용된다.
압축이란 데이터를 저장하는 방법을 고안하여 데이터 용량을 줄이는 것을 말한다. 예를 들어 지금 같은 색의 픽셀이 5개나 나란히 있다고 가정해보자. 이 경우 각 픽셀의 색상 정보를 5개씩 가지고 있는 것보다 색상 정보 1개와 그것이 5개가 나란히 있다는 정보를 가지고 있는 것이 정보량을 줄일 수 있다.

실제로는 이보다 더 복잡한 압축 방법이 많이 존재한다.
구체적인 예로 모바일의 대표적인 압축 포맷인 ASTC를 소개한다. ASTC6x6이라는 포맷을 적용하면 1024*1024의 텍스처가 4메가바이트에서 약 0.46메가바이트로 압축된다. 즉, 용량이 8분의1 이하로 압축된 결과로 압축의 중요성을 알 수 있다.
참고로 Unity에서는 텍스처 임포트 설정에 따라 플랫폼별로 다양한 압축 방식을 지정할 수 있다. 따라서 비압축 이미지를 임포트하고, 이 임포트 설정에 따라 압축을 적용하여 최종적으로 사용되는 텍스처를 생성하는 방식이 일반적이다.
<GPU와 압축 형식>
어떤 규칙에 따라 압축된 이미지는 당연히 그 규칙에 따라 압축을 풀어야 한다. 이 전개 과정은 런타임에 이루어진다. 이 처리 부하를 최소화하기 위해서는 GPU가 지원하는 압축 포맷을 사용하는 것이 중요하다. 모바일 기기의 GPU가 지원하는 대표적인 압축 포맷으로 ASTC를 들 수 있다.
[2.3.4 메시]
3DCG에서는 3D 공간 위에 수많은 삼각형을 연결하여 입체적인 형상을 표현한다. 이 삼각형의 집합을 "메시(Mesh)" 라고한다.
이 삼각형은 데이터로서는 3D공간상의 3점의 좌표 정보로 표현할 수 있다. 이 각 점을 정점이라고 부르며, 그 좌표를 정점 좌표 라고 한다. 또한 메시 하나당 버텍스 정보는 모두 하나의 배열에 저장된다.
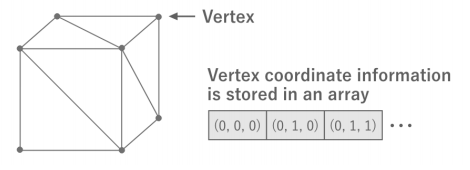
버텍스 정보는 하나의 배열에 저장되기 때문에, 이 중 어느 것을 조합하여 삼각형을 구성할 것인지에 대한 정보가 별도로 필요하다. 이를 "버텍스 인덱스" 라고 부르며, 버텍스 정보 배열의 인덱스를 나타내는 int 타입의 배열로 표현한다.
오브젝트에 텍스처를 붙이거나 라이팅을 하기 위해서는 더 많은 정보가 필요하다. 예를 들어 텍스처를 매핑하려면 UV좌표가 필요하다. 또한 라이팅을 할 때는 버텍스 컬러, 노멀, 접선 등의 정보도 사용된다.
다음 표는 주요 버텍스 정보와 버텍스당 정보량을 정리한 것이다.
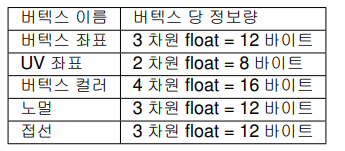
메시의 데이터는 버텍스의 수와 하나의 버텍스에서 다루는 정보의 양이 많아질수록 커지므로, 버텍스 수와 버텍스 정보의 종류를 미리 정해두는 것이 중요하다.
[2.3.5 키프레임 애니메이션]
게임에서는 UI의 애니메이션, 3D 모델의 모션 등 많은 부분에서 애니메이션을 사용한다. 애니메이션을 구현하는 대표적인 방법으로 키프레임 애니메이션이 있다.
키프레임 애니메이션은 특정 시간(키프레임)의 값을 나타내는 데이터 배열로 구성된다. 키프레임 사이의 값은 보간을 통해 얻어지기 때문에 마치 매끄럽게 연속된 데이터인 것처럼 취급할 수 있다.
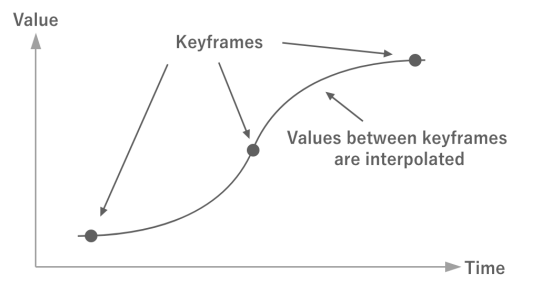
키프레임이 가지고 있는 정보는 시간과 값 외에도 접선과 그 가중치 등이 있다. 이를 보간 계산에 활용하면 적은 데이터 양으로 더 복잡한 애니메이션을 구현할 수 있다.
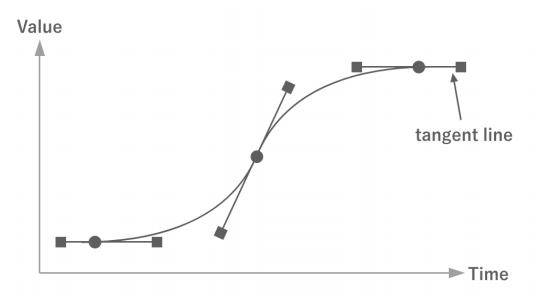
키프레임 애니메이션은 키프레임이 많을수록 복잡한 애니메이션을 표현할 수 있다. 하지만 데이터량도 키프레임의 수에 따라 증가한다. 이러한 이유로 키프레임 수를 적절히 설정해야 한다.
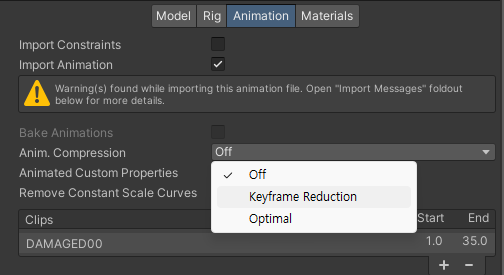
최대한 비슷한 곡선을 유지하면서 키프레임을 줄여 데이터량을 압축하는 방법도 있다. Unity의 경우 임포트 설정에서 아래 그림과 같이 키프레임을 줄일 수 있다.