
[2.4 Unity의 작동 원리]
Unity 엔진이 실제로 어떻게 돌아가는지 이해하는 것은 게임을 튜닝하는 데 있어 매우 중요하다. 이 절에서는 알아야 할 Unity의 작동 원리를 설명한다.
[2.4.1 바이너리와 런타임]
먼저 유니티가 실제로 어떤 원리로 런타임을 구동하는지에 대해 설명한다.
<C#과 런타임>
유니티로 게임을 만들 때, 개발자는 C#으로 동작을 프로그래밍한다. C#은 컴파일러형 언어이기 때문에 유니티에서 게임을 개발할 때 수시로 컴파일(빌드)이 실행된다. 그런데 C#이 전통적인 C 언어 등과 다른점은 컴파일하면 기계에서 단독으로 실행되는 기계어가 아니라 .NET의 중간 언어 (Intermediate Language; IL)로 컴파일된다는 점이다. IL로 변환된 실행 코드는 단독으로 실행할 수 없기 때문에 .NET Framework의 런타임을 이용하여 순차적으로 기계어로 변환하면서 실행된다.
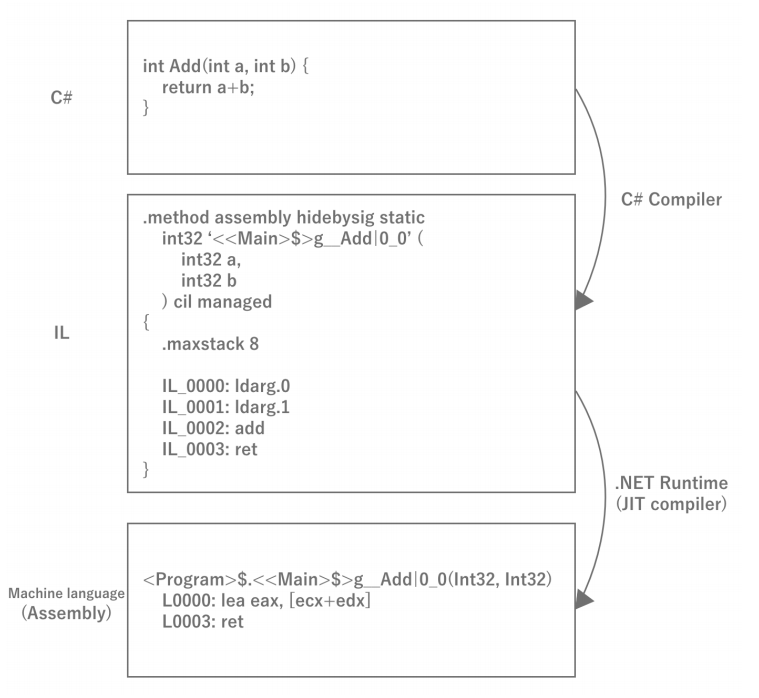
IL을 끼워 넣는 이유는 일단 기계어로 변환하면 단일 플랫폼에서만 실행할 수 있는 바이너리가 되기 때문이다. IL이라면 어떤 플랫폼에서든 해당 플랫폼에 맞는 런타임만 준비하면 동작하게 되므로 플랫폼마다 바이너리를 준비할 필요가 없어진다. 따라서 Unity의 기본 원칙은 소스코드를 컴파일하여 얻은 IL을 그대로 각 환경에 맞는 런타임으로 실행하는 것으로 멀티플랫폼을 구현하고 있다.
<IL 코드를 확인해 보자>
평소에는 잘 볼 수 없는 IL 코드는 메모리 확보, 실행 속도 등 성능을 고려하는 데 있어 매우 중요한 부분이다. 예를 들어 배열과 List는 같은 foreach 루프에서도 서로 다른 IL코드가 출력되며, 배열이 더 성능 좋은 코드가 된다. 또한 의도하지 않은 숨겨진 힙 할당을 발견할 수도 있다. 이러한 C#과 IL코드의 대응 감각을 익히기 위해 평소에 자신이 작성한 C# 코드의 IL 변환 결과를 확인해 보는 것을 추천한다. Visual Studio 나 Rider와 같은 IDE에서 IL 코드를 열람할 수 있지만, IL 코드 자체는 어셈블리라는 저급 언어이기 때문에 이해하기 어려운 언어이다. 그런 경우에는 SharpLab 이라는 웹 서비스를 이용하면 C#을 IL코드로 변환한 코드와 IL을 C#으로 역변환한 코드를 확인할 수 있어 이해하기 수월하다. 이 책의 후반부 제 10장에서 실제 변환 예제를 소개한다.
<IL2CPP>
앞서 언급했듯이 유니티는 기본적으로 C#을 IL코드로 컴파일하여 런타임에 실행하는데, 2015년 경부터 일부 환경에서 문제가 발생하기 시작했다. 바로 iOS나 안드로이드에서 동작하는 앱의 64비트 지원이다. C#은 IL코드를 실행하기 위해 각각의 환경에서 동작할 수 있는 런타임이 필요한 것은 앞서 언급했듯이 사실 그전까지의 유니티는 오랜 기간 .NET Framework의 OSS 구현인 Mono를 포크하여 Unity 자체적으로 수정하여 사용하고 있었다. 즉, Unity가 64bit를 지원하기 위해서는 포크한 Mono를 64bit로 바꿔야했다. 물론 이는 엄청난 노력이 필요하기 때문에 유니티는 대신 IL2CPP 라는 기술을 개발하여 이 난제를 해결했다.
IL2CPP는 이름 그대로 IL to CPP를 의미하며, IL 코드를 C++코드로 변환하는 기술이다. C++은 어떤 개발 환경에서도 네이티브 지원되는 범용성이 높은 언어이기 때문에 C++코드로 출력하면 각 개발 툴체인에서 기계어로 컴파일할 수 있다. 따라서 64bit 대응은 툴체인의 몫이 되므로 Unity측에서 대응할 필요가 없어진다. 또한 C#과 달리 빌드 시점에 기계어로 컴파일되기 때문에 런타임에 기계어로 변환할 필요가 없어져 성능이 향상되는 이점도 있다.
C++코드는 일반적으로 빌드 시간이 오래 걸린다는 단점이 있지만, 64bit 대응과 성능을 한 번에 해결할 수 있는 IL2CPP라는 기술은 Unity의 핵심이 되었다.
<Unity 런타임>
그런데 유니티에서 개발자는 C#으로 게임을 프로그래밍하지만, 엔진이라고 불리는 유니티 자체의 런타임은 사실 C#으로 구동되는 것이 아니다. 소스 자체는 C++로 작성되며, 플레이어라는 부분은 각 환경에서 실행할 수 있도록 미리 빌드된 상태로 배포된다. 유니티가 엔진을 C++로 작성하는 이유는 몇 가지 이유가 있다.
- 빠르고 메모리 절약형 성능을 얻기 위해
- 최대한 많은 플랫폼에 대응하기 위해
- 엔진의 지적재산권 보호를 위해 (블랙박스화)
개발자가 작성한 C# 코드는 어디까지나 C#으로 동작하기 때문에 Unity에서는 네이티브로 동작하는 엔진 부분과 C# 런타임으로 동작하는 사용자 코드 부분의 두 영역이 필요하다. 엔진과 사용자 코드는 실행 중에 적절히 데이터를 주고 받으며 동작한다. 예를 들면 GameObject.transform을 C#에서 호출하면 씬 상태 등 게임 실행 상태는 모두 엔진 내부에서 관리되기 때문에 먼저 네이티브 호출을 통해 네이티브 영역의 메모리 데이터에 접근하고, C#에 값을 반환하는 과정을 거친다. 여기서 주의할 점은 C#과 네이티브는 메모리를 공유하지 않기 때문에 C#에서 필요한 데이터는 매번 C#측에서 메모리를 확보해야 한다는 점이다. 또한 API 호출도 네이티브 호출이 발생하는 등 비용이 많이 들기 때문에 자주 호출하지 않고 값을 캐싱하는 최적화 기법이 필요하다.
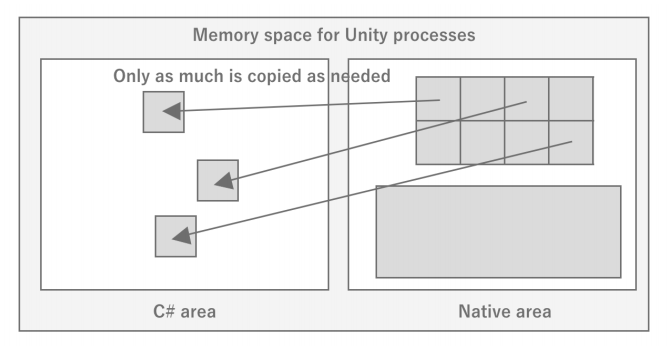
이처럼 Unity를 개발할 때는 눈에 보이지 않는 엔진 부분도 어느 정도 의식해야 한다. 따라서 수시로 유니티 엔진의 네이티브 영역과 C#을 연결하는 인터페이스의 소스코드를 살펴보는 것이 좋다. 다행히 유니티사에서 C#부분이라면 GitHub에 공개 하고 있기 때문에 대부분 네이티브 호출로 되어 있는 것을 알 수 있다.
[2.4.2 애셋의 실체]
앞 절에서 설명했듯이 유니티 엔진은 네이티브로 실행되기 때문에 기본적으로 C#측에서는 데이터를 가지고 있지 않다. 애셋을 다루는 방식도 마찬가지로 네이티브 영역에서 애셋을 로드하고, C#에 참조를 반환하거나 데이터를 복사하여 반환할 뿐이다. 따라서 애셋을 로드하고, C#에 참조를 반환하거나 데이터를 복사하여 반환할 뿐이다. 따라서 애셋을 로드할 때는 크게 두가지로 나눌 수 있는데, 유니티 엔진 측에서 로드하도록 경로를 지정하는 방법과 바이트 배열 등 원시 데이터를 직접 전달하는 방법이 있다. 경로를 지정하는 경우 네이티브 영역에서 로드하기 때문에 C#측에서 메모리를 소비하지 않지만, 바이트 배열 등 데이터를 C#측에서 로드/가공하여 전달하면 C#측과 네이티브 측에서 이중으로 메모리를 소비하게 된다.
또한, 애셋의 실체가 네이티브 측에 있기 때문에 애셋의 다중 로드나 누수 관련 조사의 난이도도 높아진다. 이는 개발자가 주로 C# 측의 프로파일링과 디버깅을 중심으로 진행하기 때문이다. C# 측의 실행 상태만으로는 이해하기 어렵고, 엔진 측의 실행 상태와 대조하면서 분석해야 하는데, 네이티브 영역의 프로파일링은 유니티가 제공하는 API에 의존하기 때문에 도구가 제한적이라는 문제가 있다. 이 책에서 다양한 툴을 활용하여 분석하는 방법을 소개하는데, 이 때 C#과 네이티브의 공간을 의식하면 이해가 쉬울 것이다.
[2.4.3 스레드]
스레드는 프로그램의 실행 단위이며, 일반적으로 하나의 프로세스 안에 여러 개의 스레드를 생성하면서 처리가 진행된다. CPU의 하나의 코어는 동시에 하나의 스레드만 처리할 수 있기 때문에 여러 개의 스레드를 처리하기 위해 빠르게 스레드를 전환하면서 프로그램을 실행한다. 이를 "컨텍스트 스위치" 라고 한다. 컨텍스트 스위치를 할 때 오버헤드가 발생하기 때문에 자주 발생하면 처리 효율이 떨어진다.
프로그램 실행 시 기본이 되는 메인 스레드가 생성되고, 이 스레드에서 프로그램이 필요에 따라 다른 스레드를 생성하고 관리한다. Unity의 게임 루프는 단일 스레드에서 동작하도록 설계되었기 때문에 사용자가 작성한 스크립트는 기본적으로 메인 스레드에서 동작하게 된다. 반대로 메인 스레드가 아닌 다른 곳에서 Unity API를 호출하려고 하면 대부분의 API는 오류가 발생한다.
메인 스레드에서 별도의 스레드를 생성하여 처리를 실행하는 경우, 해당 스레드가 언제 실행되고 언제 완료될지 알 수 없다. 따라서 스레드 간 처리를 동기화하기 위한 수단으로 "시그널" 이라는 메커니즘이 있다. 다른 스레드의 처리를 기다리는 경우, 해당 스레드에서 시그널을 알려주면 대기를 해제할 수 있다. 이 시그널 대기는 Unity 내부에서도 사용되기 때문에 프로파일링 시에도 관찰할 수 있지만, WaitFor~라는 이름에서 알 수 있듯이 단지 다른 처리를 기다리는 것일 뿐이라는 점을 주의해야 한다.
<Unity 내부의 스레드>
하지만 모든 처리를 메인 스레드에서 실행하면 프로그램 전체 처리에 시간이 오래 걸리게 된다. 여러 개의 무거운 프로세스가 있고 그것이 상호 의존성이 없는 경우, 어느 정도 처리를 동기화하여 병렬 처리를 할 수 있다면 프로그램 실행을 단축할 수 있다. 이러한 고속화를 위해 게임 엔진 내부에서는 병렬 처리를 많이사용한다. 그 중 하나가 렌더 스레드(Render Thread)이다. 이름 그대로 렌더링 전용 스레드로, 메인 스레드에서 계산한 프레임의 렌더링 정보를 그래픽 명령어로 GPU에 전송하는 역할을 한다.
메인 스레드와 렌더 스레드는 파이프라인처럼 실행되기 때문에 렌더 스레드가 처리하는 동안 다음 프레임의 계산이 시작된다. 그런데 만약 렌더 스레드 내에서 한 프레임을 처리하는 시간이 길어지면 다음 프레임의 렌더링 계산이 끝나도 렌더링을 시작하지 못하고 메인 스레드는 기다리게 된다. 게임 개발에서는 메인 스레드, 렌더 스레드 중 어느 한쪽이 무거워지면 FPS가 떨어지므로 주의하자.
<병렬 처리 가능한 사용자 처리의 스레드화>
또한, 게임 특유의 부분으로 물리 엔진이나 흔들림 등 병렬 처리가 가능한 계산 작업들이 많이 존재합니다. 이러한 계산을 메인 스레드가 아닌 다른 스레드에서 실행할 수 있도록 Unity에서는 워커 스레드(Worker Thread)가 존재한다. Worker Thread는 JobSystem을 통해 생성된 계산 태스크를 실행한다. JobSystem을 이용하여 메인 스레드의 처리 부하를 줄일 수 있다면 적극적으로 활용하도록 합니다. 물론 JobSystem을 이용하지 않고 자체적으로 스레드를 생성하는 방법도 있습니다.
스레드는 성능 튜닝에 유용한 반면, 너무 많이 사용하면 오히려 성능이 저하되거나 처리 복잡도가 높아질 위험도 있으므로 함부로 사용하지 않는 것이좋다.
[2.4.4 게임 루프]
Unity를 포함한 일반적인 게임 엔진은, 게임 루프 (플레이어 루프) 라는 엔진의 루틴 처리가 있다. 루프를 간결하게 표현하면 다음과 같다.
1. 키보드, 마우스, 터치 디스플레이 등 컨트롤러의 입력 처리
2. 1 프레임의 시간 동안 진행해야 할 게임 상태 계산
3. 새로운 게임 상태 렌더링
4. 목표 FPS에 따라 다음 프레임까지 대기
이 루프를 반복하여 게임을 영상으로 GPU에 출력한다. 만약 1프레임 내 처리에 시간이 오래 걸리게 되면 당연히 FPS가 떨어지게된다.
<Unity의 게임 루프>
유니티의 게임 루프는 유니티 공식 레퍼런스를 보면 다음과 같다.
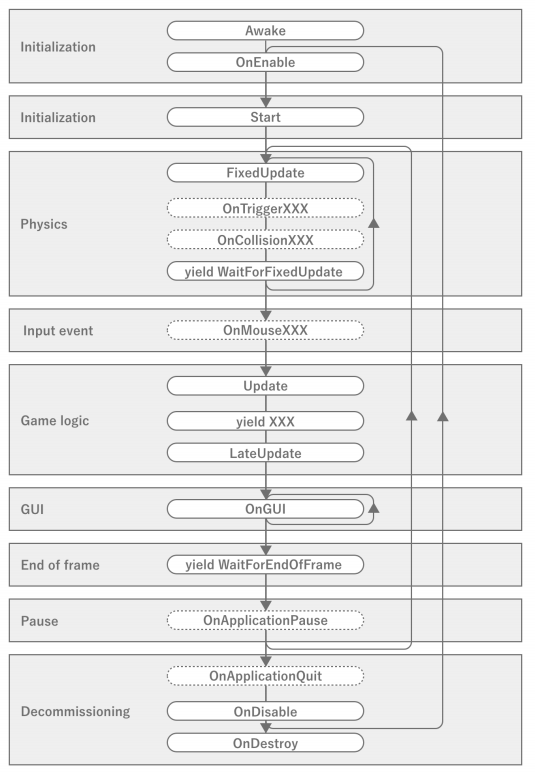
위 그림은 엄밀히 말하면 MonoBehaviour의 이벤트 실행 순서를 나타낸 것으로, 게임 엔진으로서의 게임 루프와는 다르지만, 개발자가 알아야 할 게임 루프로는 이 정도면 충분하다. 특히 중요한 이벤트로는 Awake, OnEnable, Start, FixedUpdate, Update, LateUpdate, OnDisable, OnDestroy 등 과 각종 코루틴 처리 타이밍이 있다. 이벤트의 실행 순서와 타이밍을 잘못 이해하면 예상치 못한 메모리 누수나 불필요한 계산이 발생할 수 있다. 따라서 중요 이벤트의 호출 타이밍과 해당 이벤트 내에서의 실행 순서 등의 성격을 파악해 두어야 한다.
물리 연산은 일반 게임 루프와 같은 간격으로 실행하면 충돌이 판정되지 않고 오브젝트가 빠져나가는 등의 특수한 문제가 있다. 그래서 보통은 물리 연산 루틴의 루프를 고빈도로 돌리도록 게임 루프와 다른 간격으로 루프를 돌린다. 하지만 너무 자주 돌리면 메인 게임 루프의 업데이트 처리와 충돌할 수 있기 때문에 어느 정도 동기화해야 한다. 따라서 물리 연산이 필요 이상으로 무거워지면 프레임의 렌더링 처리에 영향을 미치고, 프레임의 렌더링 처리가 무거워지면 물리 연산이 지연되어 슬립이 발생하는 등 서로 영향을 미칠 수 있으므로 주의해야한다.
[2.4.5 GameObject]
앞서 언급했듯이 Unity의 엔진 자체가 네이티브 방식으로 동작하기 때문에 C#의 Unity API도 대부분 내부 네이티브 API를 호출하기 위한 인터페이스이다. 이는 GameObject나 여기에 붙이는 컴포넌트를 정의하는 MonoBehaviour도 마찬가지이며, 항상 C# 측에서 네이티브에 대한 참조를 가지고 있게 된다. 그런데 네이티브 측에서 데이터를 관리하면서 C# 측에서도 해당 참조를 가지고 있으면 폐기 시점에 불편함이 발생한다. 네이티브 측에서 파기된 데이터에 대해 C#에서 임의로 참조를 지울 수 없기 때문이다.
실제로 아래 <리스트 1>를 보면 파기한 GameObject가 null인지 체크하고 있지만, 로그에는 true가 출력된다. 이는 표준 C#의 동작으로는 부자연스러운데, _gameObject에는 null을 대입하지 않았기 때문에 GameObject 타입의 인스턴스에 대한 참조가 남아있어야한다.
<리스트 1> : 파기 후 참조 테스트
public class DestroyTest : UnityEngine.MonoBehaviour
{
private UnityEngine.GameObject _gameObject;
Private void Start()
{
_gameObject = new UnityEngine.GameObject("test");
StartCoroutine(DelayedDestroy());
}
System.Collections.IEnumerator DelayedDestroy()
{
var waitOnesecond = new Unityengine.WaitForSeconds(1f);
yield return waitOneSecond;
Destroy(_gameObject);
yield return waitOneSecond;
UnityEngine.Debug.Log(_gameObject == null);
}
}이는 Unity의 C# 측에서 파기된 데이터에 대한 접근을 제어하고 있기 때문이다. 실제로 Unity의 C# 구현부 UnityEngine.Object의 소스 코드를 보면 아래의 <리스트 2>와 같이 되어 있다.
<리스트 2> : UnityEngine.Obejct의 == 연산자 구현
public static bool operator==(Object x, Object y)
{
return CompareBase(x, y);
}
static bool CompareBaseObjects(UnityEngine.Object lhs, UnityEngine.Object rhs)
{
bool lhsNull = ((object)lhs) == null;
bool rhsNull = ((object)rhs) == null;
if (rhsNull) return !IsNativeObjectAlive(lhs);
if (lhsNull) return !IsNativeObjectAlive(rhs);
return lhs.m_InstaceID == rhs.m_InstanceID;
}
static bool IsNativeObjectAlive(UnityEngine.Object o)
{
if (o.GetCachedPtr() != IntPtr.Zero)
return true;
if (o is MonoBehaviour || o is ScriptableObject)
return false;
return DoesObjectWithInstaceIDExist(o.GetInstanceID());
}요약하면, null 비교를 할 때 네이티브 측의 데이터가 존재하는지 여부를 체크하고 있기 때문에 폐기된 인스턴스에 대한 null 비교가 true가 된다. 이 때문에 null이 아닌 GameObject의 인스턴스가 일부 null인 것처럼 동작한다. 이 특성은 언뜻 보기에는 편리하지만, 매우 까다로운 측면도 있다. _gameObject는 실제로 null이 아니기 때문에 메모리 누수를 유발하기 때문이다. _gameObject 1개 분량의 메모리 누수는 당연하지만, 예를 들어 해당 컴포넌트 중에서 마스터와 같은 거대한 데이터에 대한 참조를 가지고 있는 경우 C#으로서는 참조가 남아있어 가비지 컬렉션의 대상이 되지 않기 때문에 엄청난 메모리 누수가 발생하기 된다. 이를 피하기 위해서는 _gameObject에 null을 대입하는 등의 대책이 필요하다.
[2.4.6 AssetBundle]
스마트폰용 게임은 앱의 크기가 제한되어 있기 때문에 모든 에셋을 앱에 포함시킬 수 없다. 따라서 필요에 따라 에셋을 다운로드하기 위해 Unity 에는 AssetBundle이라는 여러 개의 에셋을 묶어 동적으로 로드하는 메커니즘이 존재한다. 언뜻 보면 쉽게 다룰 수 있을 것 같지만, 대규모 프로젝트의 경우 제대로 설계하지 않으면 예상치 못한 곳에서 메모리를 낭비할 수 있기 때문에 메모리와 AssetBundle에 대한 충분한 이해와 세심한 설계가 필요하다. 따라서 이 절에서는 AssetBundle에 대해 튜닝 관점에서 알아야 할 사항을 설명한다.
<AssetBundle의 압축 설정>
AssetBundle은 빌드 시 기본적으로 LZMA 압축으로 설정되어 있다. 이를 BuildAssetBundleOptions의 UncompressedAssetBundle으로 마꾸면 무압축으로, ChunkBasedCompression으로 바꾸면 LZ4 압축으로 변경할 수 있다. 이러한 설정의 차이는 아래 표와 같은 경향을 보인다.
| 항목 | 무압축 | LZMA | LZ4 |
|---|---|---|---|
| 파일크기 | 특대 | 특소 | 소형 |
| 로딩시간 | 빠른 | 느림 | 상당히 빠름 |
즉, 로딩 시간을 가장 빠르게 하려면 무압축이 좋지만, 파일 크기가 치명적으로 커지기 때문에 스마트폰의 저장 공간 낭비를 피하기 위해서는 기본적으로 사용할 수 없다. 반면 LZMA는 파일 크기가 가장 작지만 알고리즘 문제로 압축 해제에 시간이 오래 걸리고, 부분 압축 해제 처리가 불가능하다는 단점이 있다. LZ4는 속도와 파일 크기의 균형 잡힌 압축 설정으로 ChunkBasedCompression 이름처럼 부분 압축이 가능하기 때문에 LZMA 처럼 전체 압축을 풀지 않고도 부분적으로 불러올 수 있다.
<AssetBundle의 종속관계와 중복성>
한 에셋이 여러 에셋에 의존하고 있는 경우, AssetBundle화할 때 주의해야한다. 예를 들어 머티리얼 A와 머티리얼 B가 텍스처 C에 의존하는 경우, 텍스처를 AssetBundle화하지 않고 머티리얼 A와 B만 AssetBundle화하면 생성되는 2개의 AssetBundle 각각에 텍스처 C가 포함되어 중복으로 낭비되는 문제가 발생한다. 물론 용량도 낭비지만, 두 머티리얼을 메모리에 로드할 때 텍스처가 따로 인스턴스화되기 때문에 메모리도 낭비하게 된다.
동일한 에셋이 여러 AssetBundle에 포함되는 것을 피하기 위해서는 텍스처 C도 단독으로 AssetBundle화하여 머티리얼의 AssetBundle에서 의존하는 형태로 만들거나 머티리얼 A,B와 텍스처 C를 하나로 묶은 AssetBundle로 만들어야 한다.
<AssetBundle에서 로드된 에셋의 동일성 확인>
AssetBundle에서 에셋을 로드할 때 중요한 특성으로, AssetBundle이 로드되는 동안에는 동일한 에셋을 몇 번을 로드해도 동일한 인스턴스가 반환된다. 이는 Unity 내부에서 이미 로드된 에셋을 관리하고 있음을 나타내며, Unity 내부에서 AssetBundle과 에셋은 묶여 있는 상태가 된다. 이 특성을 이용하면 게임 측에서 에셋의 캐시 메커니즘을 만들지 않고 Unity 측에 맡길 수도 있다.
단, AssetBundle.Unload(false)에서 언로드한 에셋은 아래 그림과 같이 같은 AssetBundle에서 같은 에셋을 다시 로드해도 다른 인스턴스가 되므로 주의해야한다. 이는 언로드하는 시점에 AssetBundle과 에셋의 연결이 해제되어 에셋의 관리가 공중에 떠 있는 상태가 되기 때문이다.
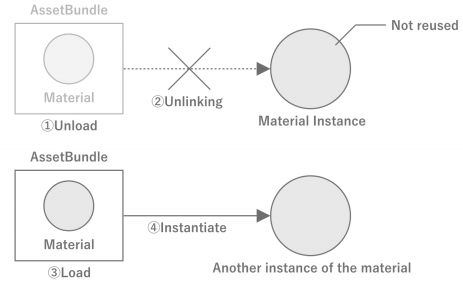
<AssetBundle에서 로드한 에셋을 파기하는 경우>
&emspAssetBundle.Unload(true)에서 AssetBundle을 언로드하는 경우, 로드한 에셋도 완전히 파기되기 때문에 메모리와 관련하여 특별히 문제가 없지만, AssetBundle.Unload(false)를 사용하는 경우 적절한 타이밍에 에셋 언로드 명령을 호출하지 않으면 에셋이 파기되지 않는다. 따라서 후자를 사용하는 경우 장면 전환 시 등에 적절히 Resources.UnloadUnusedAssets을 호출하여 에셋이 폐기되도록 해야 한다. 또한 Resources.UnloadUnusedAssets의 이름에서 알 수 있듯이 참조가 남아있는 경우 해제되지 않는다는 점도 주의해야 한다. 참고로 Addressable을 사용하는 경우 내부적으로 AssetBundle.Unload(true)를 호출한다.
[2.5 C# 기초 지식]
이 절에서는 성능 튜닝에 필수적인 C#의 언어 사양과 프로그램 실행 시 동작에 대해 설명한다.
[2.5.1 스택과 힙]
&emsp윗 부분의 <스택과 힙> 에서는 프로그램 실행 시 메모리 관리 방식으로 스택과 힙이 존재한다는 것을 소개했었다. 스택은 OS가 관리하는 반면, 힙은 프로그램 측에서 관리한다. 즉, 힙 메모리가 어떻게 관리되는지 알면 메모리를 의식한 구현을 할 수 있다. 힙 메모리 관리 구조는 프로그램을 작성한 소스 코드의 언어 사양에 따라 달라지는 부분이 크기 때문에 C#의 힙 메모리 관리에 대해 설명한다.
원래 힙 메모리는 필요한 시점에 메모리를 확보하고, 사용 후에는 메모리를 해제해야한다. 만약 메모리를 해제하지 않으면 메모리 누수가 발생하여 애플리케이션이 사용하는 메모리 영역이 팽창하여 결국에는 크래시가 발생하게 된다. 하지만 C#에는 명시적인 메모리 해제 처리가 없다. NET 런타임 환경에서 C# 프로그램이 실행되는 경우에서는 힙 메모리가 런타임에 의해 자동으로 관리되고, 다 쓴 메모리는 적절한 타이밍에 해제되기 때문에 힙 메모리를 매니지드 힙 이라고도 한다.
스택에 확보된 메모리는 함수의 수명과 일치하므로 함수의 마지막에 메모리를 해제해주면 되지만 힙에 확보된 메모리는 함수의 수명을 넘어 생존하는 경우가 대부분이다. 즉, 힙 메모리를 필요로 하는 시점과 사용 종료 시점이 다양하기 때문에 자동적이고 효율적으로 힙 메모리를 사용할 수 있는 메커니즘이 필요한데, 이 메커니즘을 가비지컬렉션 (Garbage Collection)이라고 부른다.
사실 Unity의 GC.Alloc은 가비지 컬렉션으로 관리되는 힙 메모리에 할당(Allocation)된 메모리를 나타내는 고유한 용어이다. 따라서 GC.Alloc을 줄이면 동적으로 확보되는 힙 메모리의 양을 줄일 수 있다.
[2.5.2 가비지 컬렉션]
C#의 메모리 관리에서 사용하지 않는 메모리를 검색하고 해제하는 것을 가비지 컬렉션, 줄여서 'GC'라고 한다. 가비지 컬렉터는 주기적으로 실행된다. 하지만 정확한 실행 시점은 알고리즘에 따라 달라진다. 이 작업을 통해 힙의 모든 오브젝트를 일제히 조사하고, 이미 참조되지 않는 모든 오브젝트를 삭제한다. 즉, 참조가 해제된 오브젝트가 삭제되어 메모리 공간을 확보할 수 있다.
가비지 컬렉터에는 다양한 알고리즘이 있지만, 유니티에서는 기본적으로 Boehm GC 알고리즘이 사용된다. Boehm GC 알고리즘의 특징은 '비세대적'이고 '비압축형'이라는 점이다. '비세대별'이란 가비지 컬렉션을 한 번 실행할 때마다 전체 힙을 한꺼번에 조사해야 한다는 뜻이다. 이 때문에 힙이 확장될수록 검색 범위가 넓어지기 때문에 성능이 저하된다. '비압축형'은 객체 간 간격을 채우기 위해 메모리 내 객체 이동이 이루어지지 않는다는 것을 의미한다. 즉, 메모리 상에 미세한 틈새를 만드는 파편화가 발생하기 쉽고, 관리 힙이 확장되기 쉬운 경향이 있다.
각각 계산 비용이 높은 처리이면서 다른 모든 처리를 멈춰버리는 동기식 처리이기 때문에 게임 중에 실행하면 소위 'Stop the World'라고 불리는 처리 중단 현상이 발생하게 된다.
Unity 2018.3 버전부터는 GCMode를 지정할 수 있게 되어 일시적으로 비활성화할 수 있다.
GarbageCollector.GCMode = GarbageCollector.Mode.Disabled;
하지만 당연히 비활성화된 기간 동안 GC.Alloc을 하게 되면 힙 영역이 확장되고 소모되어 결국에는 새로 확보할 수 없게 되어 앱 충돌로 이어진다. 메모리 사용량은 쉽게 증가하기 때문에 비활성화되어 있는 기간에는 GC.Alloc이 전혀 이루어지지 않도록 구현해야 하며, 구현 비용도 높아지기 때문에 실제로 사용할 수 있는 장면은 제한적이다. (예 : 슈팅 게임의 슈팅 파트만 비활성화 등)
또한, Unity 2019 버전부터 Increamental GC를 선택할 수 있게 되었다. Increamental GC는 가비지 컬렉션의 처리가 프레임 단위로 이루어지도록 하여 큰 스파이크는 이전보다 완화할 수 있게 되었다. 그러나 프레임당 처리 시간을 줄이면서 최대한의 성능을 발휘해야 하는 게임의 경우, GC.Alloc이 발생하지 않도록 구현해야 한다.
언제부터 시작해야 하는가?
게임은 코드 양이 많기 때문에 모든 기능 구현이 완료된 후 성능 튜닝을 진행하다 보면 종종 GC.Alloc을 피할 수 없는 설계/구현을 만나게 될 수 있다. 설계 초기 단계부터 어디서 발생하는지 항상 염두에 두고 코딩을 하면 재작업을 통한 비용도 줄일 수 있고, 전체적인 개발 효율이 향상되는 경향이 있다.
이상적인 구현의 흐름은 우선 속도 중심으로 프로토타입을 제작하여 플레이의 핵심이 되는 부분을 검증하고 그 다음 본 제작 단계로 넘어갈 때 한 번 설계를 검토하고 재구축하는 것이다. 이 재구축하는 단계에서 GC.Alloc의 박멸에 힘쓰는 것이 건전한 방법일 것이다. 경우에 따라서는 코드의 가독성을 낮춰서라도 속도를 높여야 하는 경우도 있기 때문에 프로토타입부터 작업하다 보면 개발 속도도 느려질 수 있다.
[2.5.3 구조체(struct)]
C#에서 복합형의 정의는 클래스와 구조체가 존재한다. 기본적으로 클래스는 참조형, 구조체는 값형이다. 각각의 특성과 선택 기준, 사용상의 주의점에 대해 알아보자.
<메모리 할당 대상의 차이>
참조형과 값형의 첫 번째 차이점은 메모리 할당 대상이 다르다는 점이다. 다소 정확하지는 않지만, 다음과 같이 알아두면 큰 무리가 없다. 참조형은 메모리의 힙 영역에 할당되어 가비지 컬렉션의 대상이 된다. 값 유형은 메모리의 스택 영역에 할당되며 가비지 수집 대상이 아니다. 값형 할당 및 할당 해제 비용은 일반적으로 참조형보다 저렴하다.
그러나 참조형 필드에 선언된 값형이나 정적 변수는 힙 영역에 할당된다. 따라서 구조체로 정의한 변수가 반드시 스택 영역에 할당되는 것은 아니라는 점에 유의해야한다.
<배열 처리>
값형 배열은 인라인으로 할당되며, 배열 요소는 값형 실체(인스턴스)가 그대로 나열된다. 반면 참조형 배열은 배열 요소들이 참조형 실체에 대한 참조(주소)로 정렬된다. 따라서 값형 배열의 할당과 해제는 참조형에 비해 훨씬 비용이 적게 든다. 또한 대부분의 경우 값형 배열은 참조의 국소성 (공간적 국소성)이 크게 향상되므로 CPU 캐시 메모리의 적중확률이 높아져 처리 속도가 빨라진다는 장점이 있다.
<값의 복사>
참조형 대입(할당)에서는 참조(주소)가 복사된다. 반면 값형 대입(할당)은 값 전체가 복사된다. 주소의 크기는 32bit 환경의 경우 4 바이트, 64bit 환경의 경우 8바이트이다. 따라서 큰 참조형 할당은 주소 크기보다 큰 값형 할당보다 비용이 적게 든다.
또한, 메소드를 이용한 데이터 교환 (인수, 반환값)에 있어서도 참조형은 참조 (주소)가 값으로 전달되는 반면, 값형은 인스턴스 자체가 값으로 전달된다.
private void HogeMethod(MyStruct myStruct, Myclass myClass){...}
예를 들어 이 메소드에서는 MyStruct의 값 전체가 복사된다. 즉, MyStruct의 크기가 커지면 그만큼 복사 비용도 증가한다. 반면 MyClass쪽에서는 myClass의 참조가 값으로만 복사되기 때문에 MyClass의 크기가 커져도 복사 비용은 주소 크기만큼만 발생하기 때문에 일정하게 유지된다. 복사 비용의 증가는 처리 부하와 직결되기 때문에 취급하는 데이터 크기에 따라 적절히 선택해야한다.
<불변성>
참조형 인스턴스에 가한 변경은 같은 인스턴스를 참조하는 다른 곳에도 영향을 미친다. 반면, 값형 인스턴스는 값 전달 시 사본이 생성된다. 값형 인스턴스가 변경되면 당연히 해당 인스턴스의 복사본에는 영향을 미치지 않는다. 복사본은 프로그래머가 명시적으로 생성하는 것이 아니라 인수가 전달될 때 또는 반환값이 반환될 때 암묵적으로 생성된다. 프로그래머로서 값을 변경한 줄 알았는데, 실제로는 복사본에 값을 설정한 것을 뿐 목적과는 다른 결과를 초래한 적이 있을 것이다. 이와같이 변경 가능한 값 유형은 많은 프로그래머에게 혼란을 줄 수 있기 때문에 값 유형은 불변으로 권장되고 있다.
참조 전달
흔히 오용하는 것으로 '참조형은 항상 참조 전달이 된다'를 들 수 있는데, 앞서 언급했듯이 참조(주소) 복사가 기본이며 참조 전달은 ref/in/out 매개변수 수식어를 사용했을 때 이루어진다.
private void HogeMethod(ref MyClass myClass){...}참조형 값 전달에서는 참조(주소)를 복사했기 때문에 인스턴스 교체를 해도 복사 원본 인스턴스에는 영향을 주지 않았지만, 참조 전달을 하면 원본 인스턴스 교체도 가능해진다.
private void HogeMethod(ref MyClass myClass)
//인수로 전달된 원래의 인스턴스를 다시 작성하게 된다.
{
myClass = new MyClass();
}
<박스화>
박스화는 값형에서 object형 값형에서 인터페이스 형으로 변환하는 과정을 말한다. 박스는 힙에 할당되어 가비지 컬렉션의 대상이 되는 객체이다. 따라서 박싱과 언박싱이 과도하게 이루어지면 GC.Alloc이 발생한다. 이에 반해, 참조형이 캐스트될 때는 박스화가 이루어지지 않는다.
<예시> : 값형에서 object형으로 캐스팅하면 박스화.
int num = 0;
object obj = num; //박스화
num = (int) obj // 박스화 해제
이렇게 알기 쉽고 무의미한 박스화를 사용하지 않지만, 메소드에서 사용되는 경우를 확인해보자.
<예시> : 암시적 캐스트로 박스화가 이뤄지는 예시
private void HogeMethod(object data){...}
// 중략
int num = 0;
HogeMethod(num); // 인수로 박스화
이런 경우, 무의식적으로 박스화를 하고 있는 경우가 존재한다.
간단한 대입에 비해 박스화 및 언박싱은 부하가 큰 과정이다. 값 타입을 박스화할 때는 새로운 인스턴스를 할당하고 구축해야 한다. 또한 박스화만큼은 아니지만 언박싱에 필요한 캐스트도 큰 부하가 발생한다.
<클래스와 구조체 선택 기준>
- 구조체를 고려해야 할 조건
-> 타입의 인스턴스가 적고 유효기간이 짧은 경우가 많은 경우
-> 다른 객체에 내장되는 경우가 많은 경우- 구조체를 피해야 하는 조건 : 단, 타입이 다음과 같은 특성을 모두 가지고 있는 경우는 제외
-> 원시형(int,double 등)과 마찬가지로 논리적으로 단일 값을 표현할 때
-> 인스턴스 크기가 16바이트 미만인 경우
-> 불변(Immutable)일 때
-> 자주 박스화할 필요가 없을 때
위의 선택 조건에 해당하지 않지만, 구조체로 정의된 타입도 다수 존재한다. 유니티에서 자주 사용되는 Vector4, Quaternion 등 16 바이트 미만은 아니지만 구조체로 정의되어 있다. 이들을 효율적으로 다루는 방법을 확인한 후, 복사 비용이 증가한다면 회피하는 방법을 포함하여 선택하고, 경우에 따라서는 자체적으로 동등한 기능을 가진 최적화 버전을 만드는 것도 고려해 보는것이 좋다.
[2.6 알고리즘과 계산량]
게임 프로그래밍에는 다양한 알고리즘이 사용된다. 알고리즘은 어떻게 만들었냐에 따라 계산 결과는 같지만, 성능이 크게 달라질 수 있다. 예를 들어, C#에 표준으로 제공되는 알고리즘이 얼마나 효율적인지, 자신이 구현한 알고리즘이 얼마나 효율적인지 각각 평가할 수 있는 척도가 필요가헤 된다. 이를 측정하는 기준으로 계산량이라는 지표가 사용되고 있다.
[2.6.1 계산량이란?]
계산량이란 알고리즘의 계산 효율을 측정하는 척도를 말하며, 세분화하면 시간 효율을 측정하는 시간 계산량, 메모리 효율을 측정하는 영역 계산량 등이 있다. 계산량 순서는 O(빅오)표기법으로 표현된다.
일반적으로 사용되는 주요 계산량은 O(1), O(n), O(n^2), O(n/logn), O(nlogn) 등이 있다. 괄호 안의 n은 데이터 수를 나타낸다. 어떤 처리가 얼마나 많은 데이터 수에 따라 처리 횟수가 늘어나는지 쉽게 이해할 수 있다. 계산량 측면에서 성능을 비교하면 O(1) < O(logn) < O(n) < O(nlogn) < O(n^2) < O(n^3) 이 된다. 예를 들어 O(logn)은 데이터 수가 1000만개여도 계산 수가 23회로 매우 우수한 것을 알 수 있다.
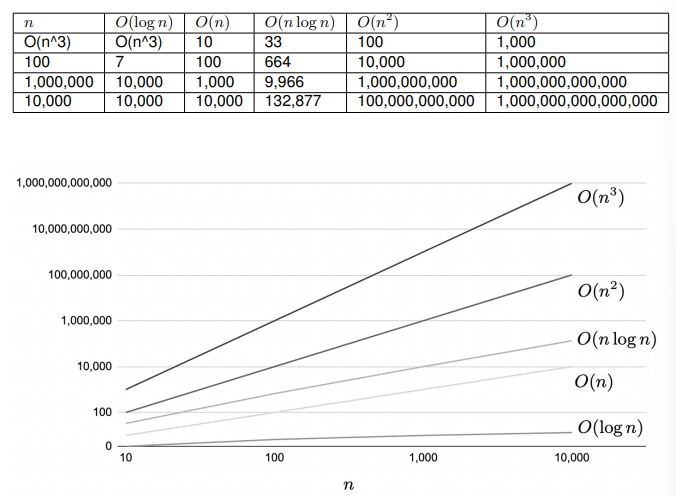
각 계산량을 보여주기 위해 몇 가지 코드 샘플을 예를 들어보자. 먼저, O(1)은 데이터 수에 관계없이 일정한 계산량임을 나타낸다.
<예시> : O(1)의 코드 예시
private int GetValue(int[] array)
{
// array는 어떤 정수값이 들어있는 배열이라고 가정한다.
var value = array[0];
return value;
}
이 메소드는 array의 데이터 수에 의존하지 않고 일정 횟수(위 식에서는 1번)로 처리가 끝난다.
다음으로 O(n)의 코드 예제를 살펴보자.
<예시> : O(n)의 코드 예시
private bool HasOne(int[] array, int n)
{
// array는 length = n, 어떤 정수 값이 들어있다고 가정한다.
for (var i = 0; i < n; ++i)
{
var value = array[i];
if(value == 1)
{
return true;
}
}
}
이 예제는 정수 값이 들어있는 배열에 1이 존재한다면 true를 반환하는 처리이다. 우연히 array의 첫 번째에 1이 있다면 가장 빠르게 처리가 끝날 수도 있지만, array 어디에도 1이 없는 경우나 array의 마지막에 1이 존재하는 경우 for문이 끝까지 돌아가기 때문에 n번 처리를 하게 된다. 이 최악의 경우를 O(n)로 나타내며, 데이터 수에 따라 계산량이 늘어나는 것을 알 수 있다.
다음으로 O(n^2)일 때의 예를 살펴보자
<예시> : O(n^2)의 코드 예시
private bool HasSameValue (int[] array1, int[] array2, int n)
{
// array1, array2는 length = n, 어떤 정수 값이 들어있다고 가정한다.
for (var i = 0; i < n; ++i)
{
var value1 = array1[i];
for (var j = 0; j < n; ++j)
{
var value2 = array2[j];
if(value1 == value2){
return true;
}
}
}
return false;
}
이 메소드는 이중 for문을 통해 두 배열의 어딘가에 같은 값이 포함되어 있으면 true를 반환한다. 최악의 경우를 생각해보면 모두 불일치하는 경우이며, 이 때 n^2번 처리하게 된다.
계산량 개념에서는 최대 차수의 항으로만 표현한다. 위 예제의 3가지 메소드를 1회씩 실행하는 메소드를 만들면 최대 차수의 O(n^2)이 된다. (O(n^2)O(n^2+n+1)이 되지 않는다.)
또한, 계산량은 데이터 수가 충분히 많을 때를 기준으로 한 것이며, 실제 측정 시간과 반드시 연동되는 것은 아니라는 점에 유의해야 한다. O(n^5)와 같이 엄청난 계산량으로 보이지만 데이터 수가 적으면 문제가 되지 않는 경우도 있기 때문에 계산량은 참고하되, 매번 데이터 수를 고려하여 처리시간에 문제가 없는지 측정하는 것을 권장한다.
[2.6.2 기본적인 컬렉션과 데이터 구조]
C#에는 다양한 데이터 구조를 가진 컬렉션 클래스가 준비되어 있다. 자주 사용하는 것을 예로 들면서 주요 메소드의 계산량을 기준으로 각각 어떤 상황에서 어떤 메소드를 사용해야 하는지 소개한다.
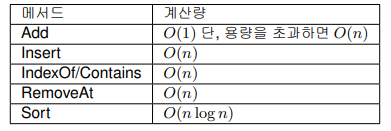
List<T>
가장 많이 사용되는 List<T>이다. 데이터 구조는 배열이다. 데이터의 정렬 순서가 중요하거나, 인덱스를 통한 데이터 조회 및 업데이트가 많은 경우에 사용하면 효과적이다. 반대로 요소의 삽입이나 삭제가 많은 경우에는 조작한 인덱스 이후의 복사본이 필요하고 계산량이 많아지므로 List<T>의 사용은 피하는 것이 좋다.
또한, Add로 용량을 초과하려고 하면 배열의 확보된 메모리 확장이 이루어진다. 메모리 확장 시에는 현재 Capacity의 2배를 확보하게 되므로 Add를 O(1)로 사용하기 위해서도 확장을 발생시키지 않고 사용할 수 이도록 적절한 초기값을 설정하여 사용해야 한다.
LinkedList<T>
LinkedList<T>의 데이터 구조는 연결 목록이다. 연결 리스트는 기본적인 데이터 구조로 각 노드가 다음 노드에 대한 참조를 가지고 있는 것과 같은 이미지이다. C#의 LinkedList<T>는 양방향 연결 리스트이므로 앞뒤 노드에 대한 참조를 각각 가지고 있다. LinkedList<T>는 요소의 추가와 삭제에 강한 특징을 가지고 있지만 배열 내의 특정 요소에 접근하는 것은 취약하다. 자주 추가나 삭제를 해야 하는 것처럼 일시적으로 데이터를 보관하는 처리를 만들고 싶을 때 등에 적합하다.

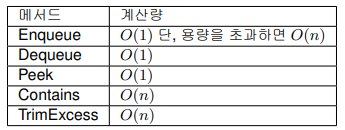
Queue<T>
Queue<T>은 선입선출법 : FIFO(First in first out)를 구현한 컬렉션 클래스이다. 입력 조작 등을 관리할 때 등 즉, 대기열을 구현할 때 사용된다. Queue<T>에서는 순환 배열을 사용하고 있다. Enqueue에서 요소를 맨 뒤에 추가하고, Dequeue에서 맨 앞의 요소를 꺼내면서 삭제한다. 용량을 초과하여 추가할 때는 확장이 이루어진다. Peak는 삭제하지 않고 맨 앞의 요소를 꺼내는 작업이다. 계산량을 보면 알 수 있듯이 *Enqueue와 Dequeue에만 사용하면 높은 성능을 얻을 수 있지만 탐색 등의 작업에는 적합하지 않다. TrimExcess는 용량을 줄이는 방법이지만 성능 튜닝 관점에서 보면 애초에 용량이 증감하지 않도록 사용하면 Queue<T>의 강점을 더욱 살릴 수 있다.
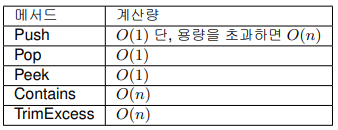
Stack<T>
Stack<T>은 후입선출법 : LIFO(Last in first out)을 구현한 컬렉션 클래스이다. Stack<T>은 배열로 구현되어 있다. Push에서 맨 앞에 요소를 추가하고, Pop에서 맨 앞의 요소를 꺼내면서 삭제한다. Peek는 삭제하지 않고 맨 앞의 요소를 꺼내는 작업이다. 자주 사용되는 장면으로는 화면 전환을 구현할 때 전환 시 진행했던 장면 정보를 Push로 남겨두고, 뒤로 가기 버튼을 눌렀을 때 Pop하는 경우 등을 들 수 있다. Stack도 Queue와 마찬가지로 Push와 Pop만을 사용하면 높은 성능을 얻을 수 있다. 요소 탐색 등은 하지 않고, 용량의 증감에도 신경을 써야한다.
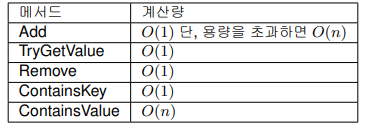
Dictionary<TKey,TValue>
지금까지 소개한 컬렉션은 순서에 의미를 부여하는 컬렉션이었지만, Dictionary<TKey,TValue>는 인덱싱에 특화된 컬렉션 클래스이다. 데이터 구조는 해시 테이블로 구현되어 있다. 키에 해당하는 값이 있는 사전과 같은 구조이다. Dictionary<TKey,TValue>는 메모리를 많이 소모하는 단점이 있지만, 그 대신 참조 속도가 O(1)로 매우 빠르다. 열거나 탐색을 필요로 하지 않고 값을 참조하는 것에 중점을 두는 경우에 매우 유용하다. 또한, 용량을 미리 설정해 두는 것이 좋다.
[2.6.3 계산량을 낮추기 위한 노력]
지금까지 소개한 컬렉션 외에도 다양한 컬렉션이 존재한다. 물론 List<T>만으로도 비슷한 처리를 구현할 수 있지만, 보다 적합한 컬렉션 클래스를 선택하면 계산량을 최적화할 수 있다. 계산량을 고려하여 메소드를 구현하는 것만으로도 무거운 처리를 피할 수 있다. 코드 최적화의 한 가지 방법으로 자신이 만든 메소드의 계산량을 확인하여 보다 적은 계산량으로 만들 수 있는지 검토해보는 것이 좋다.
고안 방법 : 메모화
어떤 복잡한 계산을 해야 하는 매우 높은 계산량의 메소드 (ComplexMethod)가 있다고 가정해보자. 하지만 어떻게 해도 계산량을 줄일 수 없을 때도 있을 것이다. 이럴 때 사용되는 수단으로 메모화라는 방법이 있다.
여기서 ComplexMethod는 인수를 주면 그에 대응하는 결과를 고유하게 반환한다고 가정한다. 먼저 전달된 인수가 처음 전달될 때는 복잡한 과정을 거친다. 계산 후 인자와 계산 결과를 Dictionary<TKey,TValue>에 넣어 캐싱해 둔다. 두 번째부터는 먼저 캐싱이 되어 있지 않은지 확인하고, 이미 캐싱이 되어 있다면 그 결과만 반환하고 종료한다. 이렇게 하면 첫 번째가 아무리 계산량이 많아도 두 번째 이후부터는 O(1)로 낮출 수 있다. 만약 미리 전달될 수 있는 인수가 어느 정도 정해져 있다면, 게임 전에 계산을 미리 해놓고 캐싱을 해두면 사실상 O(1)의 계산량으로 처리할 수 있다.
